

What do you think of when you see the following string of text?
Ronaldo Luís Nazário de Lima

Most Chinese people probably don’t understand what the above text represents. No worries, let’s look at its corresponding Chinese:
罗纳尔多·路易斯·纳萨里奥·德·利马
Now most people know this is a person’s name, and certainly, it’s a foreigner. But still, some people might not know who this person is specifically. Here is a picture of him:

From this picture, we gain additional information that he is a football player. Those not familiar with football might still have no impression of him. Now let’s take a look at this picture:

I’ll add the catchy advertisement phrase: “Protect your throat, please use JinSangZi throat lozenges. Guangxi JinSangZi!” Now many people should know who he is, after all, that catchy advertisement tormented many for a long time years ago.
The reason for giving such an example is that computers have always faced the dilemma of not being able to obtain semantic information from web text. Despite significant advancements in artificial intelligence in recent years, achieving results that surpass human capabilities in certain tasks, we are still far from the goal of a machine possessing the intelligence of a two or three-year-old child. A significant reason behind this distance is that machines lack knowledge. Just like the above example, the machine’s reaction to seeing the text is no different from our reaction to seeing Ronaldo’s name in Portuguese. To enable machines to understand the meaning behind texts, we need to model describable entities, fill in their attributes, and expand their connections with other entities, that is, to build the machine’s prior knowledge. Taking Ronaldo as an example, when we expand around this entity, we can obtain the following knowledge graph.
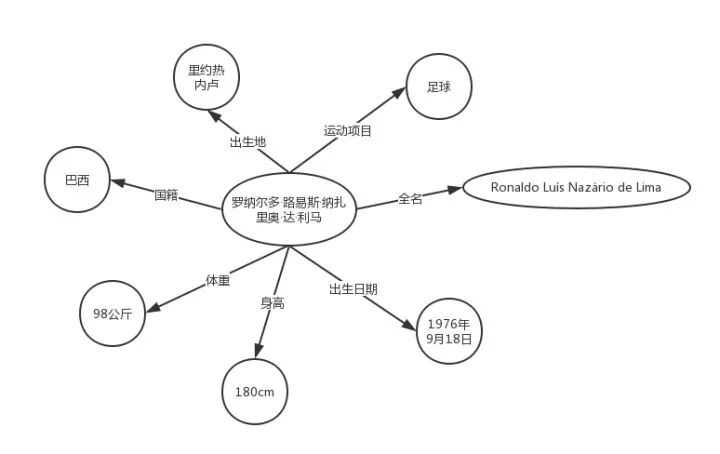
With such prior knowledge, when the machine sees Ronaldo Luís Nazário de Lima again, it will “think”: “This is a Brazilian football player named Ronaldo Luís Nazário de Lima.” This is quite similar to how we humans make associations and inferences when we see familiar things.
Notice: It should be noted that the knowledge graph above does not represent the actual organizational form of a knowledge graph; on the contrary, it may lead readers to misunderstand the concept of knowledge graphs. In the next section, I will provide a more formal representation of the content contained in this diagram within the knowledge graph. In fact, I have seen many articles introducing knowledge graphs that like to present such types of diagrams but do not provide corresponding explanations, which may mislead readers from the very beginning.
In order to improve the quality of answers returned by search engines and the efficiency of user queries, Google released the Knowledge Graph on May 16, 2012. With the Knowledge Graph as an aid, search engines can gain insight into the semantic information behind user queries and return more accurate, structured information, thus more likely satisfying user query needs. Google’s Knowledge Graph slogan “things not strings” captures the essence of the knowledge graph, which is to obtain the objects or things implied behind strings instead of meaningless strings. Again, taking Ronaldo as an example, if we want to know relevant information about Ronaldo (in many cases, the user’s search intent may also be vague; here we input the query as “Ronaldo”), in previous versions, we could only get related web pages containing this string as a result and had to enter certain web pages to find the information we were interested in; now, in addition to related web pages, the search engine will also return a “knowledge card” containing basic information about the queried object and its related other objects (CR7 is also referred to as Ronaldo; the search engine simply returns basic information about “Fat Ronaldo” based on the referential probability of “Ronaldo”, but you may need information about CR7, so the search engine lists this entity as an option), as shown in the red box in the image below. If we only want to know Ronaldo’s nationality, age, marital status, and children information, we no longer need to perform any extra operations. In the shortest time, we obtain the simplest and most accurate information.
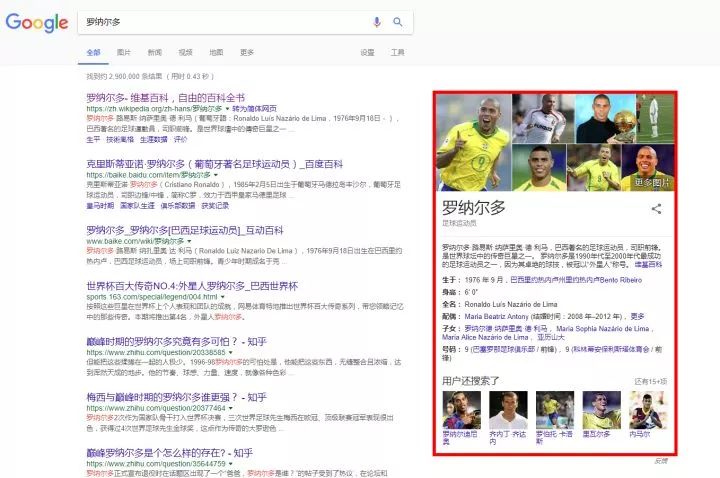
Of course, this is just one of the application scenarios of knowledge graphs in search engines. This example is also to indicate that the concept or technology of knowledge graphs was born in line with the trends of computer science and internet development. More applications of knowledge graphs will be provided in another article later.
Through the above example, readers should have a preliminary impression of knowledge graphs, which essentially represent knowledge. In fact, the concept of knowledge graphs is not new; the underlying idea can be traced back to the knowledge representation form proposed in the 1950s and 1960s – the semantic network. A semantic network consists of interconnected nodes and edges, where nodes represent concepts or objects and edges represent their relationships (is-a relationship, for example: a cat is a mammal; part-of relationship, for example: a spine is part of a mammal), as shown in the figure below. In terms of representation, semantic networks are similar to knowledge graphs, but semantic networks focus more on describing the relationships between concepts (somewhat like the hierarchical classification system of biology – kingdom, phylum, class, order, family, genus, species), while knowledge graphs focus more on describing the associations between entities.
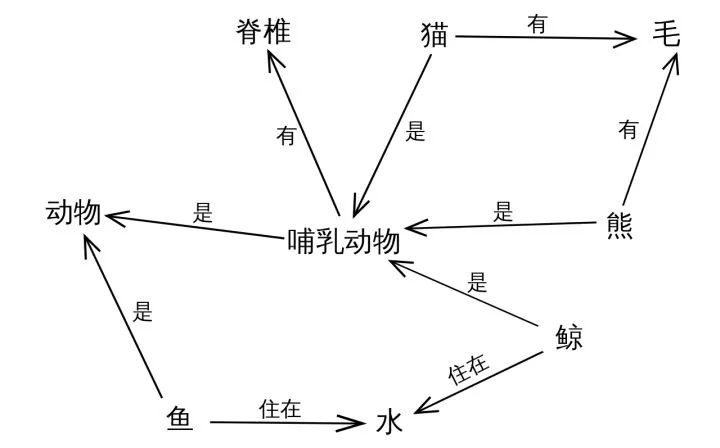
In addition to semantic networks, branches of artificial intelligence such as expert systems, the semantic web proposed by Tim Berners Lee in 1998, and linked data proposed in 2006 are all closely related to knowledge graphs and can be considered as precursors to knowledge graphs.
Currently, there is no standard definition of knowledge graphs (gold standard definition). Here, I borrow the definition of knowledge graphs from the book “Exploiting Linked Data and Knowledge Graphs in Large Organisations”:
A knowledge graph consists of a set of interconnected typed entities and their attributes.
In other words, a knowledge graph is composed of interconnected entities and their attributes. In other words, a knowledge graph consists of pieces of knowledge, each represented as an SPO triple (Subject-Predicate-Object).
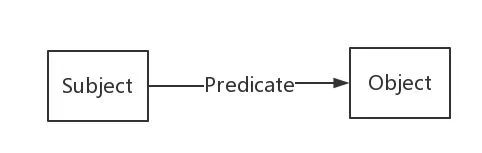
In a knowledge graph, we formally represent this triple relationship using RDF. RDF (Resource Description Framework) is a standard data model established by W3C for describing entities/resources. In an RDF graph, there are three types: International Resource Identifiers (IRIs), blank nodes, and literals. Here are the type constraints for each part of the SPO:
-
Subject can be an IRI or a blank node.
-
Predicate is an IRI.
-
Object can be any of the three types. An IRI can be viewed as a generalization and promotion of URI or URL, uniquely defining an entity/resource throughout the network or graph, similar to our ID number.
A literal is a literal value, which can be considered as plain text with a data type, for example, the original name of Ronaldo mentioned in the first part can be represented as “Ronaldo Luís Nazário de Lima”^^xsd:string.
A blank node is simply a resource without IRI and literal, or an anonymous resource. Regarding its role, interested readers can refer to W3C’s documentation; I will not elaborate here. Personally, I find the existence of blank nodes somewhat redundant, as they not only add extra difficulty to the understanding of RDF but also introduce some issues during processing. Usually, I prefer to use nodes with IRI to act as blank nodes, fulfilling their function, somewhat similar to the concept of compound value type (CVT) in Freebase. The final reference material will provide a blog discussing the flaws of blank nodes; interested readers can take a look.
So, the triple “Ronaldo’s Chinese name is 罗纳尔多·路易斯·纳萨里奥·德·利马” can be represented in RDF form as:
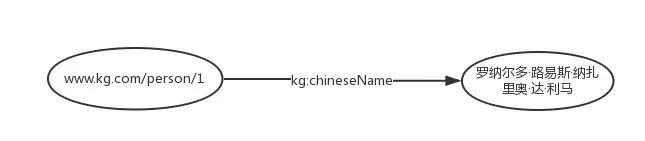
“www.kg.com/person/1” is an IRI used to uniquely represent the entity “Ronaldo”. “kg:chineseName” is also an IRI used to represent the attribute “Chinese name”. “kg:” is the prefix defined in the RDF file, as shown below.
@prefix kg: http://www.kg.com/ontology/
Thus, kg:chineseName is actually an abbreviation of “http://www.kg.com/ontology/chineseName”.
Now let’s draw the knowledge graph in a more formal way:
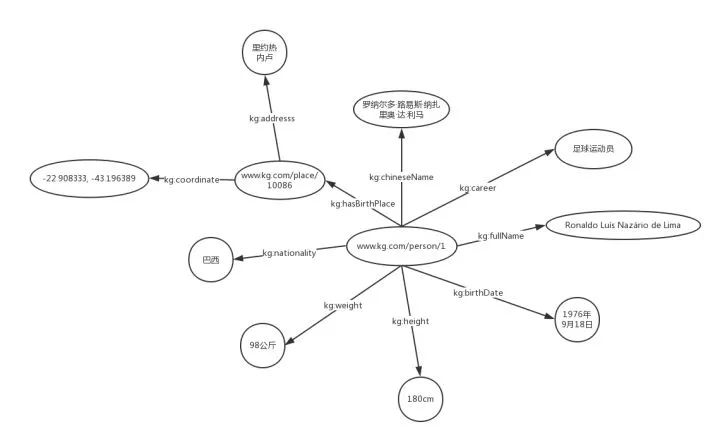
We can actually consider that knowledge graphs contain two types of nodes: resources and literals. Borrowing the concept of a tree from data structures, literals are like leaf nodes with an out-degree of 0. Now readers should understand why I said the previous diagram was inaccurate and could mislead everyone’s understanding of knowledge graphs. “Ronaldo Luís Nazário de Lima” as a literal cannot have edges pointing to external nodes, and moreover, the previous diagram does not intuitively reflect the extremely important concept of resources/entities (represented by IRI) in knowledge graphs.
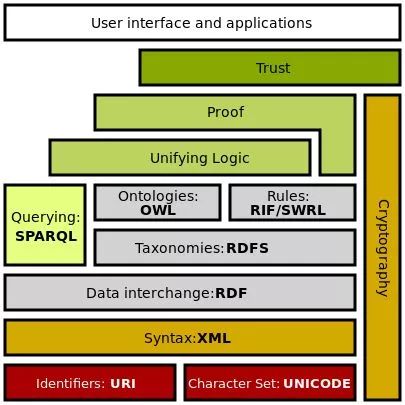
This article introduced the real need for knowledge graphs through the example of Ronaldo, then provided the definition and related concepts of knowledge graphs, and introduced the RDF formal representation of knowledge graphs. As a popular science article, many technical details were omitted. In the future, I will introduce the specific technologies needed in the process of implementing knowledge graphs based on the Semantic Web Stack (as shown in the image below). Additionally, I may combine practice to introduce how to use data from relational databases to construct a knowledge graph and set up a simple knowledge graph-based question-answering system (KBQA).
Reference Links:
W3C: RDF 1.1 Concepts and Abstract Syntax
https://www.w3.org/TR/rdf11-concepts/
Exploiting Linked Data and Knowledge Graphs in Large Organisations
Google: Introducing the Knowledge Graph: things, not strings
https://link.zhihu.com/?target=https%3A//googleblog.blogspot.co.uk/2012/05/introducing-knowledge-graph-things-not.html
Blog: Problems of the RDF model: Blank Nodes
https://link.zhihu.com/?target=http%3A//milicicvuk.com/blog/2011/07/14/problems-of-the-rdf-model-blank-nodes/
Blog: Compound Value Types in RDF
https://link.zhihu.com/?target=http%3A//blog.databaseanimals.com/compound-value-types-in-rdf
Chen, L., Zhang, H., Chen, Y., & Guo, W. (2012). Blank nodes in rdf. Journal of Software, 7(9).
https://link.zhihu.com/?target=https%3A//www.researchgate.net/publication/276240316_Blank_nodes_in_RDF

If you liked this article, or want to see more similar quality reports, remember to leave me a message and give me a thumbs up!