Guest Speaker: Chen Qi, Senior Algorithm Expert at Meituan
Editor: Mao Jiahao, Ping An Insurance Zhejiang Branch (Intern)
Produced by: DataFunTalk
Introduction:The knowledge graph shines in various industries due to its ability to describe knowledge and the relationships between everything in the world using graph models. Meanwhile, knowledge graph technology also brings new challenges and opportunities to scenario-based search. Against this backdrop, the Meituan team has undergone a new round of technological innovation, applying knowledge graph technology to the understanding of hotel and travel scenarios. This sharing is titled “Application of Knowledge Graph in Meituan’s Search for Hotel and Travel Scenarios” and mainly introduces:
-
Characteristics of Hotel and Travel Business
-
Understanding of Hotel and Travel Scenarios
-
Hotel and Travel Knowledge Graph
-
Search Solutions Based on Scenario Understanding
01
Characteristics of Hotel and Travel Business
When you mention Meituan, what comes to mind? Takeout, food, movies?

In fact, Meituan offers more than that, including a hotel and travel business that also ranks at the top of the industry!
What distinguishes the hotel and travel business from other local life services provided by Meituan? The difference lies in the larger travel radius of the hotel and travel business. Most of Meituan’s services, such as script killing and movies, only need to find merchants that meet users’ needs within the current area or city. However, for the hotel and travel business, users have a larger travel radius. Here are three examples that better explain the characteristics of the hotel and travel business:
A user from Beijing wants to ski or go to the beach. The user may choose the higher-quality Chongli ski resort, which is over 200 kilometers from Beijing; for the beach, since there are no corresponding supplies in Beijing, the user may go to Beidaihe in Qinhuangdao. Therefore, for services that do not have corresponding supplies locally, users may go to nearby cities that offer such services or even look for cities across the country that provide corresponding services. At this time, Meituan needs to search for and filter suitable scenarios and matching merchants for users.
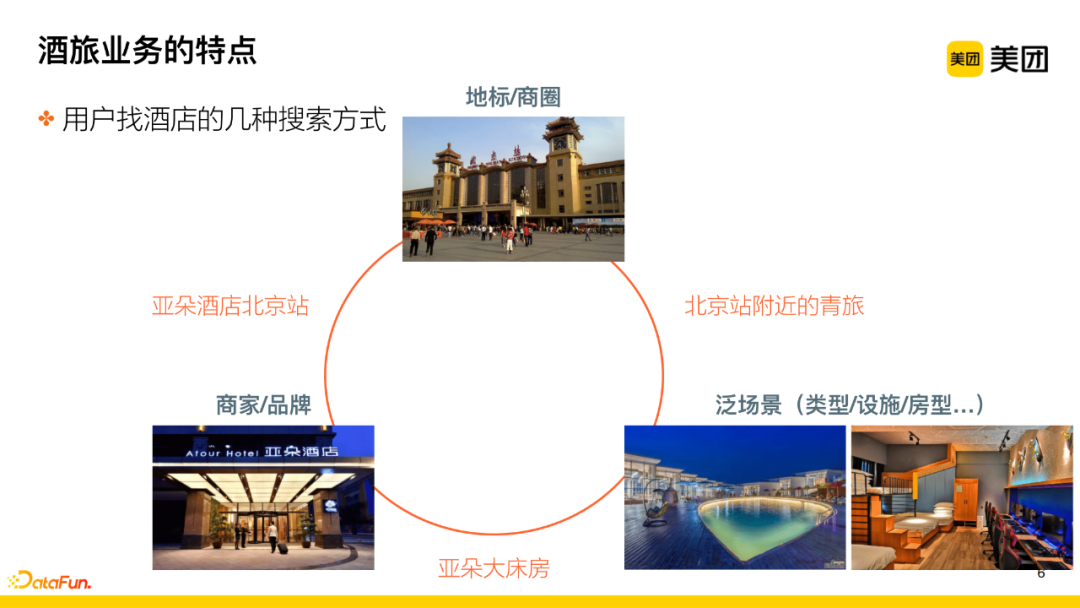
Taking hotels as an example, here are several common search methods used by users:
① Landmark/Business District. Users search for hotels around landmarks or business districts, which tends to lean towards recommended questions;
② Merchant/Brand. These users have clear goals, searching for a specific hotel or hotels under a corresponding brand;
③ General Scene Search. For example, users look for a type of merchant such as a youth hostel, hotels with certain facilities, or specific room types like e-sports rooms, etc. Other search methods mainly expand around these three combinations of searches.
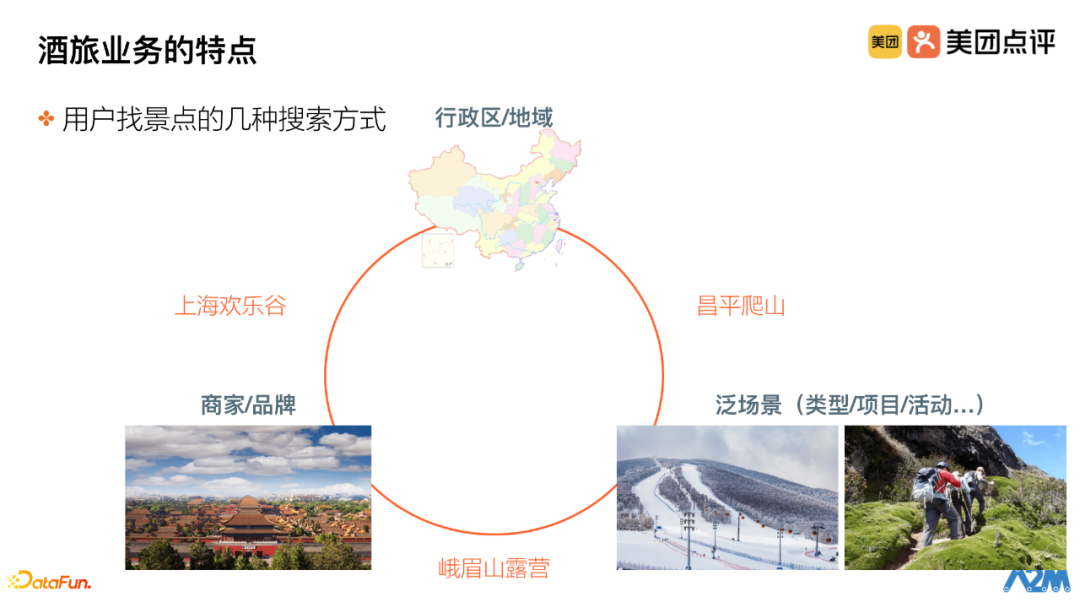
Attraction searches can also be divided into three main methods:
① Administrative Region/Area. Users search for attractions in a specific area or administrative region, and Meituan needs to find relevant attractions within that area;
② Merchant/Brand. These users also have clear goals, directly searching for the names of specific attractions such as the Forbidden City, Happy Valley, etc.
③ General Scene Search. Users look for a type of need, such as skiing or climbing, where multiple attractions with similar attributes, services, or types can meet the user’s needs. In this scenario, Meituan needs to make better recommendations for users.
02
Understanding of Hotel and Travel Scenarios
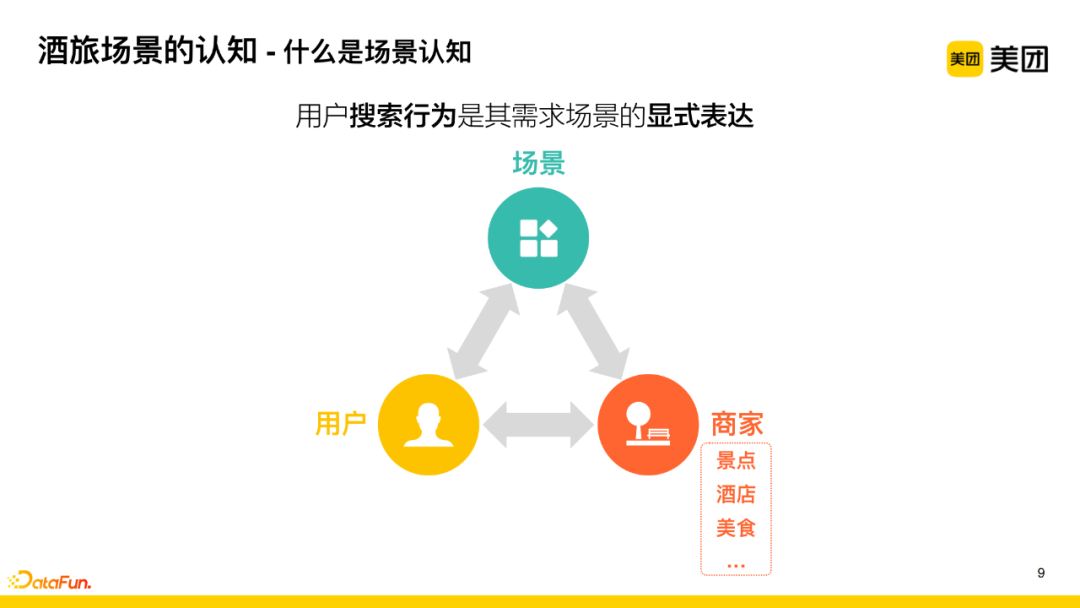
1. What is Scenario Understanding
There are many different types of merchants on the platform, such as hotels, attractions, and food. When users initiate a search on the platform, we believe their search behavior is an explicit expression of a demand scenario, which can be understood through the contextualization of user search behavior to identify the user’s demand scenario. After expressing the user’s demand scenario through tags, we can perform merchant tag retrieval, thereby matching users with merchants that can meet their needs.
2. Why Do Scenario Understanding
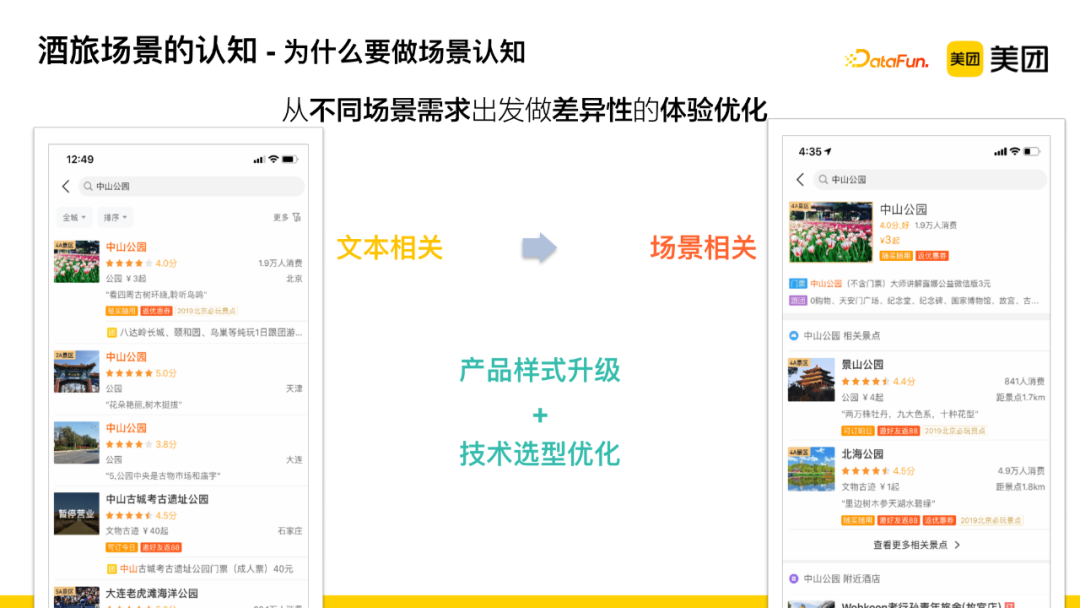
Why do scenario understanding? — We hope to optimize experiential differences based on different scenario demands.
For example, when searching for “Zhongshan Park”: the original search solution would recall text-relevant results from a textual perspective, but this does not meet users’ needs. Through analyzing user behavior data, we found that most users initiating a search for “Zhongshan Park” in Beijing often take subsequent actions around the local Zhongshan Park and its surrounding scenarios.
This essentially represents a type of user demand scenario. To better meet this demand scenario, we adopt the recommendation method shown on the right side of the diagram. First, we identify the main point users are searching for, and then recommend other services around this main point, such as related attractions, nearby food, etc., to better meet users’ diverse needs and provide more decision-making information through this main point template style.
This change in demand provides us with new problem-solving ideas:
-
To meet users’ diverse needs through product style upgrades;
-
With the transformation of product styles, it triggers a new round of technological upgrades.
3. What Are the Scenarios
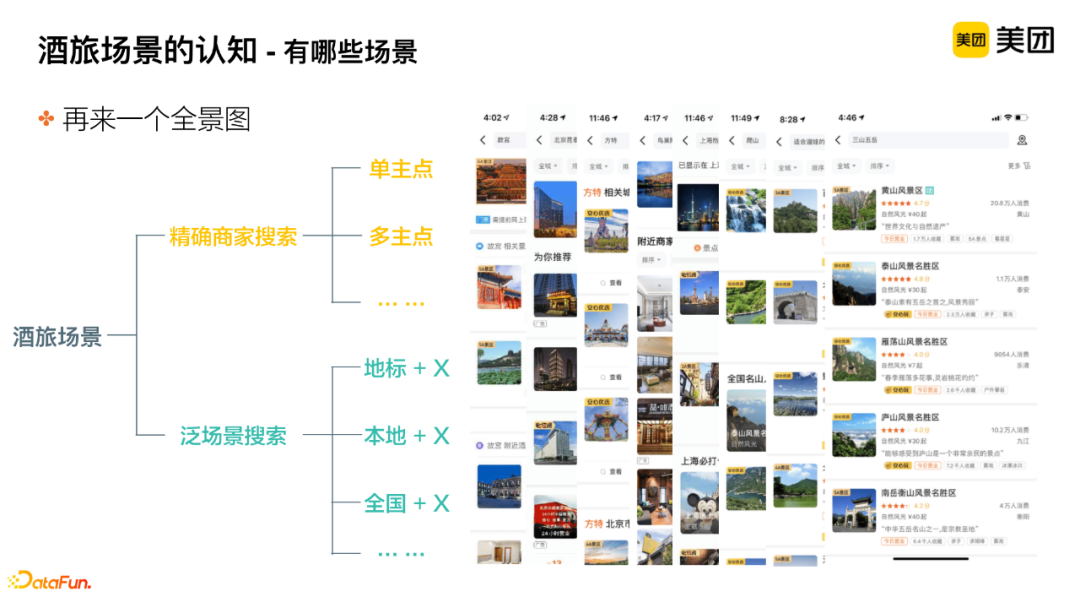
For the hotel and travel business, scenarios can be broadly divided into two categories: precise merchant search and general scenario search.
(1) Precise Merchant Search
Precise merchant search can be specifically divided into:
-
Single Main Point Search, such as the Forbidden City or Beijing Kun Tai Hotel, which only has a unique corresponding main point, allowing recommendations for services and merchants around that main point.
-
Multiple Main Points Search, such as Fantawild. There are multiple Fantawild amusement parks nationwide, so we can use a multiple main point style to provide information to users.
(2) General Scenario Search
General scenario searches can be specifically divided into:
-
Landmark + X, such as “Youth hostels near the Bird’s Nest,” where we need to recommend youth hostels near the main point of the Bird’s Nest;
-
Local + X, for example, searching for “climbing” under the city page of Beijing, where we need to recommend merchants within the local and surrounding areas that can meet users’ demand scenarios;
-
National + X, such as searching for the Five Great Mountains, where we need to help users recall results that meet their scenario needs from all over the country.
4. Where is the Difficulty in Scenario Understanding
The fundamental issue is that understanding demand scenarios relies on a significant amount of underlying domain knowledge. Basic structured data does not carry scenario expressions, thus requiring additional excavation and understanding. For example:
(1) Searching for He Shen’s Mansion. Searching for He Shen’s Mansion should yield the Prince Gong’s Mansion as a point of interest (POI), so we need to excavate that He Shen’s Mansion is an alias for Prince Gong’s Mansion;
(2) Searching for a quiet hotel. This search is a general scenario search. First, we need to conduct knowledge excavation on the hotel in the B-end to determine whether the hotel has good soundproofing characteristics. Secondly, we need to accurately associate the online query with existing B-end knowledge, for example, the expression “quiet” maps to the underlying knowledge tag “good soundproofing.”
03
Hotel and Travel Knowledge Graph
1. Construction of the Hotel and Travel Knowledge Graph
The Meituan hotel and travel knowledge graph covers approximately 800,000 hotel and travel merchants, 100 million user reviews, accumulates 1 million atomic concepts, and combines into 1.5 million demand concepts, along with 12 million associations between merchants and concepts.

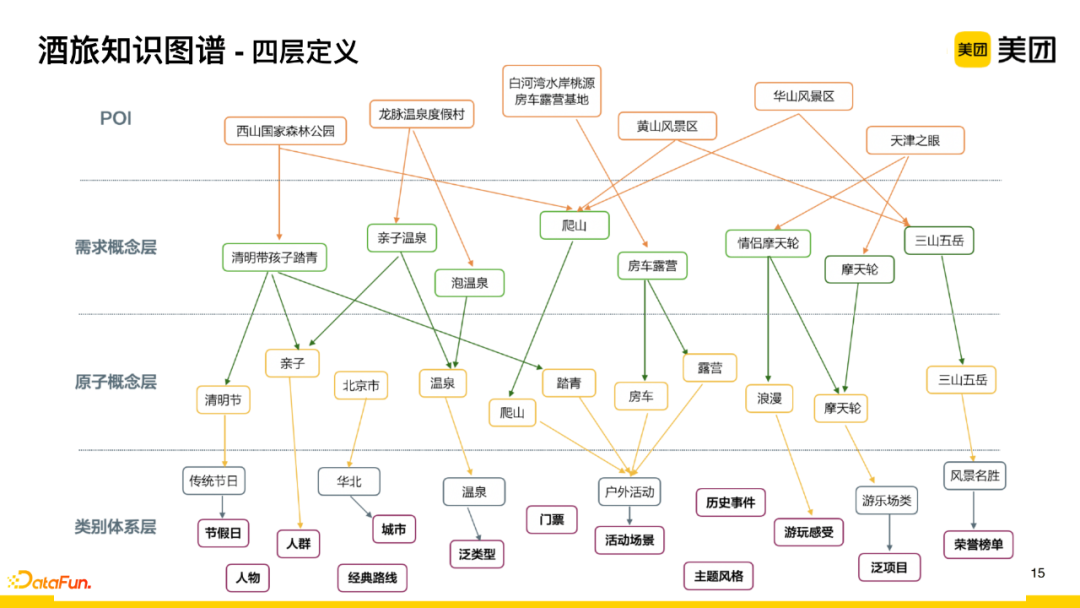
(2) Four-Layer Definition
During the application of the graph, based on user demand application dimensions, the graph is divided into four layers:
-
Category System Layer: Divided into categories based on different business characteristics. For tourism, for example, 15 primary categories are defined, and on this basis, secondary and tertiary specific category systems are further split;
-
Atomic Concept Layer: Extracted from user reviews and merchant information;
-
Demand Concept Layer: Filtering the data from the atomic concept layer and combining it according to semantic dimensions, building concept layer data aimed at search needs. For example, the atomic concept layer includes climbing, which has a directly mapped label in the demand concept layer, while for two independent semantics like family and hot spring, when there is a real user demand scenario, a more accurate dimension label of “family hot spring” will be combined. This solves the semantic drift issue that occurs when online search queries only use the most granular atomic tags for recall. Therefore, when costs allow, adopting a combination-based demand concept layer will yield better results.
-
POI Layer: Determines whether the current merchant possesses the attributes and characteristics represented by the demand concept layer tags or knowledge.
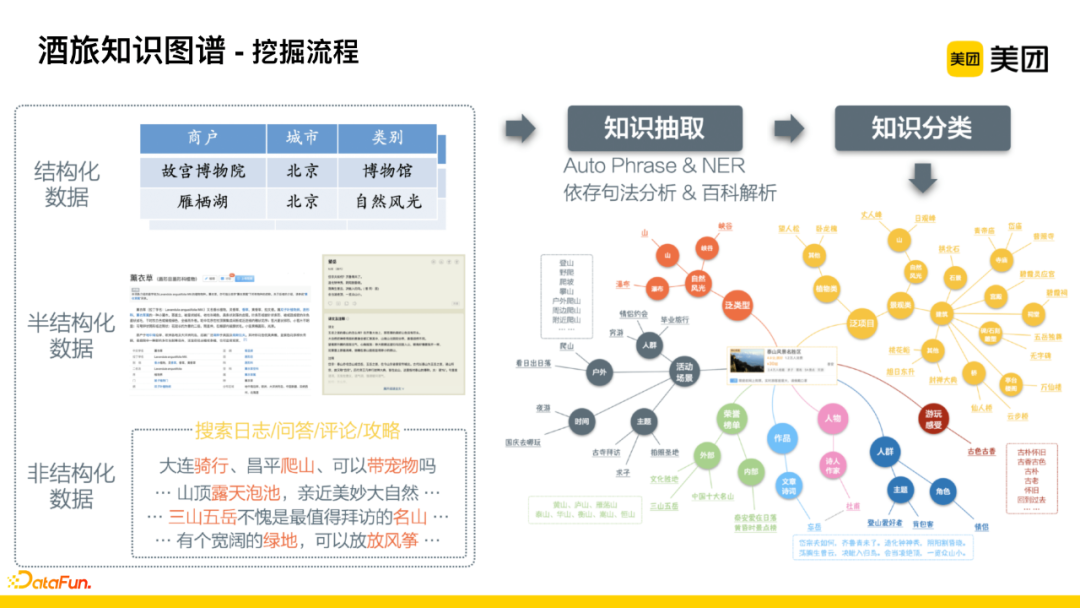
The data sources mainly include three types: structured data, semi-structured data, and unstructured data. Knowledge extraction is performed from these data sources. When there is insufficient labeled data in the early stages, semi-supervised methods such as Auto Phrase and dependency syntax analysis are adopted; after accumulating knowledge, NER methods are used for better extraction.
Knowledge segments are classified according to the previously mentioned three-level knowledge system. The following diagram shows the categories related to the Taishan Scenic Area and the knowledge segments associated with the lowest level. For the Taishan Scenic Area, the lowest-level data only includes natural scenery, but we hope to understand its semantics in finer detail, such as the types of natural scenery like canyons, waterfalls, mountains, etc. Additionally, we need to determine what activities are suitable for the Taishan Scenic Area from the perspective of the crowd, such as suitable for couples’ dates or graduation trips; from the perspective of scene events, suitable for outdoor activities like climbing and sunrise/sunset. This data can lay the foundation for subsequent understanding of queries, linking, and generating recommendations.
2. Practices in Key Steps of Graph Construction
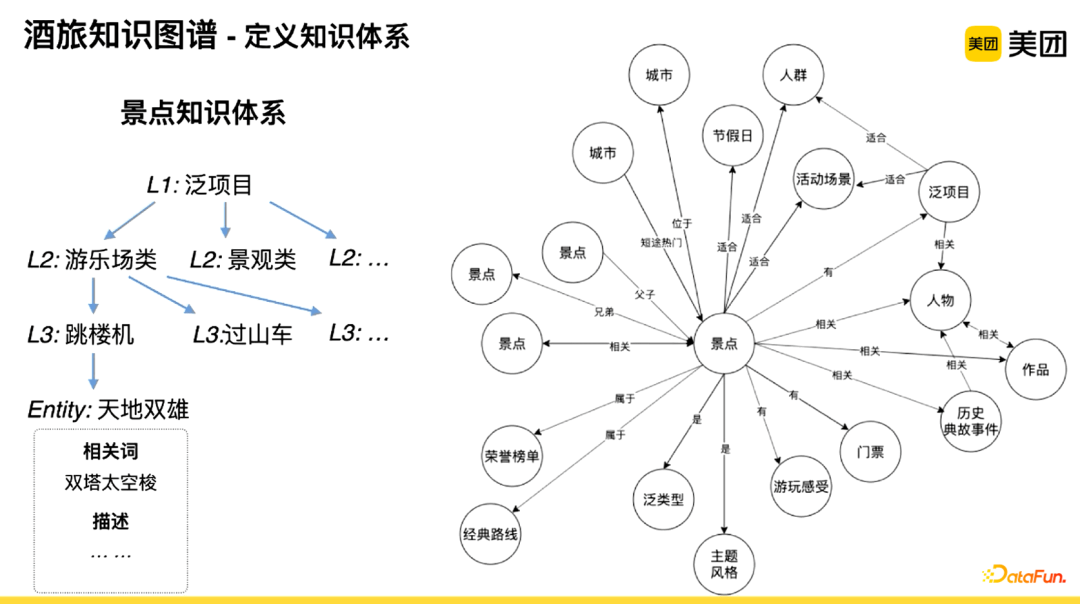
(1) Defining Knowledge System
When constructing a vertical domain knowledge graph, it is necessary to define the business in conjunction with domain knowledge. Taking attractions as an example, there are approximately 15 primary categories, each of which also has secondary and tertiary categories. The tertiary classification system can better meet search needs.
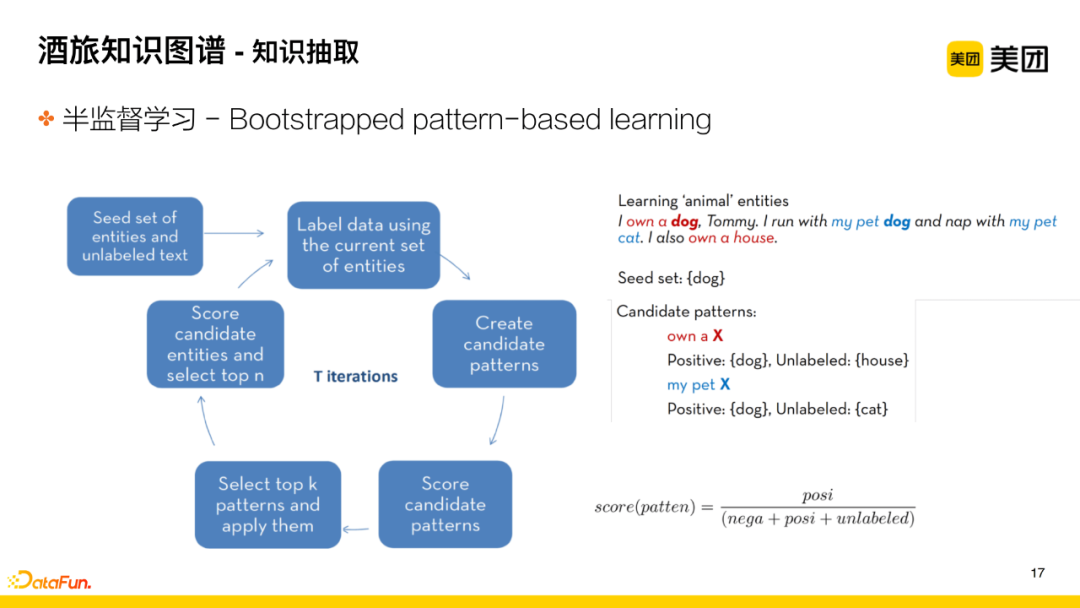
In the early stages of the business, a semi-supervised learning method, namely Bootstrapped pattern-based learning, is used to accumulate knowledge. For example, in the case of extracting animal-related entities, the general process is:
-
Step 1: Build seed entity words, in this case, dog;
-
Step 2: Extract patterns related to the entity word dog from the corpus, such as: own a, my pet;
-
Step 3: Further excavate entity knowledge segments matching the aforementioned patterns based on the candidate patterns: house, cat;
-
Step 4: Evaluate which of house and cat are similar to dog, belonging to the animal type.
After several iterations, it is found that for animal-related entity words, my pet is a better pattern, so this pattern is used to excavate and expand more entities. In the early stages, this method can quickly accumulate data.
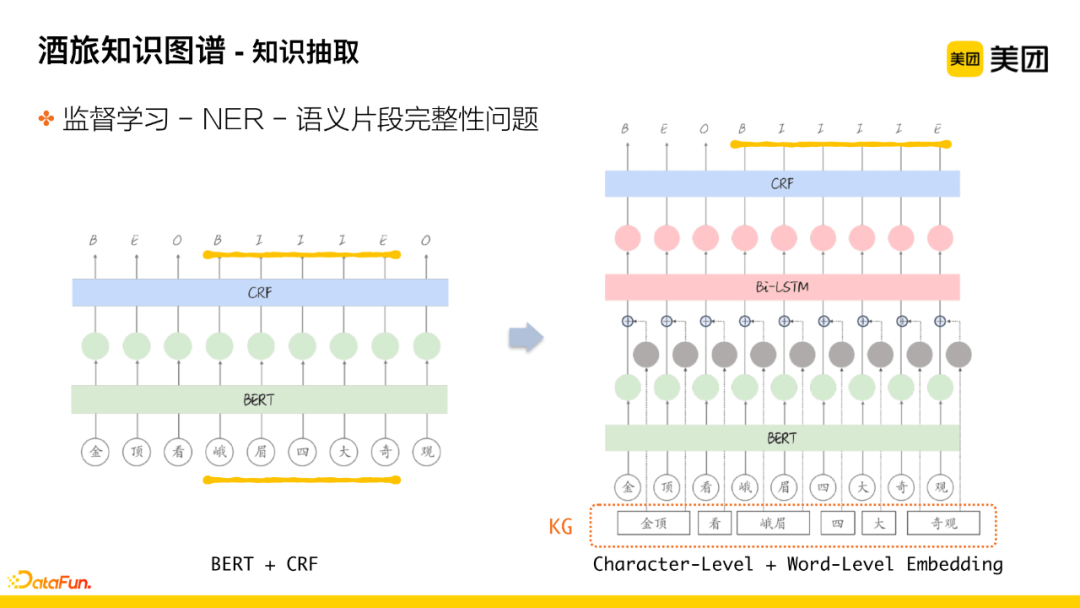
Once labeled data is available, supervised learning methods using NER can be employed for better generalization recognition. Initially, the BERT+CRF model was used for extraction, but this model tends to fragment the semantic segments of knowledge entities. As shown in the diagram, the comment “The golden peak looks at the four wonders of Emei” extracted is “Emei’s four wonders,” but we hope the segments can remain as complete as possible. Later, by introducing KG-related information, this issue was resolved. First, the text to be extracted is tokenized, while introducing two layers of vector information at the character-level and word-level to assist in determining the boundaries of segment splitting, effectively solving the problem of segment fragmentation.
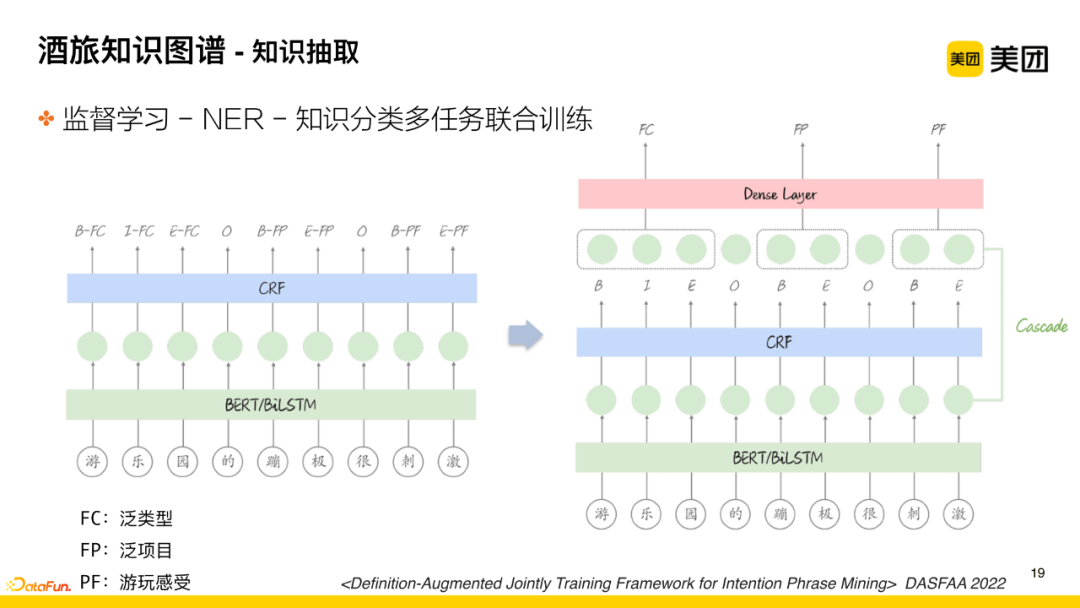
Initially, for efficiency, each of the 15 primary categories mentioned earlier was extracted separately. Later, to improve accuracy, related major categories were combined for comprehensive knowledge extraction. During this process, there may be inaccuracies in knowledge classification, and further optimization considers employing a multi-task joint training method, integrating the tasks of knowledge classification and NER.
The general idea is: After the first layer encoding (using BERT or BiLSTM encoding), the vector information is used for NER segmentation with traditional CRF, and then the vector information is introduced into the classification layer for identification and processing. This work significantly improves overall accuracy and recall (published in the 2022 DASFAA conference).
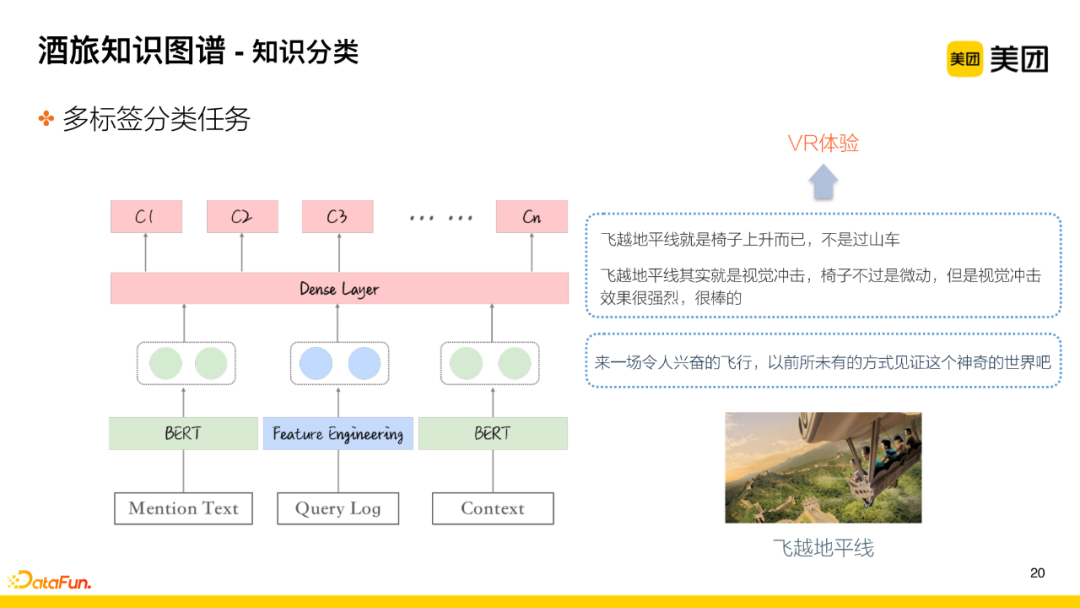
(3) Knowledge Classification
After the initial division of knowledge into primary categories, it is necessary to classify the knowledge into finer granularity. However, due to the characteristics of the business, many knowledge segments may belong to multiple secondary or tertiary category nodes, so a multi-label classification task is used for the original text classification segments. For instance, for the VR project “Fly Over the Horizon,” extracting the segment “Fly Over the Horizon” using BERT for encoding and direct recognition is likely to classify it as a roller coaster project, as expressions like “Fly Over XXX” often refer to roller coasters or other projects rather than the VR project.
To better solve this problem, after extracting this segment, the context information of the segment is introduced into the model to enrich the contextual expression. Simultaneously, feature engineering is performed on search logs and comment logs, adding manually constructed features and merging these features for unified classification, thus resolving the semantic shift problem caused by isolated texts.
(4) Associating Knowledge with Merchants
After extracting and classifying knowledge segments, it is necessary to solve the problem of associating knowledge (tags) with platform merchants.
First, it is important to clarify that this issue is not a closed-domain label problem but an open-domain label problem, meaning it is not merely a matter of classifying and mounting category systems, as tags will continue to accumulate and be added with the development and excavation of the business. Therefore, labeling needs to have a certain degree of generalization capability.
To explain this in relation to the platform: the platform’s main body is the merchants, and we need to find merchants that possess knowledge or tags. Merchants have many user reviews and associated products, and we can intuitively obtain the relevance of each review and knowledge as well as the relevance of each product to knowledge, reflecting the relevance to the merchants, with an additional layer of aggregation in between.
The solution to this problem is a multi-vote mechanism, where each piece of information hanging under the merchant is feedback from a user, judging whether it is relevant, irrelevant, or another viewpoint. By aggregating and voting on this information, we can determine whether the merchant possesses this knowledge or tag.
For example, determining whether a certain attraction allows pets:
-
Step 1: Find evidence, searching for textual expressions related to bringing pets;
-
Step 2: Determine the authenticity of the extracted short segment, mainly dividing it into positive relevance, irrelevant, and negative relevance;
-
Step 3: Multi-evidence fusion classification, in addition to the relevance obtained from previous evidence, abstracting many-dimensional feature information based on semantic features and statistical features, such as the textual relevance of the POI itself. This process mainly uses the BERT model for matching textual relevance.
-
Step 4: Distribution confidence determination, feeding the relevance obtained in the first two steps into a tree model to obtain a classification result, i.e., whether it is relevant.
If knowledge classification is done online, there are accuracy requirements, allowing for some loss in recall but ensuring that the results are accurate, thus providing users with a better experience online. Therefore, in the last step, a distribution confidence determination process is added, that is, conducting distribution statistics on the merchant category in the labeling results, filtering long-tail POIs. For instance, when users search for climbing, after category statistics, in cases of individual misjudgments, there may be a situation where the hot spring category accounts for 0.3%. Based on the threshold, this category of results will be filtered out.
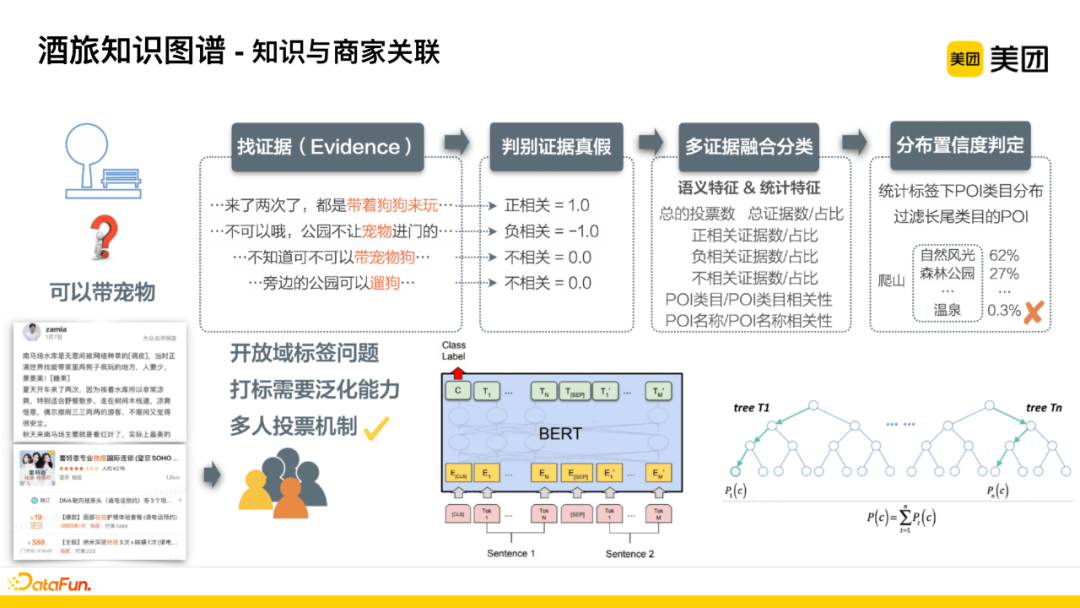
Whether in knowledge extraction or classification, the BERT model is used, and Meituan mainly uses its self-developed MT-BERT, which is characterized by incorporating a large amount of user comment information and business-related information under the Meituan business scenario to better adapt the model.

After incorporating Meituan’s UGC data, MT-BERT has shown significant improvements in some public datasets, internal query intent classification, and component analysis tasks.

04
Search Solutions Based on Scenario Understanding
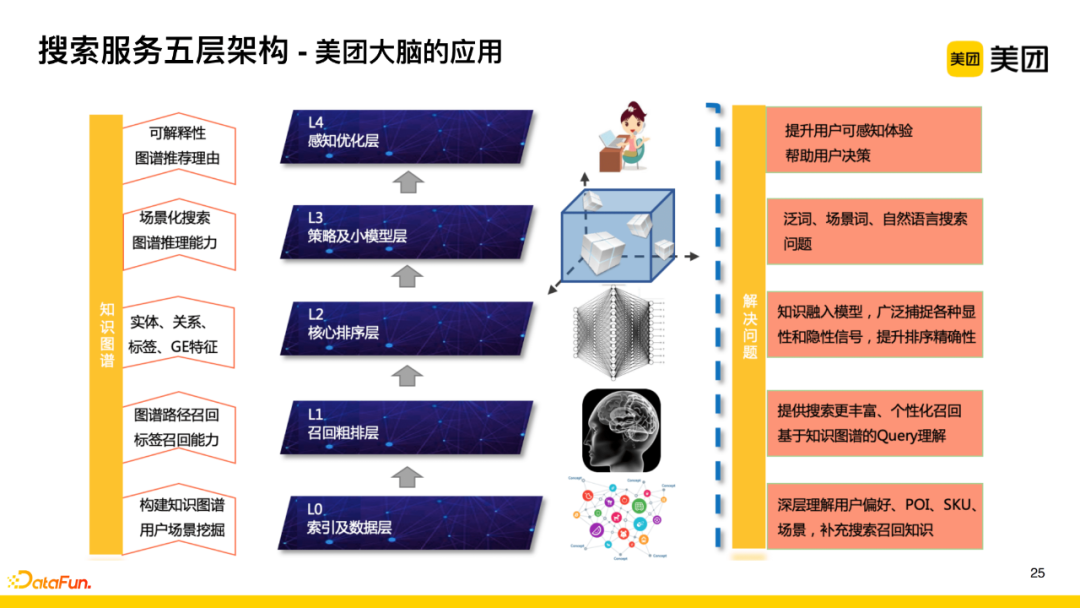
1. Five-Layer Architecture of Service Search
Service search is divided into five layers:
-
L0 Layer: Extract relevant knowledge and build an index;
-
L1 Layer: Identify and understand user queries, performing structured recall;
-
L2 Layer: Based on recall results, sort the list using deep learning models;
-
L3 Layer: Make targeted strategy adjustments in different business scenarios;
-
L4 Layer: Provide labels, recommended reasons, rankings, and other interpretable information when presenting the list, enhancing perception.
2. Solutions Under Two Categories of Search Intent
(1) Precise Merchant Search
Modeling the problem: First, identify the main point; second, recommend relevant merchants around the main point, including attractions and nearby hotels, etc. The second step is further subdivided: when users are in the planning decision phase, we can recommend alternative merchants to the main point; when users have determined to consume at a certain main point, we can recommend merchants that complement the itinerary.
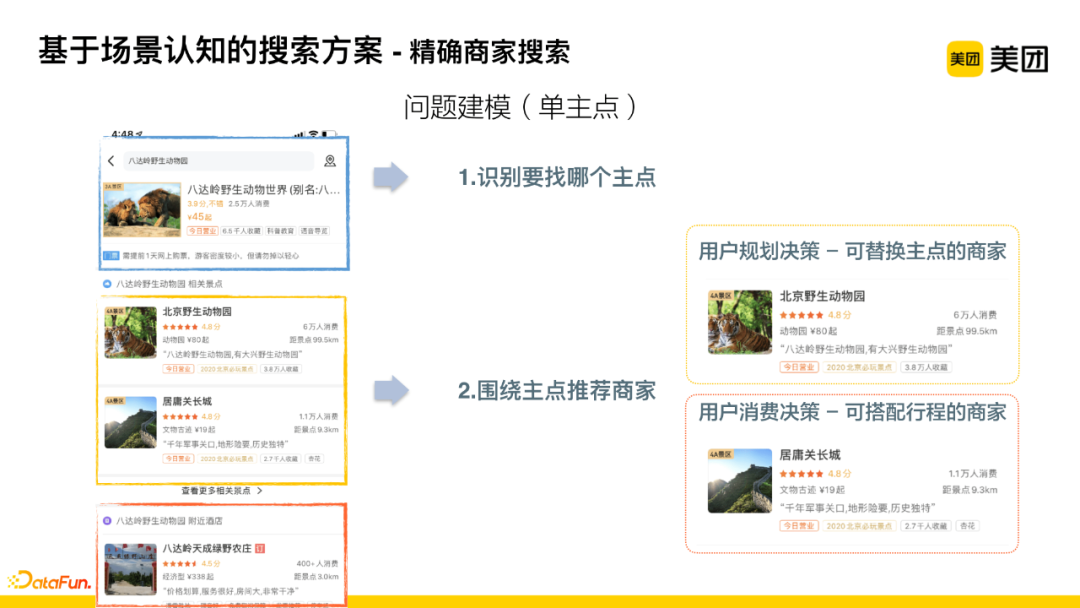
There are two technical points mentioned earlier:
-
How to identify the main point, internally referred to as merchant linking or a variant of main point linking, i.e., entity linking.
-
How to make better recommendations around the main point.
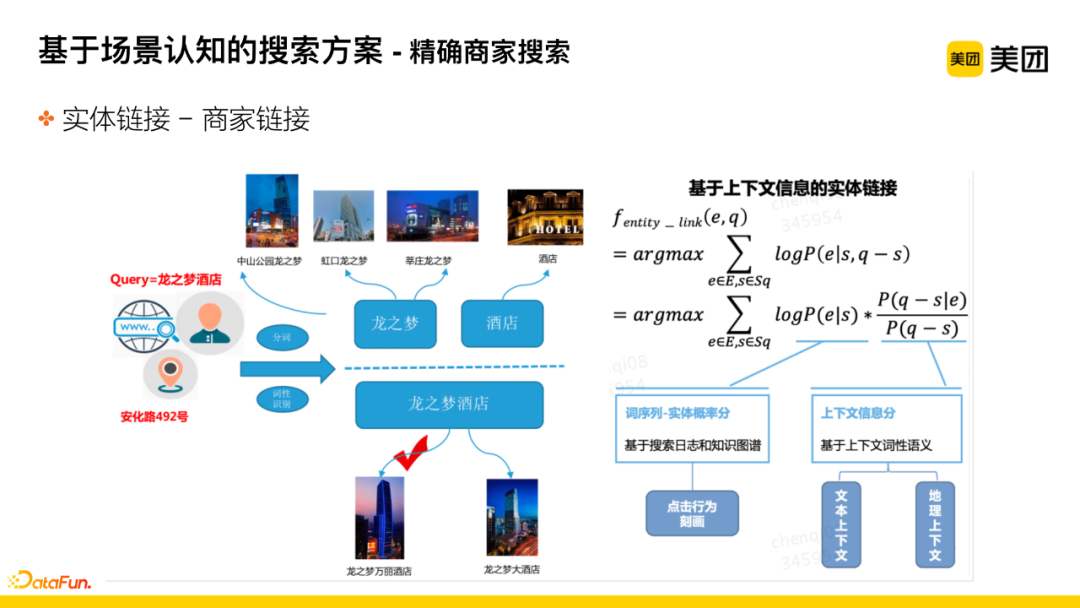
① Technical Point 1: How to Identify the Main Point
Using a context-based entity linking solution. The reason for using this solution is that in Meituan’s business, searching for the same query word in different geographical locations may yield different results. For example, searching for Longzhimeng Hotel near 492 Anhua Road, Shanghai, the user is likely looking for the Longzhimeng Hotel nearby.
The specific strategy is divided into two scores: The first score is the word sequence, i.e., the probability prediction score between the sequence segment that can currently link to a certain entity and that entity, obtained through search logs and knowledge graphs regarding the merchant’s alias expressions, to derive a comprehensive score; the second score combines contextual information, dividing the score into two parts: first, the semantic score of the textual context itself; second, the geographical context score, calculated based on the distance between the user and the merchant.
② Technical Point 2: How to Recall Better
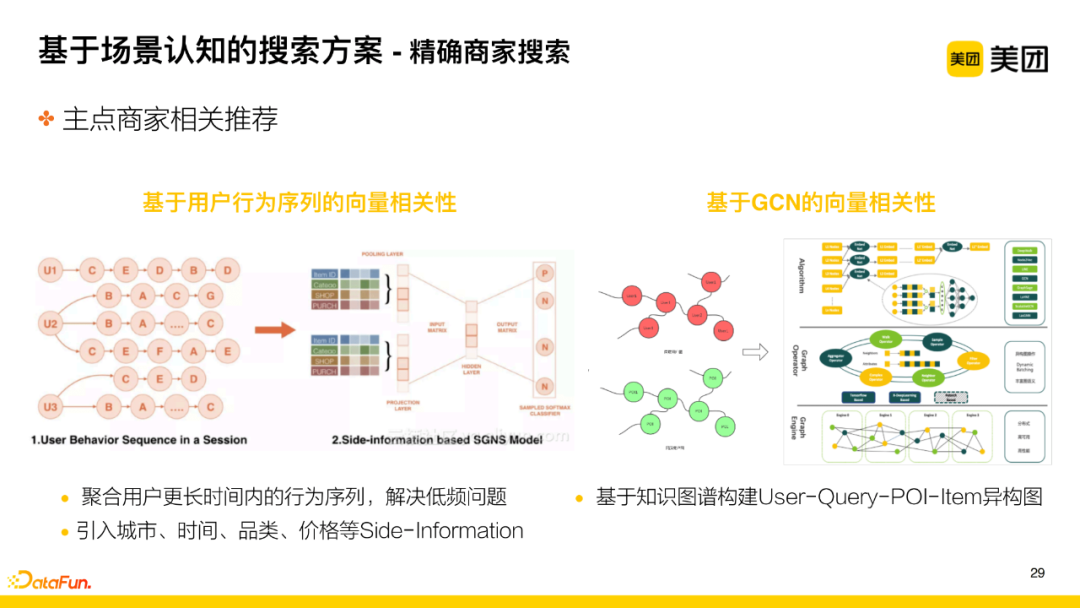
Two methods are used for recall:
-
Vector Relevance Based on User Behavior Sequence
All POIs clicked by users form a sequence, and the POI vector is encoded using skip-gram, then calculated against the main point’s POI vector to obtain similar head POIs. It is worth noting that we made targeted adjustments according to business characteristics: first, the hotel and travel business is relatively low-frequency, so we aggregate user behavior sequences over a longer time to address the low-frequency issue. Second, considering seasonal and geographical behavioral differences, we introduced side information such as city, time, category, and price to better calculate vector relevance.
-
GCN-based Vector Relevance
Each POI has relevant knowledge, and we constructed a User-Query-POI-Item (knowledge) heterogeneous graph to obtain the POI vector through graph learning methods.
(2) General Scenario Search
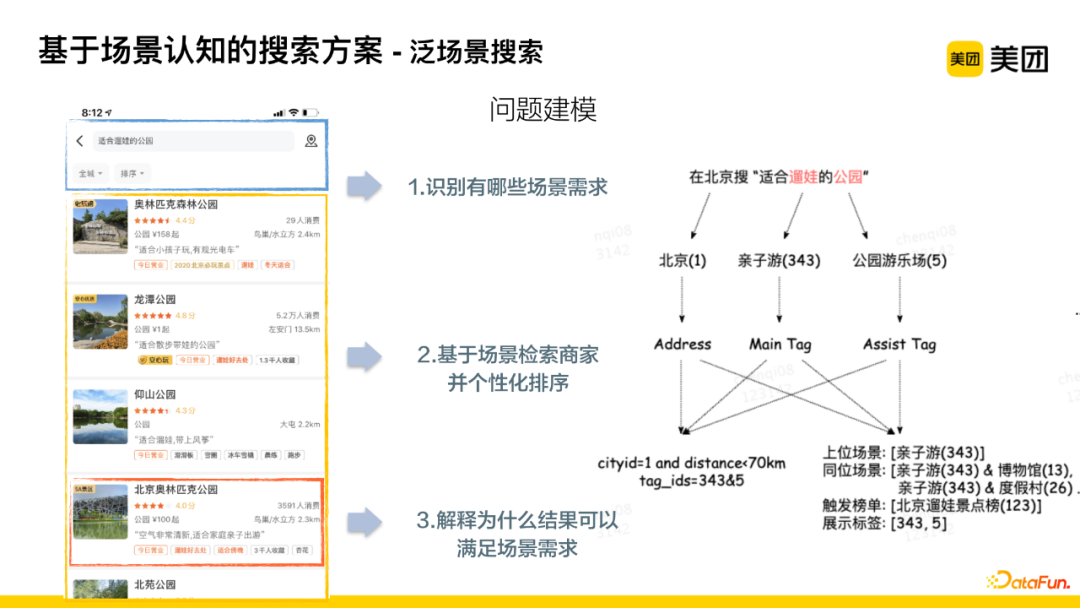
Modeling the problem: First, identify what scenario needs exist; second, retrieve merchants based on scenarios and personalize sorting; finally, explain why the results can meet scenario needs.
For example, searching for “parks suitable for walking kids” in Beijing means finding the area of Beijing, where different text segments in the query will link to different tags, and there exists a hierarchy between tags, allowing for inference of upper-level scenarios, lateral scenarios, triggered rankings, and tags that need to be displayed, ultimately forming the recall grammar for subsequent processing.
General scenario search involves three main technical points:
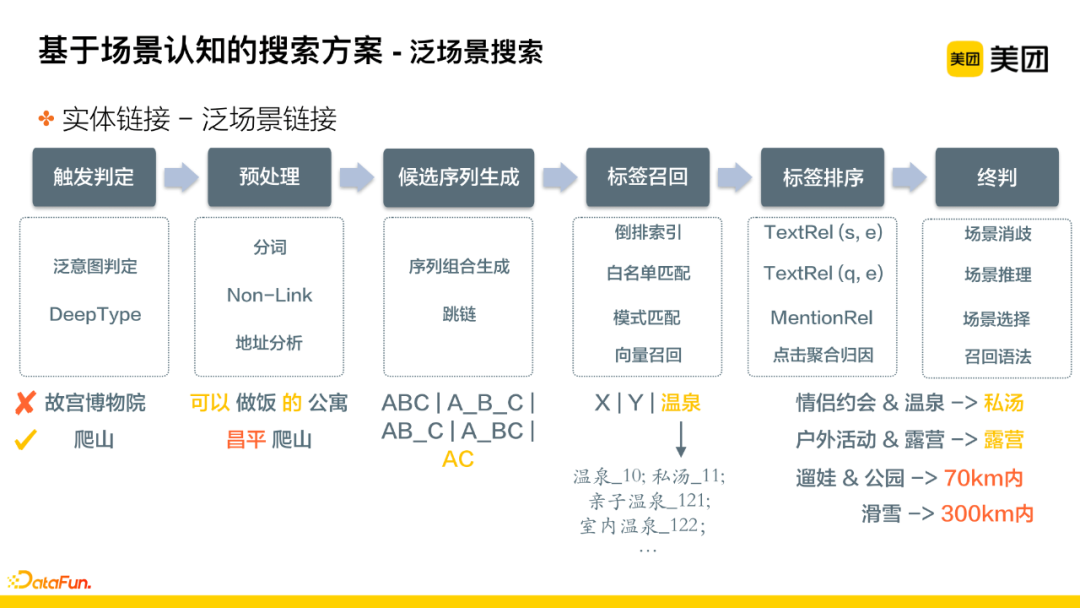
① Technical Point 1: General Scenario Linking
Identifying the query, i.e., linking to scenario tags. This process is conducted online and is divided into six steps:
-
Step 1: Trigger determination, assessing whether the current query is of the general scenario search type. For instance, the Forbidden City is precise search, while climbing is general scenario search. This step also needs to identify related intents, such as determining whether the search intent is for attractions, hotels, or dining, etc.;
-
Step 2: Preprocessing the query, including tokenization, Non-Link, and identifying the target area;
-
Step 3: Generating a candidate sequence from the processed segments for multiple combinations, which may involve jump chain techniques. For example, given existing segments A, B, and C, several sequences such as ABC, AB_C, A_B_C, and AC may be generated;
-
Step 4: Using the generated sequences for inverted index recall, which includes whitelist matching, pattern matching, vector recall, etc., to expand related tags;
-
Step 5: Tag sorting, categorizing the recall results based on several important features, including the relevance of the current entity and sequence, the relevance of the query and entity, mention information, and statistical features after click aggregation attribution, mixing these for classification, selecting top N tags for application in different businesses;
-
Step 6: Final determination stage, disambiguating and inferring the identified multiple segments linked to different tags.
② Technical Point 2: Sorting
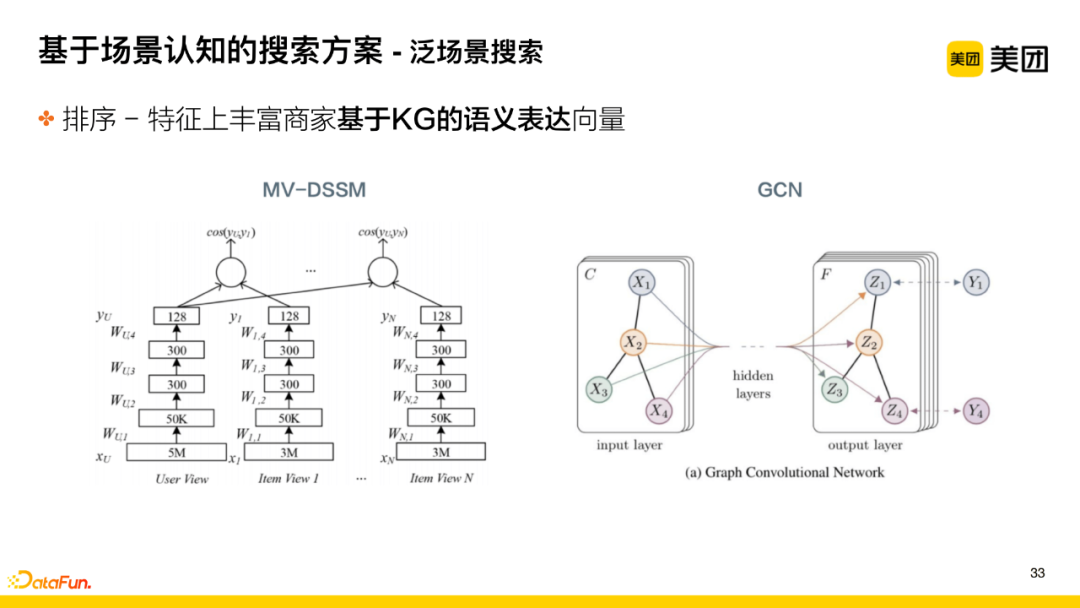
This technical point considers how to better perform personalized sorting based on scenario-type searches. General search expressions lack semantic relevance in terms of POI name dimensions, so it is necessary to supplement knowledge dimension information in the model.
First, at the feature level, enrich the merchant’s semantic expression vector based on KG using the following methods:
-
Based on multi-domain structure, introduce textual information of tags;
-
Use GCN structure to train vectors between POIs and queries, incorporating these vectors into subsequent models.
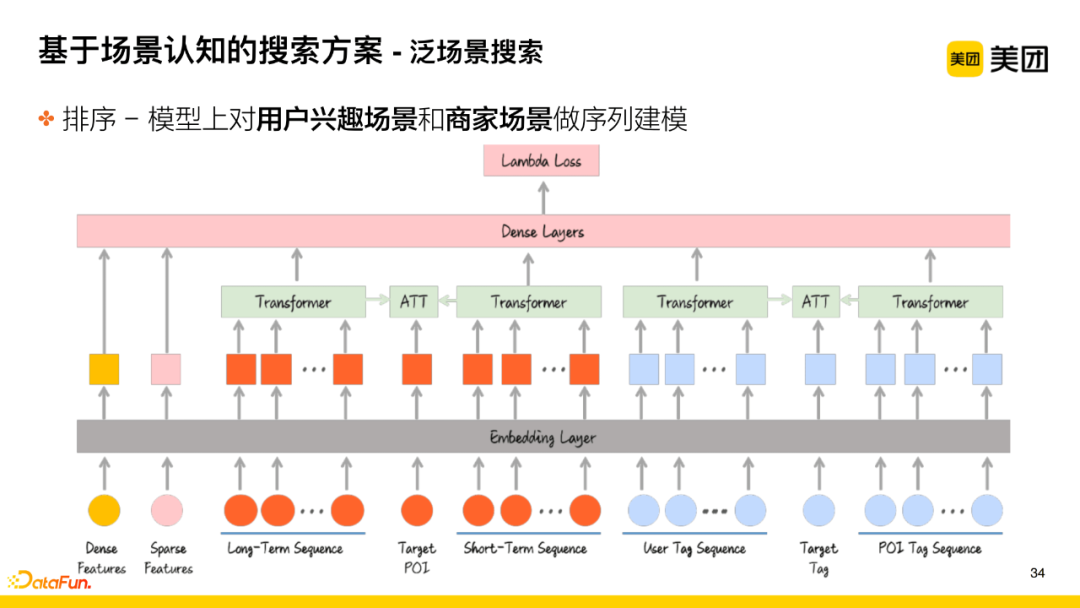
Second, in the model structure, perform sequence modeling of user interest scenarios and merchant scenarios. The innovations in this work include:
-
The current POI being sorted and the user’s long-time sequence and short-time sequence attention work, where long-time sequence and short-time sequence refer to the lists of POIs clicked by users over a longer and shorter time, respectively;
-
Incorporating a sequence of tags. The tags identified for the current user’s demand scenario are aggregated with the tags of merchants with which the user has previously interacted, forming a sequence; the tags of the POIs themselves also carry knowledge information as a sequence, and encoding these two sequences for attention work can better capture the relevance between the user’s demand scenario tags, merchant scenario sequences, and user interest sequences in general scenario searches.
③ Technical Point 3: Result Interpretability
This technical point considers how to better explain to users why the current results are relevant to the search scenario. Part of this issue is realized through recommended reasons. There are two implementation methods for recommended reasons: extractive recommended reasons and generative recommended reasons.
-
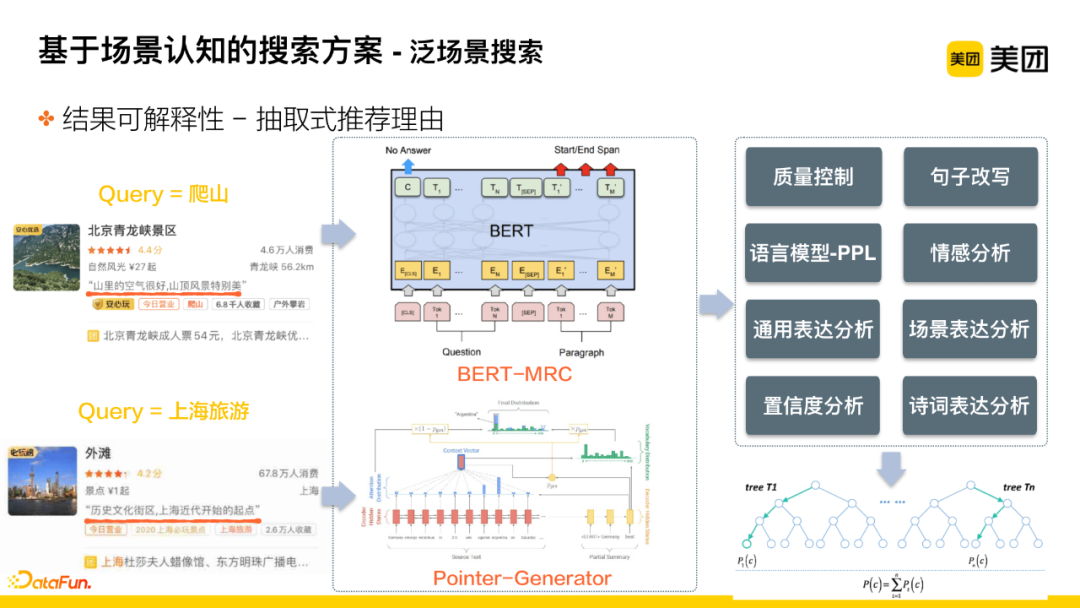
Extractive Recommended Reasons
This method extracts relevant recommended reasons through extraction, which can be divided into two major scenarios:
The first category, such as searching for “climbing.” This type of query belongs to a specific scenario, and we hope to provide users with recommended phrases directly related to the scenario, i.e., expressions from other users about the suitability of that location for climbing. For this type of recommended reason, text matching combined with BERT-MRC thinking is used to recall candidate sentences.
The second category, such as searching for “Shanghai tourism.” The range of this type of query is relatively broad, so in this scenario, the default characteristics of the attractions will be recommended to users, i.e., recommended phrases that directly represent the characteristics of the merchants, using a combination of short sentences and the pointer-generator network extraction approach to generate candidate sentences.
Once candidate recommended phrases are generated, whether they are user-generated or merchant-generated, they will all enter a determination module for quality assessment, including sentence rewriting, fluency of expression, emotional expression, etc. Through these modules, a multi-dimensional score is obtained, which is finally fed into the tree model for overall quality assessment, resulting in a final score.
-
Generative Recommended Reasons
Extractive recommended reasons can solve most issues, but there are also some problems:
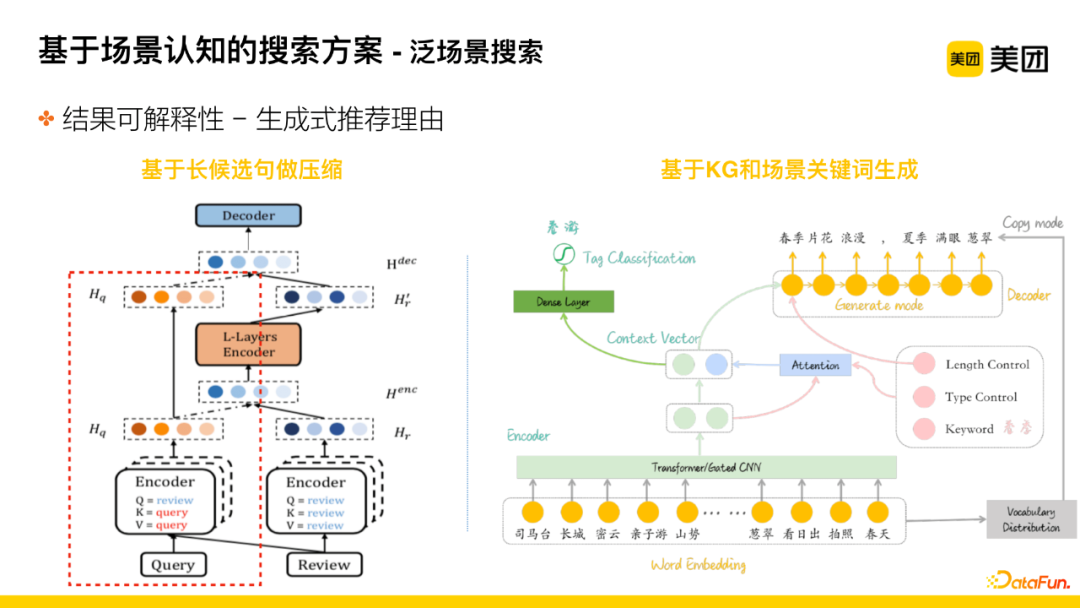
The meaning of the sentence is correct but too lengthy, and there are length limitations when displaying sentences to users on the front end. Therefore, to better utilize lengthy sentences or sentences that are correct in meaning but poorly expressed or lacking highlights, a transformer-based network structure is adopted to compress certain sentences to comply with sentence length restrictions.
Moreover, many POIs have relatively few comments, and the quality of user expressions is poor, and since we maintain strict control over the overall quality of recommended phrases, this often leads to a lack of recommended phrases related to scenarios.
At this point, we consider generating recommended phrases based on existing knowledge of merchants to expand data. This approach is implemented based on KG and scene keywords. There are two key points to illustrate: first, “Simatai Great Wall” has related tags in the Word embedding layer; second, controlling tags to generate related recommended phrases based on the “spring outing” tag. By comprehensively encoding these two dimensions, the generated segment is obtained, with the encoder outputting “Spring blossoms romantically, summer is lush.” This sentence undergoes the quality assessment mentioned earlier. This method supplements recall and ultimately produces offline candidates for final recommended phrases.
The above describes the relevant candidates for generating recommended reasons in the offline phase, whether extractive or generative. Once deployed online, it will also involve the distribution of specific online traffic. That is, when the list contains content that meets user scenario needs, further considerations include: first, the relevance of the recommended phrases to the query; second, the recommended phrases in the list should not be overly homogenized, requiring a mix of diverse expressions; lastly, maintaining content novelty, etc.

Overall, from the underlying data layer to the upstream display layer, the overall architecture is divided into many layers, specifically structured as follows:

Thank you all for today’s sharing.
At the end of the article, please share, like, and follow for a triple hit~
01/Guest Speaker
Senior Algorithm Expert at Meituan Search and NLP Department
Graduated with a master’s degree from the Institute of Computing Technology, Chinese Academy of Sciences in 2015, joined Meituan in the same year, participated in the construction and technological evolution of hotel and travel search from 0 to 1, possesses strong business modeling capabilities, and currently serves as the technical head of scene search and tourism search direction, mainly focusing on the implementation and algorithm optimization of technologies such as semantic understanding, knowledge graphs, data mining, and deep learning ranking in business scenarios.
02/Special Electronic Book, Limited Time Free

03/Sign Up for Live Broadcast, Get PPT for Free

DataFun: Focused on sharing and communication of big data and artificial intelligence technology applications. Launched in 2017, has held over 100+ offline and 100+ online salons, forums, and summits in cities such as Beijing, Shanghai, Shenzhen, and Hangzhou, inviting over 2,000 experts and scholars to participate in sharing. Its public account DataFunTalk has produced over 800 original articles, with over a million readings and more than 150,000 precise followers.
🧐 Share, Like, Follow, give a triple hit!



