Author: Huang Chongyuan
“Data Insect Nest”
Total 23138 words
Cover image ssyer.com

“ In recommendation systems or computational advertising, ReRank blatantly disrupts the sequence generated by recall, coarse ranking, and fine ranking, yet claims to act in the greater interest. This is a very interesting phase of the algorithm, full of fun and, of course, challenges. ”
In the entire recommendation system or computational advertising, ReRank is not as well-known as ranking. Even the recall phase preceding it is more familiar to people, let alone the further breakdown into coarse and fine ranking phases.
This unfamiliarity is reflected in the ongoing accumulation of model papers and the core role it plays in business logic. The former can be seen in the proportion of content in the re-ranking field in various journals, which is clearly neglected compared to ranking and recall. The latter is that even among practitioners in the field of recommended advertising, the true significance of re-ranking in the entire system may not be clearly articulated; most may only stop at user experience and diversity, which is far from sufficient.
But should it be treated this way? Theoretically, it should not, especially in an era where traffic dividends are peaking, and homogenization is severe, as everyone digs into the value of existing traffic. It will become increasingly important. The value it generates and its role throughout the entire chain are worth our deep consideration; its technical logic and business logic are also more interesting and challenging than we might imagine.
Thus, the theme of this article is re-ranking, a seemingly simple but actually very interesting and important phase of algorithm application.
Therefore, this article will include a breakdown of the positioning of the entire recommendation advertising algorithm chain, an in-depth discussion of ranking and re-ranking, a breakdown of the underlying technical logic of re-ranking, as well as the current state of re-sorting unique to the advertising field and the problem-solving ideas to break through its pattern. Each chapter is interrelated, progressing layer by layer, combining business and technical points, allowing readers not only to understand the business scenarios of re-ranking but also to fully grasp why it should be done and how, ultimately hoping to extend to how to do it in their own business scenarios.
When discussing re-ranking, one cannot avoid the entire algorithm chain’s position where re-ranking is located, its dependence on preceding stages, and the positioning of different algorithm phases.


01
Endless Ranking: The Complex Algorithm Chain
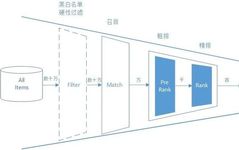
Regarding the entire algorithm chain of recommendation systems or computational advertising, let’s look at the diagram directly.
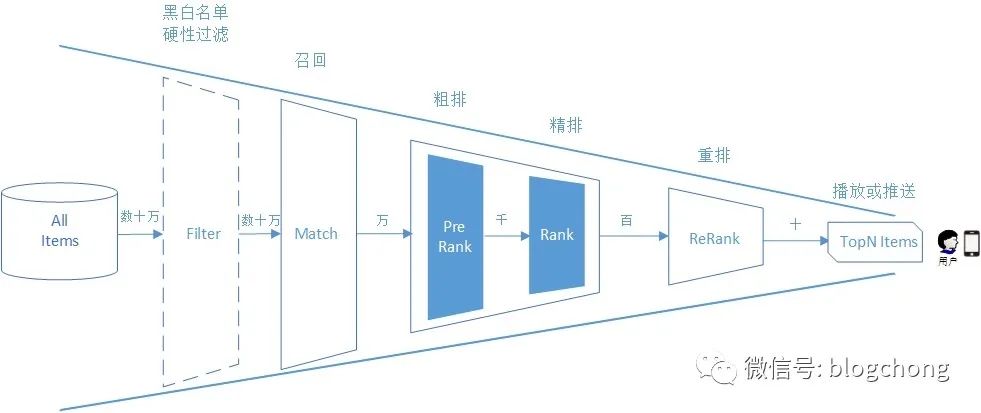
Figure 1: Recommendation Advertising Algorithm ChainFigure
As shown, we do not specifically distinguish between recommendation systems and computational advertising; we observe the entire algorithm chain’s construction from the perspective of item candidate reduction triggered by user recommendations or ad triggers.
The starting point is tens of thousands, even millions of candidate items, such as product SKUs, while the endpoint is several final recommended items, such as several displayed items in a recommendation system, whereas the advertising playback scenario may ultimately only take the Top 1 ad for user playback.
The number of items ranges from tens of thousands to tens, going through some hard condition filtering to directly eliminate candidates that do not meet the criteria, then entering the candidate recall phase, reducing candidates to the level of thousands, and finally outputting hundreds of sequences after fine ranking, which are then rearranged through ReRank, ultimately truncated based on the application scenario to Top N or Top 1.
The entire process, taking information flow as an example, is included in the underlying logic from the user sliding the screen to the recommendation of items or the playback of ads, taking only about 100 milliseconds.
So, why does the entire chain logic look so complex? The core demand is how to quickly filter out suitable items from tens of thousands of candidates within just 100ms to maximize business objectives, such as maximizing advertising traffic efficiency or maximizing conversion in recommendations.
Based on the candidate volume reduction and timeliness requirements, this corresponds to different definitions for different stages, with different requirements for model implementation logic and engineering logic, each with its role, ultimately driving the growth or maximization of overall business returns.
Setting aside the filter logic based on hard condition filtering, let’s start with the recall that can truly reduce volume. For those familiar with classic recall, the first reaction should be the so-called multi-route recall.
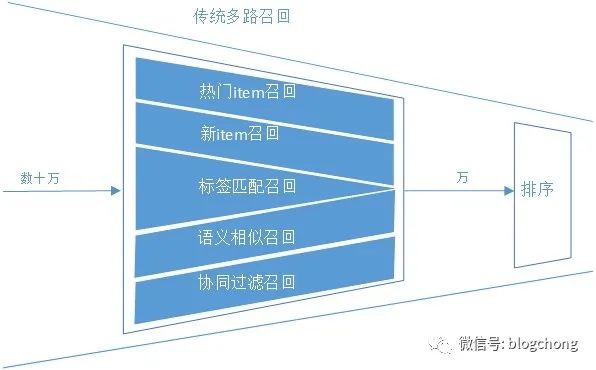
Figure 2: Traditional Multi-Route Recall LogicFigure
Hotspot recall is basically a non-personalized top recall based on historical statistical information; purely catering to new item cold-start recall; i2i basically calculates the relevance between items, but there are different choices in implementation methods, such as directly calculating the surface semantic relevance between items or incorporating user-item interaction behavior into the i2i relevance calculation based on item CF collaborative logic, and even item sets within the same category or clustering can serve as recall logic; u2i’s traditional logic is based on user CF collaboration to obtain the relationship between user and item; in addition, there are labeling items and users, and then performing recall through retrieval logic for label matching, etc.
The above multi-route recall logic is characterized by its diversity of types and differing logics, and it is unclear who came up with it, making it quite challenging to understand. A common feature of these recall logics is speed, able to filter out candidates that meet the recall logic in just about 10ms, either through direct memory data lookup or by pre-constructing indexes through inverted indexes for retrieval recall.
Regardless of whether it is table lookup or rules, most of the above relies on offline computation; even some clustering and collaborative filtering models are built offline, predicted offline, and loaded online data before memory retrieval.
This is due to the engineering limitations caused by the large number of candidates and short response times.
And why are there so many different recall logics? It essentially stems from the capability definition of the recall phase—to provide more potential candidates for the subsequent ranking phase and more possibilities. Therefore, multi-route recall often neglects high-quality candidates that are personalized and related to the recommended objects, as well as collaborative recommendation logic based on user behavior or interest label-related recall logic.
Providing input candidates from different dimensions for the ranking phase is still fundamentally aimed at providing more potentially useful item candidates for the subsequent ranking phase. How to define useful involves the modeling objectives of fine ranking. Taking the most common pCTR as an example, it predicts how likely the current user is to click on the candidate item; in terms of advertising, it is also a pCTR estimate (not discussing more complex conversion issues for now), but the final ranking is based on eCPM after adding bids.
Moreover, another layer of product logic in multi-route recall is to provide various logical recalls, thereby increasing the diversity of candidate items, thus enhancing user experience.
However, to satisfy the multi-route logic recall brought by diversity, the first issue to address is the fusion problem, as the number of candidate items that downstream coarse ranking can accept is limited. For example, taking a thousand candidates to pass downstream, many recall logics have different calculation logics, some based on static statistics, some based on simple label matching, and some based on simple collaborative models calculated offline, making it difficult to truncate on a single dimension.
Currently, most systems still using traditional multi-route recall adopt proportional fusion, where each route is fused according to a ratio, ultimately taking enough items to transmit to downstream.
However, this logic has significant flaws.
Firstly, such proportional combinations often rely on arbitrary decisions, making it impossible to quantify and measure their rationality.
Secondly, setting aside the non-accumulative re-ranking, after recall, at least there is still coarse and fine ranking. The modeling objectives of coarse and fine ranking are very clear; taking the conventional click-through rate scenario as an example, the optimization is about maximizing the pCTR for a single user-item interaction. In simpler terms, the one with the largest pCTR ranks higher. Is it possible that items recalled by hotspot recall get eliminated in coarse ranking? Or that most rankings based on i2i are pushed to the back? This is entirely possible, so it is likely that even if you set a large proportion in the proportional logic, after coarse and fine ranking, it is likely to be discarded, leaving you with a multi-route that leads to nothing.
Therefore, in recent years, two core mainstream directions have emerged: guiding recall towards vector recall and emphasizing the overall consistency of recall, coarse ranking, and fine ranking.
For vector recall, please refer to previous articles in this series, such as “Data and Advertising Series 25: The Origin and Evolution of Embedding, and the Factional Struggle of Sequence Construction and Target Fitting”; “Data and Advertising Series 19: Recommendation Recall and Advertising LookAlike, Everything Can Be Embedded”; and “Data and Advertising Series 22: Technical Implementation Strategies for Scale Expansion Scenarios in Intelligent Delivery” which include the implementation of vector recall using a dual-tower model structure diagram.
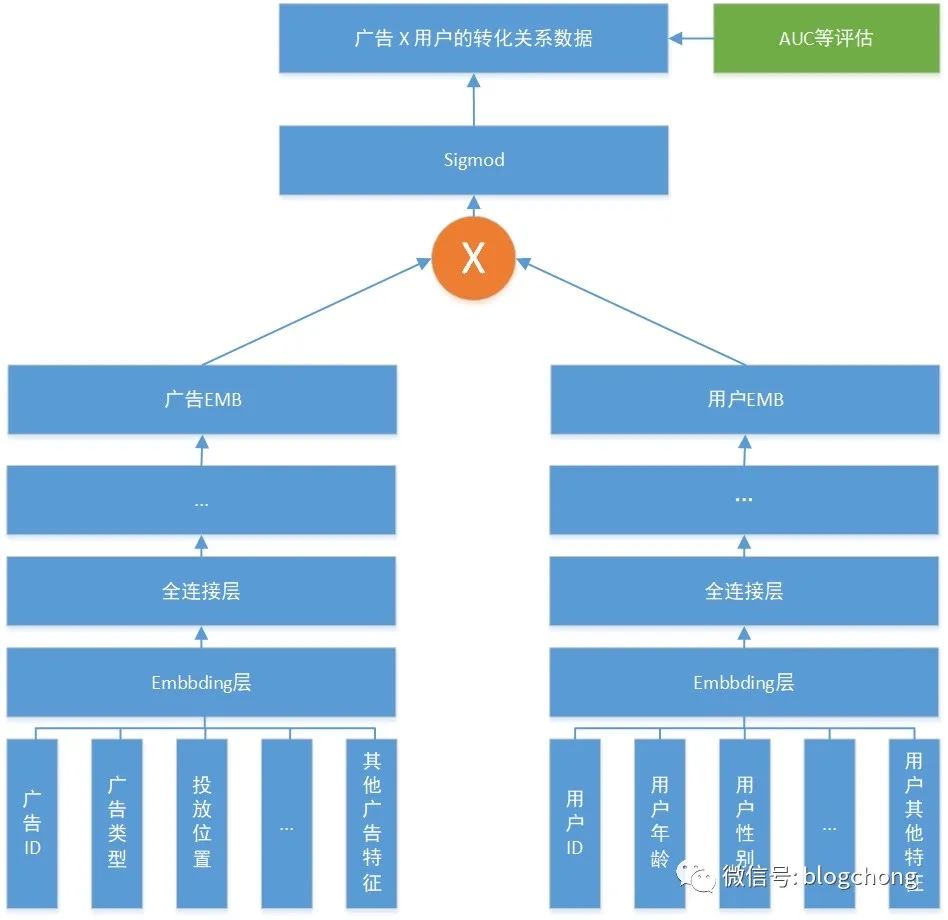
Figure 3: Dual-Tower Model Vector Recall in Advertising Recall
The increasingly mainstream vector recall solution, on the one hand, aligns with the general trend of deep models gradually moving to the forefront, while on the other hand, the explosive growth of data can sufficiently train the network. Finally, the dual-tower structure can efficiently conduct offline predictions, online deployment, and perform efficient vector retrieval in engineering dimensions, thus satisfying both target consistency and engineering efficiency.
Moreover, since the modeling objectives are consistent with the ranking phase, the inner product calculation of item-vec and user-vec can represent the user-item relationship. Therefore, to determine how many levels to pass downstream, it is sufficient to truncate according to Top. Thus, we will not elaborate on the recall logic further and will enter the ranking phase.
As shown in Figure 1, essentially, whether pre-rank or rank is actually sorting. In the early days, many recommendation systems did not even separate pre-rank, and the reason for the separation is very clear: under limited response times, fine ranking cannot individually assess too many candidates while pursuing high accuracy in predictions.
Why is it assessed one by one? Because most fine ranking modeling methods adopt a pointwise approach, which is the most granular modeling estimate for each item-user pair. Therefore, its response efficiency is directly related to the number of candidates to be sorted; not to mention a linear relationship, at the very least, there is a positive correlation.
Meanwhile, pre-rank largely maintains consistency with rank and is distinguished from match; it is also a stage positioning issue. The modeling objectives of pre-rank and rank can be regarded as completely the same, including sample construction methods. If not limited by the input candidates of pre-rank, which are more numerous, and the response time requirements, one could even consider the feature inputs to be quite similar.
Thus, to maintain the consistency of objectives with rank, pre-rank can only simplify the model network and reduce complex features, which can be viewed as a lightweight rank model. This was a very mainstream practice in the past, especially in the era of deep networks, where the network structure in the rank phase was very complex, which provided greater room for simplifying the network to sacrifice some prediction accuracy to allow for lightweight predictions of more candidates.
In addition, the currently popular model distillation also provides a very good landing idea for simplifying models. Furthermore, since coarse ranking is entirely a pre-selection action for rank and is only responsible for the accuracy and precision of estimates, is it feasible to directly learn to fit the fine ranking order? This is another path for coarse ranking modeling, Learning to Rank (LTR). Because essentially, even for advertising, the final sorting relies on eCPM (pCTR * pCVR * CPAbid), theoretically, before fine ranking, it only requires truncating the order, without needing to know the exact pCTR or pCVR for each item, as long as the relative positions of the items in the truncated list are correct.
Regarding sorting, there has been little mention in the series articles, and this is a field that the author is cautious about and does not dare to write lightly, so we will not elaborate further here, but will expand when we output chapters related to sorting. Finally, let’s look at re-ranking.
Before discussing, it is necessary to clarify that in the algorithm chain logic of Figure 1, only match and rank are mandatory options; pre-rank and re-rank are essentially optional, at least in many recommendation advertising scenarios. As for large companies, with inexhaustible manpower and resources, under massive candidates and complex business demands, there are no optional items left; all that remains are mandatory options, and the more complex, the better.
From most of the existing materials, we can find that re-ranking is defined as ensuring the diversity of recommended items, focusing more on user experience, or considering the insertion of some business rule logic.
Setting aside rigid strategic adjustments, from the perspective of modeling ideas, the goal of re-ranking is no longer limited to the matching relationship of a single user-item pair, but rather the relationship of a user to N-items. This means that the mutual influence of previously pushed items must be considered, which is especially important in recommendation scenarios, while in advertising scenarios, the perception may be less strong since there are strict frequency controls in place, thereby weakening the perception of items exposed before and after.
For re-ranking, a more intuitive positioning is to enhance the diversity of recommendation results, thereby improving user perception experience. Whether from a deeper experiential perspective or directly considering diversity, it has moved away from the judgment of a single item and is now evaluated based on the quality of a push list rather than the conversion rate of a single item-user pair.
Therefore, from the perspective of the entire chain logic, based on current mainstream model solutions, whether recall or coarse ranking, their objectives align with fine ranking, which is what we refer to as objective consistency. More often than not, the preceding phases of fine ranking, whether recall or coarse ranking, essentially serve to narrow down the candidate scale for fine ranking to allow for rapid and accurate estimation of the value of a single item within the specified time.
In contrast, re-ranking is different; it is the last link in the entire algorithm chain logic, possessing the power to rearrange the order of fine ranking. However, its objectives differ from sorting, focusing more on the diversity of list results and enhancing the overall perception experience for users. From this perspective, ReRank can be seen as the betrayer of the entire chain.
However, it is not merely a “betrayal” of recall and sorting, nor is it simply a forced insertion of diversity for user experience; rather, it bears a greater responsibility, which is to reshape the pattern of the system’s ecology, and it should stand higher and see farther.


02
ReRank: Betrayal of the Chain and Reshaping of the Ecology
Returning to the so-called “betrayal,” what we see intuitively is the rearrangement of the order of fine ranking, but we need to understand more deeply why it is necessary to disrupt the order.
Essentially, we can return to the question of the modeling objectives of business logic, including what LTR (Learning to Rank) methods to use for modeling and what logic to use for sample construction, especially the definition of positive samples.
For the recall phase, taking the current mainstream vector recall as an example, when constructing the mainstream dual-tower model, we usually build samples based on pointwise logic.
For recommendations, in most cases, user click data should be treated as positive samples, essentially distinguishing between clicks and non-clicks. Advertising is similar; it may consider deeper conversions after clicks, such as whether to download, further activate the app, or make a purchase.
For the sorting phase, it is even more about predicting whether a single user will click or convert in a single request scenario. Therefore, whether for mainstream recall or sorting, their model objectives are the same.
The differences between the two mostly lie in the logic of constructing negative samples, which is what Zhihu’s “Shita Xi” refers to as “the king of negative samples in the recall phase.” Recall emphasizes the perception of global data, so it needs to let the model “see” some unseen negative samples (random from the market or constructed), while sorting predicts whether a click or conversion will occur based on exposure, with slightly different scenarios.
However, this difference does not affect their overarching goal of maintaining consistency.
As for coarse ranking preceding fine ranking, it is essentially a compromise at the engineering efficiency level, which can be considered a lightweight, simplified version of fine ranking. The simplification lies in reduced model complexity, fewer hyperparameters, and a narrower feature range, aiming to further narrow down candidates through lightweight means to ensure timeliness.
Of course, there is also a gradually mainstream approach to coarse ranking, which is true LTR, allowing coarse ranking to learn the order of fine ranking, ensuring that the order remains as consistent as possible rather than calculating pCTR/pCVR and then ranking based on values.
Let’s take a look at re-ranking.
First, it is essential to clarify that the goal of re-ranking is no longer to sort based on maximizing the single business value, such as click-through rates in recommendations or eCPM (CPAbid * pCTR * pCVR) in advertising. Its considerations lean more towards the cumulative effects of multiple user behaviors and even emphasize improving user experience.
For example, the most common practice of re-ranking is to enhance the diversity of the order, thereby avoiding users receiving overlapping pushes multiple times, which can lead to user aversion and increase user churn rates.
This is where the contradiction between sorting and re-ranking lies; from the perspective of goal construction, they are fundamentally different. Sorting does not consider the mutual influence formed after multiple user touches, only ranking based on the single mutually exclusive user-item pCTR (or pCVR, or a comprehensive index after adding bid factors), while ignoring the mutual influences formed after the order is established. Thus, sorting focuses more on short-term gains, while re-ranking attempts to construct modeling objectives from a global perspective, or from a medium to long-term revenue angle.
For example, in some short video recommendation systems, the combination of sequences has a significant mutual influence, especially the impact of earlier items on later ones. This is similar in shopping scenarios; the combination of window products should be viewed as a whole rather than as several independent entities ranked by a certain metric. The arrangement of window products affects the overall user experience and even enhances purchasing intent.
However, in advertising scenarios, this mutual context influence is much weaker, as ads themselves have frequency control in place, and there are strategies to limit the number of exposures for the same advertiser, which weakens the mutual influences. Instead, the context of ads embedded in information streams has an impact, such as ads embedded in information streams. The re-sorting of ads is somewhat special, which we will dissect later. Let’s return to the perspective of constructing the objectives of re-ranking.
Many of the current processing logics for re-ranking are aimed at enhancing the diversity of items to improve user experience, which is a very general logic for re-ranking. However, let’s continue to think about one point: any commercial scenario is not charity; increasing costs (algorithm costs/machine costs) is not merely to enhance user experience and gain user favor at the expense of commercial conversion.
Therefore, the ultimate goal must still be commercial objectives, merely shifting from the goal of maximizing single commercial conversion to medium and long-term, or overall evaluative commercial objectives.
For instance, in short video recommendations, the sorting phase focuses on enhancing the click-through rate of a single video item (or the playback duration of a single video) to form the initial order and reduce candidates. However, in the re-ranking phase, it can completely view this from the perspective of recommending a combination of videos to maximize the overall viewing duration or the maximum number of videos the user swipes through.
Similarly, in e-commerce shopping, in the sorting phase, modeling is typically conducted based on product click-through rates or purchase conversion rates, ultimately ranking based on click-through rates or conversion rates to reduce candidates. However, in the re-ranking phase, it can entirely consider the perspective of recommended product combinations to enhance overall purchasing conversion or GMV, or to increase the overall combination purchasing leading to higher average order value while maintaining the overall click conversion rate.
In both short video and e-commerce scenarios, the focus shifts from merely enhancing the diversity of item combinations to the ultimate business goals of the specific scenario, such as maximizing user engagement in short videos or maximizing purchasing GMV in e-commerce.
Thus, enhancing diversity in the re-ranking phase is merely a means and still a relatively superficial approach. The ultimate goal must be global, even considering the ecological perspective, ultimately achieving the enhancement of overall business objectives through the mutual influence of sequences and the arrangement of sequences.
This is why the sorting phase emphasizes maximizing the value of individual items, while the significance of re-ranking lies in optimizing the global objectives of combinations, even reshaping the ecological pattern, allowing the entire business ecology to become more rational and focusing more on medium to long-term stable revenues.
Therefore, re-ranking and recall sorting are not on the same path; it has a broader perspective, standing higher and looking farther.
So why have fewer people focused on the positioning of re-sorting in earlier years? This has led to the aforementioned weak position of re-ranking compared to the sorting phase in the algorithm chain. This is determined by external environments; the speed of any technological advancement is dictated by the benefits it can produce, and the definition of benefits depends on the most urgent business goals at that time.
In the portal era, there was no recommendation system, but traffic growth surged. As users gradually had experience demands for media, it essentially resulted from the slowing of traffic growth, leading to the need for personalized services to enhance user experience and improve user stickiness. Notably, the development of internet advertising, which highly pursues ROI, has pushed this business scenario further down the path of sorting.
However, after 2018, with the near-complete popularization and coverage of mobile smartphones, traffic dividends peaked, media content became highly homogenized, entering a stage of mutual elimination, and even advertising for competing products became mainstream. This means that traffic has entered a stage of high stock maintenance, which was when the industry began to shout about “private traffic,” essentially focusing on stock.
As an advertising practitioner, a very obvious example is that from 2021 to 2022, a notable trend among advertisers is the increasing pursuit of retention in deep conversions, growing dissatisfaction with shallow conversion models, or reducing advertising budgets, and forcing DSP platforms to increase the cost achievement rate for deep conversions.
This real example clearly illustrates that traffic owners are anxious (advertisers are essentially traffic owners; the essence of advertising is to drive traffic), focusing more on user experience, and stabilizing traffic is essential for long-term benefits.
From the above logic, we can see that the importance of maintaining stock traffic is even more severe than we imagine, and the reshaping of the ecological pattern of the system must shift from maximizing single revenue to maximizing long-term revenue.
This is a significant trend.
However, the difficulty lies precisely here: how to consider maximizing medium and long-term benefits in a single request; this is both a responsibility and a challenge.
Moreover, the challenge’s difficulty lies in not merely considering diversity and enhancing user experience through diversity, but in how to quantify the enhancement of experience through diversity, and even how to ensure sustained benefits in the medium and long term after the experience is improved.
Let’s see how ReRank focuses on the medium and long-term benefits of business and how to technically achieve the evolution from experience diversity to the ultimate ecological goals.


03
The Evolution from Diversity to Ultimate Ecological Goals
In early studies of re-ranking, both product managers and algorithm practitioners focused more on how to use re-ranking to resort the sequence to achieve the goal of optimizing user experience, which further breaks down to the adjustment of the sequence, specifically how to avoid continuously presenting highly similar items, thus causing user fatigue.
In short, the optimization goal of the business is clear: outputting a diverse sequence. So, what is the algorithmic modeling objective when broken down? How is the loss function defined, and how is the effectiveness evaluated?
First, let’s talk about evaluation. Without a clear evaluation method to define the quality of data, there is no point in discussing modeling. For recommendations, early commonly used evaluation methods were DCG or its evolved version, NDCG, with the following formula.
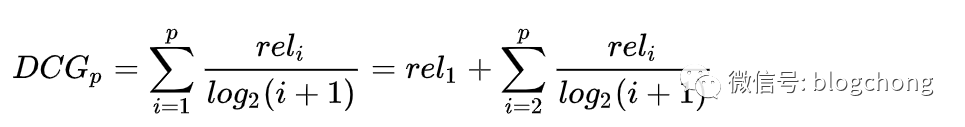
DCG (Discounted Cumulative Gain) should be split into Discounted and cumulative gain; the latter counts the cumulative gain, which is a straightforward assessment of the quality of the output list’s cumulative items. Thus, the reliability expressed corresponds to the relevance of item i. When discounted, it needs to consider that the impact of gain varies with position; in simpler terms, items ranked higher are theoretically more important, and thus have a greater weight (conversely, if the estimation is wrong, the loss is also greater). Therefore, a position decay of 1/log2(i+1) is directly implemented in the logic.
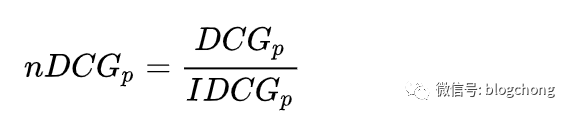
NDCG needs to address the issue of quantifying normalization, as varying lengths of sequences would lead to unfairness through cumulative summation (clearly, longer sequences yield higher DCG). The maximum theoretical value is normalized, with IDCGp in the denominator representing the maximum DCG for position p in the sorted order of all candidate relevances.
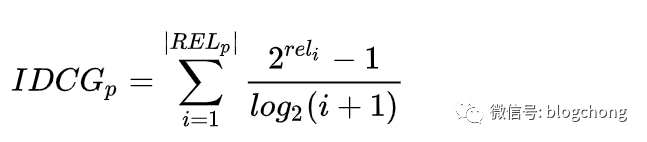
Subsequently, other similar metrics such as MRR (Mean Reciprocal Rank) and MAP (Mean Average Precision) emerged, generally not differing significantly; they all score the items in the output sequence and then combine the scores with output positions to calculate a comprehensive evaluation score to compare the quality of two sequences. It is worth noting that the evaluation of search results is also very similar, comprehensively assessing the entire sequence rather than individual items.
As for evaluating diversity, one cannot simply replicate NDCG, as NDCG does not consider the mutual influences of context on individual item evaluations. Hence, the improved version α-NDCG (published in SIGIR 2008 in the paper “Novelty and Diversity in Information Retrieval Evaluation”) was introduced.

From the paper, it can be seen that it is fundamentally based on DCG, with core modifications in defining the gain. Two adjustments were added: one is that with each additional item, the current k-th item’s information gain is calculated against the previous k-1 items; the lower the gain, the greater the penalty, thus controlling diversity. Secondly, the position of the sequence also influences the overall score—items placed later have less weight.
The key improvement lies in the influence of the previous items on the current item’s score, with the improvement penalizing or weighting the score of the current item based on the information gain from diversity. Theoretically, the higher the gain, the smaller the penalty; the smaller the gain, the higher the penalty, indicating greater similarity. This allows the sequence to consider not only the rationality of recommendations but also the mutual influences of context.
This is the evaluation method. Next, let’s look at how to implement the differences in diversity within the algorithm internally, starting with the ancient MMR.
MMR (Maximal Marginal Relevance) algorithm, also known as the maximum marginal relevance algorithm, was originally designed to calculate the similarity between query texts and the searched documents, then rank the documents (published in SIGIR 1998 in the paper “The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries”).
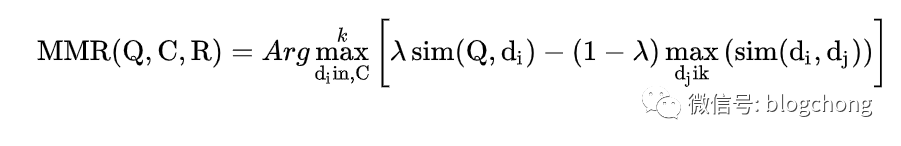
Where Q is the query text, C is the set of searched documents, R is an already obtained initial set based on relevance, and Arg max[*] refers to the index of the K sentences returned. The left part of the formula represents the similarity of a certain sentence d in document Q to the entire document, while the right part represents the similarity of a sentence di in the document to already extracted summary sentences dj. The meaning of the entire formula is that in the process of continuously extracting summaries, it aims to extract sentences that can represent the meaning of the entire document while maximizing the information gain between the extracted sentences, thus enriching the information contained in the summary.
This is the logic of needing both; it is similar to our re-ranking diversity. Therefore, enhancing user diversity experience through re-ranking ensures that the arrangement of items maintains diversity, widening the gap between items while simultaneously ensuring that each item in the sequence is optimal or relatively good for conversion.
In the overall list re-ranking process, the evaluation details reference MMR, but the upper-level strategy adopts a greedy algorithm to generate the Top K results. The specific logic for similarity calculation can be replaced, leaning towards relevance or diversity, adjusted by λ; increasing λ favors relevance, decreasing it increases the weight of diversity, ultimately depending on the business scenario’s positioning.
It appears to be a mathematical game, but does adjusting λ really affect our final experience and ultimate goals? We will analyze this later.
Next, let’s look at another early paper pursuing diversity. Unlike MMR, DPP (Determinantal Point Processes) is relatively new in the context of recommendation retrieval systems (MMR is an antique from 1998) and has been officially used by Google, Hulu, Huawei, etc., for adjusting diversity in re-ranking results (for example, the 2018 NIPS paper from Hulu titled “Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity”).
Although the mathematical logic of DPP is quite complex and not something the author excels at, we will try to understand this process in simple terms. Essentially, DPP achieves a balance of utility and diversity through a determinantal point process, while its difference from MMR lies in the posterior probability used to solve the maximum combination subset matrix, which is much more efficient and scalable than MMR. The balance of relevance (utility) and diversity is also supported by parameter adjustments to shift tendencies.
Comparing MMR and DPP, if we set aside the specific calculation logic and theoretical details, fundamentally, the definitions of the problems to be solved do not qualitatively differ; the difference lies in methods, efficiency, scalability, and reasonable quantification.
Based on the classic algorithms of MMR and DPP, along the logic of optimizing both diversity and effectiveness (conversion), let’s look at the evolution of re-ranking in Airbnb, with information from Airbnb’s 2020 paper published at KDD titled “Managing Diversity in Airbnb Search,” which provides insight into how Airbnb considers re-ranking.
In the early days, Airbnb’s re-ranking ensured relevance (the paper used the term Relevance, but the author believes that conversion rates might better represent this dimension) and diversity, still using MMR and balancing relevance and diversity through explicit formula combinations.
Three micro-optimizations they made are worth referencing (not necessarily to be applied to one’s own business but to consider whether deep revisions are needed).
First, they clearly defined diversity based on their business, with Airbnb explicitly stating that they focus on location, price, size, room types, etc. This aligns well with the logic of explicit optimization, focusing on what metrics to optimize.
Second, they constructed item listings based on the diversity attributes of interest, calculating diversity and relevance through vectors. This expression was innovative at the time (in today’s era of