Have you ever been troubled by these questions?
Searching through a cluttered computer hard drive for an assignment you saved, clearly remembering the general content, but unable to find it by name because the file name has little to do with the content; or when writing a paper, you remember a piece of literature supporting your point, but the title alone isn’t enough to find it in your reference management tool, forcing you to sift through each possible document again, wasting a lot of time; or perhaps you’ve forgotten a knowledge point, but that point is buried in a thick textbook or hundreds of pages of your teacher’s PPT, and searching with the name you remember just doesn’t work.
Now, these issues are no longer problems, let artificial intelligence help you.
PART.1
What is RAG Knowledge Base?
The RAG (Retrieval Augmented Generation) Knowledge Base is a natural language processing application based on text vectorization and large language models. Its purpose is to overcome the context limitations of natural language models by finding the most relevant answers to user queries from vast amounts of information and organizing that information using a large language model to output accurate, high-information responses.
Compared to traditional search technologies, its advantages lie in its closer integration with semantics and higher local deployment capability. Semantics refers to the meaning of sentences. While traditional search engines find results based on characters (pattern matching), augmented information retrieval matches query statements with results based on ‘meaning’. At the same time, language models can summarize scattered information, directly presenting the most relevant and coherent answers to users. Furthermore, the knowledge base can be deployed locally, helping users organize their own files on their computers, which traditional web search engines like Baidu cannot do.
With the RAG knowledge base, we can build our own knowledge base using written assignments, teachers’ PPTs, reference literature, textbooks, and even web links and WeChat articles, helping us better organize what we learn and improve our learning and research efficiency.
Example 1: Definition Explanation

In the past, whenever I had to write definitions for assignments, I would have to laboriously search through the hundreds of pages of PPT from my teacher.
Now, by entering all the course PPTs into the knowledge base, I can easily find the information I want in a Q&A format, along with the source, knowing exactly which chapter the corresponding content is in.
Example 2: Literature Review
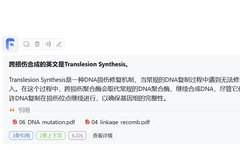
In some cases, we need to quickly read literature in a very short time to accurately find relevant scientific questions. By entering literature into the knowledge base, even when dealing with specialized terminology, asking summary questions about English articles in Chinese yields mostly correct and complete answers.
PART.2
Principles of RAG Knowledge Base
The RAG Knowledge Base consists of three modules. The first module is the text segmentation module, which processes the input files by chunking them, reducing the difficulty of locating content by breaking long texts into shorter paragraphs. The second module is the embedding module, which converts discrete, variable-length texts into continuous, fixed-length vectors, allowing for operations like adding, deleting, and searching in the vector database. The third module is the large language model (LLM) module, which organizes and formats the information in the knowledge base for output to users.
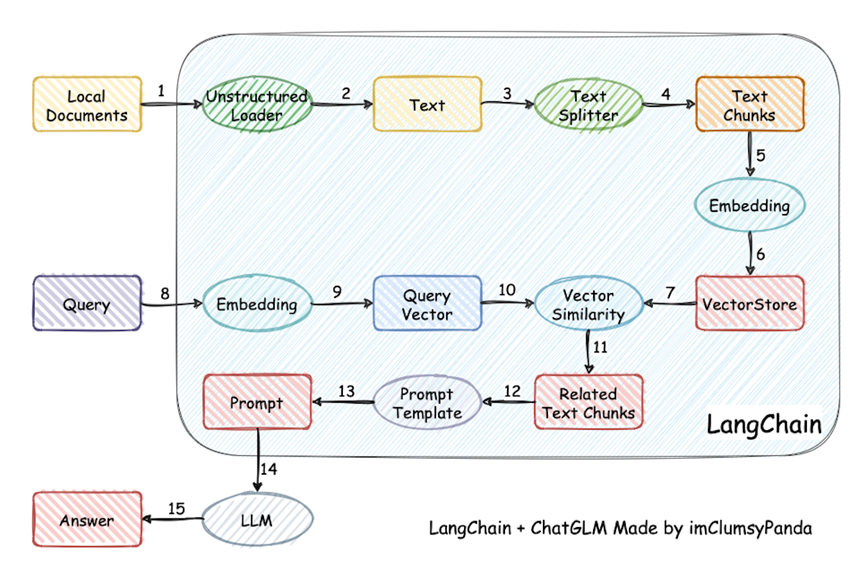
LangChain-chatchat Architecture Diagram
The most important functionality of the RAG model is derived from the embedding module. How do we evaluate the semantic similarity between two sentences? Comparing identical characters and grammar is a good method, but it is not suitable for many scenarios. For example, ‘I am a happy person’ and ‘I am a happy dog’ differ by only two characters, have similar grammar and tone, yet their meanings are completely different. Or ‘You are right’ and ‘Ah, yes, yes, you are right’, the latter just adds a few synonymous words to the former, but the meaning expressed is entirely opposite. From these examples, we can see that we need to consider not only the meaning of each character but also the relationships between them, which is often referred to as ‘attention’ in large models.
The embedding model converts variable-length texts into fixed-length vectors, ensuring that semantically similar texts have vectors that are close together. This means that the similarity of sentences can be measured by the similarity of their vectors. Common similarity measures include cosine similarity and Euclidean distance. However, the embedding model is not omnipotent and is limited by the training data and model structure. Some models may struggle with metaphors, as seen in the previous examples.
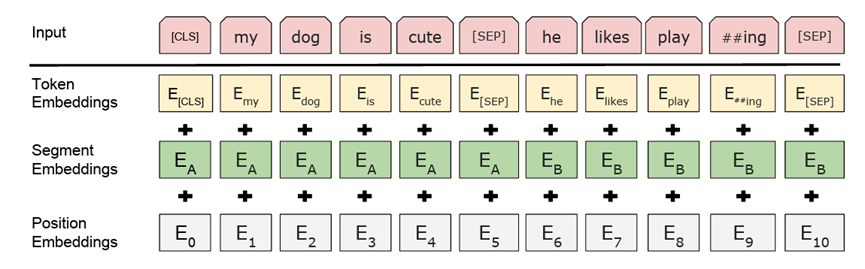
Bert Model Input Representation
All three modules affect the performance of the RAG knowledge base. For the text segmentation module, the most commonly used method is fixed-length segmentation, which cuts the text every so often. This method is simple and fast, and its performance is sufficient for most scenarios. Other methods include semantic segmentation and grammatical segmentation, with semantic segmentation being the slowest but most effective. For the embedding module, the most important performance metrics are semantic relevance and reordering performance. When selecting a model, you can refer to the MTEB leaderboard and choose a model based on application needs. Generally, models with higher overall rankings can meet requirements. Finally, for large language models, the more powerful the model, the stronger its summarization capabilities.
PART.3
How to Choose RAG Knowledge Base Products
Currently, AI applications are still in a rapid development phase, and there are no very mature knowledge base applications on the market. Currently, RAG knowledge base applications can be divided into two types: one is products integrated by enterprises, where users simply log in to the website to use, such as FastGPT. The advantage is that it is very convenient and easy to use, essentially upgrading the experience based on traditional competitors; the downside is that it is expensive and requires internet access. The other type is open-source projects that can be deployed locally, where users install the software on their computers and can call cloud APIs or perform computations entirely locally, such as LangChain-chatchat. Its advantages are that it does not require internet access, ensuring speed and security; the downside is that it requires some technical skills, and some applications may have higher hardware requirements. Finally, one can also write their own; for those interested in exploring AI applications, the RAG knowledge base is a great ‘hello world’ project that is not difficult to implement.
Every technological iteration enhances productivity. In recent years, ‘AI+’ has gradually entered our field of vision. The essence of ‘AI+’ is to use new tools to solve existing and emerging problems faster and better, and learning and research can certainly try new methods and tools. However, whether traditional learning methods, notes, mind maps, or innovative knowledge bases, they are all auxiliary tools for learning; only those that suit oneself are the best.
Finally, I wish everyone success in their studies and the realization of their grand ambitions!
Image Source:
Langchain-Chatchat: A local knowledge base Q&A based on Langchain and ChatGLM language models, forked from GitHub: https://github.com/chatchat-space/Langchain-Chatchat (gitee.com)
[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (arxiv.org)

Scroll down to view more

