
-
Open Source Model: The Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M models, which extend the context length of the open-source Qwen model to 1M for the first time. -
Inference Framework: Fully open-sourced the vLLM-based inference framework and integrated a sparse attention method, which can improve speed by 3 to 7 times when processing 1M length inputs. -
Technical Report: Shared the technical details behind the Qwen2.5-1M series, including design ideas for training and inference frameworks and results from ablation experiments.
-
Qwen2.5-7B-Instruct-1M: Requires at least 120GB of memory (total across multiple GPUs). -
Qwen2.5-14B-Instruct-1M: Requires at least 320GB of memory (total across multiple GPUs).
Key Technology Long Context Training
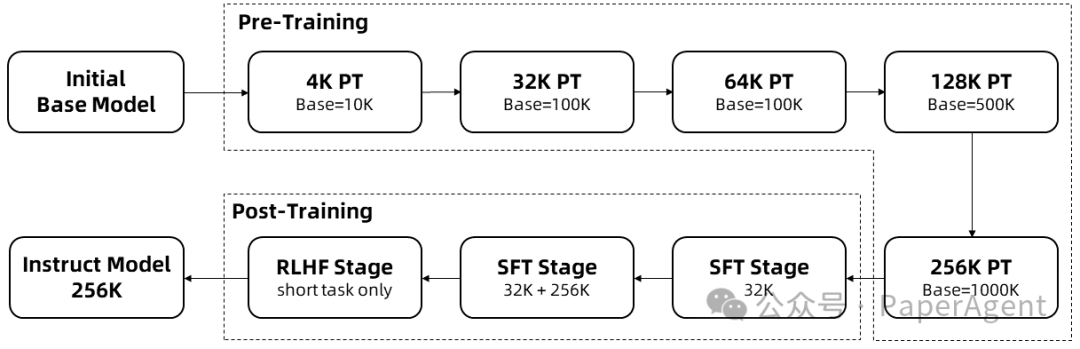
Training long sequences requires a large amount of computational resources, so a stepwise length expansion method was adopted, gradually extending the context length of Qwen2.5-1M from 4K to 256K in multiple stages:
-
Starting from an intermediate checkpoint of the pre-trained Qwen2.5, where the context length is 4K.
-
In the pre-training phase, the context length is gradually increased from 4K to 256K, while using theAdjusted Base Frequency scheme to raise the RoPE base frequency from 10,000 to 10,000,000.
-
In the supervised fine-tuning phase, it is divided into two stages to maintain performance on short sequences:
-
First Stage: Fine-tuning only on short instructions (up to 32K length), using the same data and number of steps as the 128K version of Qwen2.5 to achieve similar performance on short tasks.
-
Second Stage: Mixing short instructions (up to 32K) and long instructions (up to 256K) for training to enhance performance on long tasks while maintaining accuracy on short tasks.
-
In the reinforcement learning stage, the model is trained on short texts (up to 8K length). Even when trained on short texts, it can effectively generalize human preference alignment performance to long context tasks.
Through the above training, a 256K context length instruction fine-tuning model was finally obtained.
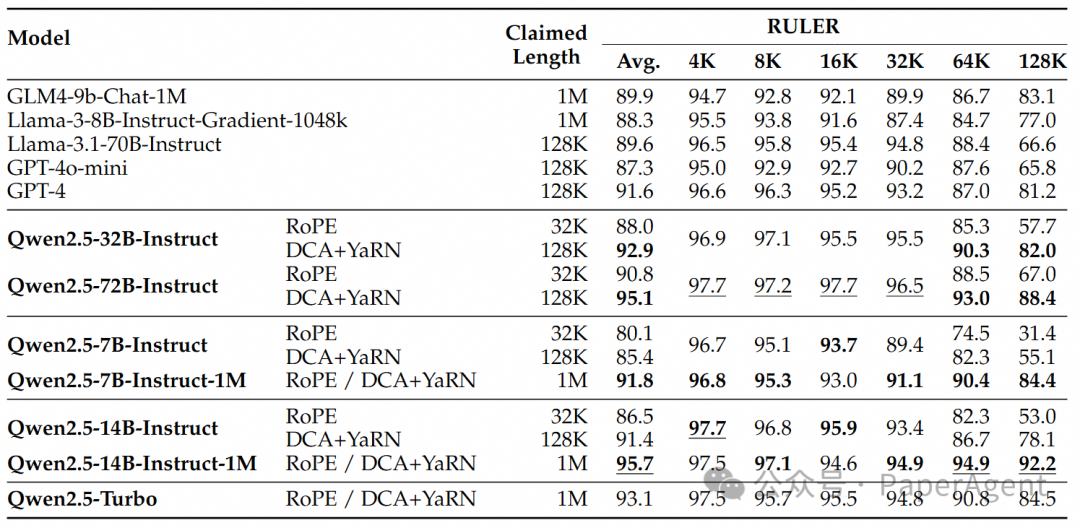
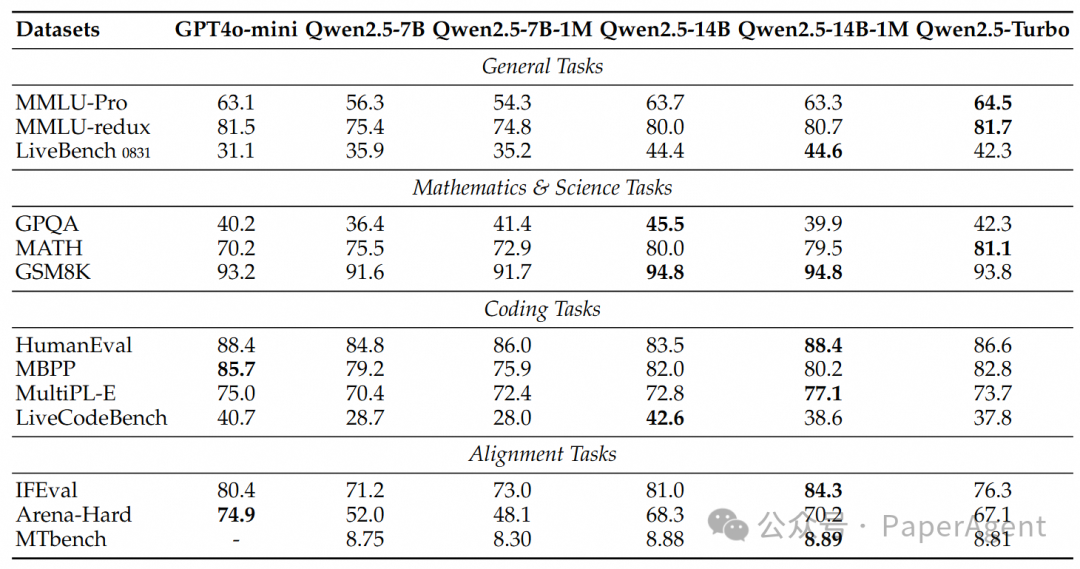
https://qwenlm.github.io/zh/blog/qwen2.5-1m/https://hf-mirror.com/Qwen/Qwen2.5-14B-Instruct-1Mhttps://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdfSource | PaperAgent