
Hello everyone, this is NewBeeNLP.
-
Although language models like BERT have made significant achievements, they still perform poorly in terms of sentence embeddings due to issues like sentence bias and anisotropy;
-
We found that prompts can generate different aspects of positive pairs when given different templates, avoiding embedding bias.
1
Related Work
1
Related Work
Contrastive Learning can utilize BERT to better learn sentence representations. The focus is on how to find positive and negative samples. For example, using the inner dropout method to construct positive samples.
Existing research shows that BERT’s sentence vectors exhibit a collapse phenomenon, meaning that sentence vectors are influenced by high-frequency words and collapse into a convex cone, leading to anisotropy. This property causes issues when measuring sentence similarity, which is the anisotropy problem.
2
Findings
2
Findings
(1) Original BERT layers fail to improve performance.
Comparing two different sentence embedding methods:
-
Averaging the input embeddings for BERT;
-
Averaging the outputs (last layer) of BERT
To evaluate the effectiveness of the two sentence embedding methods, we use the sentence level anisotropy evaluation metric:
anisotropy: Calculate the cosine similarity of sentences in the corpus pairwise and take the average.
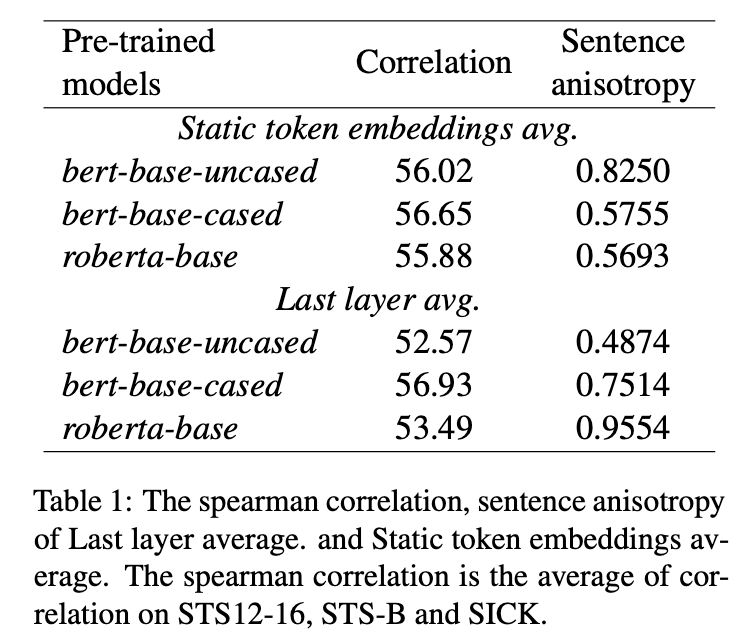
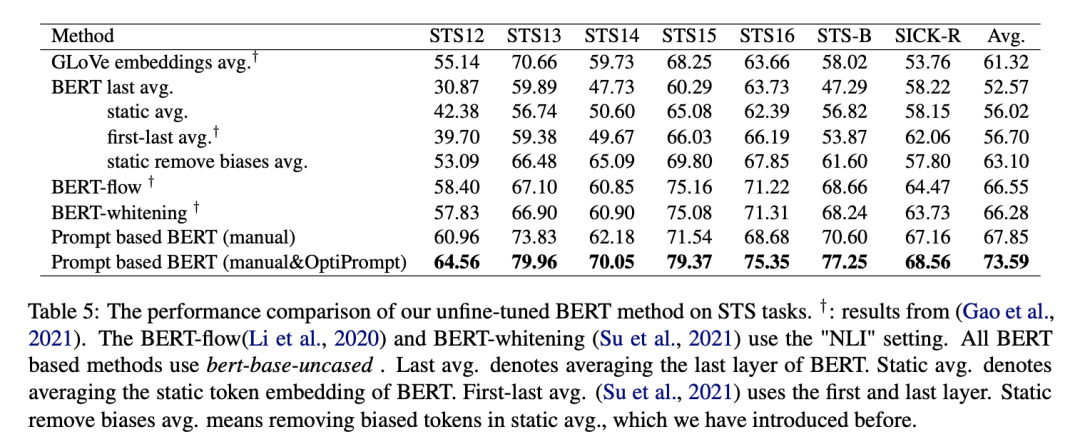
We compared different language models, and the preliminary results are as follows:
-
From the above table, it seems that the Spearman coefficient corresponding to anisotropy is relatively low, indicating low correlation. For example, with bert-base-uncased,
-
It can be seen that the anisotropy of static token embeddings is quite large, but the final effects are similar.
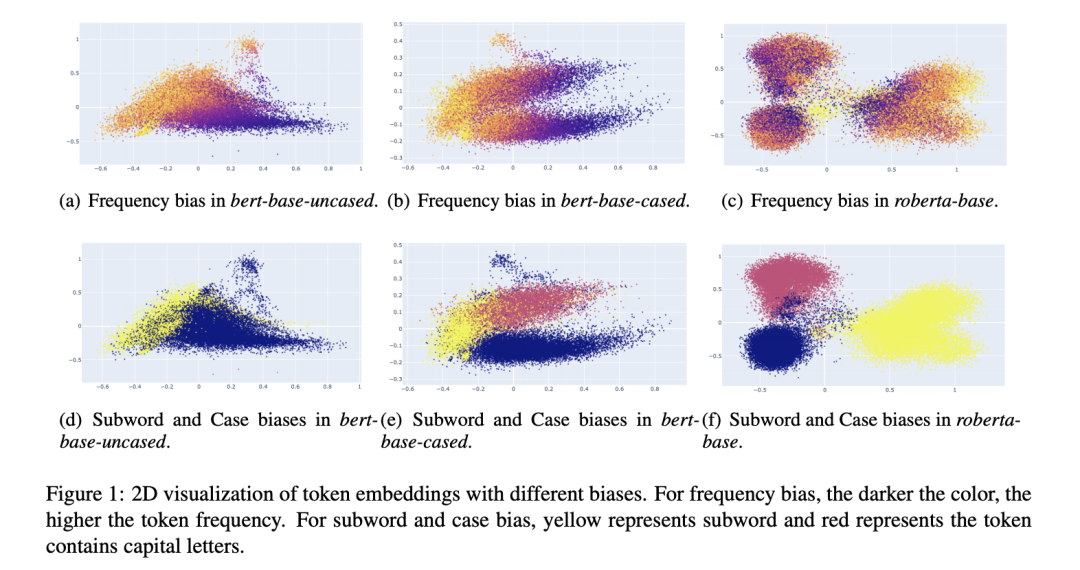
(2) Embedding biases harm the performance of sentence embeddings. Token embeddings are influenced by both token frequency and word piece.
-
The token embeddings of different language models are highly affected by word frequency and subwords;
-
Through 2D visualization, high-frequency words tend to cluster together, while low-frequency words are dispersed.
For frequency bias, we can observe that high frequency tokens are clustered, while low frequency tokens are dispersed sparsely in all models (Yan et al., 2021). The begin-of-word tokens are more vulnerable to frequency than subword tokens in BERT. However, the subword tokens are more vulnerable in RoBERTa.
3
Method
3
Method
To avoid the aforementioned issues in BERT when representing sentences, this paper proposes using prompts to capture sentence representations. However, unlike previous applications of prompts (classification or generation), we do not obtain labels for sentences, but rather their vectors. Therefore, two questions must be considered regarding prompt-based sentence embedding:
-
How to use prompts to represent a sentence;
-
How to find appropriate prompts;
This paper proposes a sentence representation learning model based on prompts and contrastive learning.
3.1 How to Use Prompts to Represent a Sentence
This paper designs a template, for example, “[X] means [MASK]”, where [X] represents a placeholder corresponding to a sentence, and [MASK] indicates the token to be predicted. Given a sentence and transformed into a prompt, it is fed into BERT. There are two methods to obtain the sentence embedding:
-
Method 1: Directly use the hidden state vector corresponding to [MASK]: h=h_[MASK] -
Method 2: Use MLM to predict the top K words at the [MASK] position, and weight the word embeddings of each word based on their predicted probabilities to represent the sentence:
Method 2 represents the sentence using several tokens generated by MLM, which still has bias, so this paper only adopts the first method.
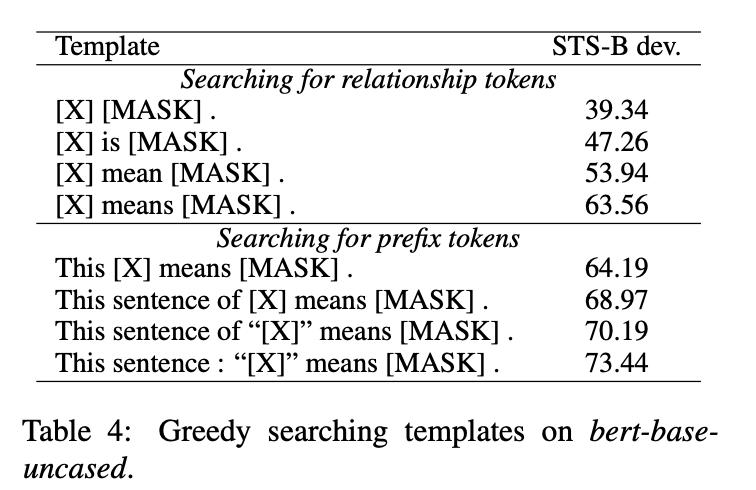
3.2 How to Find Appropriate Prompts
-
manual design: Explicitly design discrete templates; -
Use the T5 model to generate; -
OptiPrompt: Convert discrete templates into continuous templates; -
3.3 Training
The idea is to use different templates to represent the same sentence from different points of view, which helps the model produce more reasonable positive pairs. To avoid the template itself introducing semantic bias to the sentence, the author employs a trick:
-
Feed the sentence containing the template to obtain the embedding corresponding to [MASK]: h_i^hat; -
Only feed the template itself, keeping the position IDs of the template tokens in their original input positions. At this time, obtain the embedding corresponding to [MASK]: h_i – h_i^hat and finally apply it to the contrastive learning loss for training:
4
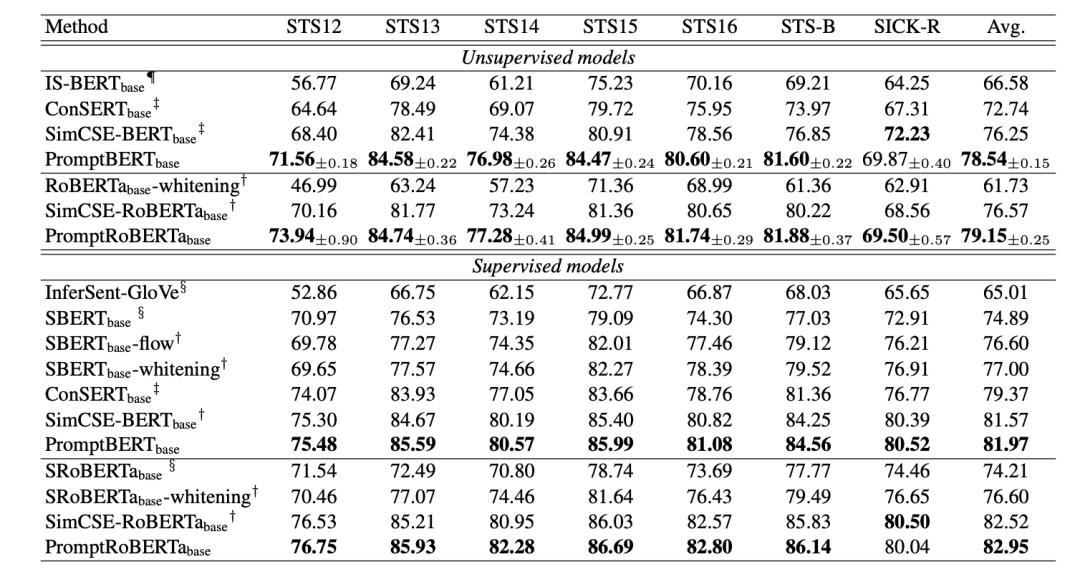
Experiments
4
Experiments

Scan the QR code to add the assistant on WeChat
About Us
