

By | python
The rise of large models like GPT-3 has brought about a new paradigm of in-context learning. In in-context learning, the model does not use gradient descent to adjust parameters based on supervised samples; instead, it connects the inputs and outputs of supervised samples as prompts, guiding the model to generate predictions based on the input from the test set. This method can significantly outperform zero-shot learning and provides new insights for few-shot supervised learning.
Previous research in supervised learning has shown that random shuffling of the training set typically does not have a significant impact on model performance. However, this conclusion does not hold in in-context learning. The authors found that the order of examples in the prompt has a significant impact on the performance of in-context learning, causing model performance to fluctuate between state-of-the-art and random. This rule does not change with model size or sample quantity, and there is no discernible pattern to the order of better prompt samples.
So, can we not select the best prompt order? The authors suggest that, on one hand, we can use a validation set to select the order of prompts. However, this contradicts the original intention of few-shot learning in in-context learning. On the other hand, the authors found that most prompt orders that cause model failure lead to a significant deviation between the predicted label distribution and the true distribution. Therefore, based on a small number of samples, they generate unlabeled data using a pre-trained language model. They use the automatically generated unlabeled data as a validation set and the entropy of the label distribution as a validation metric to select the optimal prompt order. The method proposed by the authors achieved a relative improvement of 13% across 11 text classification tasks.
This paper is an ACL 2022 outstanding paper, with authors mainly from UCL.
Paper Title: Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Paper Link: https://aclanthology.org/2022.acl-long.556
Background
Unsupervised Prediction with Large Pre-trained Language Models: Given a trained model, input the test data (x) directly into the language model to predict the output (P(y|x)). As shown in the figure below, the manual part introduces a small amount of human design. The blue part is the label that needs to be predicted.

In-context learning is similar to the above-mentioned unsupervised prediction, but it inputs a small amount of labeled data before the test samples. It also does not require parameter adjustment and predicts directly. This is equivalent to adding a prefix to unsupervised prediction, as shown in the figure below.
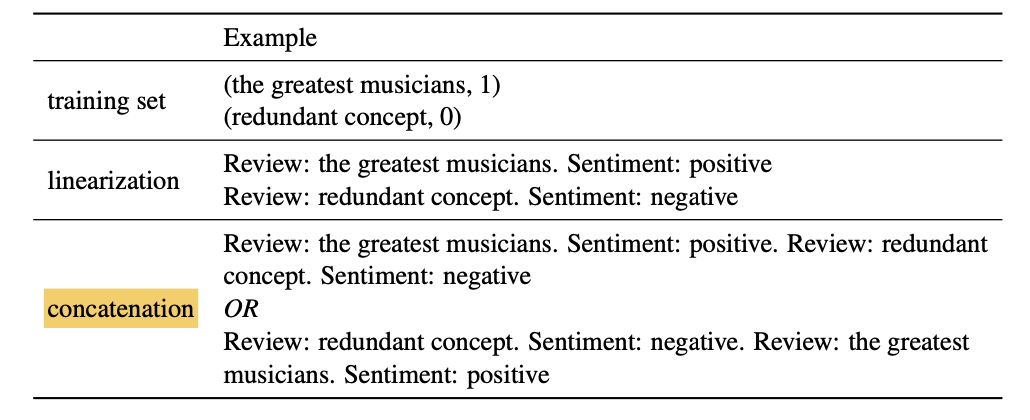
The main focus of this paper is to explore the impact of the order of labeled data in the prefixes introduced in in-context learning (i.e., the concatenation part in the above figure) on model performance.
Importance of Prompt Order
The figure below shows the performance of different sizes of GPT-2 and GPT-3 models (horizontal axis, 0.1B~175B) under different prompt orders on the SST-2 (left) and subj (right) tasks. The authors randomly selected 4 supervised samples, and if fully permuted, there are a total of 4!=24 arrangements. Each column displays the mean performance and error bar of the model under the 24 prompt orders for that task. It can be seen that in SST-2, the accuracy of the 2.7B model can fluctuate between 50% and 85%. 50% is merely the accuracy of random guessing, while 85% is close to the best performance under supervised learning. Therefore, the order of prompts is very important.
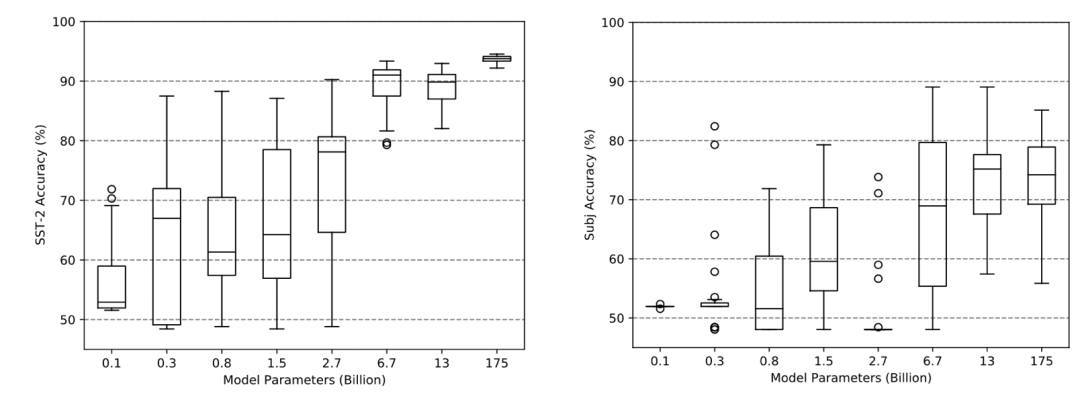
It is difficult to completely avoid fluctuations in model performance with prompt order for larger models. In the SST-2 task (left figure), it seems that as the model size increases, the fluctuations decrease significantly. However, in the subj task (right figure), even the 175B GPT-3 model still shows considerable fluctuations in performance based on prompt order.
More displayed samples cannot alleviate the fluctuations in model performance due to prompt order. The figure below shows the fluctuation range of GPT-2 models of four different sizes when using 1 to 32 displayed samples. It can be seen that as the number of displayed samples increases, the model performance generally improves, but the fluctuation range does not decrease significantly.

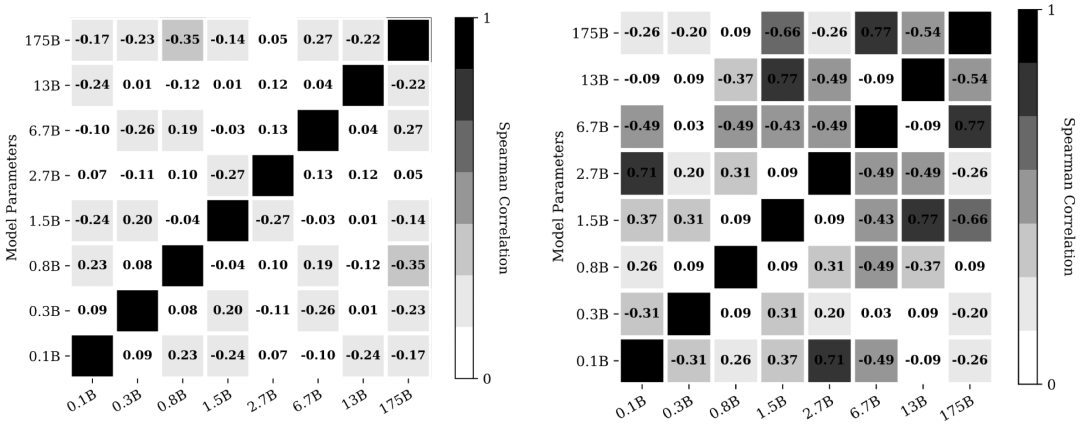
The order of high-quality displayed samples also does not show any significant pattern. If the order of high-quality displayed samples had a certain pattern, it should have a certain transferability, meaning good performance across different models. However, this pattern does not exist. There is a significant difference in the quality of displayed samples across different models. The left figure displays the Spearman rank correlation coefficient between the performance of different displayed sample orders (4!=24), and the right figure shows the correlation for displayed sample label orders (there are 6 combinations due to 2 positive and 2 negative). It can be seen that neither the sample order nor the label order possesses cross-model transferability. Therefore, the order of high-quality displayed samples also does not display a significant pattern.
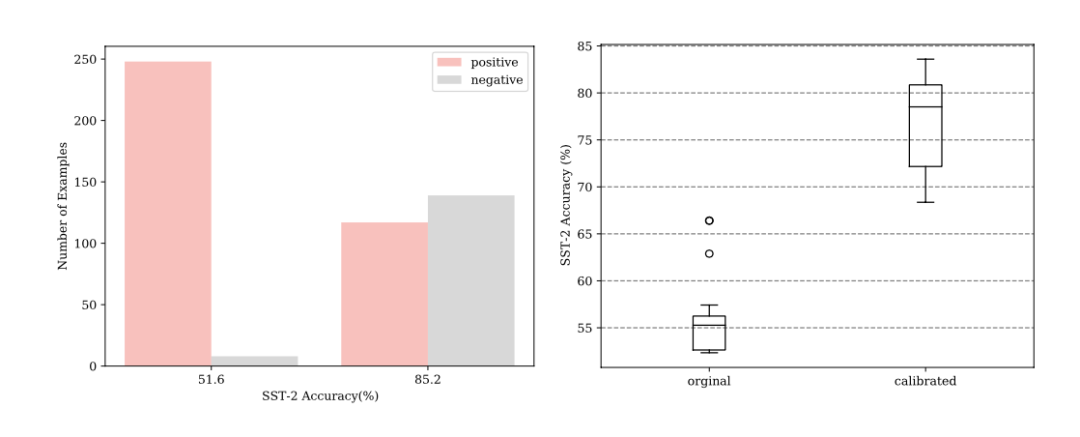
But is the relationship between the order of displayed samples and model performance purely random? Not quite. The authors found that those prompt orders that lead to poor model performance often cause significant deviations in the model’s predictions, such as predicting all samples as one category in binary classification. As shown in the left figure, the prediction result distributions for the display orders with accuracies of 51.6% and 85.2% show significant differences.
However, simply calibrating the decision threshold for prediction results can partially improve model performance, but still cannot completely solve the randomness problem of model performance fluctuations with displayed sample order. As shown in the right figure, adjusting the prediction result distribution for poorly performing display orders leads to an average accuracy improvement, but the standard deviation actually increases.
Optimizing Prompt Order Selection
So, do we have no way to handle the order of prompts? The authors suggest that, on one hand, we can use a validation set to select the order of prompts. However, this contradicts the original intention of few-shot learning in in-context learning. On the other hand, we can generate unlabeled data based on the observation that “most prompt orders that cause model failure lead to a significant deviation between the predicted label distribution and the true distribution.” Using a small number of samples, we generate unlabeled data. The automatically generated unlabeled data serves as a validation set, and the entropy of the label distribution serves as a validation metric to select the optimal prompt order.
The first step is to generate an unlabeled dataset for validation. The authors simply use each prompt order as a prefix, input it into the pre-trained language model, and let the model decode a series of identically distributed data. As shown in the figure below. The reason for using a pre-trained model to generate pseudo datasets, rather than using real data as a validation set, is mainly due to considerations of few-shot learning.
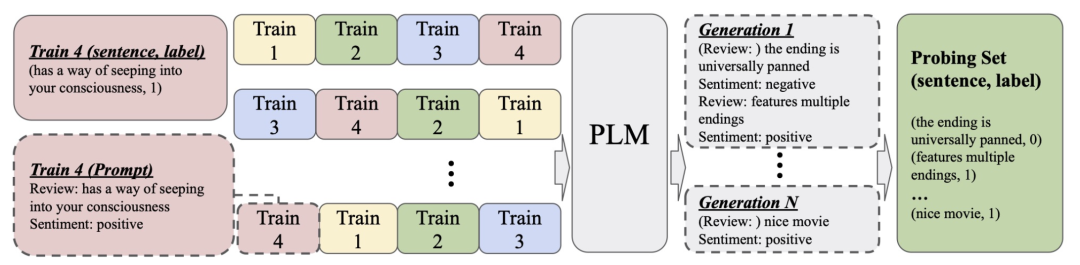
After generating the validation dataset, the next step is to determine evaluation metrics to assess the quality of the prompt’s display order. The authors considered that the labels of the generated data are not accurate, so they do not use the usual validation set application method in supervised training, but instead designed an unsupervised evaluation metric based on entropy. This is mainly based on the intuition that most prompt orders that cause model failure lead to relatively extreme predicted label distributions, resulting in lower entropy values.
The authors designed two selection metrics, one being the global entropy metric (GlobalE). Given a certain display sample order, predictions are made on the generated data, and frequencies are counted to determine the predicted probabilities for each category. The higher the entropy value of the predicted probabilities, the higher the quality of the display sample is considered.
The other metric is the local entropy metric (LocalE). This method calculates the average entropy value using the predicted probabilities for data entries. The higher this entropy value, the higher the quality of the display sample is considered.
Experimental Results
The experimental results are shown in the figure below. The specific experimental details are not elaborated here. In the table, Oracle represents the model performance under the optimal display sample order.
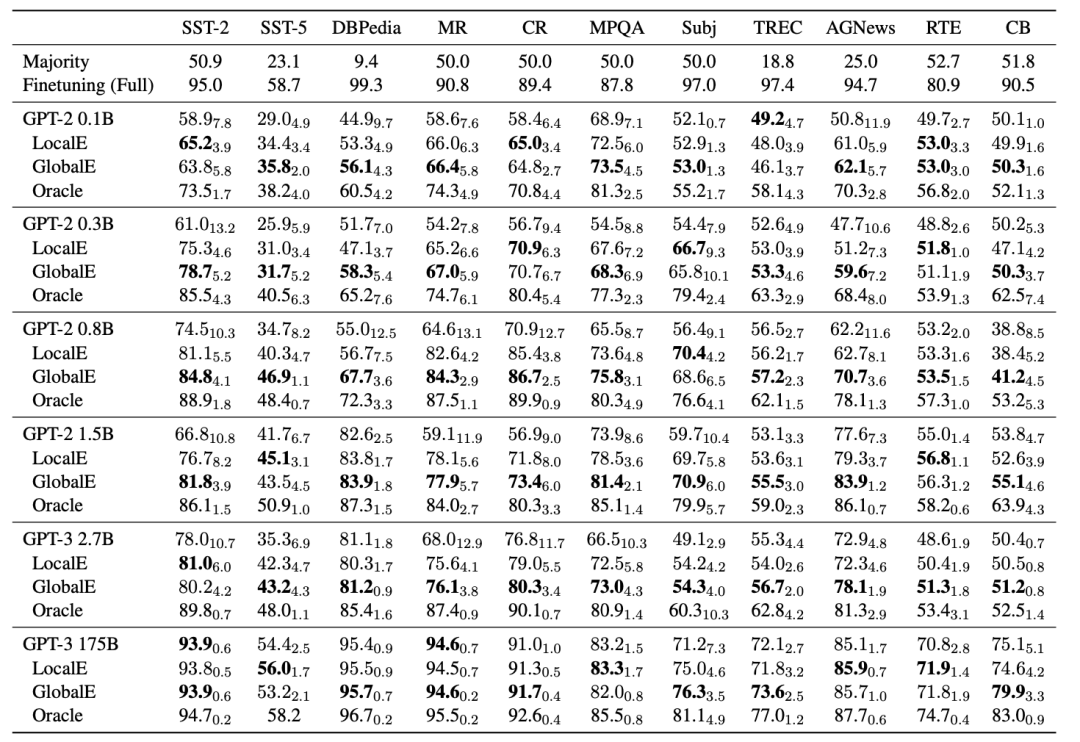
Compared to methods that do not select prompt display orders, using GlobalE and LocalE methods achieved average improvements of 13% and 9.6%, respectively. This indicates that the selection method based on entropy and unlabeled data generation is effective.
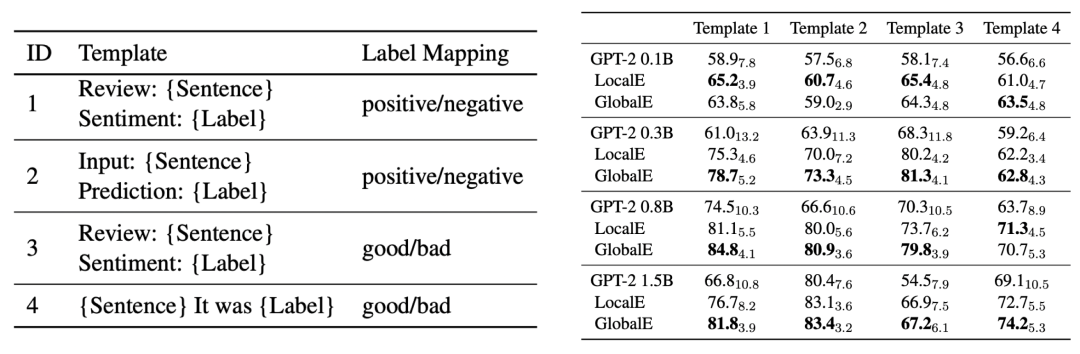
The method in this paper is robust across different prompt templates. When using four different templates for linearized input samples (left figure), the performance improvement of the model is stable and consistent (right figure).
Conclusion
To be honest, when I first saw this material from Xiao Yi, I was reluctant to write it. Mainly because the material description says, “finding that different orders can lead to different results,” and “proposing a method to generate more effective prompts, achieving a relative improvement of 13% across 11 tasks,” I felt it was just a work with superficial embellishments. After all, the order of input samples theoretically has no value, and the improvement of this paper might just be a coincidence discovered in an imperfect method (in-context learning) regarding a specific point (display order), resulting in an insignificant improvement.
However, after reading it, I felt this paper has many merits and deserved to be an outstanding paper. On one hand, the authors reveal that this instability due to order changes is prevalent across various tasks and does not vary with model size or labeled sample size through thorough experiments. Moreover, the fluctuation range is vast, and there is no regularity. Of course, if it only achieved this, it would merely be a negative report, a decent short article. The authors also look for invariance amidst change, discovering the patterns in predicted label distributions caused by different prompt orders, thus proposing an entropy-based prompt selection method, which has been validated for effectiveness. This makes the work interesting.
Although this article discovers phenomena and provides solutions, it lacks linguistic theoretical/intuitional analysis behind these phenomena. It seems a bit insufficient for a paper in ACL (as opposed to ICLR/IJCAI). Are there commonalities in these good orders linguistically? How are these good orders generated? Do they correlate with certain language distributions in the pre-training corpus? Why are some validation set data sensitive to prompt sample orders? Which data is sensitive, and which is not? Do sensitive and non-sensitive data exhibit certain linguistic characteristics?
In addition, there are some questions worth further exploration in this paper. For example, does this instability only occur in autoregressive language models like GPT? Do models like T5 and BART still have this issue? Is the main experimental test set with only 256 samples too few, thus increasing instability? What changes would be observed with a large-scale test set? Are the results consistent when applying the experiments done on SST-2 to all 11 tasks? The authors mention that the entropy-based method has relatively low improvement for sentence pair matching tasks. Do the patterns discovered in this paper still exist for non-classification tasks like fill-in-the-blank, which were tried with GPT-3? Not exploring these questions does not affect the integrity of this paper, but the answers to these questions are indeed quite intriguing.
Finally, I would like to complain about the writing format of this paper. For example, the camera-ready limit is 9 pages, but this paper only has 8 pages, yet Table 1 has a very small font, making it difficult to read. Also, the text in Figure 6 is too small, making it hard to see. The formatting of the appendix is also a nightmare for perfectionists. Of course, these are somewhat nitpicking, but it is probably not unreasonable to nitpick a paper that is outstanding~ If you are interested in some writing format suggestions, you can refer to my previous article: A Thorough Compilation: Pay Attention to These Details in Paper Writing to Significantly Improve Manuscript Quality, or its subsequent version organized on GitHub: https://github.com/MLNLP-World/Paper-Writing-Tips
Author: python
PhD in NLP from Peking University. Regularly writes papers, codes on Zhihu, and solves problems on LeetCode. Mainly focuses on question answering, dialogue, information extraction, pre-training, intelligent law, and other areas. Currently a top Python competitor in LeetCode (often drops down). My Zhihu ID is Erutan Lai, and my LeetCode ID is pku_erutan. Feel free to visit my profiles!
Recommended Works
To be frank, your experimental conclusions may heavily rely on the random seed! AllenAI releases the universal question-answering system MACAW! Excelling at all types of questions, significantly outperforming GPT-3! AllenAI releases the universal question-answering system MACAW! Excelling at all types of questions, significantly outperforming GPT-3! To be frank, your model may not really understand what the prompt is saying
Reply with the keyword 【Join Group】
Join the Cute House NLP, CV, Promotion, and Job Discussion Group