“Knowledge is the driving force of artificial intelligence.” Knowledge engineering aims to study machine representation and computation of human knowledge, making it an important branch of artificial intelligence. Knowledge engineering was first proposed by Turing Award winner Feigenbaum at the 5th International Conference on Artificial Intelligence in 1977, but related research can be traced back to the 1950s, throughout the entire development of artificial intelligence.
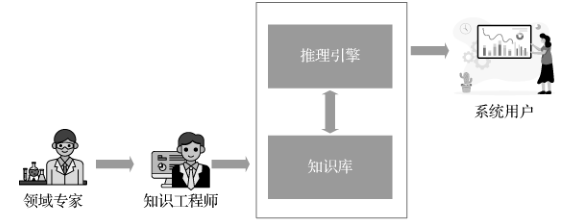
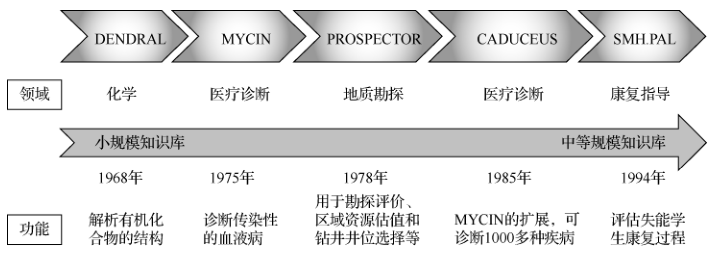
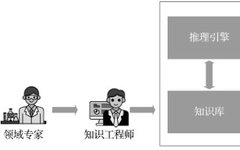
As early as 1956, one of the pioneers of computational linguistics, Richens, designed Semantic Nets as an intermediate language for machine translation, which is the prototype of subsequent semantic networks and knowledge graphs. In 1958, another Turing Award winner, McCarthy, who proposed the concept of “artificial intelligence,” invented the LISP language that supports symbolic reasoning, which became an important tool for knowledge engineering. In 1965, Feigenbaum collaborated with chemist Lederberg to develop the first expert system, DENDRAL, for identifying unknown organic molecules. In the 1970s, artificial intelligence entered its first “winter period,” but knowledge engineering experienced rapid development, continuing into the 1980s. Major advancements included three aspects: first, the logic programming language PROLOG, which has pattern matching and automatic backtracking capabilities; second, various types of knowledge bases, such as the common sense knowledge base Cyc and the semantic dictionary WordNet; third, expert systems in different fields, such as the MYCIN system for diagnosing infectious bacteria and the Xcon system for helping customers configure computers. During this period, significant achievements were also made in our country. Academician Wu Wenjun proposed the “Wu Elimination Method” in automatic reasoning. Academician Lu Ruqian designed the knowledge engineering language TUILI and led the development of the expert system development environment “Tianma.” AI historian McCorduck analyzed the rapid development of knowledge engineering during this period, believing that the main reason was that people realized that intelligence largely depends on knowledge processing.
In the 1990s, artificial intelligence entered its second “winter period,” and this time knowledge engineering did not escape. The main reason was that traditional knowledge engineering exposed a series of defects, in addition to the well-known “knowledge acquisition bottleneck,” traditional knowledge engineering also struggled to cope with perceptual tasks and tasks requiring common sense and cross-domain knowledge. Such tasks are widespread in practical engineering problems.
Professor Zheng Qinghua’s team began researching this field during the second “winter period” of artificial intelligence, focusing on three issues: expert knowledge base construction, rule conflict detection and resolution, and rule scheduling engines. The series of algorithms proposed were used to solve practical engineering problems such as abnormal detection of off-budget invoices in the finance and taxation field and optimization of cold rolling process flows in processing enterprises. This was the first attempt to solve problems that were difficult for humans to address, achieving good results in detection accuracy and production efficiency. However, these problems generally still belong to simple problems with defined scenarios, clear rules, and distinct boundaries. For complex problems with dynamic scenarios, unknown rules in advance, and fuzzy boundaries, such as tax evasion identification, autonomous driving, and personalized navigation of learning content, the research work at that time was still difficult to apply. For example, in the case of tax evasion identification, the research faced the “knowledge acquisition bottleneck” dilemma, the reason for this problem lies in the fact that tax evasion behavior is often intricate and constantly evolving, coupled with continuous reforms and adjustments in tax policies. Therefore, even seasoned tax experts find it challenging to summarize relatively systematic and complete identification rules. Thus, it gradually became clear that knowledge engineering cannot rely solely on expert knowledge. On one hand, expert systems face challenges such as high labor costs and limitations of expert experience; on the other hand, expert systems struggle to adapt to dynamic scenarios and unclear rules, and it is essential to dynamically mine knowledge from practical scenarios and data to solve practical engineering problems.
The times are the examiners. In the 21st century, with the advent of the big data era, knowledge engineering faces new opportunities and challenges, leading to the emergence of big data knowledge engineering. Its core task is to transform the scattered, miscellaneous, and chaotic fragmentary knowledge in a big data environment into structured knowledge that can be represented and computed by machines, which is a common requirement and an inevitable path for various fields such as education, government affairs, finance, and healthcare to transition from informatization to intelligentization. The McKinsey Global Institute report points out that knowledge engineering is one of the 12 disruptive technologies that will shape the future economy, with vast application and industrial prospects, expected to create a value of $5.2 trillion, equivalent to the value created by 110 million laborers.
However, big data knowledge engineering faces entirely new theoretical and technical challenges, characterized by cross-source data, cross-domain knowledge, and cross-media representation, facing scientific questions on how to integrate and generate knowledge systems from spatially dispersed, multimodal, superficially presented, and complexly related fragmentary knowledge. Traditional databases, expert systems, etc., cannot solve this problem, and knowledge graphs are insufficient to depict hierarchical cross-domain knowledge systems, thus requiring theoretical innovation. As pioneers in the field of big data knowledge engineering, Professor Zheng Qinghua’s team proposed the original concept of knowledge forest in 2011, establishing a theoretical and technical system of big data knowledge engineering centered on the knowledge forest. The inspiration for proposing the knowledge forest concept comes from the epistemological insight of “seeing both the trees and the forest,” creatively utilizing “leaves – trees – forests” to represent “fragmentary knowledge – thematic knowledge – knowledge systems,” establishing formal logic from fragmentary knowledge to knowledge systems, revealing the spatiotemporal characteristics and distribution laws of fragmentary knowledge in the big data environment, establishing a hierarchical and thematic knowledge forest model, and developing a series of models, algorithms, and tools for knowledge forest construction, reasoning, etc., initially constructing a set of theories and methods for big data knowledge engineering, achieving a new paradigm that complements the advantages of “data fitting + rule induction” and “numerical computation + symbolic reasoning,” promoting the leap from expert knowledge acquisition to knowledge mining and integration from big data in knowledge engineering.
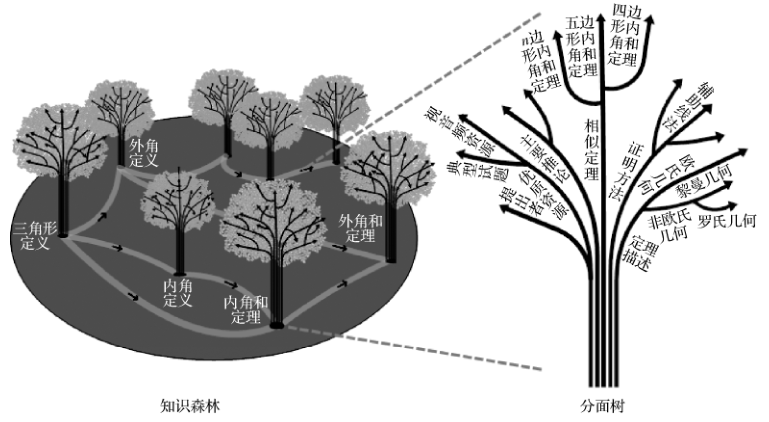
▲Examples of Knowledge Forest Related to “Triangles”
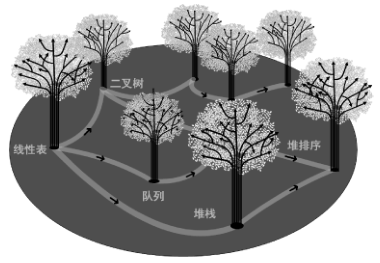
▲Knowledge Forest Schematic Diagram
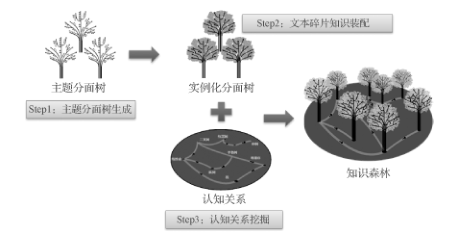
▲The Automatic Construction Process of Knowledge Forest
The value of the big data knowledge engineering theory lies in its ability to break through the inherent deep problems of traditional deep learning models, such as process black box, large parameter scale, and high training cost, as a fusion of “knowledge-guided + data-driven” methods. At the same time, its practical value has also been confirmed in applications such as tax evasion identification in the Golden Tax project and personalized guidance in online education knowledge forests. Additionally, this achievement has been successfully applied in fields such as financial risk management and judicial case event tracing.
Although big data knowledge engineering has made significant progress, it remains an emerging research field. As artificial intelligence gradually transitions from perceptual intelligence to cognitive intelligence, it poses new challenges for knowledge acquisition, representation, memory, and reasoning, especially in complex, time-varying, heterogeneous big data environments (visual knowledge, common sense knowledge, etc.), where knowledge acquisition and representation, causal reasoning and explainable machine learning, brain-inspired knowledge coding and memory still face many unresolved issues.
The book “Big Data Knowledge Engineering” summarizes the stage research achievements of Professor Zheng Qinghua’s team and peers at home and abroad in the field of big data knowledge engineering, systematically presenting them to readers, helping them grasp the development context of this field, understand classic models and algorithms, and clarify future research directions, striving to become a “stepping stone” for readers entering this research field.
The book has a total of 9 chapters, and its organizational structure is shown in the figure below. The content involved in big data engineering is extensive, and this book strives to cover the basic concepts and key technologies related to big data knowledge engineering.
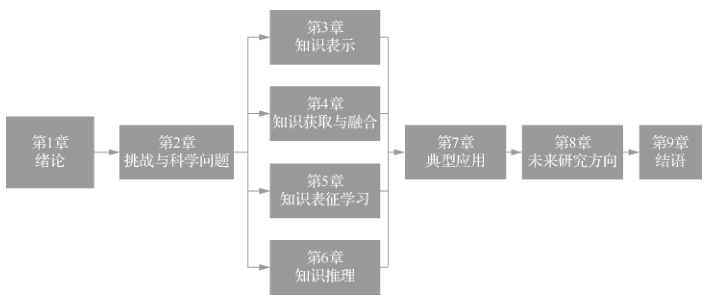
The first chapter mainly covers an overview of big data knowledge engineering, first introducing the background, purpose, significance, and typical examples of knowledge engineering, and then analyzing the problems faced by big data knowledge engineering and its relationship with the new generation of artificial intelligence.
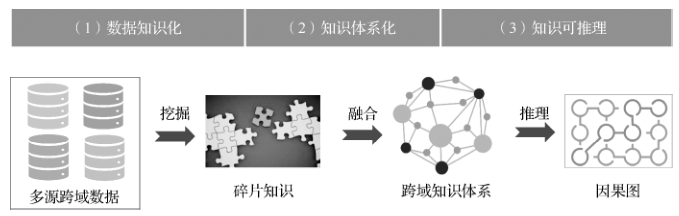
The second chapter introduces the “three crosses” characteristics of big data knowledge engineering and the three challenges of being scattered, miscellaneous, and chaotic, proposing a general research framework of “data knowledge transformation → knowledge systematization → knowledge reasoning.”
Chapters 3 to 6 respectively introduce the four core links of big data knowledge engineering, where Chapter 3 summarizes the research status and trends of knowledge representation, introducing traditional knowledge representation methods and three big data knowledge representation methods. Chapter 4 elaborates on the acquisition and integration of fragmentary knowledge in the big data era, introducing methods for the automatic construction of knowledge graphs, logical formulas, and knowledge forests. Chapter 5 discusses the research status and trends of knowledge representation learning, and provides representation learning methods for three different knowledge structures: knowledge graphs, heterogeneous graphs, and logical formulas. Chapter 6 discusses traditional knowledge reasoning methods, memory-based reasoning models, and symbolic hierarchical learning models, and discusses the application of knowledge reasoning in knowledge retrieval and intelligent Q&A.
Chapter 7 introduces application cases of big data knowledge engineering in education, taxation, and online public opinion fields, including personalized guidance in knowledge forests, intelligent tax governance, and intelligent monitoring of online public opinion.
Chapter 8 discusses future research directions of big data knowledge engineering from three aspects: complex big data knowledge acquisition, hybrid learning of knowledge-guided + data-driven, and brain-inspired knowledge coding and memory.
Chapter 9 summarizes the entire book.


Zheng Qinghua, PhD, Professor, recipient of the National Outstanding Youth Fund, head of the National Natural Science Foundation Innovation Group, head of the Ministry of Education Innovation Team and Shaanxi Province Key Scientific and Technological Innovation Team, leader of the “National Level Teaching Team for Computer Networks and Architecture,” recipient of 3 National Science and Technology Progress Second Prizes, First and Second Prizes of National Teaching Achievements twice, and 6 Provincial and Ministerial Level Science and Technology Progress First Prizes. Currently serves as the director of the Ministry of Education Key Laboratory of Intelligent Networks and Network Security, National Supervisor, member of the Ministry of Education Science and Technology Committee, and chairman of the Ministry of Education University Computer Teaching Guidance Committee. He has received honors such as the He Liang He Li Foundation Science and Technology Award, the China Association for Science and Technology “Qiu Shi” Outstanding Youth Award, the China Youth Science and Technology Award, special allowances from the State Council, Baosteel Excellent Teacher Special Prize, National Excellent Backbone Teacher, Google China Excellent Teacher Award, IBM China Excellent Teacher, and National Advanced Worker in Science and Technology Innovation in the Information Industry. Research field: big data knowledge engineering.
Big data knowledge engineering aims to acquire knowledge from big data, represent knowledge, and perform reasoning calculations based on this knowledge to solve practical engineering problems in the context of big data. Big data knowledge engineering is an inevitable path for the transition from informatization to intelligentization. This book comprehensively and systematically introduces the relevant content of big data knowledge engineering. The book consists of 9 chapters, with Chapter 1 introducing the background of big data knowledge engineering; Chapter 2 introducing the “three crosses” characteristics of big data knowledge engineering and the challenges of being “scattered, miscellaneous, and chaotic”; Chapters 3 to 6 introducing the four core links of knowledge representation, knowledge acquisition and integration, knowledge representation learning, and knowledge reasoning; Chapter 7 introducing applications of big data knowledge engineering in education, taxation, and online public opinion; Chapter 8 pointing out future research directions; and Chapter 9 summarizing the book.
This book is suitable for teachers and graduate students in computer science, artificial intelligence, the Internet of Things, etc., and can also serve as a reference for researchers in fields such as knowledge representation, knowledge graphs, information knowledge retrieval, and question-answer reasoning.
Preface
Chapter 1 Introduction 11.1 Development History of Knowledge Engineering 11.2 Overview of Big Data Knowledge Engineering 31.2.1 Background 31.2.2 Basic Concepts 41.2.3 Differences from Traditional Knowledge Engineering 51.3 Relationship with the New Generation of Artificial Intelligence 61.3.1 Characteristics of the New Generation of Artificial Intelligence 61.3.2 Big Data Knowledge Engineering as a Common Technology 71.4 Organization of This Book 71.5 Summary of This Chapter 8References 9Chapter 2 Challenges and Scientific Issues 112.1 Characteristics of the “Three Crosses” 112.2 Three Challenges of Being Scattered, Miscellaneous, and Chaotic 122.3 Research Framework and Scientific Issues 162.4 Summary of This Chapter 18References 18Chapter 3 Knowledge Representation 213.1 Research Status and Trends 213.2 Traditional Knowledge Representation Methods 233.3 Knowledge Graphs 263.3.1 Definition of Knowledge Graphs 263.3.2 Classification of Knowledge Graphs 263.3.3 Storage of Knowledge Graphs 283.4 Event Graphs 293.4.1 Definition of Event Graphs 303.4.2 Data Model of Event Graphs 313.4.3 Common Event Graphs 323.5 Knowledge Forests 333.5.1 Background of Knowledge Forests 333.5.2 Definition of Knowledge Forests 343.5.3 Storage Model of Knowledge Forests 373.6 Summary of This Chapter 39References 39Chapter 4 Knowledge Acquisition and Integration 424.1 Research Status and Trends 424.1.1 Research Status 424.1.2 Challenges and Development Trends 444.2 Automatic Construction of Knowledge Graphs 454.2.1 Triple Knowledge Extraction 454.2.2 Triple Knowledge Integration 494.3 Logic Formula Extraction 504.3.1 Formal Definition of Logic Formulas 514.3.2 Statistical Extraction Methods 524.3.3 Matrix Sequence-Based Extraction Methods 544.3.4 Relation Path-Based Extraction Methods 564.3.5 Challenges and Outlook 574.4 Automatic Construction of Knowledge Forests 574.4.1 Theme Facet Tree Generation 584.4.2 Text Fragment Knowledge Assembly 614.4.3 Cognitive Relation Mining 634.4.4 Knowledge Forest Visualization 674.5 Summary of This Chapter 70References 71Chapter 5 Knowledge Representation Learning 755.1 Research Status and Trends 755.1.1 Research Status 765.1.2 Challenges and Development Trends 785.2 Knowledge Graph Representation Learning 795.2.1 Direct Learning 795.2.2 Inductive Learning 825.3 Heterogeneous Graph Representation Learning 845.3.1 Shallow Heterogeneous Information Network Representation Learning 855.3.2 Deep Heterogeneous Information Network Representation Learning 875.3.3 Challenges and Development Trends 915.4 Logic Formula Representation Learning 925.4.1 Sequence-Based Methods 935.4.2 Tree Structure-Based Methods 935.4.3 Graph Structure-Based Methods 955.4.4 Challenges and Development Trends 975.5 Summary of This Chapter 98References 98Chapter 6 Knowledge Reasoning 1026.1 Research Status and Trends 1026.1.1 Basic Concepts 1026.1.2 Research Status 1036.1.3 Challenges and Development Trends 1066.2 Memory-Based Reasoning Models 1066.2.1 Role of Memory Mechanisms in Reasoning 1076.2.2 Neural Turing Machines 1076.2.3 Differentiable Neural Computers 1116.2.4 Summary of Memory Models 1146.3 Symbolic Hierarchical Learning Models 1156.3.1 SHiL Model 1156.3.2 Construction Method of SHiL Model 1166.3.3 Hierarchical Division and Area Recognition of Complex Data Systems 1176.3.4 Inter-Area Control Mechanism of Symbolic Differentiable Programming 1186.3.5 Cross-Boundary Reasoning Path Generation 1216.4 Knowledge Retrieval 1246.4.1 Basic Concepts 1246.4.2 Typical Knowledge Retrieval Methods 1266.4.3 Why-Not Problem in Knowledge Retrieval 1306.4.4 Challenges and Development Trends 1326.5 Intelligent Q&A 1336.5.1 Natural Language Q&A 1336.5.2 Visual Q&A 1376.5.3 Textbook-style Q&A 1406.5.4 Question Generation 1456.6 Summary of This Chapter 150References 150Chapter 7 Typical Applications 1547.1 Personalized Guidance in Knowledge Forests 1547.1.1 Knowledge Forest Navigation Learning System 1557.1.2 Knowledge Forest AR Interactive Learning 1587.1.3 Application Demonstration 1617.2 Intelligent Tax Governance 1637.2.1 Construction of Tax Knowledge Base 1637.2.2 Tax Benefit Calculation 1717.2.3 Intelligent Identification of Tax Evasion Risks 1767.3 Intelligent Monitoring of Online Public Opinion 1797.3.1 Definition and Construction of Public Opinion Networks 1807.3.2 Analysis of Public Opinion Network Applications 1817.4 Summary of This Chapter 185References 185Chapter 8 Future Research Directions 1868.1 Complex Big Data Knowledge Acquisition 1868.1.1 Visual Knowledge 1868.1.2 Common Sense Knowledge 1918.1.3 Knowledge Proliferation and Quality-Quantity Transformation 1968.2 Hybrid Learning of Knowledge-Guided + Data-Driven 1988.2.1 Differentiable Programming 1998.2.2 Counterfactual Reasoning 2038.2.3 Explainable Machine Learning 2088.3 Brain-Inspired Knowledge Coding and Memory 2128.3.1 Cognitive Maps Inspired by Dual Process Theory 2128.3.2 Knowledge Memory and Reasoning Inspired by Hippocampal Theory 2148.4 Summary of This Chapter 217References 217Chapter 9 Conclusion 222Acknowledgments 224



Contact us!

Science Press



Science Press Video Channel
Hardcore and Informative Audio-Visual Science
Spreading science, welcome to light up★ the star mark, like, and watch ▼