
Click on the above “China Computer Federation” to subscribe easily!
Source: “China Computer Federation Communications”, Issue 5, 2017, “Column”
As artificial intelligence upgrades from perceptual intelligence to cognitive intelligence, the importance of Natural Language Processing (NLP) has become increasingly prominent. On one hand, NLP is driven by big data and deep learning, making varying degrees of progress in various key technologies; on the other hand, NLP penetrates various fields, deeply integrating with knowledge service industries such as education, healthcare, and law, while new application models like virtual/physical robots connect with offline services. This article attempts to outline the development of NLP technology using the evolution of knowledge acquisition methods as the main line, and further explore how big data closely collaborates with deep learning to promote the development of NLP.
The issues in natural language processing require the use of knowledge constraints.
Various issues in natural language processing can be abstracted as: How to select a correct mapping from the many-to-many mapping of form and meaning based on context. For example, in the phrase “playing basketball,” the word “play” means to “engage in,” while in “buying soy sauce,” it means to “purchase.” In the context at that moment, which meaning is needed must be chosen and disambiguated. Similarly, in text generation, to express the meaning “someone has died,” one would use “sacrificed” for heroes, “passed away” for emperors, and “shot” for criminals. The same linguistic form can express multiple meanings, and the same meaning can be expressed by various linguistic forms. This many-to-many mapping relationship between form and meaning makes language expression both concise and rich, but it poses significant obstacles for machines to process language, which is also the core problem that NLP aims to solve.
Why do humans not need to stop and speculate whether “play” means “engage in” or “purchase” when reading the phrase “playing basketball”? Because humans have rich background knowledge. Similarly, machines need to utilize knowledge to break the dilemma of the many-to-many mapping of form and meaning. However, the knowledge that machines possess is insufficient, and this lack of knowledge is the main obstacle to the development of NLP.
After decades of development in NLP, researchers have been providing knowledge to machines, but why is knowledge still far from sufficient? This is because, first, language is complex and dynamic, and organizing and depicting it is no easy task. Secondly, to understand language, mere linguistic knowledge is not enough; common sense knowledge and specialized knowledge are also required. Without understanding the non-linguistic knowledge that language carries, one cannot truly comprehend language. Moreover, this non-linguistic knowledge, especially common sense knowledge, is the hardest to acquire because it has been integrated into people’s subconscious and is self-evident in various communications, hence it is not explicitly written online. Finally, knowledge is dynamic; even if machines possess all human knowledge, which knowledge should be used in a specific context remains a challenging issue.
Three Elements of Knowledge Acquisition in Natural Language Processing
We need to utilize knowledge to help machines impose constraints. Knowledge in NLP can generally be divided into two categories: explicit knowledge and implicit knowledge. Explicit knowledge is primarily provided by domain experts and can be intuitively understood by humans, while implicit knowledge is automatically acquired from data using learning algorithms. Implicit knowledge is mainly represented in the form of parameters, making it difficult for humans to understand intuitively. Data and learning algorithms are key to acquiring implicit knowledge. Explicit knowledge, data, and learning algorithms are the three elements of knowledge acquisition in NLP.
1. Explicit Knowledge: This is knowledge that humans can intuitively construct and interpret. Within explicit knowledge, there is a unique type of knowledge called “meta-knowledge.” Meta-knowledge is knowledge about knowledge, such as the hierarchical structure of an NLP system or the characteristics of a language object to be recognized. Meta-knowledge plays a crucial role in NLP systems. Besides meta-knowledge, NLP systems also require the following knowledge: (1) Linguistic knowledge, such as WordNet for English, “Da Cilin” for Chinese, and rules for machine translation; (2) Common sense knowledge, such as CYC (Note: CYC is an artificial intelligence project dedicated to integrating ontologies and common sense knowledge from various fields and achieving knowledge reasoning based on this integration, which began in 1984.); (3) Specialized knowledge, such as knowledge graphs. This knowledge can be compiled manually or automatically collected and constructed. Automatically constructed knowledge bases may contain a certain percentage of errors, which can be refined through manual proofreading. Automated knowledge bases are cost-effective, have broad coverage, and are easy to update dynamically, thus their flaws are overshadowed by their advantages, making them increasingly favored.
2. Data: Data is not knowledge; it is the source of knowledge. Data can be divided into labeled data, unlabeled data, and pseudo-data. Labeled data is when labels (answers) are applied to raw data manually, typically seen in manually annotated tokenization, part-of-speech tagging, and syntactic analysis corpora; unlabeled data does not have labels and can be utilized by unsupervised learning algorithms; pseudo-data consists of labeled training data, but these labels are not obtained through manual annotation for the problem at hand, but are naturally generated or automatically constructed. The labels in pseudo-data are approximate answers (pseudo) rather than precise answers. Although the labels are not precise, due to the vast scale of data, even infinite data, pseudo-data has high usage value.
3. Learning Algorithms: NLP has greatly absorbed research achievements from machine learning in terms of algorithms, while also continuously driving the development of machine learning through practical issues in NLP. Before the rise of deep learning, NLP commonly used manually defined feature templates to extract features and feature combinations, combined with shallow learning models like Support Vector Machines (SVM) and Conditional Random Fields (CRF); today, deep learning models like Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN) dominate the NLP field, mainly due to their ability to automatically learn effective features and feature combinations.
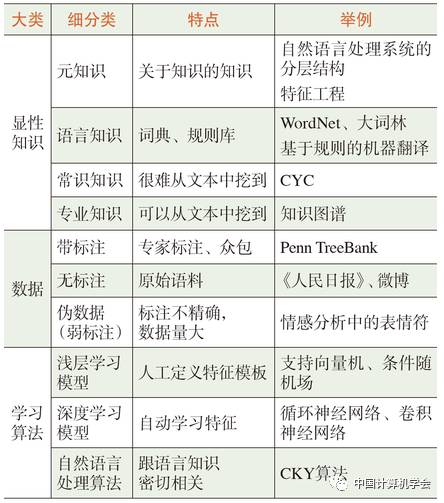
Table 1: Three Elements of Knowledge Acquisition in Natural Language Processing
The Evolution of Knowledge Acquisition Methods in Natural Language Processing
Figures 1-4 illustrate several stages in the evolution of knowledge acquisition methods in NLP. It can be seen that the true source of knowledge is people. There are three types of people providing knowledge: domain experts, annotators, and the general public. Among the annotators are full-time data annotators, part-time students, and annotators on crowdsourcing platforms. Meanwhile, computer experts develop relevant algorithms to obtain implicit knowledge from data.
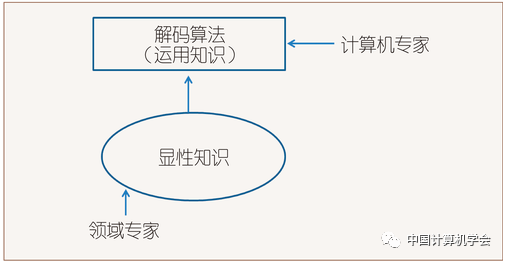
Figure 1: Expert System
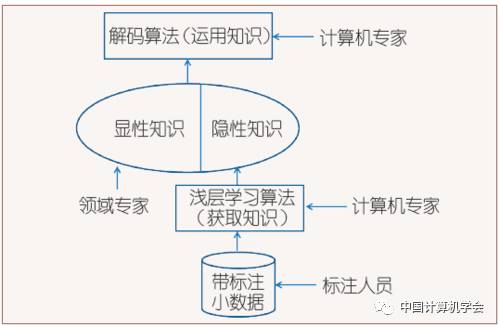
Figure 2: Corpus-Based Method
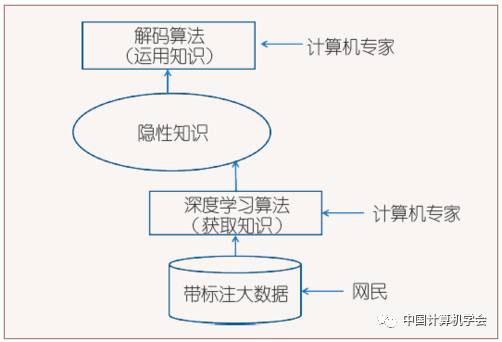
Figure 3: Deep Learning Based on Big Data
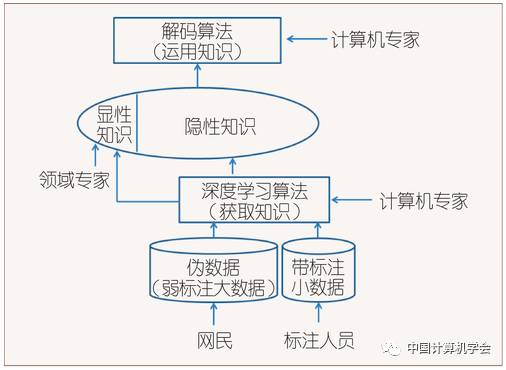
Figure 4: Deep Learning Based on Pseudo-Data
Figure 1 shows the era of expert systems, where domain experts (mainly linguists) directly provide explicit knowledge. Figure 2 depicts the period dominated by the corpus-based method. In the corpus-based method, meta-knowledge provided by domain experts still plays an important role, such as determining the hierarchical structure of the NLP system and the features of the objects to be recognized. Compared to the language knowledge compiled by experts through introspection, the knowledge contained in the small-scale data annotated by annotators is more comprehensive, accurate, and quantifiable. With the rise of deep learning’s end-to-end approach, for some simple problems, if enough big data can be found, knowledge is acquired according to the pattern shown in Figure 3, where explicit knowledge is completely sidelined. Deep learning systems almost do not require meta-knowledge provided by domain experts, as the machine itself determines features and assigns functions to each layer, although the division of these functions is implicit and difficult to explain. However, for many problems, labeled data is limited, even very limited, so the ideal situation shown in Figure 3 is rare. Figure 4 presents a more realistic solution: combining large-scale “pseudo-data” with small manually annotated data while also accepting some meta-knowledge provided by domain experts, thus, in the case of insufficient data, with the help of human effort, the pursuit of optimal system performance is achieved.
When reviewing the development of NLP, we can see that knowledge acquisition methods are continuously evolving: from acquiring expert knowledge through expert introspection to having dedicated personnel annotate small-scale datasets, this evolution has freed NLP from reliance on the limited experience of individual experts; from dedicated annotation to attracting numerous internet users for “crowdsourcing,” which has reduced annotation costs and expanded the scope and scale. However, “crowdsourcing” still requires researchers to actively find people to consciously label a batch of data, and due to cost reasons, the data scale remains limited. Thus, the emergence of “naturally labeled big data” has occurred, utilizing the records people unconsciously leave while using the internet to obtain data labels. For instance, when a blog author submits a blog post, the author tags it to make it easier for readers to search, and objectively, the machine can utilize this tag as a basis for blog classification or keyword extraction. In summary, in the field of NLP, knowledge acquisition is evolving along the route of continuously reducing costs and expanding scale, from manual to automatic, from explicit to implicit, and from dedicated annotation to pseudo-data, and the knowledge available for NLP continues to enrich.
Big Data and Deep Learning Collaborate to Promote the Development of Natural Language Processing
The key to an NLP system is knowledge acquisition. Among the three elements of knowledge acquisition, at least one must be improved or breakthrough achieved to bring about an increase in the overall system performance of NLP. In other words, without the addition of new knowledge, new data, or new algorithms to the NLP system, the system’s capabilities will not improve.
In recent years, which of the three elements of knowledge acquisition in NLP has been the main driving force? The answer is primarily data, which is the big data rich in collective wisdom contributed by users while using the internet and mobile internet; secondly, deep learning, which fully unleashes the potential of big data. It can be said that it is the combination of “big data + deep learning” that has driven this wave of NLP enthusiasm. The contribution of explicit knowledge is mainly reflected in meta-knowledge and knowledge graphs, while the role of traditionally manually constructed linguistic knowledge has been very limited in recent years.
Big data and deep learning are interdependent: on one hand, big data requires complex learning models. This was previously controversial; some believed that with big data, models could become very simple. In extreme cases, having complete data could solve problems through lookup tables. However, the fact we see is that for most AI problems, the amount of data is always insufficient, and if one wants to depict big data in detail, especially long-tail data, complex models are required; only complex models can accurately depict the intricacies of big data and fully unleash its potential.
On the other hand, deep learning requires big data. Deep learning is not omnipotent; its effectiveness is significantly reduced when data is insufficient. As shown in Table 2, deep learning has the most obvious advantages in simple problems with large-scale training data. For more complex issues, such as machine translation, significant progress can be made if there is sufficient bilingual aligned corpus (such as Chinese-English). In the past two years, neural machine translation (NMT) has rapidly surpassed statistical machine translation (SMT). However, in some language analysis problems defined by humans (such as part-of-speech tagging and deep semantic analysis), due to the impossibility of obtaining sufficient big data, even for simple problems, deep learning has not significantly surpassed traditional methods, and in complex problems, it may even have disadvantages. Because problems are complex and data volume is insufficient, the more powerful the learning tool, the more likely it is to overfit, which naturally leads to poor outcomes.
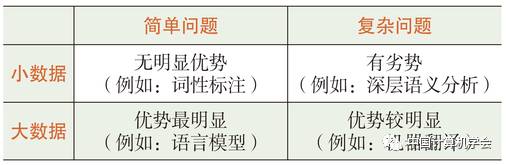
Table 2: The Effectiveness of Deep Learning in Natural Language Processing Problems
From the analysis above, it can be concluded that once large-scale training data is available, the power of deep learning is immense, capable of swiftly replacing existing technologies with overwhelming momentum. Such technological opportunities must be highly valued and actively seized. It should be emphasized that the so-called “deep learning” methods here are key to the “end-to-end” approach, which delegates all work from input to output to the machine, rather than artificially layering it. Below, we will illustrate this with “information extraction” as an example. There are two approaches to information extraction: one is to perform syntactic analysis first and then extract information; the other is to directly extract information, the latter being the so-called “end-to-end”. In the end-to-end model, there are also layers, but the machine itself processes the layers, and the meanings of each layer are not intuitively understandable. When training data for end-to-end is insufficient, human assistance is required, such as dividing the information extraction process into two steps: first, creating a syntactic tree (this step adds explicit knowledge but also introduces errors); second, implementing information extraction. When sufficient training data for end-to-end is available, it can be done in one step—directly extracting information, and the performance is better. Similar to information extraction are sentiment binary classification, inter-sentence relationship classification, and question-answer matching.
The advancements made by the end-to-end method have even led to questions about whether traditional core NLP problems, such as syntactic analysis and semantic analysis, still hold value or are simply false propositions. Our view is that many problems are complex and it is challenging to find sufficient training data; therefore, the involvement of human explicit knowledge, especially meta-knowledge (the definition of syntactic trees itself is also explicit meta-knowledge), remains necessary.
Conclusion
Various issues in natural language processing can be abstracted as: How to select a mapping from the many-to-many mapping of form and meaning based on context. To enable machines to break the dilemma of many-to-many mapping of form and meaning, knowledge constraints must be utilized. The three elements of knowledge acquisition are: explicit knowledge, data, and learning algorithms. Knowledge acquisition is evolving continuously along the route of reducing costs and expanding scale, from manual to automatic, from explicit to implicit, and from dedicated annotation to pseudo-data.
The arrival of big data has provided deep neural networks with a platform to operate. If there is enough big data, end-to-end deep learning methods can significantly enhance the performance of NLP systems, but due to the high cost of manually annotated data, it is challenging to expand the data scale. How to transplant, collect, and create large-scale pseudo-data, and how to combine large-scale pseudo-data with small-scale manually annotated data, has become an important research topic for applying deep learning to NLP problems, and this method has already shown powerful capabilities.
Author:

Liu Ting
CCF Council Member, Professor at Harbin Institute of Technology. His main research directions are natural language processing and social computing.

Che Wanxiang
CCF Senior Member, Associate Professor at Harbin Institute of Technology. His main research direction is natural language processing.
CCF Recruitment
【Featured Articles】
Zhou Yuanyuan: Bridging the Gap Between Academia and Industry
Chen Xilin: The Academic Community Should Focus on Scientific Research and Science Popularization
Du Zide: The Crisis of CCF
Zheng Yu: AlphaGo Has Not Conquered the Go Problem; Humanity Still Has Hope
Huang Tiejun: The Legend of Computers (Part 1) The Birth of Computers
Du Zide: Why Should the Association Have Members?
Du Zide: The Non-Profit Nature and Commercial Operations of Societies
Shan Shiguang, Yan Shuicheng, Li Hang, Yu Kai: How Long Can the Benefits of Combining Deep Learning and Big Data Last?
Zheng Yu: This Era Lacks Data, What It Lacks Is Sufficiently Open-Minded Thinking
【High-Quality Videos】
Li Guojie: Re-Understanding the Information Age
Zheng Yu: Applications of Deep Learning in Spatio-Temporal Data
Zhang Xiaodong: Building World-Class Universities Should Pursue Scientific Spirit and Return to the Essence of Education
Job Positions: Project Management, Publication Editing, Senior Secretarial, Website Construction, Graphic Design, New Media Operations, Membership Development, Human Resources, etc.
Resume Submission: [email protected]
CCF provides employees with six insurances and one fund, annual leave, free health checks, meal subsidies, transportation, communication allowances, a comprehensive training system, rich team-building activities, and salaries and bonuses above the industry average!
Join CCF and work with top experts in the field of computer science!
Reply “Recruitment” in the public account response box to view recruitment details.
For more exciting reports from CCF, please follow the WeChat public account.
