

Abstract: AI large models are an important research direction in the field of natural language processing and a fundamental technology in artificial intelligence, playing an increasingly prominent role in social production and life. In recent years, the application range of AI large models has been continuously expanding, and their applications in language processing have gradually matured; however, certain technical challenges still exist in the field of large model research. This article analyzes and studies the application strategies of AI large models in the field of natural language processing, aiming to provide reference and insights for relevant personnel.
Keywords: Natural Language Processing, Artificial Intelligence, Large Models
AI large models refer to the use of artificial intelligence technology to integrate various technologies and process natural language through artificial intelligence techniques, mainly including deep learning and reinforcement learning. In practical applications, it is necessary to scientifically and reasonably process data to ensure that large models function effectively in the field of natural language processing. Currently, a large number of large models have emerged in the field of natural language processing, which can analyze and understand text, speech, images, etc., improving the level of natural language processing technology.
The rapid development and application of artificial intelligence technology have promoted the emergence of new business models and formats such as digital economy, smart manufacturing, smart agriculture, and smart cities, bringing great convenience to people’s production and life. Among them, AI technology centered on big data and deep learning plays a key role. With the support of large model technology, the artificial intelligence industry has transitioned from a traditional single technology model to a new model of human-machine collaboration[1].
Currently, AI large models play an increasingly important role in the field of language processing. For example, Google has proposed the Google BERT pre-training model, which can generate high-quality language models with a prediction accuracy of up to 92.5%; Microsoft developed a pre-training model based on the BERT model, achieving over 99% accuracy on multiple datasets; Baidu developed a Transformer NLP pre-training model based on the Transformer model, achieving over 93% accuracy on multiple datasets; and iFlytek developed the “iFlytek Super Brain” platform based on NLP technology, which constructs an intelligent voice interaction system using its speech recognition and machine translation technologies. In addition to the field of natural language processing, AI large models have extensive applications in machine translation, question-answer systems, intelligent writing, and other areas.
From an application perspective, large models are widely used in various fields. For instance, in the field of speech recognition, the application of speech synthesis technology helps people convert their voices into text more quickly; many companies have chosen to use large models for speech synthesis; in the field of machine translation, large models have achieved intelligent translation in multiple scenarios; in the field of image recognition, large models are widely applied in scenarios such as autonomous driving and robotics, and can even assist humans in precise recognition[2].
From a technical perspective, the development of AI large models faces many challenges. On one hand, the scale of model parameters is continuously increasing, leading to a stronger dependence on data; on the other hand, the quality requirements for data are becoming increasingly high, especially regarding understanding human emotions and semantics. Additionally, large models face issues such as insufficient computational power and high computational costs. There are still many urgent problems to be solved in AI large models, such as limitations regarding data quality and algorithm architecture; further research is needed to address application scenarios and data interpretability across different industries and enterprises.
3.1 Text Information Processing
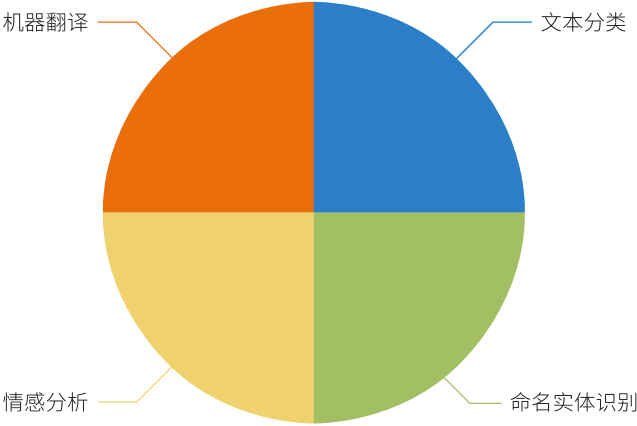
Large models have wide applications in text information processing. Applications in the field of natural language processing can be divided into four categories: text classification, named entity recognition, sentiment analysis, and machine translation (see Figure 1). Text classification is the foundation of text information processing. Based on pre-training models, text can be transformed into vector representations for tasks such as sentiment analysis, named entity recognition, and entity relationship extraction. In text classification, large models, leveraging their powerful feature learning capabilities, have reached levels comparable to humans. Named entity recognition tasks involve transforming text into corresponding entity representations, such as “Zhang San” and “Li Si”. This task is quite challenging, and traditional methods mainly rely on manual annotation. In named entity recognition tasks, large models have many advantages: they have a large number of parameters during training, can complete tasks without annotated data, can automatically learn and process a large amount of labeled data, and can be applied in multiple domains. Sentiment analysis involves analyzing and understanding text to derive conclusions or opinions. In sentiment analysis, large models can utilize their strong feature learning capabilities to convert text into vector representations. Sentiment analysis is mainly divided into sentiment polarity analysis and sentiment tendency analysis, and currently, the application of large models in sentiment analysis is still insufficient[3]. Machine translation refers to the process of translating between different languages using computers.
3.2 Machine Translation
In the internet era, machine translation has become an important means of daily communication, and the introduction of large models can significantly enhance the effectiveness of machine translation, especially when training models on large-scale corpora, which can yield better translation results. In the field of machine translation, commonly used technologies include rule-based and statistical methods. Rule-based methods are simple, easy to implement, and yield good results; while statistical methods have developed in recent years to effectively handle large-scale data but suffer from low training efficiency and poor accuracy. Recently, transformer-based machine translation models such as BLEU, WMT2019, and TTBLE2020 have emerged. However, traditional models have drawbacks such as high computational resource consumption and slow training speeds, which cannot meet the demands of machine translation tasks under large-scale data conditions. To address these issues, researchers have proposed various solutions, such as using large-scale data to enhance model performance and efficiency.
3.3 Question-Answer Systems
Question-answer systems are important applications of natural language processing technology, helping users quickly and accurately obtain answers and improving user experience. In the field of natural language processing, rule-based question-answer systems have been shown to have significant performance bottlenecks when handling complex problems, while statistical model-based question-answer systems have considerable room for improvement in performance. The key to traditional rule-based question-answer systems lies in constructing a sufficiently large corpus and knowledge graph, but this method clearly cannot meet the actual needs for large amounts of natural language data[4].
Currently, large models have been widely applied in the field of natural language processing, with models such as BERT, GPT-2, GRU, and SQuAD achieving remarkable results in various domains. Among them, BERT is one of the earliest large-scale pre-training models and is currently the best pre-training model in the field of natural language processing[5]. The encoder consists of bidirectional LSTMs to extract the most important information from sentences; the decoder consists of three layers of LSTMs, where the first two layers extract the highest and lowest probabilities of each word in the input text, respectively; the last layer employs an attention mechanism to obtain the highest and lowest relevance between each word in the input text and its context[6].
3.4 Text Classification and Sentiment Analysis
Text classification and sentiment analysis are classic problems in the field of natural language processing. With the advent of the big data era, algorithms for text classification and sentiment analysis have rapidly developed, becoming one of the most important tasks in the field of natural language processing. For example, for sentiment analysis tasks, a certain team proposed a method that combines pre-trained language models and deep learning algorithms, and evaluated it on multiple datasets. One advantage of these methods is that they can learn from data without expert assistance[7]. In addition to text classification and sentiment analysis tasks in the field of natural language processing, a certain team has also utilized deep learning and reinforcement learning to solve other problems, such as product recommendations and online fraud detection. For instance, this team introduced reinforcement learning methods in the field of natural language processing to improve the accuracy of recommendation systems, designing a reinforcement learning strategy to predict which recommendations users are most likely to click when purchasing products. The team collected data through interactions with users and learned how to reward users to enhance recommendation accuracy[8].
3.5 Multilingual Processing
Multilingual processing (MLP) refers to analyzing and understanding texts in different languages, such as machine translation and cross-language information retrieval. Large models play a significant role in multilingual processing, with models like GPT-3, BERT, and TensorFlow being multilingual models. The primary challenges in multilingual processing include: first, the complex semantic relationships between different languages, where the meanings of multiple words or terms may vary significantly; second, the differences in word order between different languages may lead to certain deviations in semantic expression; and third, the syntactic relationships between different languages may also vary, requiring the integration of grammatical information from multiple languages[9].
In summary, in the current applications of large models, downstream tasks are often fine-tuned based on pre-training tasks. Therefore, for pre-training tasks, researchers need to build datasets, pre-training models, and downstream tasks from scratch for specific domains, which limits the breadth of large model applications. At the same time, pre-training tasks often cannot meet the requirements of specific domains or applications[10].
References:
1 Hu Zile, Zhao Yi, Zhang Chengzhi. A Study on the Relationship Between the Institutional Composition of International Cooperation Teams in the Field of Natural Language Processing and Their Academic Influence. Information Science: 1-19 [2024-04-17]. http://kns.cnki.net/kcms/detail/22.1264.G2.20240403.1414.008.html.
2 Kong Qingzhao, Ji Keyan, Xiong Bing, et al. Assessment of Urban Building Damage Based on Media Word Clouds and Natural Language Processing. Engineering Mechanics: 1-10 [2024-04-17]. http://kns.cnki.net/kcms/detail/11.2595.O3.20240321.1840.028.html.
3 Zhang Shihong, Lai Degang, Huang Tingting. Research on Emotion Analysis Algorithms Based on Recurrent Neural Networks (RNN) in Natural Language Processing. China Informatization, 2024(3): 59-60, 92.
4 Li Chunlei. Research on the Application of Knowledge Services in Digital Publishing in the New Era: Opportunities and Challenges of Natural Language Processing Technology Empowering Digital Publishing Driven by Artificial Intelligence. China Media Technology, 2024(3): 56-59.
10 Wang Lening, Gao Min, Chen Gong’e, et al. Intelligent Research and Application of Natural Language Processing in Standardized Water and Electricity Operations. Water and Electricity Energy Science, 2024, 42(3): 195-199.


For more content, please subscribe to the magazine “High Technology and Industrialization”
Address: 33 North Fourth Ring West Road, Zhongguancun, Haidian District, Beijing (100190) Phone: 010-62539166
Email: [email protected]
Website: http://www.hitech.ac.cn
http://www.hitech.ac.cn
12 issues a year, 58 yuan per issue, annual subscription price 696 yuan
Postal code: 82-741
ISSN: 1006-222X CN11-3556/N