Click on the above “Xiaobai Learns Vision“, select “Star” or “Pin“
Important content delivered immediately
Authors: Matt H and Daniel R
Compiled by: ronghuaiyang
Introduction
Experience and lessons accumulated from thousands of hours of model training.

In our machine learning lab, we have accumulated thousands of hours of training on many high-performance machines. However, it is not only the computers that have learned a lot in this process: we have made many mistakes and fixed many errors ourselves.
Here, based on our experience (mainly based on TensorFlow), we present some practical tips for training deep neural networks. Some suggestions may seem obvious to you, but they were not for some of us. Other suggestions may not apply or may even be bad advice for your specific task: use them cautiously!
We acknowledge that these are well-known methods. We also stand on the shoulders of giants! The purpose of this article is simply to summarize them at a high level for practical use.
General Tips
- Use the ADAM optimizer. It works really well. I prefer it over traditional optimization methods like plain gradient descent. Note: If you want to save and restore weights, remember to set the
<span>AdamOptimizer</span>first and then set the<span>Saver</span>, because ADAM also has states to restore (i.e., learning rates for each weight). - ReLU is the best non-linearity (activation function). This is a bit like saying Sublime is the best text editor. But in reality, ReLUs are fast, simple, and surprisingly effective, and they do not suffer from the vanishing gradient problem. While sigmoid is a common textbook activation function, it does not propagate gradients well through DNNs.
- Do not use an activation function in the output layer. This should be obvious, but it is an easy mistake to make if you build each layer with a shared function: make sure to turn off the activation function at the output.
- Always add a bias in every layer. This is ML 101: a bias essentially shifts the plane to the best position. In
<span>y=mx+b</span>, b is the bias, allowing the line to move up or down to the “best fitting” position. - Use variance-scaled initialization. In TensorFlow, like
<span>tf.contrib.layers.variance_scaling_initializer()</span>. In our experience, this generalizes/scales better than conventional Gaussian distributions, truncated normal distributions, and Xavier. Roughly speaking, variance scaling initialization adjusts the variance of the initial random weights based on the number of inputs or outputs of each layer (the default in TensorFlow is based on the number of inputs), helping signals propagate deeper into the network without needing additional “tricks” like clipping or batch normalization. Xavier is a similar method, but it has the same variance across all layers, which may not handle the varying shapes of layers well in networks with large shape changes (usually convolutional networks). - Whiten (normalize) your input data. During training, subtract the mean of the dataset and then divide by its standard deviation. The less you stretch and scale in various directions, the faster and easier your network will learn. Keeping the mean of the input data centered with a constant variance helps address this issue. You must also perform the same normalization on each test input, so ensure your training set is similar to real data.
- Scale input data in a way that reasonably retains its dynamic range. This relates to normalization but should be done before normalization. For example, data “x” with an actual range of [0,140000000] can usually be processed with
<span>tanh(x)</span>or<span>tanh(x/C)</span>, where<span>C</span>is some constant that stretches the curve to fit more input range into the dynamic, sloped part of the tanh function. Particularly in cases where one or both ends of the input data may be unbounded, neural networks can learn better between (0,1). - Do not bother lowering the learning rate (usually). Learning rate decay is more common in SGD, but ADAM handles this issue naturally. If you absolutely want to squeeze every ounce of performance: reduce the learning rate for a short time at the end of training, and you may see a sudden, very small drop in error, after which it flattens again.
- If your convolutional layers have 64 or 128 filters, that may be enough. Especially for deep networks. In fact, 128 is already quite a lot. If you already have a large number of filters, adding more may not improve performance.
- Pooling is used for translation invariance. Pooling essentially allows the network to learn the “gist” of an image. For example, max pooling can help convolutional networks become robust to translations, rotations, and scalings of features in images.
Debugging Neural Networks
If your network is not learning (meaning: during training, the loss is not converging, or you are not getting the results you expect), try the following suggestions:
- Overfitting! If your network is not learning, the first thing to do is to make the network overfit on a single data sample. In this case, the accuracy should be 100% or 99.99%, or the error close to 0. If your neural network cannot overfit a single data point, there may be a serious problem with the architecture, but the issue can be subtle. If you can overfit a data point but training on a larger set still does not converge, try the following suggestions.
- Lower the learning rate. Your network will learn more slowly, but it may reach a minimum it couldn’t reach before because its step size was too large. (Intuitively, when you really want to get into a ditch where your error is lowest, imagine crossing a roadside ditch.)
- Increase the learning rate. This will speed up training and help tighten the feedback loop, meaning you will know sooner if your network is working. While the network should converge faster, its results may not be good, and the process of “convergence” may actually jump around. (When using ADAM, we found ~0.001 to be a very good value in many experiments.)
- Reduce the minibatch size. Reducing the minibatch size to 1 can provide finer-grained feedback related to weight updates, and you can use TensorBoard (or other debugging/visualization tools) to report these updates.
- Remove batch normalization. As the batch size reduces to 1, this can cause gradient vanishing or exploding. For several weeks, our network did not converge, and when we removed batch normalization, we realized that the outputs were NaN in the second iteration. Batch norm is a band-aid for something that needs a tourniquet. It has its place, but only when your network is bug-free.
- Increase the minibatch size. A larger minibatch – if possible, use the entire training set – reduces variance in gradient updates, making each iteration more precise. In other words, it ensures the direction of weight updates is correct. But! Its usefulness has an effective ceiling, limited by physical memory. Generally, we find this not as useful as the first two suggestions, which reduce the minibatch size to 1 and remove batch normalization.
- Check your reshaping. Severe reshaping (like changing the X, Y dimensions of images) can destroy spatial locality, making it harder for the network to learn, as it also has to learn the reshaping. (Natural landscapes become fragmented. Natural features are local in space, which is why conv nets are so effective. Be particularly careful when using multiple images/channels for reshape, using
<span>numpy.stack()</span><code><span> for proper alignment.</span> - Double-check your loss function. If using a composite function, try simplifying it to L1 or L2. We find L1 is less sensitive to outliers and adjusts less when encountering noisy batches or training points.
- Carefully check your visualizations, if applicable. Does your visualization library (matplotlib, OpenCV, etc.) scale the values or clip them? Also consider using a color scheme that feels consistent.
Learn with an Example
To bring the above-described process closer to reality, here are some loss graphs (drawn with TensorBoard) for some actual regression experiments of the convolutional neural network we built.
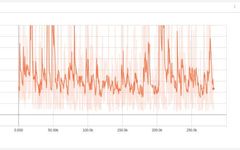
Initially, this network was not learning at all:
We tried clipping the values to prevent them from exceeding limits:
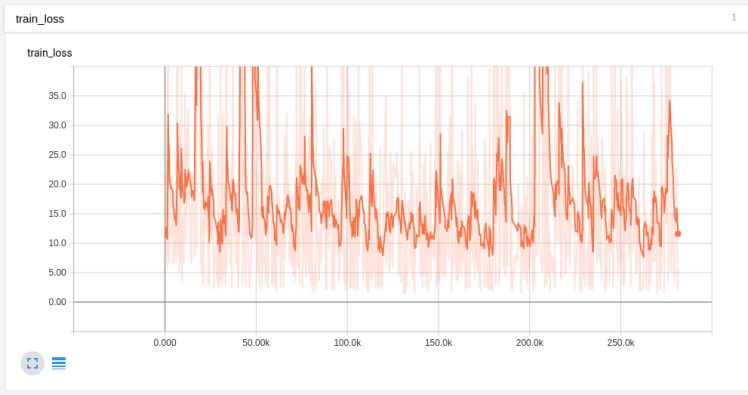
Hmm. Look how crazy these unsmoothed values are. Was the learning rate too high? We tried lowering the learning rate and trained on just one input:
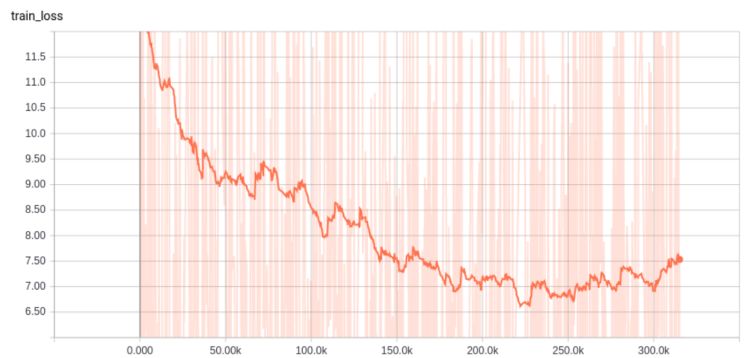
You can see where the initial few changes in learning rate occurred (around step 300 and step 3000). Clearly, we decayed too quickly. So, give it more time before decaying, it can do better:
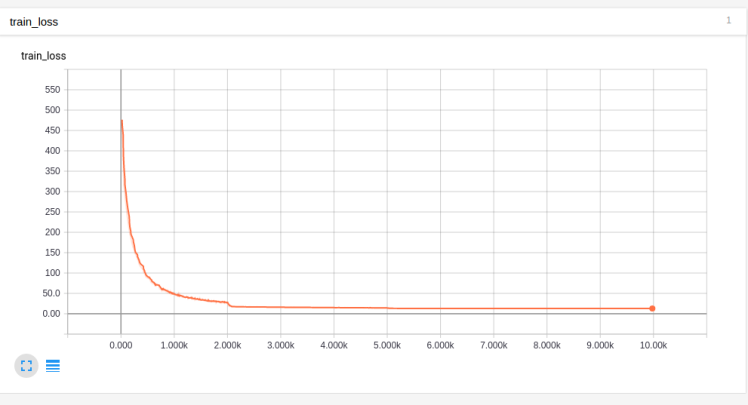
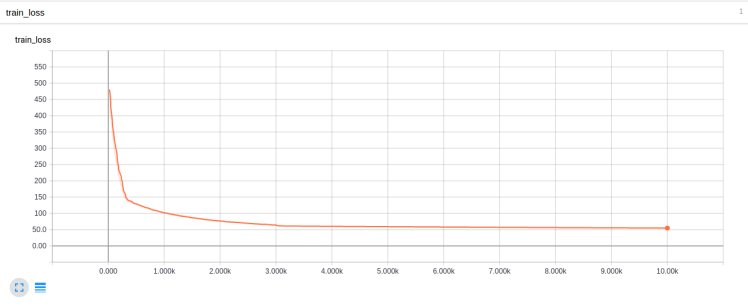
You can see we decayed at steps 2000 and 5000. This is better but still not great as it does not approach 0.
Then, we disabled learning rate decay and tried to shift the values into a narrower range, but not through inputting tanh. While this clearly brought the error value below 1, we still could not overfit the training set:
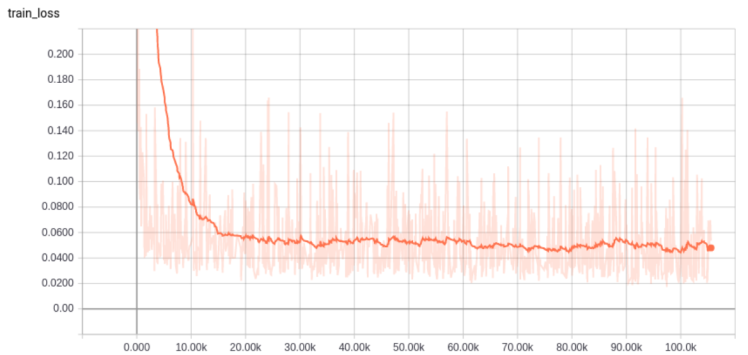
By removing batch normalization, we found that after a few iterations, the network could quickly output NaN. We disabled batch normalization and changed the initialization to variance scaling. These changes made all the difference! We were able to overfit our test set with just one or two inputs. While the bottom graph covers the Y-axis, the initial error value was far above 5, indicating an error reduction of nearly 4 orders of magnitude:
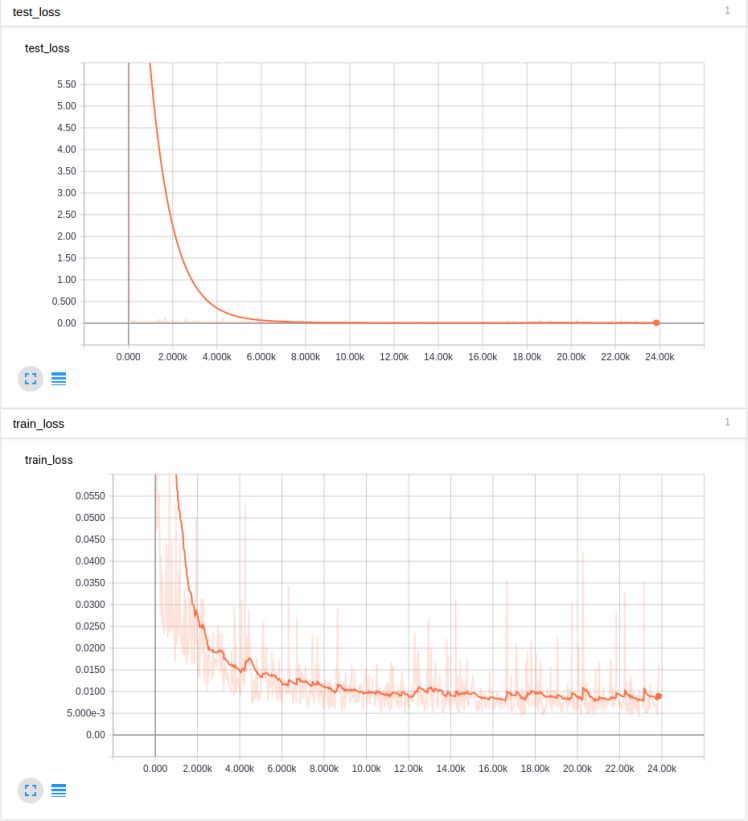
The graph above is very smooth, but you can see it overfits the test inputs very quickly, and the loss for the entire training set dropped below 0.01 over time. This did not decrease the learning rate. After decreasing the learning rate by an order of magnitude, we continued training and got better results:
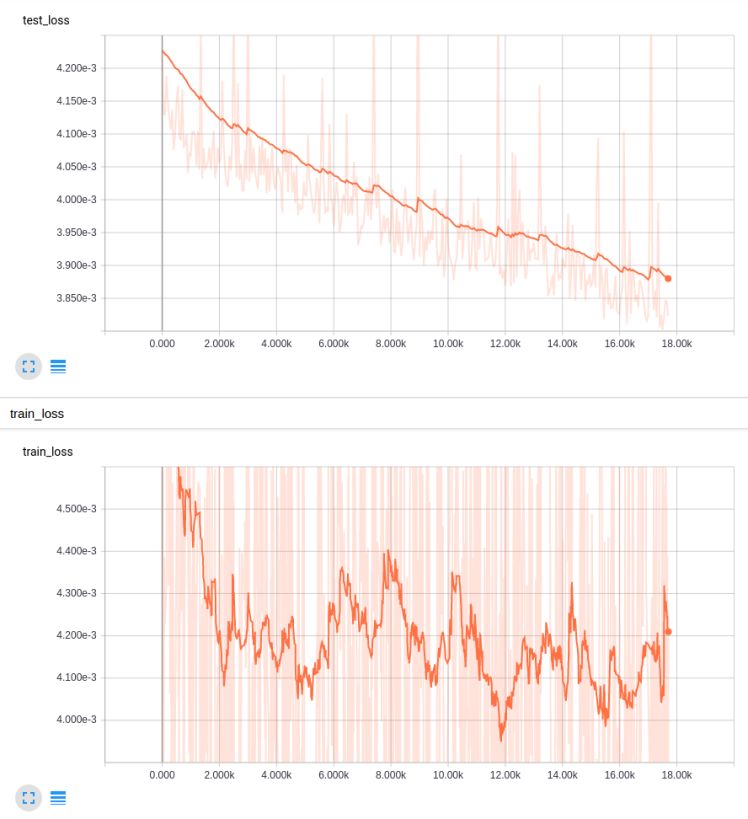
These results are much better! But what if we decay the learning rate geometrically instead of splitting the training into two parts?
Multiplying the learning rate by 0.9995 at each step does not yield good results:
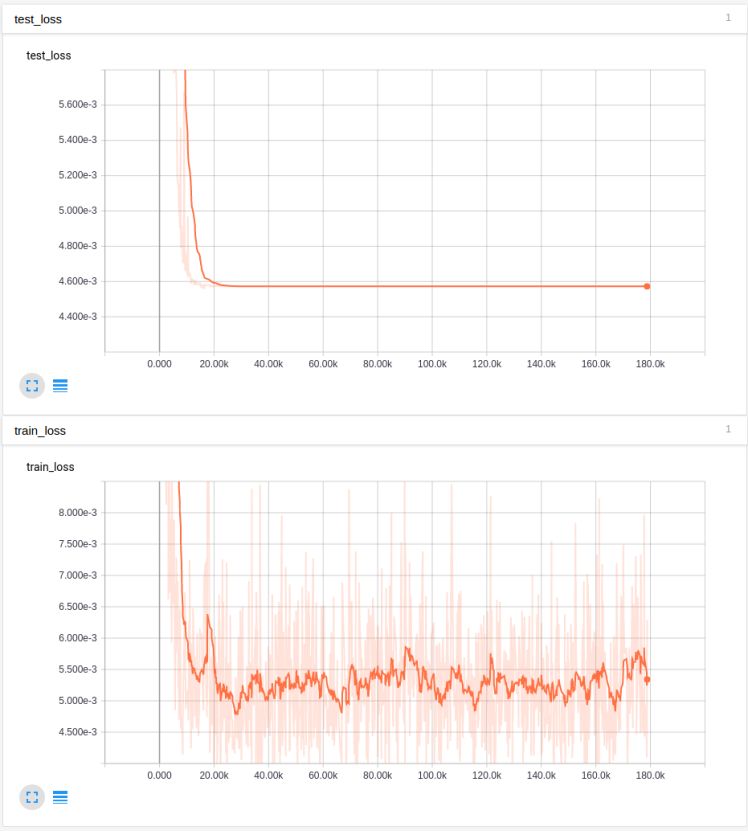
Probably because the decay was too fast, the case with a multiplier of 0.999995 was somewhat better, but the result was almost the same as no decay at all. From this particular sequence of experiments, we concluded that batch normalization masked the severe changes in gradient caused by poor initialization, and lowering the learning rate did not particularly help the ADAM optimizer, except possibly intentionally lowering it at the end. Together with batch normalization, clipping merely covered up the real issue. We also dealt with high variance input values by putting them into tanh.
We hope that as you become more familiar with building deep neural networks, you find these fundamental tips very useful. Often, just a few simple things can change everything.
Good News!
Xiaobai Learns Vision Knowledge Planet
Is now open to the public 👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "Xiaobai Learns Vision" public account to download the first Chinese version of OpenCV extension module tutorial on the internet, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of "Xiaobai Learns Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, it will not be approved. After successful addition, you will be invited to relevant WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~