
Source:DeepHub Imba
This article is approximately 2500 words long and is recommended to be read in 5 minutes. In this article, we will introduce how to implement a simpler HydraNet in Pytorch.
In machine learning, we usually focus on a single task, which means optimizing a single metric. However, Multi-Task Learning (MTL) has achieved success in many applications of machine learning, from natural language processing and speech recognition to computer vision and drug discovery.
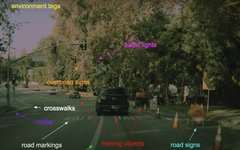
The most famous example of MTL might be Tesla’s autonomous driving system. In autonomous driving, it is necessary to handle a large number of tasks simultaneously, such as object detection, depth estimation, 3D reconstruction, video analysis, tracking, etc. You might think that more than 10 deep learning models are needed, but that is not the case.
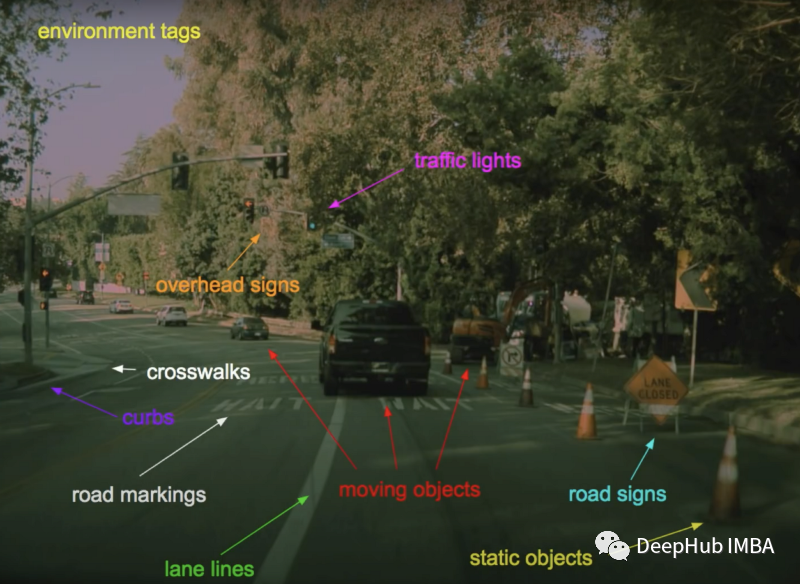
Introduction to HydraNet
In general, the architecture of multi-task learning models is very simple: a backbone network for feature extraction, and then multiple heads are created for different tasks. This allows a single model to solve multiple tasks.
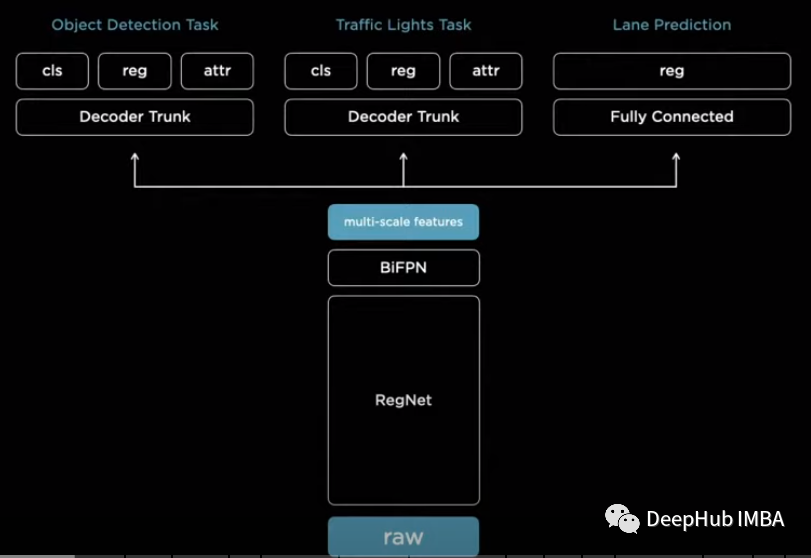
As seen in the image above, the feature extraction model extracts image features. The output is finally split into multiple heads, each responsible for a specific case, and since they are independent of each other, they can be fine-tuned separately!
Tesla’s presentation details this model (YouTube: v=3SypMvnQT_s).
Multi-Task Learning Project
In this article, we will introduce how to implement a simpler HydraNet in Pytorch. We will use the UTK Face dataset, which is a classification dataset with three labels (gender, race, age).
Our HydraNet will have three independent heads, which are different because age prediction is a regression task, race prediction is a multi-class classification problem, and gender prediction is a binary classification task.
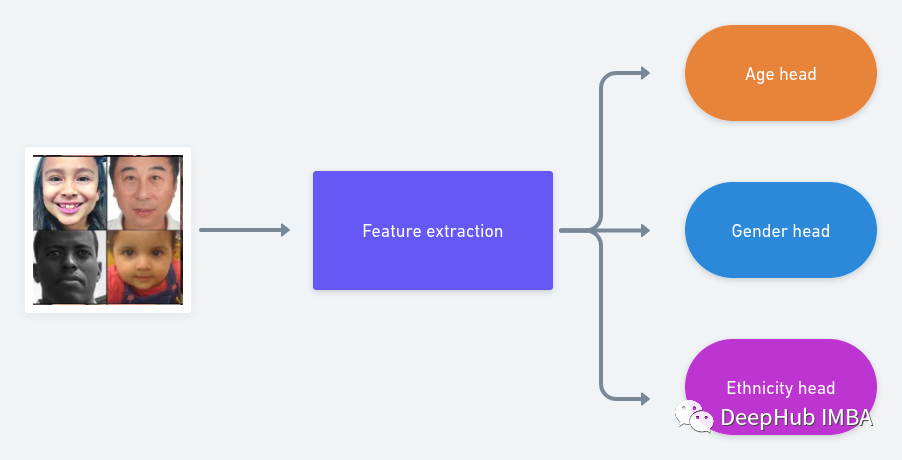
Every deep learning project in Pytorch should start by defining the Dataset and DataLoader.
In this dataset, these labels are defined by the name of the image, for example, UTKFace/30_0_3_20170117145159065.jpg.chip.jpg
-
30 is the age
-
0 is the gender (0: male, 1: female)
-
3 is the race (0: White, 1: Black, 2: Asian, 3: Indian, 4: Other)
So our custom Dataset can be written as follows:
class UTKFace(Dataset): def __init__(self, image_paths): self.transform = transforms.Compose([transforms.Resize((32, 32)), transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) self.image_paths = image_paths self.images = [] self.ages = [] self.genders = [] self.races = [] for path in image_paths: filename = path[8:].split("_") if len(filename)==4: self.images.append(path) self.ages.append(int(filename[0])) self.genders.append(int(filename[1])) self.races.append(int(filename[2])) def __len__(self): return len(self.images) def __getitem__(self, index): img = Image.open(self.images[index]).convert('RGB') img = self.transform(img) age = self.ages[index] gender = self.genders[index] eth = self.races[index] sample = {'image':img, 'age': age, 'gender': gender, 'ethnicity':eth} return sampleTo briefly introduce:
The __init__ method initializes our custom dataset, responsible for initializing various transformations and extracting labels from image paths.
The __getitem__ method loads an image, applies the necessary transformations, retrieves the labels, and returns an element of the dataset, meaning this method returns a single data point (a single sample) from the dataset.
Then we define the dataloader.
train_dataloader = DataLoader(UTKFace(train_dataset), shuffle=True, batch_size=BATCH_SIZE) val_dataloader = DataLoader(UTKFace(valid_dataset), shuffle=False, batch_size=BATCH_SIZE)Next, we define the model, using a pre-trained model as the backbone, and then create three heads representing age, gender, and race.
class HydraNet(nn.Module): def __init__(self): super().__init__() self.net = models.resnet18(pretrained=True) self.n_features = self.net.fc.in_features self.net.fc = nn.Identity() self.net.fc1 = nn.Sequential(OrderedDict( [('linear', nn.Linear(self.n_features,self.n_features)), ('relu1', nn.ReLU()), ('final', nn.Linear(self.n_features, 1))])) self.net.fc2 = nn.Sequential(OrderedDict( [('linear', nn.Linear(self.n_features,self.n_features)), ('relu1', nn.ReLU()), ('final', nn.Linear(self.n_features, 1))])) self.net.fc3 = nn.Sequential(OrderedDict( [('linear', nn.Linear(self.n_features,self.n_features)), ('relu1', nn.ReLU()), ('final', nn.Linear(self.n_features, 5))])) def forward(self, x): age_head = self.net.fc1(self.net(x)) gender_head = self.net.fc2(self.net(x)) ethnicity_head = self.net.fc3(self.net(x)) return age_head, gender_head, ethnicity_headThe forward method returns the results from each head.
The loss is crucial as the basis for optimization because it will affect the model’s performance. The simplest thing we can think of is to sum the losses:
L = L1 + L2 + L3However, in our model:
L1: the loss related to age, such as mean absolute error, since it is a regression loss.
L2: the cross-entropy related to race, which is a multi-class classification loss.
L3: the loss related to gender, such as binary cross-entropy.
The biggest issue with loss calculation here is that the scales of the losses are different, and the weights of the losses are also different. This is a topic that is being deeply researched, and we will not discuss it here; we will simply use a straightforward addition, so some of our hyperparameters are as follows:
model = HydraNet().to(device=device) ethnicity_loss = nn.CrossEntropyLoss() gender_loss = nn.BCELoss() age_loss = nn.L1Loss() sig = nn.Sigmoid() optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.09)Then our training loop is as follows:
for epoch in range(n_epochs): model.train() total_training_loss = 0 for i, data in enumerate(tqdm(train_dataloader)): inputs = data["image"].to(device=device) age_label = data["age"].to(device=device) gender_label = data["gender"].to(device=device) eth_label = data["ethnicity"].to(device=device) optimizer.zero_grad() age_output, gender_output, eth_output = model(inputs) loss_1 = ethnicity_loss(eth_output, eth_label) loss_2 = gender_loss(sig(gender_output), gender_label.unsqueeze(1).float()) loss_3 = age_loss(age_output, age_label.unsqueeze(1).float()) loss = loss_1 + loss_2 + loss_3 loss.backward() optimizer.step() total_training_loss += lossThus, we have completed the most straightforward multi-task learning process.
About Loss Optimization
The loss function for multi-task learning allocates weights to the losses of each task. In this process, it is crucial to ensure that all tasks are equally important and that simpler tasks do not dominate the entire training process. Manually setting weights is inefficient and not optimal; therefore, it is necessary to learn these weights automatically.
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics cvpr_2018
This paper proposes to bring different losses to a unified scale, making it easier to unify. The specific method is to use the uncertainty of the same variance, treating uncertainty as noise for training.
End-to-End Multi-Task Learning with Attention cvpr_2019
This paper proposes a mechanism that can automatically adjust weights (Dynamic Weight Average), making weight allocation more reasonable. The general idea is that each task first calculates the ratio of the corresponding loss from the previous epoch, then divides it by a fixed value T, performs an exp mapping, and calculates the proportion of each loss.
Finally, if you are interested in multi-task learning, you can first take a look at this paper:
A Survey on Multi-Task Learning arXiv 1707.08114
This paper surveys MTL from the perspectives of algorithm modeling, applications, and theoretical analysis, making it the best introductory material.
Edited by: Yu TengkaiProofread by: Lin Yilin