Introduction
This article provides an overall introduction to the LlamaIndex framework, including its functions, components, and explanations.
LlamaIndex is an open-source LLM application development framework built on large models (including Agents and Workflows) to create context-enhanced generative AI applications.
Components of LlamaIndex
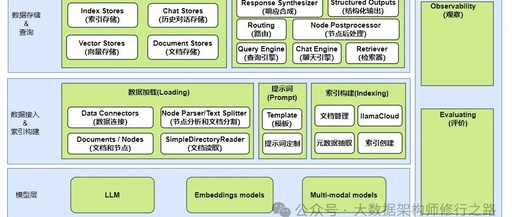
The following diagram illustrates the overall functional structure of LlamaIndex, abstracted from the functional components provided by LlamaIndex, to facilitate a comprehensive understanding of its functions and components.
Layer 1: Model Layer
The bottom layer is the model, upon which many upper-level applications are built based on the foundational large models. Here, I depict indexing as part of the first layer. This layer includes three types of models:
-
Large models, including open-source and closed-source large models, such as OpenAI, Llama3.2, Qwen, etc.
-
Embedding models: used to convert high-dimensional data (such as text, images, or other types of data) into low-dimensional vector representations (embeddings). These vectors can capture the semantic or feature information of the data, making it easier to manipulate and compute in mathematical space.
-
Multimodal models: a type of machine learning model capable of processing and relating data from various types (modalities). Common modalities include text, images, audio, video, sensor data, etc. These models provide more comprehensive solutions for complex tasks by learning the relationships and interactions between different modalities.
Layer 2: Data Access and Indexing
The second layer includes three functional aspects: data loading, prompt management, and index construction. The storage and indexing functionalities can only be achieved based on the features provided by this layer.
-
Data Loading
The key to data acquisition in LlamaIndex is loading and transformation. After loading documents, you can process them through transformation and output nodes (Nodes). LlamaIndex provides hundreds of libraries for loading data from external sources, allowing data acquisition from any data source. Additionally, LlamaParse provides PDF parsing capabilities.
-
Prompt Management
LlamaIndex uses a set of out-of-the-box default prompt templates. Additionally, there are some prompts specifically written for chat models such as GPT-3.5-turbo. Users can also provide their own prompt templates to further customize the framework’s behavior. The best method for customization is to copy the default prompts from the above link and use them as a basis for any modifications.
-
Index Construction
An index is a data structure that allows us to quickly retrieve relevant context for user queries. For LlamaIndex, it is the core foundation for retrieval-augmented generation (RAG) use cases. At a high level, indexes are constructed based on documents. They are used to build query engines and chat engines, enabling question answering and chatting based on your data.
At the lower level, indexes store data in Node objects (blocks representing the original documents) and expose support for additional configuration and automation through retriever interfaces. The most common type of index to date is the VectorStoreIndex.
Layer 3: Storage and Querying
With the accessed data and indexes, you can save the data and indexes to the corresponding databases or files, providing data querying capabilities for the upper layers.
-
Storage
LlamaIndex offers a high-level interface for ingesting, indexing, and querying external data.
At the lower level, LlamaIndex also supports interchangeable storage components, allowing you to customize:
(1) Document storage: where the ingested documents (i.e., Node objects) are stored.
(2) Index storage: where index metadata is stored.
(3) Vector storage: where embedding vectors are stored.
(4) Property graph storage: where knowledge graphs are stored (i.e., PropertyGraphIndex).
(5) Chat storage: where chat messages (including historical messages) are stored and organized. Document/index storage relies on a general key-value storage abstraction, which is detailed below.
LlamaIndex supports persistent data storage in any storage backend supported by fsspec. We have confirmed support for the following storage backends:
(1) Local filesystem
(2) AWS S3
(3) Cloudflare R2
-
Querying
Querying is the most important part of LLM applications. For more information on obtaining deployable end products, please refer to the query engine and chat engine.
(1) The query engine is a general interface that allows you to ask questions about the data. The query engine accepts natural language queries and returns rich responses. It is typically (but not always) built on one or more indexes through a retriever. You can combine multiple query engines for more advanced functionality.
(2) The chat engine is an advanced interface for conversing with your data (multiple back-and-forth interactions rather than a single question and answer). Think of it as ChatGPT but enhanced with your knowledge base. Conceptually, it is the stateful analogy of the query engine. By tracking conversation history, it can answer questions based on past context.
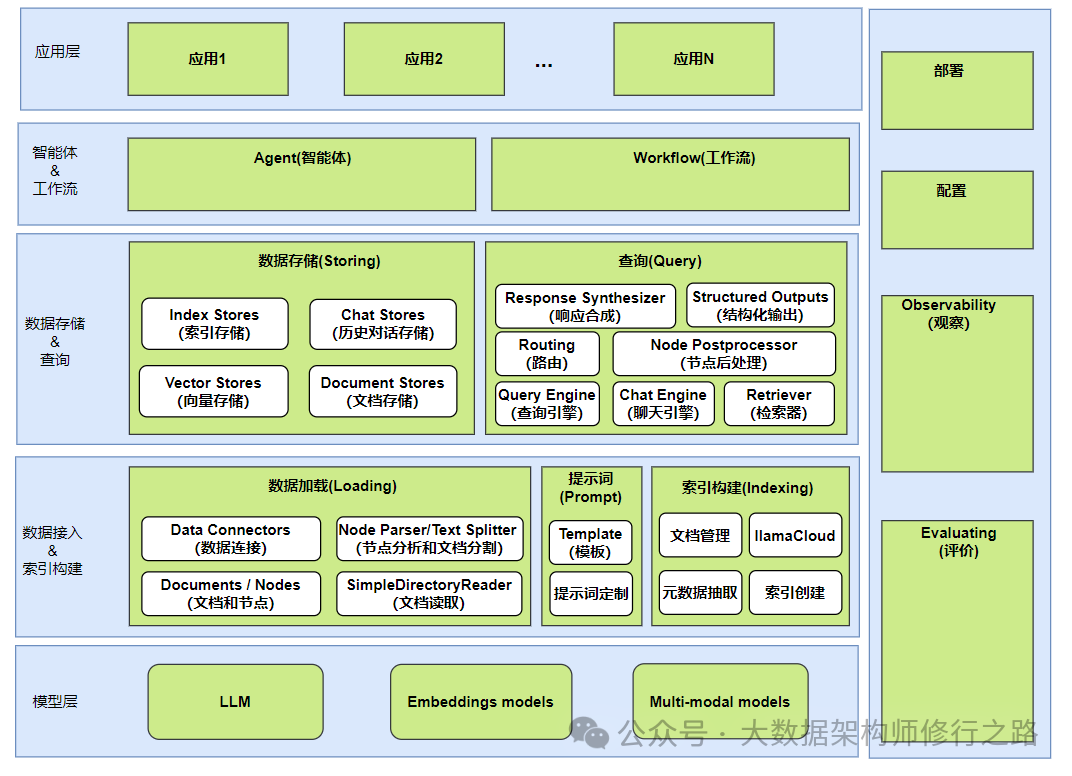
Layer 4: Agents and Workflows
Based on the index, queries, and the capabilities of large models, relevant objects and interfaces for agents can be provided, allowing applications to be built based on these foundational interfaces.
-
Agents
Data Agents are knowledge workers supported by LLM in LlamaIndex, capable of intelligently performing various tasks on data through “reading” and “writing” functionalities. They have the ability to:automatically search and retrieve different types of data (unstructured, semi-structured, and structured).Structurally call any external service API, handle responses, and store them for later use.
In this sense, Agents go beyond our query engine, as they can not only “read” from static data sources but also dynamically fetch and modify data from various tools.Building data Agents requires the following core components:
(1) Reasoning loop
(2) Tool abstractionData Agents are initialized through a set of APIs or tools for interaction;
Agents can call these APIs to return information or modify state. Given an input task, the data Agent uses the reasoning loop to determine which tools to use, in what order, and the parameters for each tool call.
-
Workflows
Workflows in LlamaIndex are event-driven abstractions used to link multiple events together. A workflow consists of steps, each responsible for processing certain types of events and emitting new events.Workflows in LlamaIndex work by decorating functions with the @step decorator. This is used to infer the input and output types of each workflow for validation and ensure that each step runs only when the accepted events are ready.
You can create a workflow to perform any operation! Build Agents, RAG flows, extraction flows, or any other you desire. Workflows are also automatically detected, so you can use tools like Arize Phoenix to observe each step. (Note: Observability applies to integrations utilizing newer instrumentation systems. Usage may vary.)
General Components: Model Evaluation, Observability, Configuration, and Deployment
-
Evaluation
Evaluation and benchmarking are key concepts in the development of LLM applications. To improve the performance of LLM applications (RAG, agents), you must have a method to measure them.
LlamaIndex provides key modules for measuring the quality of generated results. We also provide key modules for measuring retrieval quality. Response evaluation: Does the response match the retrieved context? Does it match the query? Is it consistent with the reference answer or guideline? Retrieval evaluation: Are the retrieved sources relevant to the query?
-
Observability
LlamaIndex provides one-click observability, allowing you to build principled LLM applications in production environments. A key requirement for principled development of LLM applications based on data (RAG systems, agents) is the ability to observe, debug, and evaluate your system – whether as a whole or for each component. This feature allows you to seamlessly integrate the LlamaIndex library with powerful observability/evaluation tools provided by our partners.
Configure variables once, and you can:
(1) View LLM/prompt input/output
(2) Ensure that the output of any component (LLM, embedding) operates as expected
(3) View the call tracing of indexes and queriesEach provider has similarities and differences. Please refer to the complete guide for each item below!
-
Configuration
Settings are a set of common resources used in the indexing and querying stages of LlamaIndex workflows/applications. You can use it to set global configurations. Local configurations (transformations, LLM, embedding models) can be directly passed to the interfaces using them.Settings are a simple singleton object that exists within your application. When specific components are not provided, the Settings object will be used to provide them as global defaults.
-
Deployment
Llama Deploy (formerly known as llama-agents) is an asynchronous-first framework for deploying, scaling, and producing multi-service systems based on llama_index workflows. With Llama Deploy, you can build any number of workflows in llama_index and run them as services, accessible via HTTP API through the user interface or other parts of the system.
The goal of Llama Deploy is to easily transform what you build in notebooks into something that runs in the cloud, with minimal changes to the original code (possibly none). To make this transition enjoyable, the inherent complexity of running agents as services is managed by a component called the API Server, which is the only user-facing component in Llama Deploy. You can interact with the API Server in two ways:
(1) Using the llamactl CLI from the shell.
(2) Through the Llama Deploy SDK in Python applications or scripts.The SDK and CLI are distributed with the Llama Deploy Python package, so it comes with batteries included.
Basic Concepts in LlamaIndex
Context-Augmented
Large models provide a natural language interface between humans and data. Large models have been pre-trained on a vast amount of publicly available data, but they have not been trained on your data. Your data may be private or specific to the problem you want to solve. It may reside behind APIs, in SQL databases, or hidden in PDFs and slides.
Context augmentation allows large models to utilize your data to solve current problems. LlamaIndex provides tools to build any context-augmented use case (from prototypes to production). Our tools allow you to acquire, parse, index, and process data, and rapidly implement complex query workflows that combine data access with LLM prompts.The most popular example of context augmentation is retrieval-augmented generation (RAG), which combines context with LLM during inference.
Agents
Agents are knowledge assistants powered by large models that use tools to perform tasks such as research and data extraction. The scope of agents ranges from simple Q&A to the ability to perceive, make decisions, and take actions to complete tasks.LlamaIndex provides a framework for building agents, including the ability to use RAG pipelines as one of many tools for task completion.
Workflows
Workflows are multi-step processes that combine one or more agents, data connectors, and other tools to accomplish a task. They are event-driven software that allows you to create complex applications by combining RAG data sources and multiple agents, capable of executing various tasks with reflection, error correction, and advanced LLM application features. You can then deploy these agent workflows as production microservices.
Framework for Context-Augmented LLM Applications
LlamaIndex places no restrictions on how to use LLMs. You can use large models as: auto-complete, chatbots, agents, etc. LlamaIndex makes implementations utilizing them easier. LlamaIndex provides the following tools:
-
Data connectors: acquire existing data from its source and format it. These can be APIs, PDFs, SQL, etc.
-
Data indexes: build data in intermediate representations that are both simple and efficient for large models.
-
Engines: provide natural language access to data. For example:
-
The query engine is a powerful question-and-answer interface (e.g., RAG flows).
-
The chat engine is a conversational interface for multi-message, “back-and-forth” interactions with data.
-
-
Agents: Agents are knowledge workers supported by large models, enhanced through tools, ranging from simple assistive functions to API integrations, etc.
-
Observability/Evaluation: Integrations enable you to rigorously experiment, evaluate, and monitor your applications in a virtuous cycle.
-
Workflows: Allow you to combine everything mentioned above into an event-driven system that is more flexible than other graph-based approaches.
Use Cases of LlamaIndex
LlamaIndex provides tools for beginners, advanced users, and everyone in between. Advanced APIs allow beginners to use LlamaIndex to acquire and query their data with just 5 lines of code.For more complex applications, our lower-level APIs allow advanced users to customize and extend any module (data connectors, indexes, retrievers, query engines, and re-ranking modules) to meet their needs.