
Click the “Beginner’s Guide to Vision” above, and choose to add “Star” or “Top“
Important content delivered at the first time
Table of Contents
-
Overview
-
Why Visual Attention is Needed -
Classification and Basic Concepts of Attention -
Soft Attention
-
The application of two-level attention models in deep convolutional neural network for fine-grained image classification—CVPR2015 -
1. Spatial Transformer Networks—2015 NIPS -
2. SENET (Channel Domain)—2017 CPVR -
3. Residual Attention Network (Mixed Domain)—2017 -
Non-local Neural Networks, CVPR2018 -
Interaction-aware Attention, ECCV2018 -
CBAM: Convolutional Block Attention Module (Channel Domain + Spatial Domain), ECCV2018 -
DANet: Dual Attention Network for Scene Segmentation (Spatial Domain + Channel Domain), CPVR2019 -
CCNet -
OCNet -
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond -
Attention-Augmented Convolutions -
PAN: Pyramid Attention Network for Semantic Segmentation (Layer Domain)—CVPR2018 -
Multi-Context Attention for Human Pose Estimation -
Tell Me Where to Look: Guided Attention Inference Network -
Hard Attention
-
A study on guiding learning visual question answering tasks by introducing hard attention mechanisms -
1. Diversified visual attention networks for fine-grained object classification—2016 -
2. Deep networks with internal selective attention through feedback connections (Channel Domain)—NIPS 2014 -
3. Fully Convolutional Attention Networks for Fine-Grained Recognition -
4. Temporal Attention (RNN)
Why Visual Attention is Needed
The basic idea of attention mechanisms in computer vision is to make the system learn to pay attention—able to ignore irrelevant information and focus on key information. Why ignore irrelevant information?
Classification and Basic Concepts of Attention
What is “attention” in neural networks? How to use it? Here is a detailed explanation: http://www.sohu.com/a/198312880_390227)This article divides into: hard attention, soft attention, and also Gaussian attention, spatial transformations
Classified by the differentiability of attention:
-
Hard-attention, is a 0/1 problem, which areas are attended, and which areas are not. Hard attention has been well-known for years in image applications: image cropping (hard attention) differs from soft attention in that hard attention focuses more on points, meaning that every point in the image may extend attention, while hard attention is a random prediction process, emphasizing dynamic changes. Of course, the key is that hard attention is non-differentiable, and the training process is often completed through reinforcement learning. (Reference article: Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in neural information processing systems. 2014.)
Hard attention can be implemented in Python (or TensorFlow) as:
g = I[y:y+h, x:x+w]
The only problem here is that it is non-differentiable; if you want to learn the model parameters, you must use the score-function estimator. I briefly introduced this in my previous article.
-
Soft-attention, is a continuous distribution problem between [0,1], indicating the degree of attention to each area, represented by a score from 0 to 1.
The key point of soft attention is that this type of attention focuses more on areas or channels, and soft attention is deterministic; once learned, it can be generated directly through the network. The most critical place is that soft attention is differentiable, which is very important. Differentiable attention can calculate gradients through neural networks and learn the attention weights through forward propagation and backward feedback. However, this type of soft attention is computationally very wasteful. The black part of the input has no effect on the result but still needs to be processed. At the same time, it is also over-parameterized: the sigmoid activation function used to implement attention is independent of each other. It can select multiple targets at once, but in practice, we often want selectivity and can only focus on a single element in the scene. The following two mechanisms introduced by DRAW and Spatial Transformer Networks effectively solve this problem. They can also adjust the input size to further improve performance.
Classified by the domain of attention focus:
-
Spatial Domain -
Channel Domain -
Layer Domain -
Mixed Domain -
Time Domain: There is also a rather special implementation of attention in the time domain, but because hard attention is implemented using reinforcement learning, training is somewhat different.
A concept: Self-attention is the autonomous learning of feature maps, allocating weights (which can be spatial, temporal, or between channels).
Soft Attention
The application of two-level attention models in deep convolutional neural network for fine-grained image classification—CVPR2015
1. Spatial Transformer Networks (Spatial Domain Attention)—2015 NIPS
Spatial Transformer Networks (STN) model [4] is an article from NIPS 2015. This article uses the attention mechanism to transform the spatial information in the original image to another space while retaining the key information.
This article argues that previous pooling methods are too aggressive, directly merging information, which can lead to key information being unrecognizable. Therefore, it proposes a module called spatial transformer, which performs corresponding spatial transformations on the spatial domain information in the image, thus extracting key information.
Spatial transformer is actually the implementation of the attention mechanism, as the trained spatial transformer can identify the areas in the image information that need to be focused on. At the same time, this transformer can have the functions of rotation and scaling transformation, so that important local information in the image can be extracted through transformation.
 For example, this intuitive experimental image:
For example, this intuitive experimental image:
(a) Column is the original image information, where the first handwritten digit 7 is unchanged, the second handwritten digit 5 is rotated, and the third handwritten digit 6 has some noise; (b) The colored frames in column b are the learned bounding boxes of the spatial transformer, each bounding box corresponds to a spatial transformer learned from the image; (c) The column shows the feature map after transformation by the spatial transformer, where the key area of 7 is selected, 5 is rotated into the correct image, and the noise of 6 is not recognized.
2. SENET (Channel Domain)—2017 CPVR
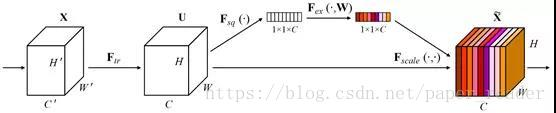 The middle module is the innovative part of SENet, which is the attention mechanism module. This attention mechanism is divided into three parts: squeeze, excitation, and scale (attention). The process:
The middle module is the innovative part of SENet, which is the attention mechanism module. This attention mechanism is divided into three parts: squeeze, excitation, and scale (attention). The process:
-
Perform Global AVE pooling on the input features to obtain 1_1_ Channel -
Then bottleneck features interact, first compressing the channel number and then reconstructing back to the channel number -
Finally, connect a sigmoid to generate attention weights between channels from 0 to 1, and finally scale back to the original input features
See “Paper Reading Notes—SENET” https://blog.csdn.net/xys430381_1/article/details/89158063
3. Residual Attention Network (Mixed Domain)—2017
The attention mechanism in the article is the basic soft attention with a masking mechanism, but different from this, the attention mechanism mask draws on the idea of residual networks. It not only adds a mask based on the information of the current network layer but also passes down the information from the previous layer, thus preventing the problem of insufficient information after masking leading to the inability to stack the network layers deeply.
The proposed attention mask is not just for spatial or channel domains; this mask can be seen as the weight of each feature element. By finding the corresponding attention weight for each feature element, both spatial and channel attention mechanisms can be formed simultaneously.
Many people may have questions here: this approach should be a very natural transition from spatial or channel domains; why has no one thought of doing single-domain attention? The reasons are:
-
If you assign a mask weight to each feature element, the information after masking will be very little, which may directly destroy the deep feature information of the network; -
In addition, if you can add the attention mechanism, the identity mapping property of the residual unit will be destroyed, making it difficult to train.
The innovation of the attention mechanism in this article is to propose residual attention learning, which not only takes the masked feature tensor as the input for the next layer, but also takes the unmasked feature tensor as the input for the next layer, thus obtaining richer features and being able to better focus on key features.
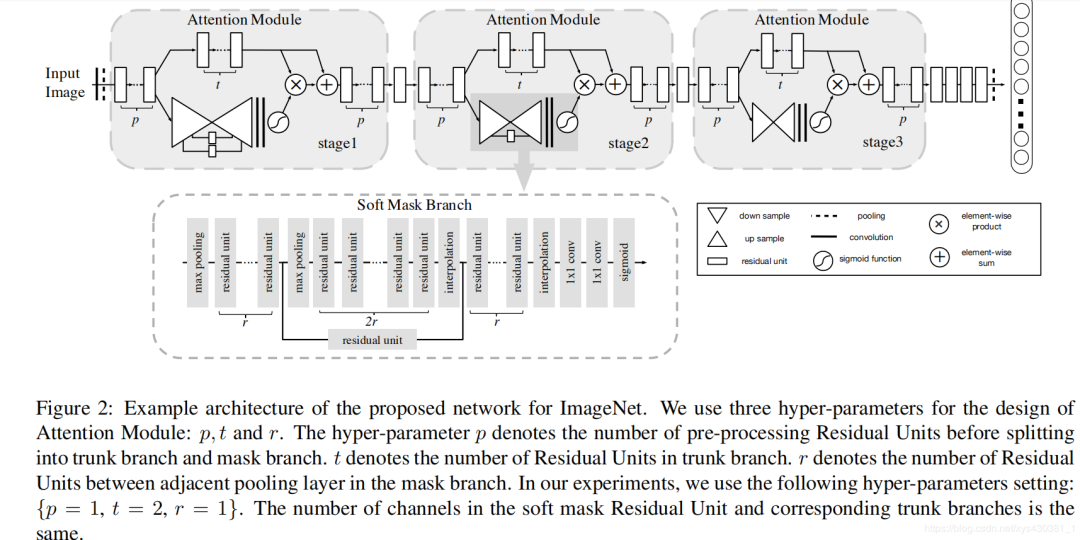 The model structure in the article is very clear, and the overall structure is a three-stage attention module. Each attention module can be divided into two branches (see stage 2), the upper branch is called the main branch (trunk branch), which is the basic structure of the residual network (ResNet). The lower branch is the soft mask branch, and the main part contained in the soft mask branch is the residual attention learning mechanism. Through down sampling and up sampling, as well as the residual module, the attention mechanism is composed.
The model structure in the article is very clear, and the overall structure is a three-stage attention module. Each attention module can be divided into two branches (see stage 2), the upper branch is called the main branch (trunk branch), which is the basic structure of the residual network (ResNet). The lower branch is the soft mask branch, and the main part contained in the soft mask branch is the residual attention learning mechanism. Through down sampling and up sampling, as well as the residual module, the attention mechanism is composed.
The innovative residual attention mechanism in the model structure is: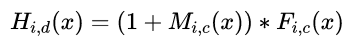 H is the output of the attention module, F is the feature of the image tensor from the previous layer, M is the soft mask attention parameter. This constitutes the residual attention module, which can input both the image features and the features after enhancing attention into the next module. The F function can choose different functions to obtain results from different attention domains:
H is the output of the attention module, F is the feature of the image tensor from the previous layer, M is the soft mask attention parameter. This constitutes the residual attention module, which can input both the image features and the features after enhancing attention into the next module. The F function can choose different functions to obtain results from different attention domains:

Non-local Neural Networks, CVPR2018
FAIR’s masterpiece, mainly inspired by traditional methods using non-local similarity for image denoising.
The main idea is also very simple; in CNN, the convolution unit focuses only on the neighborhood kernel size area each time. Even though the receptive field grows larger over time, it is still a local operation, which ignores the contribution of other distant pixels to the current area.
Thus, what non-local blocks need to do is to capture this long-range relationship: for a 2D image, it is the relationship weight of any pixel in the image to the current pixel; for a 3D video, it is the relationship weight of all pixels in all frames to the pixels of the current frame.
The network framework diagram is also simple and straightforward:
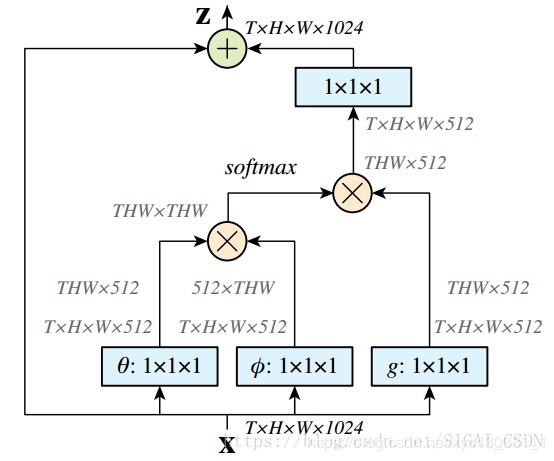 The article discusses various implementation methods. Here, I will briefly mention the Matmul method, which is best implemented in the DL framework:
The article discusses various implementation methods. Here, I will briefly mention the Matmul method, which is best implemented in the DL framework:
-
First, perform linear mapping on the input feature map X (essentially a 1x1x1 convolution to compress the channel number), obtaining the θ, ϕ, g features. -
By performing reshape operations, forcibly merging the above three features except for the channel number, then performing matrix point multiplication to obtain something similar to the covariance matrix (this process is very important, calculating the self-correlation of the features, i.e., obtaining the relationship of each pixel in each frame to all other pixels in all frames). -
Then perform Softmax operation on the self-correlation features by column or by row (depending on the form of the matrix g) to obtain weights between 0 and 1; this is the self-attention coefficient we need. -
Finally, multiply the attention coefficients back into the feature matrix g, then expand the channel number, and perform a residual operation with the original input feature map X to complete the bottleneck.
The visualization effect of the attention map embedded in the action recognition framework:

The arrows in the figure indicate the contribution relationship of certain pixels in the previous several frames to the pixel of the ankle joint in the last image (current frame). As it is soft attention, actually every pixel in each frame has a contribution relationship to it, and the yellow arrows describe the responses with the largest relationships.
Summary
Pros: Non-local blocks are very general and can be easily embedded in any existing 2D and 3D convolution networks to improve or visualize understanding related CV tasks. For example, a recent article has applied non-local to the Video ReID task.
Cons: The results in the article suggest that non-local should be placed as early as possible in the layers, but in fact, for 3D tasks, the early layers have a relatively large temporal T, leading to excessive parameters during the construction and point multiplication operations, which requires a large amount of GPU memory.
Interaction-aware Attention, ECCV2018
An article by Meitu and the Chinese Academy of Sciences.
This article discusses a lot of multi-scale feature fusion, telling a lot of stories, but the key contribution is to design a new loss based on PCA on the covariance matrix of the non-local block for better feature interaction. The authors believe that this process allows features to interact better in the channel dimension, hence the name Interaction-aware attention.
So the question arises, how to achieve attention weights through PCA?
The article does not directly use the eigenvalue decomposition of the covariance matrix; instead, it uses the following equivalent form:
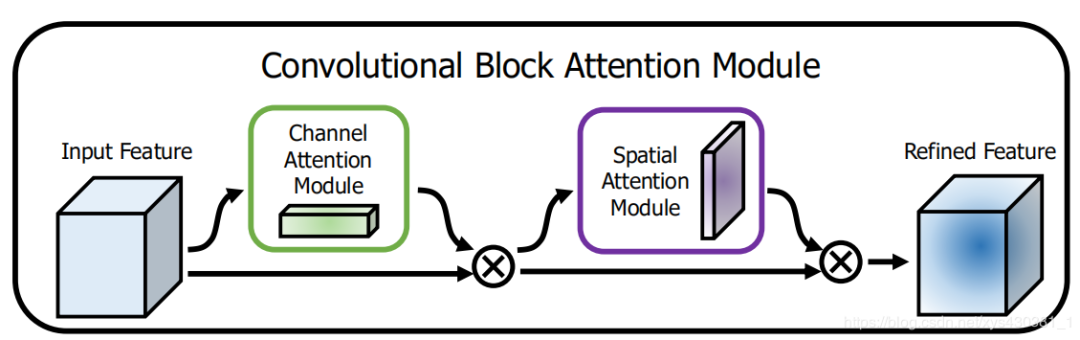
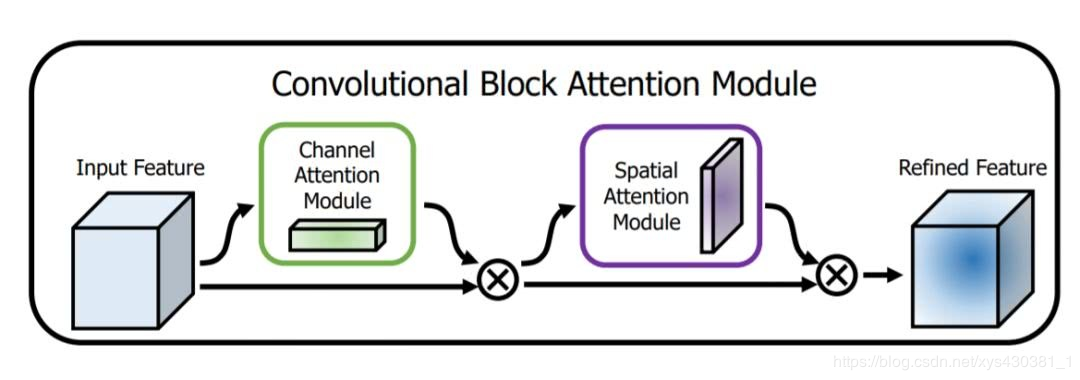
CBAM: Convolutional Block Attention Module (Channel Domain + Spatial Domain), ECCV2018
This is based on the Squeeze-and-Excitation module in SE-Net to further expand.
Specifically, the article considers channel-wise attention as teaching the network “Look ‘what'”; while spatial attention is teaching the network “Look ‘where'”, so its main advantage over the SE Module is the latter.
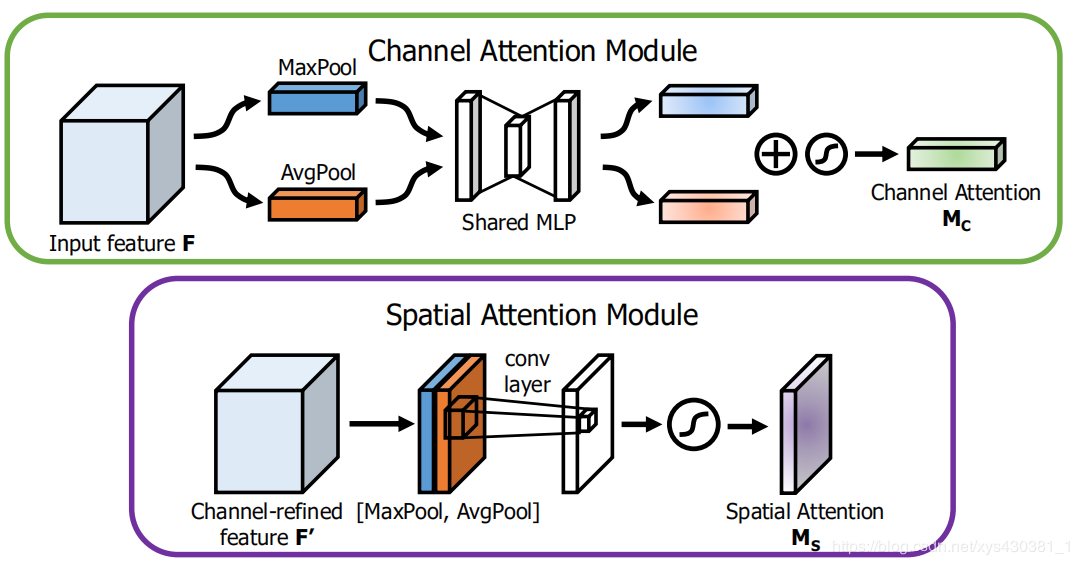
Channel attention formula:
Spatial attention formula: (Spatial domain attention is obtained by performing AvgPool and MaxPool on the channel axis)
CBAM is particularly lightweight and easy to deploy on the edge.
DANet: Dual Attention Network for Scene Segmentation (Spatial Domain + Channel Domain), CPVR2019
code: https://github.com/junfu1115/DANet was recently posted on arXiv, applying the idea of self-attention to image segmentation, allowing for more precise segmentation through long-range contextual relationships.
The main idea is also a fusion of the above articles CBAM and non-local:
Perform spatial-wise self-attention on the deep feature map while also performing channel-wise self-attention, and finally fuse the two results through element-wise sum.The advantage of this approach is:
Based on the idea of performing spatial and channel self-attention in CBAM, it directly uses the self-correlation matrix Matmul form of non-local for computation, avoiding the complex operations of manually designed pooling and multi-layer perceptron.
CCNet
The highlight of this article is the clever method of reducing the number of parameters. In the above DANet, the attention map calculates the similarity between all pixels and all pixels, with a spatial complexity of (HxW)x(HxW). This article adopts the criss-cross idea, calculating the similarity only between each pixel and its corresponding pixels in the same row and column, thus indirectly calculating the similarity between each pixel and every other pixel, reducing the spatial complexity to (HxW)x(H+W-1), as illustrated below:
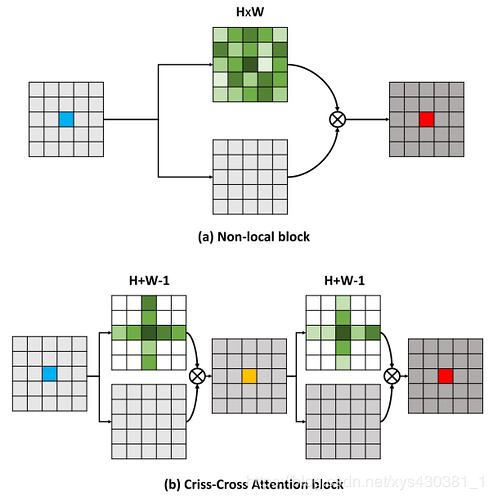 The overall architecture of the network is the same as that of DANet, except that the attention module is different. In the following figure: when calculating the matrix multiplication, each pixel only extracts the corresponding pixels in the cross position of the feature map for point multiplication to calculate similarity.The attention map obtained after one round of this attention calculation is shown in the following figure R1, where each element has only the similarity in its cross. After two rounds of this calculation, each element will obtain the similarity across the entire image, as shown in R2.
The overall architecture of the network is the same as that of DANet, except that the attention module is different. In the following figure: when calculating the matrix multiplication, each pixel only extracts the corresponding pixels in the cross position of the feature map for point multiplication to calculate similarity.The attention map obtained after one round of this attention calculation is shown in the following figure R1, where each element has only the similarity in its cross. After two rounds of this calculation, each element will obtain the similarity across the entire image, as shown in R2. The reason for obtaining this result is shown in the following figure. After one round of calculation, each pixel can obtain the similarity in its cross. For pixels in different rows and columns (not in their cross), there is no similarity, but these different row and column pixels also perform similarity calculations, calculating the similarities in their crosses, so the two crosses must intersect. In the second attention calculation, through the intersection point, it indirectly calculates the similarity between these two different row and column pixels.
The reason for obtaining this result is shown in the following figure. After one round of calculation, each pixel can obtain the similarity in its cross. For pixels in different rows and columns (not in their cross), there is no similarity, but these different row and column pixels also perform similarity calculations, calculating the similarities in their crosses, so the two crosses must intersect. In the second attention calculation, through the intersection point, it indirectly calculates the similarity between these two different row and column pixels.
The experimental results have reached SOTA levels, but the accuracy of the attention method that does not calculate all pixels is higher.
OCNet
OCNet: Object Context Network for Scene Parsing (Microsoft Research) paper analysis https://blog.csdn.net/mieleizhi0522/article/details/84873101 Image semantic segmentation (13)—OCNet: Object Semantic Network for Scene Parsing https://blog.csdn.net/kevin_zhao_zl/article/details/88732455
The abstract of the paper focuses on the semantic aggregation strategy in semantic segmentation, which no longer predicts pixel by pixel but aggregates similar pixel points for semantic segmentation, thus proposing the object semantic pooling strategy. It obtains the label of a certain pixel that belongs to an object by utilizing the information of the pixel set belonging to the same object, where the pixel set is called the object semantics. The specific implementation is influenced by the self-attention mechanism and includes two steps: 1) calculating the similarity between a single pixel and all pixels to obtain the mapping of object semantics to each pixel; 2) obtaining the label of the target pixel. The result is more accurate than existing semantic aggregation strategies such as PPM and ASPP, which do not distinguish whether there is a relationship between a single pixel and object semantics.
It must be said that this paper collided with DANet, and it collided very hard, using the same core content.
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
Non-local Networks Meet Squeeze-Excitation Networks and Beyond paper interpretation https://blog.csdn.net/nijiayan123/article/details/90035599
GCNet network structure integrates the non-local network and Squeeze-excitation networks. We know that the non-local network (NLNet) can capture long-distance dependency relationships. It can be found that the network structure of NLNet uses self-attention mechanisms to model pixel relationships. **In this paper, the global context of non-local networks is almost the same at different positions, indicating that it has learned a global context without positional dependency, which leads to a large amount of computational waste. The authors propose a simplified model to obtain global context information.** It uses a query-independent modeling method (which can be understood as independent of query). At the same time, it can share this simplified structure with the SENet network structure. Therefore, the authors combine these three methods to produce a global context (GC) block.
Attention-Augmented Convolutions
A dialogue between the new and old generations of neural networks (including implementation) https://mp.weixin.qq.com/s/z2scG7VvguXXZVpRhyLpxw
PyTorch implementation address: https://github.com/leaderj1001/Attention-Augmented-Conv2d
PS: The inspiration is to add multiple attention heads on the basis of the convolution operator (each self-attention head is a no-local block), and then concatenate these heads together.
Mechanism
Convolution operations have a significant flaw in that they only work on local neighbors, thus missing out on global information. On the other hand, self-attention is a recent advancement in capturing long-range interactivity, but it is still mainly applied in sequence modeling and generative modeling tasks. In this paper, we study the problem of using self-attention (as a substitute for convolution) for discriminative visual tasks. We propose a novel two-dimensional relative self-attention mechanism, and research shows that this is sufficient to replace convolution as a standalone primitive in image classification tasks. In contrast experiments, we found that the best results are achieved when combining convolution and self-attention. Therefore, we propose using this self-attention mechanism to enhance the convolution operator, specifically by concatenating the convolution feature map with a set of feature maps generated by self-attention.
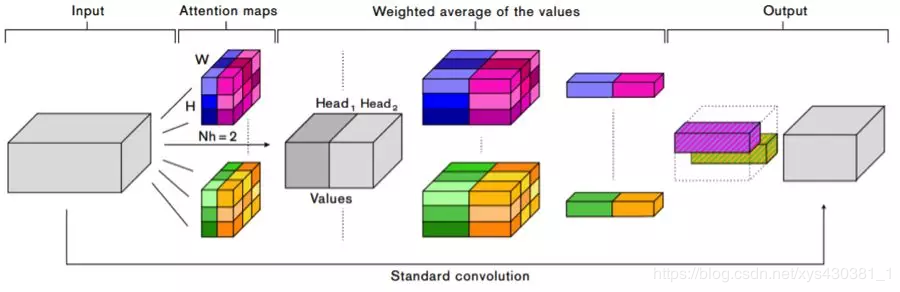

Given an input tensor of shape (H, W, F_in), we expand it into a matrix and perform multi-head attention as proposed in the Transformer architecture. The output of the single head h’s self-attention mechanism is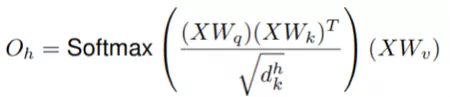
where, are learnable linear transformations that map the input X to queries Q, keys K (xys: when performing matrix multiplication for self-correlation, one is called query and the other is called key) and values V. The outputs of all heads can be concatenated:
We conducted extensive experiments using different scales and types of models (including ResNet and a currently best-performing movable restricted network), and the results showed that attention augmentation can achieve stable improvements in ImageNet image classification and COCO object detection tasks while keeping the number of parameters roughly close. It is especially worth mentioning that our method achieved a top-1 accuracy on ImageNet that is 1.3% better than the ResNet50 benchmark, and our method also exceeded the RetinaNet benchmark by 1.4 mAP on COCO object detection. Attention augmentation achieves systematic improvements with minimal computational burden and significantly outperforms popular Squeeze-and-Excitation channel-based attention methods in all experiments. Another surprising result is that the fully self-attention model (a special case of attention augmentation) performs slightly worse than the corresponding fully convolutional model on ImageNet, indicating that self-attention itself is a powerful basic method for image classification.
PAN: Pyramid Attention Network for Semantic Segmentation (Layer Domain)—CVPR2018
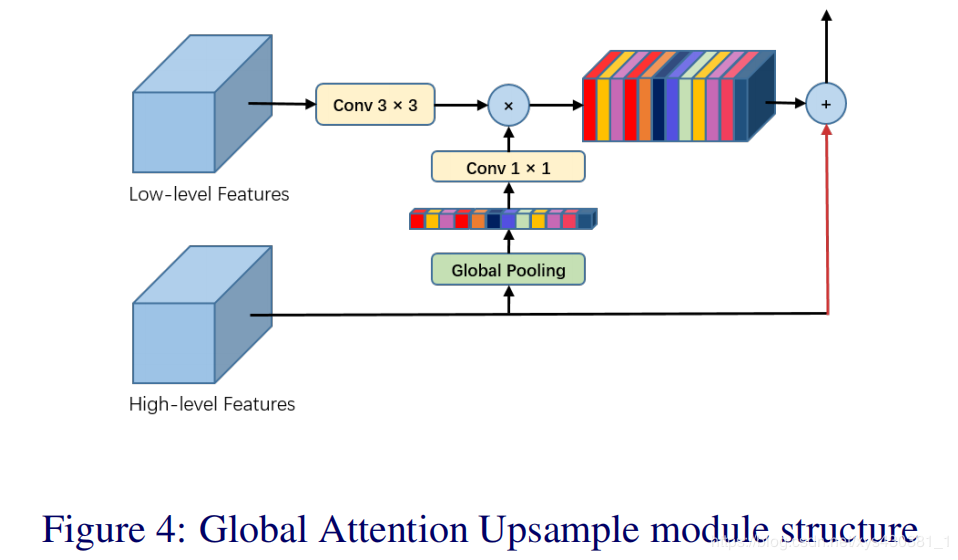
Highlight 1: The paper combines the attention mechanism with a pyramid structure as its highlight, allowing for the extraction of relatively precise dense features based on high-level semantic guidance, replacing the complex dilated convolutions and multiple encoder-decoder operations in other methods, breaking away from the commonly used U-Net structure; Highlight 2: It adopts a global pooling method for weighting the low-level features, playing a role in selecting the feature map.
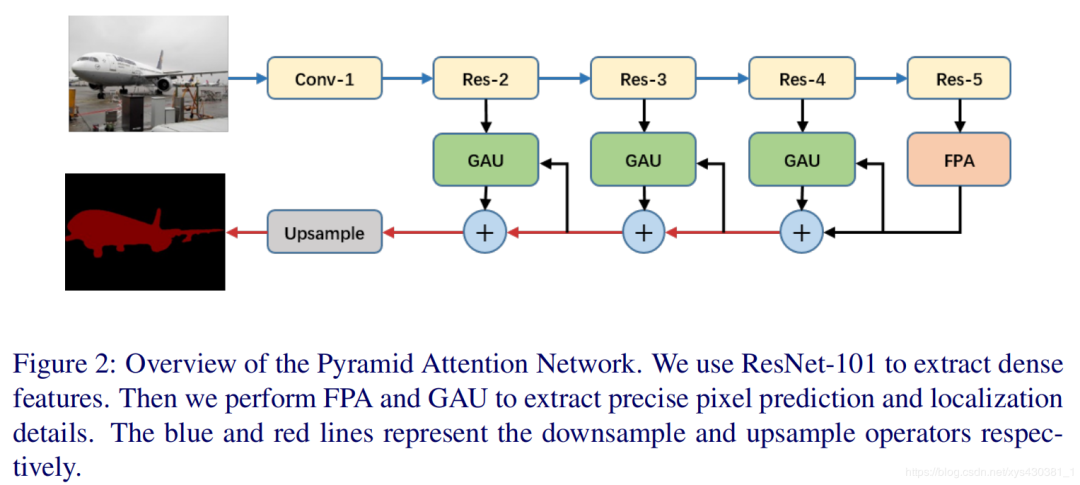 Module 1: FPA (Feature Pyramid Attention) Feature Pyramid Attention
Module 1: FPA (Feature Pyramid Attention) Feature Pyramid Attention
-
Problem solved: Different scale sizes of images and different sizes of objects create difficulties for object segmentation. -
Existing methods: Similar to PSPNet and DeepLab, spatial pyramid pooling is used to achieve different scales and multi-porous pyramid pooling ASPP structure. Problem 1: Pooling easily loses local information; Problem 2: ASPP, being a sparse operation, causes checkerboard artifacts; Problem 3: Simply concatenating multiple scales lacks contextual information and performs poorly without paying attention to contextual information (the following figure illustrates the existing methods), this part of the processing is mainly used for handling high-level feature operations. -
Proposed solution: As shown in the right figure, after extracting high-level features, instead of performing pooling operations, three consecutive convolutions are used to achieve higher-level semantics. We know that higher-level semantics are closer to the ground truth, focusing on some object information, so higher-level semantics are used as a form of attention guidance, multiplying with high-level features in 1×1 convolution without changing size, thus enhancing the weight of parts with object information, resulting in attention-enhanced output. At the same time, because the pyramid convolution structure uses different sizes of convolution kernels, representing different receptive fields, it also solves the problem of different objects at different scales.
Multi-Context Attention for Human Pose Estimation
Tell Me Where to Look: Guided Attention Inference Network
Hard Attention
A study on guiding learning visual question answering tasks by introducing hard attention mechanisms
Soft attention mechanisms have achieved wide applications and success in the field of computer vision. However, we find that the research on hard attention mechanisms in computer vision tasks is still relatively blank. **Hard attention mechanisms can select important features from input information, thus being regarded as a more efficient and direct method than soft attention mechanisms.** This time, I will introduce a study on guiding learning visual question answering tasks by introducing hard attention mechanisms. Additionally, combining L2 regularization to filter feature vectors can efficiently promote the filtering process and achieve better overall performance without a dedicated learning process.
1. Diversified visual attention networks for fine-grained object classification—2016
2. Deep networks with internal selective attention through feedback connections (Channel Domain)—NIPS 2014
A Deep Attention Selective Network (dasNet) is proposed. After training is completed, the attention is dynamically adjusted through reinforcement learning (Separable Natural Evolution Strategies). Specifically, the attention adjusts the weight of each conv filter (similarly to SENet, which also has a channel dimension). The policy is a neural network, and the RL part of the algorithm is as follows: Each while loop represents an iteration of SNES, M represents the trained CNN, u and Sigma are the hyperparameters of the policy parameters, p is the sampling of p policy parameters, and n is the random selection of n images.
Each while loop represents an iteration of SNES, M represents the trained CNN, u and Sigma are the hyperparameters of the policy parameters, p is the sampling of p policy parameters, and n is the random selection of n images.
3. Fully Convolutional Attention Networks for Fine-Grained Recognition
This article utilizes a reinforcement learning-based visual attention model to simulate learning to locate object parts and classify objects in scenes. This framework simulates the recognition process of the human visual system by learning a task-driven strategy, going through a series of glimpses to locate the parts of the object. So, what are glimpses? Each glimpse corresponds to a part of the object. The original image and the previous glimpse position are used as input, and the next glimpse position is output as the next object part. Each glimpse position acts as an action, and the image and previous glimpse position act as the state, with rewards measuring classification accuracy. This method can simultaneously locate multiple parts, while previous methods could only locate one part at a time.
4. Temporal Attention (RNN)
This concept is actually quite large because computer vision only recognizes images, lacking the concept of time domain. However, this article proposes a recognition model based on a Recurrent Neural Network (RNN) with an attention mechanism.
RNN models are suitable for scenarios where data has temporal characteristics, such as using RNN to produce attention mechanisms, which perform well in natural language processing tasks. This is because natural language processing involves text analysis, and there is a temporal correlation behind the text, such as one word being followed by another, which is a temporal dependency.
However, image data itself does not inherently have temporal characteristics; an image is often a sample at a single point in time. But in video data, RNN is a relatively good data model, thus allowing the use of RNN to generate recognition attention.
RNN’s model is specifically referred to as temporal attention because this model adds a time dimension on top of the previously introduced spatial, channel, and mixed domains. This dimension arises from the temporal characteristics of sampling points.
In the Recurrent Attention Model, attention mechanisms are seen as sampling a point in an area on an image, and this sampling point is the point that needs to be attended to. And the attention in this model is no longer a differentiable attention information, so this is also a strong attention (hard attention) model. The training of this model requires reinforcement learning, leading to longer training times.
What needs to be understood more about this model is not the RNN attention model itself, as it is discussed in more detail in natural language processing, but how this model converts image information into temporal sampling signals:
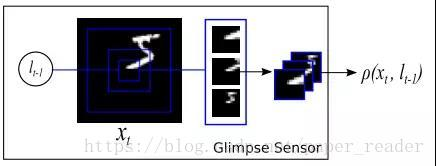 This is a key point in the model, called the Glimpse Sensor. My translation is “scanning device”. The key point of this sensor is to first determine the points (pixels) in the image that need to be focused on, and then this sensor begins to collect three types of information, all with the same information volume: one is very detailed (the innermost frame’s information), one is medium local information, and one is rough thumbnail information.
This is a key point in the model, called the Glimpse Sensor. My translation is “scanning device”. The key point of this sensor is to first determine the points (pixels) in the image that need to be focused on, and then this sensor begins to collect three types of information, all with the same information volume: one is very detailed (the innermost frame’s information), one is medium local information, and one is rough thumbnail information.
These three types of sampled information are generated from the image information at the position, and as t increases, the sampling position changes. As for how l changes with t, this is something that needs to be trained using reinforcement learning.
Self-Attention
Self-attention mechanism in computer vision applications https://cloud.tencent.com/developer/news/374449) Using Attention to Explore CV, an Overview of Progress in Self-Attention Semantic Segmentation https://mp.weixin.qq.com/s/09_rc9J-4cEs7GrYQaL16Q
Self-attention mechanisms are improvements on attention mechanisms that reduce dependence on external information and are better at capturing the internal correlations of data or features.
In neural networks, we know that convolutional layers obtain output features through the linear combination of convolution kernels and original features. Since convolution kernels are usually local, to increase the receptive field, stacking convolutional layers is often used, which is not efficient. At the same time, many tasks in computer vision are affected by insufficient semantic information, which impacts the final performance. Self-attention mechanisms capture global information to obtain a larger receptive field and contextual information.
Self-attention mechanism (self-attention) [1] has made significant progress in sequence models; on the other hand, contextual information is crucial for many visual tasks, such as semantic segmentation and object detection. Self-attention mechanisms provide an effective modeling method for capturing global contextual information through the triplet (key, query, value). Next, we will first introduce several corresponding works, then analyze their respective advantages and disadvantages as well as improvement directions.
Related Works
Attention is all you need [1] is the first paper to propose replacing recurrent neural networks with self-attention mechanisms in sequence models, achieving great success. One important module is the scaled dot-product attention module, which proposes a triplet (key, query, value) to capture long-distance dependency modeling, as shown in the figure below, where key and query obtain corresponding attention weights through point multiplication, and finally the obtained weights are point-multiplied with value to obtain the final output.
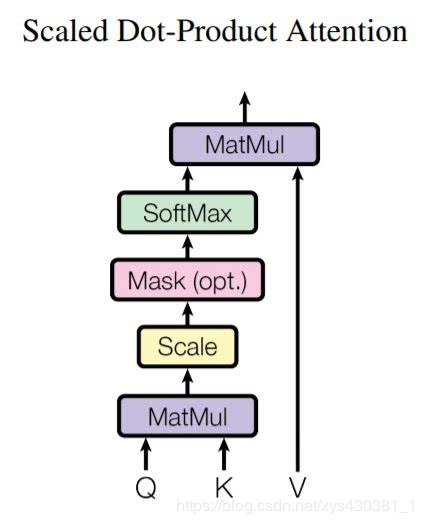
Non-local neural network [2] inherits the modeling method of the triplet (key, query, value) and proposes an efficient non-local module, as shown in the figure below. After adding the non-local module to the ResNet network, both object detection and instance segmentation show an increase of more than one point (mAP) in performance, indicating the importance of contextual information modeling.
Danet [3] is a work from the Chinese Academy of Sciences Automation, whose core idea is to supervise semantic segmentation tasks through contextual information. The authors adopt two forms of attention, as shown in the figure below, which are spatial and channel-wise, and then perform feature fusion, finally connecting to the semantic segmentation head network. The idea is simple and has achieved good results.
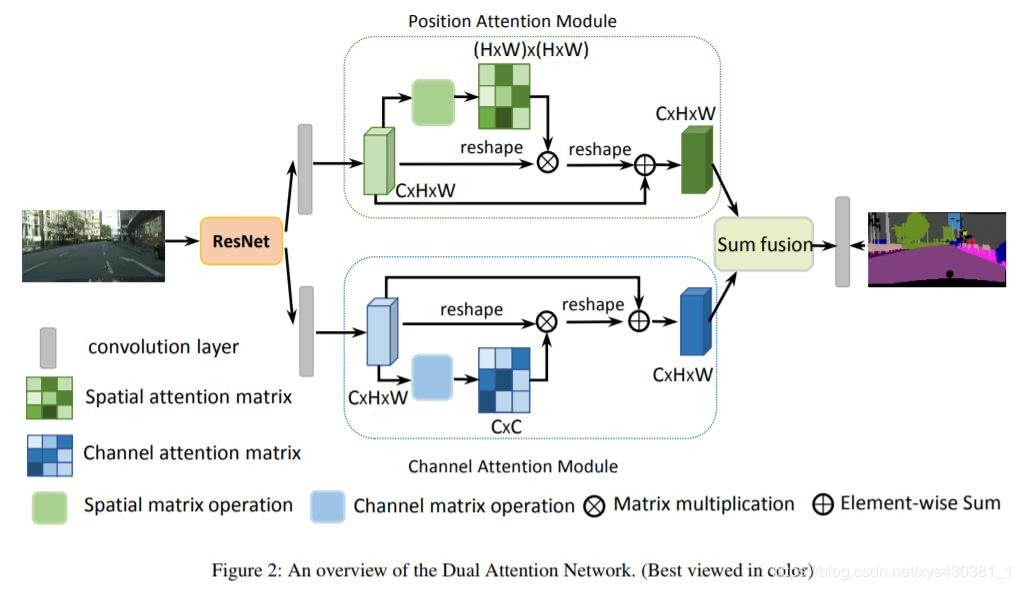 Ocnet [4] is a work from Microsoft Research Asia. It also uses the triplet (key, query, value) to better supervise semantic segmentation tasks by capturing global contextual information. Unlike Danet [3], it only uses spatial information. It also achieved good results.
Ocnet [4] is a work from Microsoft Research Asia. It also uses the triplet (key, query, value) to better supervise semantic segmentation tasks by capturing global contextual information. Unlike Danet [3], it only uses spatial information. It also achieved good results.
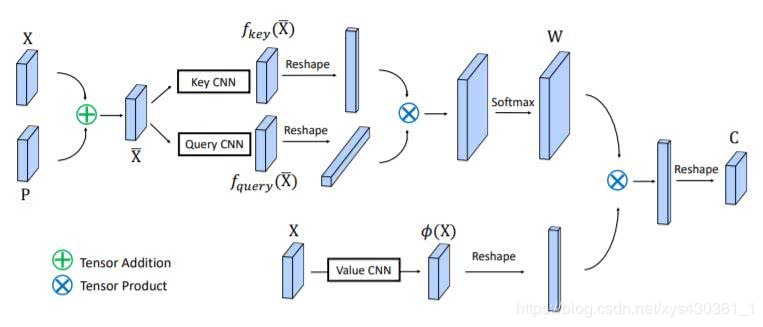
DFF [5] is a work from the Visual Computing Group at Microsoft Research Asia. As shown in the figure below, it models the motion information between different frames of videos through optical flow, thus proposing a very elegant video detection framework, DFF. One very important operation is warp, which achieves alignment between point-to-point. After this, many works on video detection, such as FGFA [6] and Towards High Performance [7], have emerged, most of which operate based on the warp feature. Generally speaking, we assume that the flow motion information will not be too far away, which easily inspires us to think about finding the corresponding motion feature points through the neighborhood of each point. The specific approach will not be introduced here; welcome everyone to think about it (related operations and self-attention mechanisms).
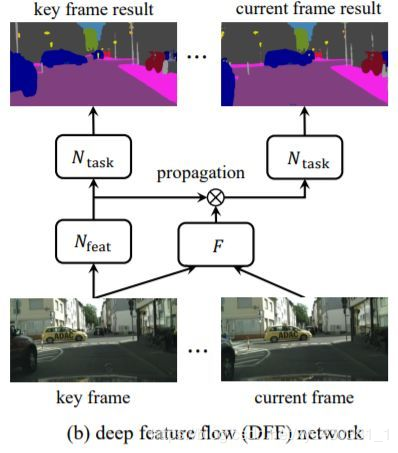
Disadvantages and Improvement Strategies of Self-Attention
The previous section mainly introduced the uses of self-attention mechanisms. Next, we will analyze their disadvantages and corresponding improvement strategies. Since every point must capture global contextual information, this leads to a large computational complexity and memory capacity of the self-attention mechanism module. If we can know some prior information, such as the aforementioned feature alignment is usually within a certain neighborhood, we can perform operations limited to a certain neighborhood. Additionally, how to achieve efficient sparsification and its relationship with graph convolution are all open questions; everyone is welcome to think actively.
Next, we will introduce some other improvement strategies. Senet [9] inspires us that information on the channel is very important, as shown in the figure below.
CBAW [10] proposes a module combining spatial and channel information, as shown in the figure below, achieving good results across various tasks.
Finally, we introduce a work from Baidu IDL that combines channel and spatial modeling [11]. Essentially, it directly incorporates channel information into the (key, query, value) triplet during reshaping, but this introduces a very important issue: the computational complexity greatly increases. We know that grouped convolutions are an effective way to reduce the number of parameters, and this approach also adopts grouping. However, even with grouping, it still cannot fundamentally solve the problems of large computational complexity and parameter volume. The authors ingeniously adjust the order of computing key, query, and value using Taylor series expansion, effectively reducing the corresponding computational complexity. The table below shows the optimized computational volume and complexity analysis, and the following figure shows the overall framework of the CGNL module.
Summary of Self-Attention
As an effective way to model context, the self-attention mechanism has achieved good results in many visual tasks. At the same time, the disadvantages of this modeling approach are also evident: one is that it does not consider channel information, and the other is that the computational complexity is still large. Corresponding improvement strategies include how to effectively combine information on spatial and channel levels and how to perform sparsification of captured information. The benefits of sparsification are to be more robust while maintaining smaller computational load and memory. Finally, graph convolution, as a hot research direction in recent years, how to relate self-attention mechanisms and graph convolution, as well as a deeper understanding of self-attention mechanisms, are all very important directions for the future.
Recommended Articles on Attention Mechanisms
Microsoft Research: Empirical Study of Spatial Attention Mechanisms in Deep Networks http://www.myzaker.com/article/5cb40c5a8e9f09734a62fab1/
Paper: An Empirical Study of Spatial Attention Mechanisms in Deep Networks https://arxiv.org/abs/1904.05873
Paper Reading: Attention Mechanisms in Image Classification https://blog.csdn.net/Wayne2019/article/details/78488142 introduces Spatial Transformer Networks, Residual Attention Network, Two-level Attention, SENet, Deep Attention Selective Network
Visual Attention in Computer Vision https://blog.csdn.net/paper_reader/article/details/81082351
Quickly Understand the Application of Attention Mechanisms in Image Processing https://blog.csdn.net/weixin_41977512/article/details/83243160 mainly discusses the 2017 CPVR article: Residual Attention Network for Image Classification
Summary of Attention Mechanism Articles https://blog.csdn.net/humanpose/article/details/85332392
Latest Progress of Self-Attention in Computer Vision Technology https://blog.csdn.net/SIGAI_CSDN/article/details/82664511
ECCV2018–Attention Model CBAM https://blog.csdn.net/qq_14845119/article/details/81393127
[Paper Reproduction] CBAM: Convolutional Block Attention Module https://blog.csdn.net/u013738531/article/details/82731257
BAM: Bottleneck Attention Module Algorithm Notes https://blog.csdn.net/qq_32768091/article/details/86612132
Fine-grained Image Classification Based on Attention Mechanism https://blog.csdn.net/step_forward_ml/article/details/80630682 discusses RACNN
In addition, there are methods such as MACNN.
Microsoft Research: Empirical Study of Spatial Attention Mechanisms in Deep Networks http://www.myzaker.com/article/5cb40c5a8e9f09734a62fab1/
Paper: An Empirical Study of Spatial Attention Mechanisms in Deep Networks https://arxiv.org/abs/1904.05873
Paper Reading: Attention Mechanisms in Image Classification https://blog.csdn.net/Wayne2019/article/details/78488142 introduces Spatial Transformer Networks, Residual Attention Network, Two-level Attention, SENet, Deep Attention Selective Network
Visual Attention in Computer Vision https://blog.csdn.net/paper_reader/article/details/81082351
Quickly Understand the Application of Attention Mechanisms in Image Processing https://blog.csdn.net/weixin_41977512/article/details/83243160 mainly discusses the 2017 CPVR article: Residual Attention Network for Image Classification
Summary of Attention Mechanism Articles https://blog.csdn.net/humanpose/article/details/85332392
Latest Progress of Self-Attention in Computer Vision Technology https://blog.csdn.net/SIGAI_CSDN/article/details/82664511
ECCV2018–Attention Model CBAM https://blog.csdn.net/qq_14845119/article/details/81393127
[Paper Reproduction] CBAM: Convolutional Block Attention Module https://blog.csdn.net/u013738531/article/details/82731257
BAM: Bottleneck Attention Module Algorithm Notes https://blog.csdn.net/qq_32768091/article/details/86612132
Fine-grained Image Classification Based on Attention Mechanism https://blog.csdn.net/step_forward_ml/article/details/80630682 discusses RACNN
In addition, there are methods such as MACNN.
Good news!
The Beginner's Guide to Vision knowledge circle is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Beginner's Guide to Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, helping you quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, realizing advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided later). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for remarks, otherwise, you will not be approved. After successful addition, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~