
The ocean covers approximately 71% of the Earth’s surface and plays a crucial role in global climate regulation, weather patterns, biodiversity, and human economic development. Ocean science focuses on studying the natural characteristics of the ocean, its changing patterns, and the theories, methods, and applications related to the development and utilization of ocean resources.
This article introduces a large language model designed for the ocean field—OceanGPT. As shown in Figure 1, this model can handle question answering and content generation tasks in ocean science. Additionally, this article attempts to validate the large model’s ability to simulate the control of underwater robots, exploring the realization of underwater embodied intelligence driven by large models. OceanGPT provides an open-source download of the pre-trained model.

Paper Link:
Project Homepage:
Model Download:
https://huggingface.co/zjunlp/oceangpt-7b


1.1 Pre-training in the Ocean Field
To train OceanGPT, this article constructs a pre-training corpus specifically for the ocean field. First, documents are collected from openly accessible literature as the raw corpus and tools are used to convert the content of these documents into plain text. To ensure data quality, the collected dataset is further filtered using regular expressions to remove charts, titles, headers, footers, page numbers, URLs, and citations. Additionally, unnecessary spaces, line breaks, and other non-text characters are filtered out.
The processed documents cover various fields of ocean science, such as ocean physics, ocean chemistry, ocean biology, geology, and hydrology. Furthermore, a hashing method is employed to deduplicate the data, which helps reduce the risk of overfitting during pre-training and improves its generalization ability.
1.2 Instruction Data Generation and Fine-tuning Based on Multi-Agent Collaboration
In the instruction fine-tuning phase, to address the difficulty of obtaining ocean domain data, this article designs a novel multi-agent collaborative instruction data generation and processing framework—DoInstruct, which can automatically collect and generate a large amount of instruction data in the ocean field. As shown in Figure 2, DoInstruct’s ocean data generation framework relies on the collaboration of large model multi-agents to automate the generation of substantial ocean science instruction data.
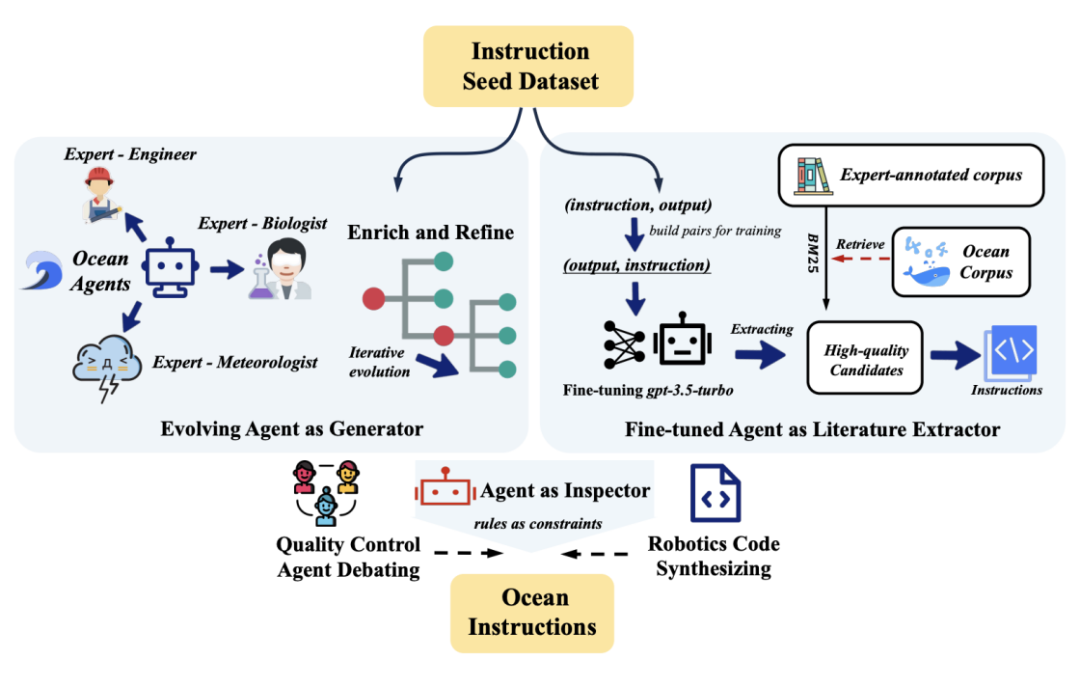
▲ Figure 2 Algorithm Framework for Ocean Instruction Construction
Specifically, each ocean agent plays the role of a corresponding ocean expert, such as an expert in marine biology or marine meteorology. The entire framework is divided into two parts: one part uses evolutionary algorithms to iteratively increase the knowledge richness of ocean seed data, while the other part trains individual agents dedicated to extracting data from ocean science literature to enhance knowledge expertise. Finally, artificial rules related to ocean science are used as prompts to ensure the quality of the instruction data generated by the agents.
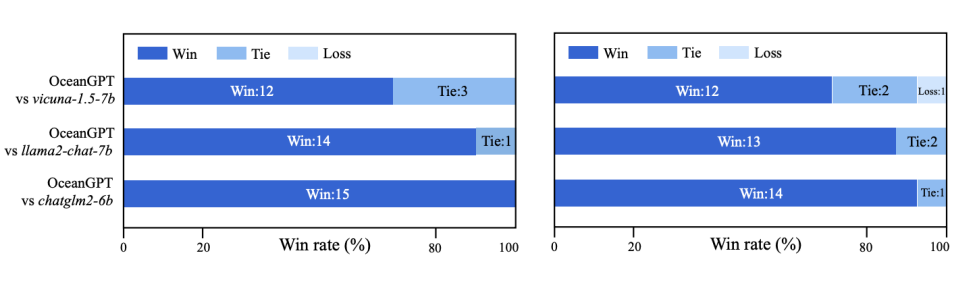
This article establishes a benchmark dataset for evaluating large language models in the ocean field systematically. As shown in Figure 3, through automated and manual evaluations, it is found that OceanGPT performs relatively well on 15 ocean science tasks.
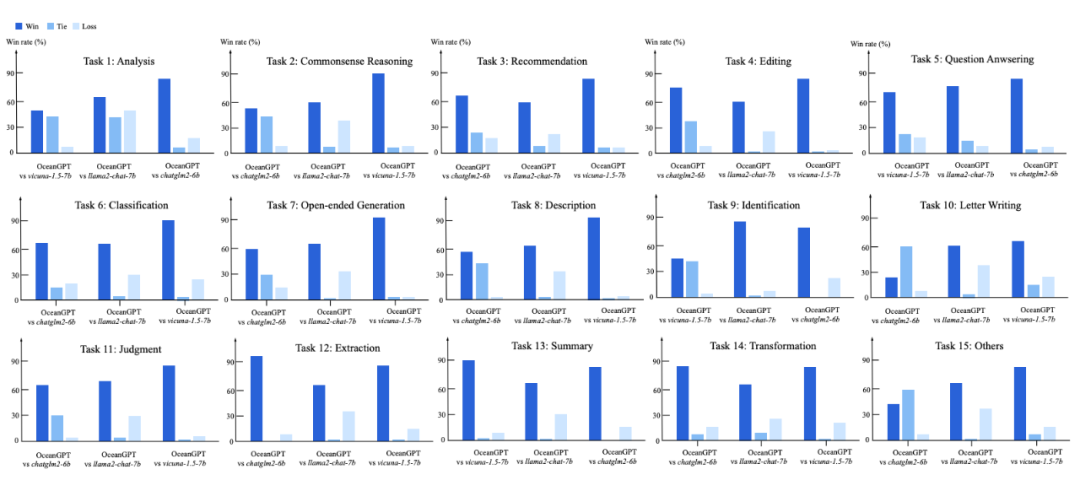
▲ Figure 3 Comparison of OceanBench Experimental Results
2.2 In-depth Analysis of Ocean Large Model Capabilities

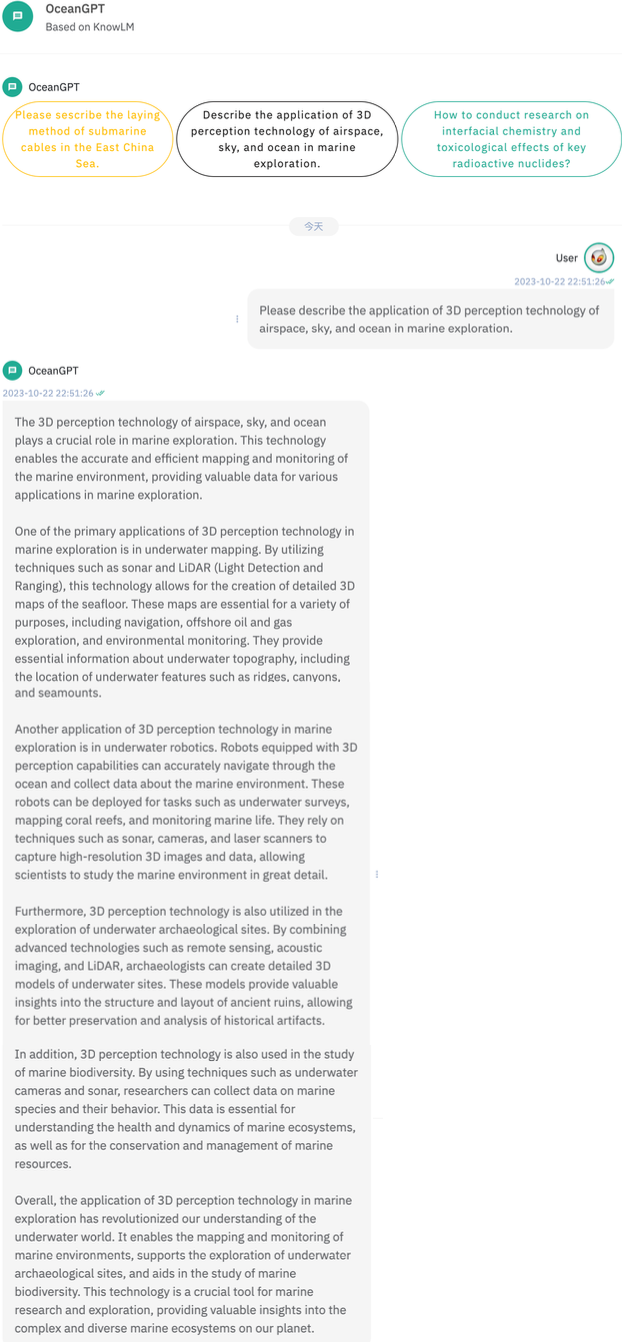
▲ Figure 4 OceanGPT’s Performance in Ocean Science Q&A Scenarios
For ocean science Q&A scenarios, OceanGPT demonstrates better performance in knowledge richness and expertise. Specifically, OceanGPT shows relatively higher domain knowledge expertise when describing research topics such as the protection of oceanic radioactive nuclides; its text content is not only clearly structured and organized but also comprehensively covers all aspects of radioactive nuclide research, from experimental design to data analysis, and risk assessment to disposal guidelines.

▲ Figure 5 OceanGPT’s Performance in Simulating Underwater Robot Operations (Based on Gazebo Simulator)
Furthermore, this article explores OceanGPT’s ability to simulate the operation of ocean robots. By integrating code instructions into the model’s instruction data, it is found that OceanGPT can operate underwater robots to some extent based on human instructions, enabling the robots to perform basic path control operations. OceanGPT has made preliminary attempts at interacting with ocean robots, which can provide a reference for the realization of underwater embodied intelligence driven by large models.

Using OceanGPT
This article provides a simple tutorial for using OceanGPT on Hugging Face (https://huggingface.co/zjunlp/OceanGPT-7b). Execute the following script to load and use OceanGPT.
>> from transformers import pipeline
>> pipe = pipeline("text-generation", model="zjunlp/OceanGPT-7b")
>> from transformers import AutoTokenizer, AutoModelForCausalLM
>> tokenizer = AutoTokenizer.from_pretrained("zjunlp/OceanGPT-7b")
>> model = AutoModelForCausalLM.from_pretrained("zjunlp/OceanGPT-7b")OceanGPT also provides an online interactive demonstration system, as shown in Figure 6, and plans to update the model in the future to further enhance its capabilities for ocean science tasks. For more details, please refer to the original paper.
Further Reading




#Submission Channels#
Let Your Writing Be Seen by More People
How can high-quality content reach readers more efficiently, reducing the cost for readers to find quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly could be a bridge that facilitates the collision of scholars and academic inspiration from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university laboratories or individuals to share various high-quality content on our platform, which can include latest paper interpretations, analysis of academic hotspots, research insights, or competition experiences. Our only goal is to make knowledge flow.
📝 Basic Requirements for Submissions:
• The article must be an original work by the individual, not previously published in public channels. If it is an article published or to be published on other platforms, please specify.
• Manuscripts should be written in markdown format, and images in the text should be sent as attachments, requiring clear images with no copyright issues.
• PaperWeekly respects the author’s right to attribution and will provide competitive compensation for each accepted original submission based on the article’s readership and quality.
📬 Submission Channels:
• Submission Email:[email protected]
• Please include immediate contact information (WeChat) in your submission for us to contact the author as soon as the manuscript is selected.
• You can also add the editor on WeChat (pwbot02) for quick submissions, with the note: Name – Submission.

△ Long press to add PaperWeekly editor
🔍
Now, you can also find us on Zhihu
Search for PaperWeekly on the Zhihu homepage
Click Follow to subscribe to our column
