
Selected from arXiv
Authors: Anuroop Sriram et al.
Translated by Machine Heart
Contributors: Li Yazhou, Li Zenan
Baidu recently published a paper proposing the use of Generative Adversarial Networks (GAN) to achieve a robust speech recognition system. The authors state that the new framework does not rely on the domain-specific knowledge or simplified assumptions often required in signal processing, and directly encourages a data-driven approach to generate robustness. For more details, please refer to the original paper.
Automatic Speech Recognition (ASR) supports voice assistants, smart speakers, and has gradually become a part of our daily lives, such as Siri, Google Now, Cortana, Amazon Echo, Google Home, Apple HomePod, Microsoft Invoke, Baidu Duer, etc. Although recent breakthroughs in research have significantly improved ASR technology, these models experience considerable performance degradation when faced with reasonable variations in reverberation, environmental noise, accents, and other human barriers.
Most of these issues can be alleviated by training on large datasets. However, in unstable processes, such as accents or when precise data augmentation is not feasible, collecting high-quality datasets can be very time-consuming and expensive. Previous ASR-related literature has detailed manual engineering front-end and back-end data-driven approaches to attempt to enhance the value of poor-quality data. While these techniques are quite effective in their respective environments, they do not generalize well to other forms due to the aforementioned reasons. Essentially, it is challenging to model under reverberation and background noise based on fundamental principles. Existing technologies do not directly induce variations of ASR or are not scalable. Additionally, due to the temporal characteristics of speech, two different pronunciations of the same text require comparative calibration.
In this paper, the researchers use a Generative Adversarial Network (GAN) framework to enhance the robustness of sequence-to-sequence models in a scalable, end-to-end manner. The encoder component acts as the generator of the GAN, trained to output indistinguishable embeddings between noisy audio samples and clean audio samples. Since there are no restrictive assumptions, this novel robust training method can theoretically enhance robustness without alignment or complex inference processes, and even without augmentation. The researchers also experimented with the encoder distance objective function to explicitly constrain the embedding space, demonstrating that achieving invariance at the level of hidden representations is a promising direction for robust automatic speech recognition.
Paper: ROBUST SPEECH RECOGNITION USING GENERATIVE ADVERSARIAL NETWORKS

Paper link: https://arxiv.org/abs/1711.01567
This paper describes a universal, scalable, and end-to-end framework that utilizes Generative Adversarial Networks (GAN) to achieve robust speech recognition. The encoder is trained through a learning method that maps noisy audio to the same embedding space as clean audio, enhancing invariance. Unlike previous methods, the new framework does not rely on domain-specific knowledge or simplified assumptions often required in signal processing, and directly encourages a data-driven approach to generate robustness. We experimentally demonstrate that the new method can improve far-field speech recognition performance in a vanilla sequence-to-sequence model without specialized front-end or preprocessing steps.
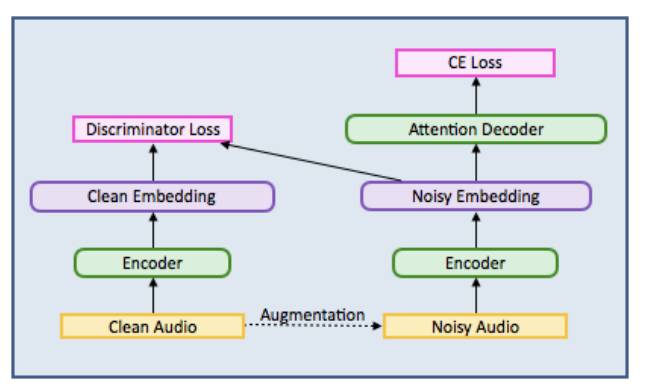
Table 1. Architecture of the enhancer model in Baidu’s paper. The discriminator’s loss can be L1-distance or WGAN loss. The entire model is trained end-to-end using discriminator loss and cross-entropy loss. The researchers used RIR convolution to simulate far-field audio. We can also train this model using the same speech recorded under different conditions.

Algorithm 1. WGAN Enhancement Training. In Baidu’s experiments, the sequence-to-sequence model used the Adam optimizer during training. If x can generate x tilde, the sequence-to-sequence model can also use data augmentation.
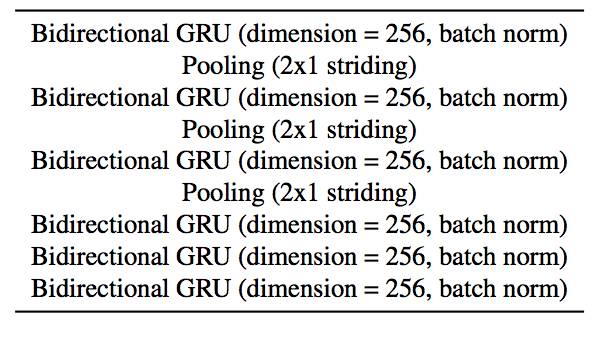
Table 1. Encoder Architecture

Table 2. Architecture (Features) × (Times)
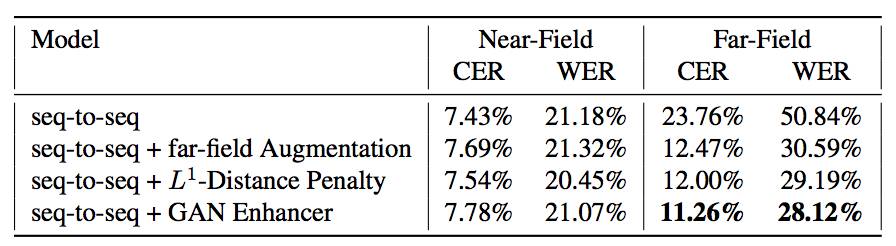
Table 3. Performance of the speech recognition system on the Wall Street Journal corpus 
This article is compiled by Machine Heart, please contact this public account for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or seeking coverage: [email protected]
Advertising & Business Cooperation: [email protected]
Click “Read Original” to participate in PaperWeekly discussion