Original by Machine Heart
Since the introduction of the Transformer, it has swept through the entire NLP field. In fact, it can also be used for object detection. Researchers at Facebook AI first launched the visual version of the Transformer—Detection Transformer (DETR), filling the gap of using Transformer for object detection, surpassing Faster R-CNN. Based on DETR, researchers have proposed various optimized versions for object detection tasks, which have shown promising results.

The Transformer is a classic work in NLP proposed by the Google team in June 2017, introduced in the paper “Attention Is All You Need” by Ashish Vaswani et al. Since the introduction of the Transformer, it has dominated the NLP field due to its powerful attention mechanism. However, surprisingly, the Transformer has received a lukewarm response in the CV field, initially deemed unsuitable for it, until recently when several papers emerged in the computer vision field that demonstrated performance close to the SOTA of CNNs, opening up new possibilities for the application of Transformers in computer vision, where the paradigm is beginning to take shape.
In the field of computer vision, object detection has developed rapidly, with two-stage network architectures represented by R-CNN, Faster R-CNN, and Mask R-CNN, and one-stage network architectures represented by YOLO and SSD. If the Transformer, which has shown superior performance in NLP, is applied to object detection, what would the results be? Currently, researchers have attempted to use the Transformer for object detection tasks, filling the gap of using Transformer for object detection.
This article will introduce using the Transformer for object detection tasks, mainly covering the following content:
-
Paper 1: “End-to-End Object Detection with Transformers”, launched by researchers from Facebook AI, introducing the Transformer visual version—Detection Transformer (DETR), which can be used for object detection and panoptic segmentation.
-
Paper 2: “DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION”, proposed by researchers from SenseTime Research Institute, University of Science and Technology of China, and Chinese University of Hong Kong, introduced Deformable DETR, which addresses the two major issues of slow convergence and high computational complexity in DETR.
-
Paper 3: “UP-DETR: Unsupervised Pre-training for Object Detection with Transformers”, proposed by researchers from South China University of Technology and Tencent Wechat AI, introduced a pre-task called random query patch detection for unsupervised pre-training of DETR (UP-DETR) for object detection.
-
Paper 4: “End-to-End Object Detection with Adaptive Clustering Transformer”, proposed by researchers from Peking University and Chinese University of Hong Kong, introduced a new variant of the transformer: Adaptive Clustering Transformer (ACT), which addresses the high computational costs required for training and inference in DETR.
Paper 1: End-to-End Object Detection with Transformers
Since the Transformer is widely used in processing sequential data tasks, especially showing good performance in language modeling and machine translation tasks, can the model that performs well in the NLP field be applied to the visual field? Researchers from Facebook AI have achieved this functionality.
Researchers from Facebook AI applied the Transformer to the object detection task, achieving results comparable to Faster R-CNN. The research introduced the Transformer visual version—Detection Transformer (DETR), which can be used for object detection and panoptic segmentation. Compared to previous object detection methods, DETR’s architecture has undergone fundamental changes, and it is the first object detection framework to successfully integrate the Transformer as a central building block of the detection pipeline. The end-to-end object detection based on Transformer does not have an NMS post-processing step, truly has no anchors, and surpasses Faster R-CNN.

Algorithm Implementation: A New Architecture for Handling Object Detection Tasks
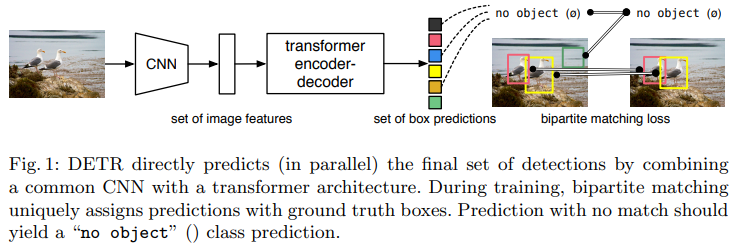
DETR combines common CNNs with the Transformer architecture to directly (and in parallel) predict the final detection results. During the training phase, bipartite matching assigns unique predictions to GT boxes. Unmatched predictions produce no-object (∅) class predictions.
The workflow of DETR can be summarized in the following steps: Backbone -> Transformer -> detect header.
The structure of DETR is specified as follows:
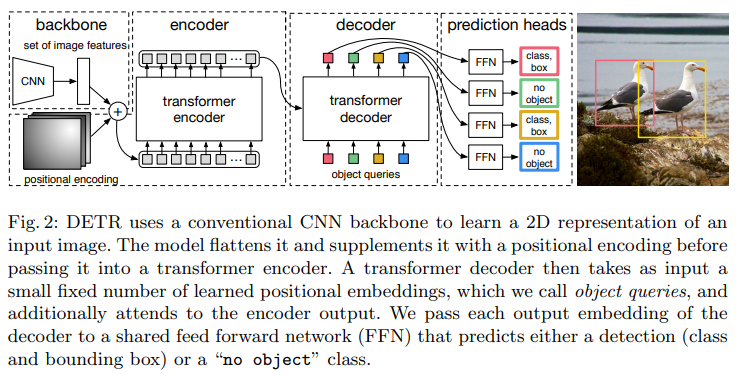
DETR uses a conventional CNN backbone to learn a 2D representation of the input image. The model flattens it and adds positional encoding before passing it to the transformer encoder. Then, the transformer decoder takes a fixed number of positional embeddings as input, called object queries, and additionally participates in the output of the encoder. Each output embedding from the decoder is passed to a shared feed-forward network (FFN) to predict detection (class and bounding box) or no-object class.
More specifically, the DETR architecture is as follows:
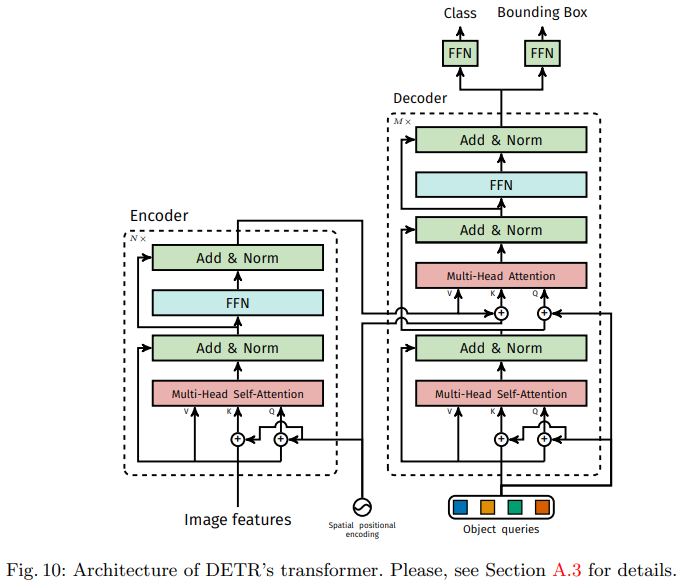
The above figure gives a detailed explanation of the use of transformers in DETR, passing positional encodings at each attention layer. Image features from the CNN backbone pass through the transformer encoder and pass spatial position encodings added to queries and keys. Then, the decoder receives queries (initially set to zero), outputs position encodings (object queries), and encoder memory, generating a final set of predicted class labels and bounding boxes through multiple multi-head self-attention and decoder-encoder attention. Additionally, the first self-attention layer in the first decoder layer can be skipped.
Although DETR performs well, it also has the following two issues:
-
Compared to existing object detectors, it requires a longer number of training epochs to converge. For example, on the COCO benchmark, DETR requires 500 epochs to converge, which is 10 to 20 times slower than Faster R-CNN;
-
DETR performs poorly in detecting small objects. Today’s object detectors typically utilize multi-scale features, allowing small objects to be detected from high-resolution feature maps. However, for DETR, high-resolution feature maps would lead to unacceptable computational and memory complexity.
Paper 2: DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
At the end of May this year, Facebook AI proposed DETR (Paper 1), utilizing the Transformer for object detection, which removed many manually designed components in object detection while demonstrating very good performance. However, DETR has defects such as slow convergence speed and limited feature resolution, leading to slow training times. To address these issues, researchers from SenseTime, USTC, and CUHK proposed Deformable DETR, which solves the two major problems of slow convergence and high computational complexity in DETR. Its attention module focuses only on a small number of sampling points near reference points as key elements in the attention module. Deformable DETR can achieve better performance (especially for small objects) in fewer training epochs than DETR, with extensive experiments on the COCO benchmark validating the effectiveness of this method.
The deformable attention proposed by Deformable DETR can alleviate the slow convergence and high complexity issues of DETR, while combining the sparse spatial sampling capability of deformable convolution with the relational modeling capability of the transformer. The deformable attention can consider a small set of sampling locations as a pre-filter to highlight the key features of all feature maps, and it can naturally extend to fuse multi-scale features, allowing multi-scale deformable attention itself to exchange information between multi-scale feature maps without needing FPN operations.

Paper link: https://arxiv.org/pdf/2010.04159.pdf
Deformable DETR Method and Model Interpretation
Deformable DETR combines the advantages of sparse spatial sampling in deformable convolution with the relational modeling capability in the Transformer. Researchers proposed a deformable attention module (as shown in the formula (2) below), which focuses on a small number of sampling locations as significant key elements pre-filtered from all pixels of the feature map.

This module can be extended to aggregate multi-scale features (as shown in formula (3) below), without needing FPN.
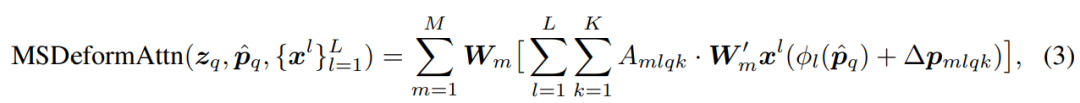
Deformable DETR replaces the attention in DETR with Deformable Attention, making the DETR paradigm’s detector more efficient, improving convergence speed by 10 times, as shown in the figure below:
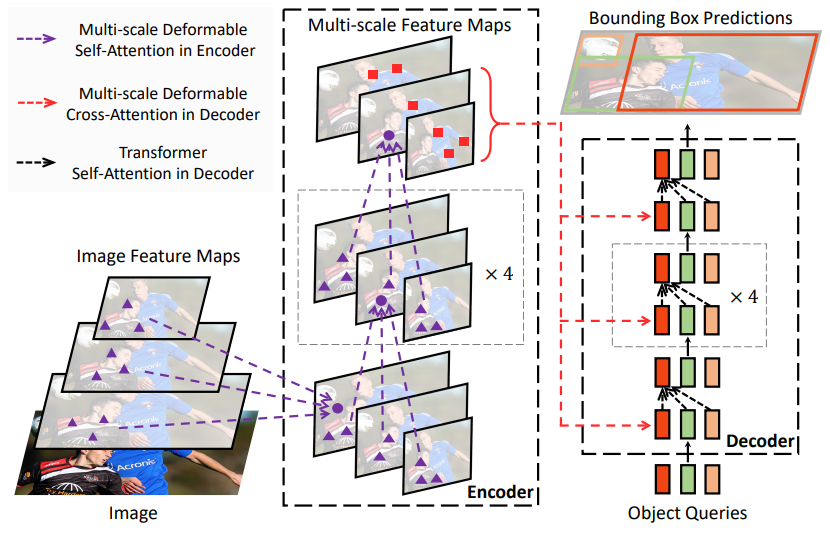
Due to the rapid convergence and computational memory efficiency of Deformable DETR, it opens up the possibility of exploring variants of end-to-end object detectors. In addition, researchers explored a simple and effective iterative object bounding box refinement mechanism to further improve detection performance. They also attempted a two-stage network architecture of Deformable DETR, where the region proposals of the first stage are generated by a variant of Deformable DETR, and then further input into the decoder for iterative object bounding box refinement.
Paper 3: UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
Inspired by the tremendous success of pre-trained transformers in NLP tasks, researchers from South China University of Technology and Tencent Wechat AI proposed a pre-task called random query patch detection for unsupervised pre-training of DETR (UP-DETR) for object detection. Specifically, researchers randomly cropped patches from a given image and provided these cropped patches as queries to the decoder.
The model can detect these query patches from the original image after pre-training. During pre-training, two key issues need to be addressed: multi-task learning and multi-query localization. On one hand, to balance the multi-task learning of classification and localization in the pre-task, this study froze the CNN backbone and proposed a patch feature reconstruction branch that is jointly optimized with patch detection. On the other hand, to perform multi-query localization, this study introduced UP-DETR from single-query patches and expanded it to multi-query patches with target query shuffle and attention masks. In experiments, UP-DETR significantly improved the performance of DETR on the PASCAL VOC and COCO datasets with faster convergence and higher accuracy.
During the pre-training process, researchers primarily addressed the following two key issues:
-
Multi-task learning: Object detection is coupled with object classification and localization. To avoid query patch detection from disrupting classification features, researchers introduced a frozen pre-trained backbone and patch feature reconstruction to maintain the feature recognition of the transformer;
-
Multi-query localization: Different object queries focus on different location areas and detection box sizes. To illustrate this property, researchers proposed simple single-query pre-training and expanded it to a multi-query version. For multi-query patches, researchers designed target query shuffle and attention masks to address the allocation problem between query patches and object queries.

Paper link: https://arxiv.org/pdf/2011.09094.pdf
UP-DETR includes a pre-training and fine-tuning process: unsupervised pre-training of the transformer on large datasets without any manual annotations; fine-tuning the entire model with labeled data identical to the original DETR for downstream tasks.
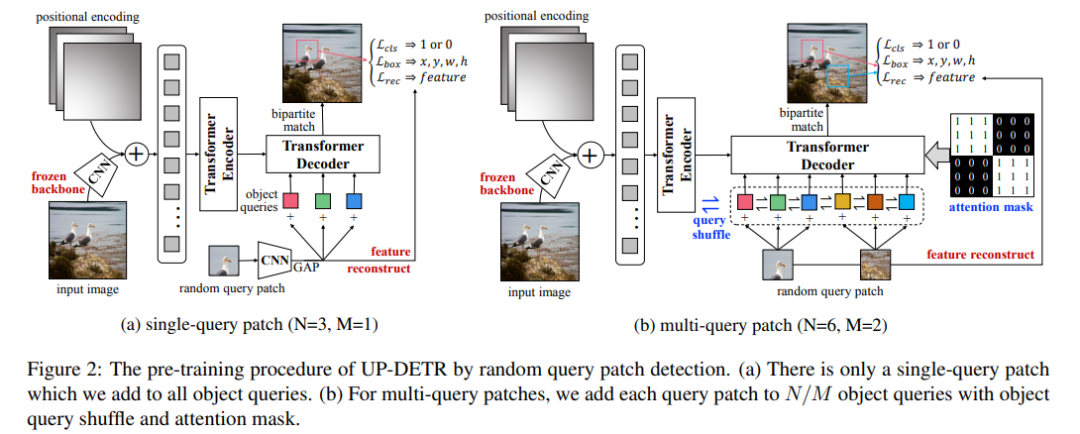
As shown in Figure 2, random query patch detection is simple yet effective. First, the frozen CNN backbone extracts feature maps f∈R^C×H×W from the input image, where C is the channel dimension and H×W is the feature map size. Then, in DETR, the feature maps are combined with positional encodings and passed to the multi-layer transformer encoder. For the randomly cropped query patches, CNN backbone extracts patch features p∈R^C using global average pooling (GAP), flattens them, and augments them with target queries q∈R^C, which are then passed to the transformer decoder. Note that query patches refer to the patches cropped from the original image, while target queries refer to position embeddings passed to the decoder. The CNN parameters are shared across the entire model.
Single Query Patch: DETR learns different spatial specializations for each object query, indicating that different object queries focus on different location areas and bounding box sizes. When randomly cropping patches from the image, there is no prior information about the location areas and bounding box sizes of the query patches. To maintain different spatial specializations, this study explicitly assigns a single query block (M=1) for all object queries (N=3), as shown in Figure 2(a).
Figure 2b shows the pre-training of multi-query patches with attention masks and target query shuffle. To improve generalization ability, researchers randomly masked 10% of the query patches to zero during pre-training, similar to the dropout method. In experiments, two typical values were set to N=100 and M=10.
Paper 4: End-to-End Object Detection with Adaptive Clustering Transformer
Using the Transformer for end-to-end object detection (DETR) can achieve performance comparable to two-stage network architectures (like Faster R-CNN). However, due to high-resolution spatial inputs, DETR requires significant computational resources for training and inference.
To reduce the computational cost of high-resolution inputs, researchers from Peking University and the Chinese University of Hong Kong proposed a new transformer variant: Adaptive Clustering Transformer (ACT). ACT adaptively clusters query features using local sensitive hashing (LSH) and utilizes prototype-key interaction to approximate query-key interaction. ACT can reduce the quadratic O(N^2) complexity of self-attention to O(NK), where K is the number of prototypes per layer. Without affecting the performance of the pre-trained DETR model, ACT can replace the original self-attention module in DETR. ACT achieves a good balance between accuracy and computational cost (FLOPs).

Paper link: https://arxiv.org/pdf/2011.09315.pdf
The main contributions of this research are as follows:
-
Proposed a new Adaptive Clustering Transformer (ACT) method that can reduce the inference cost of DETR. ACT aims to use lightweight LSH to select representative prototypes from queries, and then pass the updated features of the selected prototypes to the nearest queries. ACT can reduce the quadratic complexity of the original transformer while being fully compatible with the original transformer;
-
Without any training, this study reduced the FLOPS of DETR from 73.4 Gflops to 58.2 Gflops (excluding backbone ResNet FLOPs), with only a 0.7% loss in AP;
-
By multi-task knowledge distillation (MTKD), the loss in AP was reduced to 0.2%, achieving a seamless transition between ACT and the original transformer.
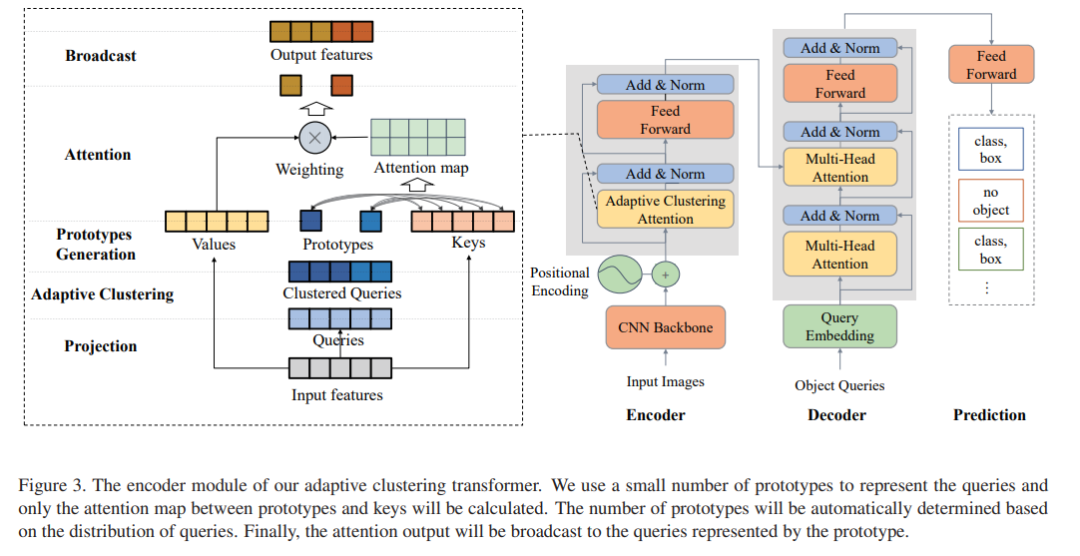
The following figure (Figure 3) shows the three stages of DETR. In the encoder, a ResNet model pre-trained on ImageNet extracts 2D features from the input image. The positional encoding module encodes spatial information using sine and cosine functions of different frequencies. DETR flattens the 2D features, supplements them with positional encodings, and passes them to a six-layer transformer encoder. Each layer of the encoder has the same structure, including an 8-head self-attention module and an FFN module. Then, the decoder takes a fixed number of learnable position embeddings as input, referred to as object queries, and additionally focuses on the encoder output. The decoder also has six layers, each containing an 8-head self-attention module and an 8-head cross-attention module, along with an FFN module. Finally, DETR passes each output from the decoder to a shared feed-forward network that predicts detection (class and bounding box) or no-object class.
https://blog.csdn.net/irving512/article/details/109713148
https://jishuin.proginn.com/p/763bfbd2ee77
A “Fresh Fragrance” Feast in Chengdu: DevRun Developer Salon Invites You to Start a “Spicy” Development Journey
Traveling to the southwest, meet Chengdu.
On December 12, the DevRun Developer Salon Huawei Cloud Chengdu Special Session will take you through: AI development and cloud-native DevOps advanced journey, face-to-face teaching guidance from Huawei Cloud technical experts, key points for breaking through technical bottlenecks and enhancing core efficiency, and the best posture to embrace change and self-advancement. Exciting moments not to be missed!
Scan the QR code to register now.

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]
