Machine Heart reports
Machine Heart Editorial Department
In the field of computer vision, Convolutional Neural Networks (CNNs) have always been dominant. However, researchers are continuously attempting to apply Transformers from the NLP domain to cross-disciplinary studies, with some achieving quite impressive results. Recently, an anonymous ICLR 2021 submission paper directly applied the standard Transformer to images, proposing a new Vision Transformer model that has achieved performance close to or even surpassing the current SOTA methods on multiple image recognition benchmarks.
On October 2, the top conference in deep learning, ICLR 2021, concluded its paper submissions, and a paper applying Transformers to image recognition garnered widespread attention.
Andrej Karpathy, head of Tesla AI, retweeted the paper, stating, “It is great to see the increasing convergence between computer vision and NLP.”
Previously, Facebook applied Transformers to object detection tasks, and OpenAI attempted image classification using GPT-2. What new attempts does this “cross-disciplinary” paper present?
Transformer architecture has long been widely used in natural language processing tasks, but it remains limited in the field of computer vision. In computer vision, attention is either used in conjunction with convolutional networks or to replace certain components of convolutional networks while keeping the overall architecture unchanged.
This research indicates that reliance on CNNs is not necessary; when directly applied to sequences of image patches, Transformers can also perform well on image classification tasks. The study pre-trained the model on a large dataset and transferred it to multiple image recognition benchmark datasets (ImageNet, CIFAR-100, VTAB, etc.), showing that the Vision Transformer (ViT) model can achieve results comparable to the current best convolutional networks while significantly reducing the computational resources required for training.
Transformer in NLP vs. CNN in Computer Vision
Self-attention-based architectures, especially Transformers, have become the preferred model in the NLP field. This mainstream approach pre-trains on large text corpora and then fine-tunes on smaller task-specific datasets. Due to the computational efficiency and scalability of Transformers, models with over 100 billion parameters can even be trained based on them. As models and datasets grow, there are still no signs of performance saturation.
However, in computer vision, convolutional architectures still dominate. Inspired by the success of NLP, many computer vision studies have attempted to combine CNN-like architectures with self-attention, some even completely replacing convolutions. Although the latter is theoretically effective, it has not yet scaled effectively on modern hardware accelerators due to its use of specialized attention patterns. Therefore, classical ResNet-like architectures remain state-of-the-art in large-scale image recognition tasks.
Cross-disciplinary Integration of Transformers into Vision
Inspired by the scaling success of Transformers in the NLP field, this study attempts to apply the standard Transformer directly to images while minimizing modifications. To this end, the research splits images into multiple image patches and uses the linear embeddings of these patches as input to the Transformer. The image patches are then processed in the same way tokens are processed in the NLP domain, and the image classification model is trained in a supervised manner.
When trained on medium-sized datasets (like ImageNet), such models produce suboptimal results, with accuracy several percentage points lower than equivalent-sized ResNets. This seemingly disappointing result is expected: Transformers lack some inherent inductive biases of CNNs, such as translational equivariance and locality, and therefore do not generalize well when trained on insufficient data.
However, when trained on large datasets (14M-300M images), the situation changes significantly. This research finds that large-scale training outweighs inductive biases. When pre-trained on sufficiently large data and transferred to tasks with fewer data points, Transformers can achieve excellent results.
The Vision Transformer proposed in this study was pre-trained on the JFT-300M dataset, achieving close to or exceeding SOTA levels on multiple image recognition benchmarks, reaching 88.36% accuracy on ImageNet, 90.77% accuracy on ImageNet ReaL, 94.55% accuracy on CIFAR-100, and 77.16% accuracy on 19 tasks in the VTAB benchmark.
The researchers followed the original design of the Transformer as closely as possible. This deliberately simple setup has the advantage that the scalable NLP Transformer architecture and its corresponding efficient implementations can almost be achieved out of the box. The researchers aimed to demonstrate that when appropriately scaled, this method is sufficient to surpass the current optimal convolutional neural networks.
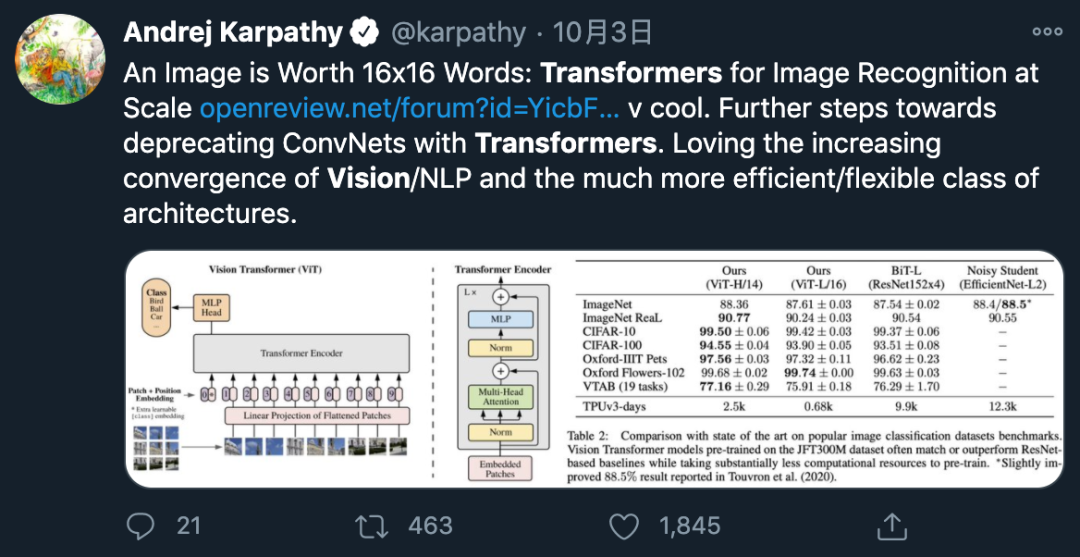
The Vision Transformer architecture proposed in this study follows the original Transformer architecture. Figure 1 below shows the model architecture.
The standard Transformer takes 1D sequence token embeddings as input. To process 2D images, the researchers reshape the image x ∈ R^H×W×C into a series of flattened 2D patches x_p ∈ R^N×(P^2 ·C), where (H, W) represents the resolution of the original image, and (P, P) represents the resolution of each image patch. Then, N = HW/P^2 becomes the effective sequence length for the Vision Transformer.
The Vision Transformer uses the same width across all layers, so a trainable linear projection maps each vectorized patch to the model dimension D (formula 1), and the corresponding output is called the patch embedding.
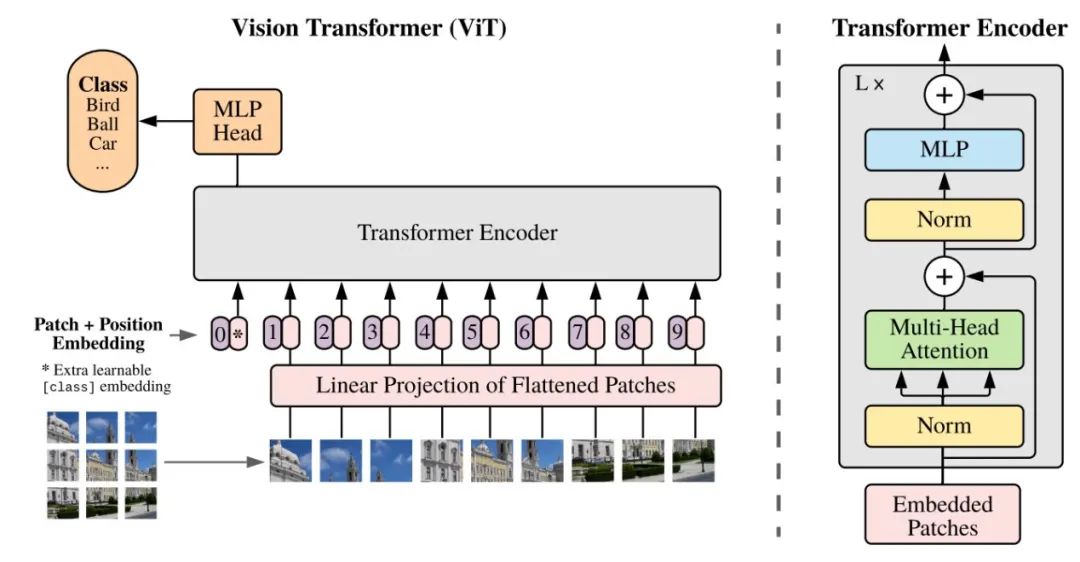
Similar to the [class] token in BERT, the researchers pre-add a learnable embedding before a series of embedded patches (z_0^0 = x_class), whose state in the output of the Transformer encoder (z_0^L) can serve as the image representation y (formula 4). During pre-training and fine-tuning, the classification head (head) is attached to z_L^0.
Position embeddings are added to patch embeddings to retain positional information. The researchers experimented with different 2D-aware variants of position embeddings, but there were no significant gains compared to standard 1D position embeddings. Therefore, the encoder takes the joint embeddings as input.
The Transformer encoder consists of multiple interactive layers of multi-head self-attention (MSA) and MLP blocks (formulas 2, 3). Layer normalization (LN) is applied before each block, and residual connections are applied after each block. The MLP consists of two layers presenting GELU non-linearities.
As an alternative to splitting images into patches, the output sequence can be formed through intermediate feature maps of ResNet. In this hybrid model, the patch embedding projection (formula 1) is replaced by an early-stage ResNet. One of the intermediate 2D feature maps of ResNet is flattened into a sequence, mapped to the Transformer dimension, and then fed in as the input sequence of the Transformer. Finally, as mentioned above, the classification input embedding and position embedding are added to the Transformer input.
Fine-tuning and Higher Resolution
The researchers pre-trained the ViT model on large datasets and fine-tuned the model for smaller downstream tasks. To do this, the researchers removed the pre-trained prediction head and added a zero-initialized D × K feed-forward layer, where K represents the number of downstream classes. Fine-tuning at higher resolutions is usually more beneficial compared to pre-training. When feeding in higher resolution images, the researchers kept the patch size unchanged, resulting in a larger effective sequence length.
The ViT model can handle arbitrary sequence lengths (depending on memory constraints), but the pre-trained position embeddings may no longer be meaningful. Therefore, the researchers performed 2D interpolation on them based on their positions in the original image. It is important to note that only during resolution adjustment and patch extraction can the inductive biases of 2D images be manually injected into the ViT model.
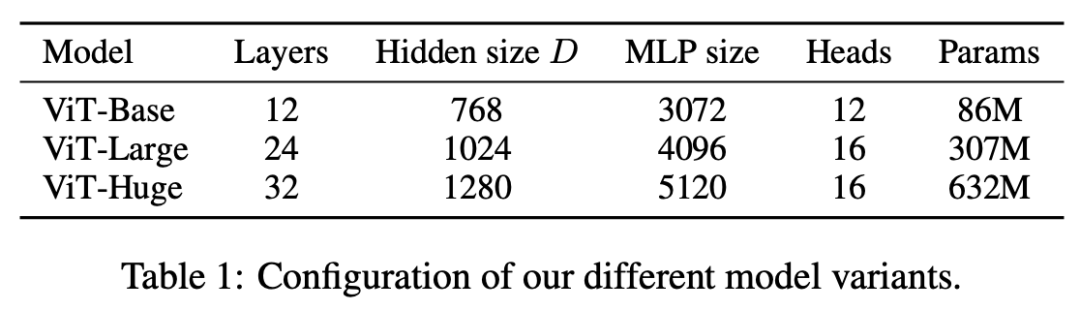
The researchers conducted extensive experiments using multiple ViT model variants, as shown in Table 1:
Performance Comparison with SOTA Models
The researchers first compared the largest ViT models (ViT-H/14 and ViT-L/16 pre-trained on the JFT-300M dataset) with SOTA CNN models, as shown in Table 2.
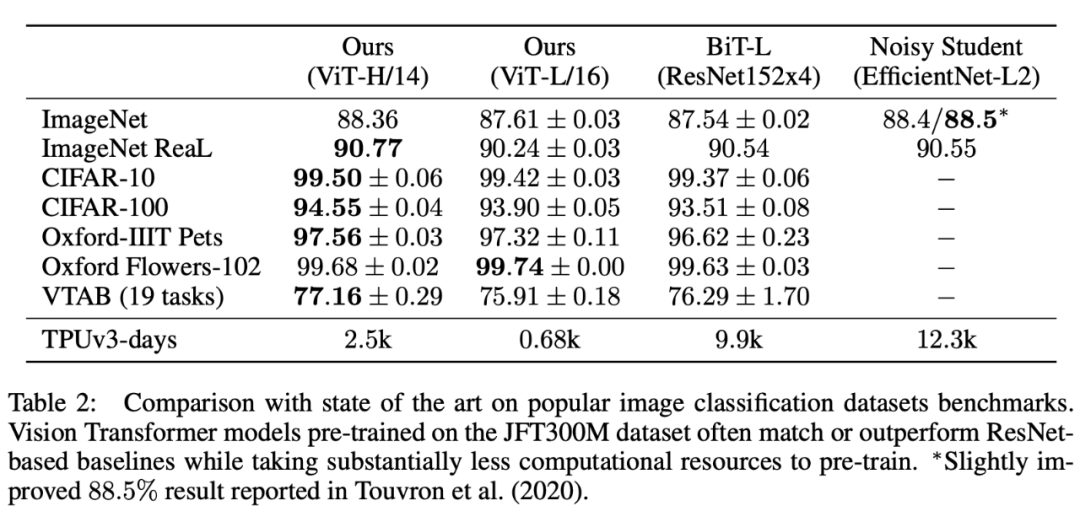
Table 2: Performance comparison of ViT models with SOTA models on popular image classification benchmark datasets.
From the table, it can be seen that the smaller ViT-L/16 model performs comparably or exceeds BiT-L on all datasets while requiring much less computational power. The larger ViT-H/14 model further enhances performance, especially on more challenging datasets like ImageNet, CIFAR-100, and VTAB. The ViT-H/14 model matches or exceeds SOTA on all datasets, and in some cases significantly outperforms SOTA models (e.g., 1% higher performance on the CIFAR-100 dataset). On the ImageNet dataset, the performance of the ViT model is about 0.1% lower than Noisy Student, but on the cleaner ReaL labels of the ImageNet dataset, the ViT outperforms the SOTA model.
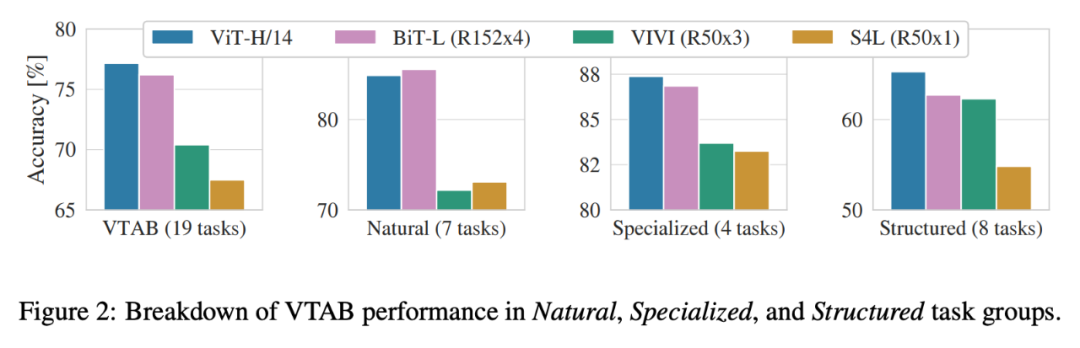
Figure 2 breaks down the VTAB tasks into several groups and compares the performance of ViT with SOTA methods, including BiT, VIVI, and S4L.
In Natural tasks, the performance of ViT-H/14 is slightly lower than BiT-R152x4; in Specialized tasks, the performance of ViT exceeds methods like BiT; while in Structured tasks, ViT significantly outperforms other methods.
Pre-training Data Requirements
After pre-training on the large JFT-300M dataset, the Vision Transformer demonstrated excellent performance. What is the geometric importance of dataset scale when ViT has less inductive bias than ResNet? The study conducted some experiments.
First, the ViT model was pre-trained on progressively larger datasets (ImageNet, ImageNet-21k, and JFT300M). Figure 3 shows the model’s performance on the ImageNet dataset:
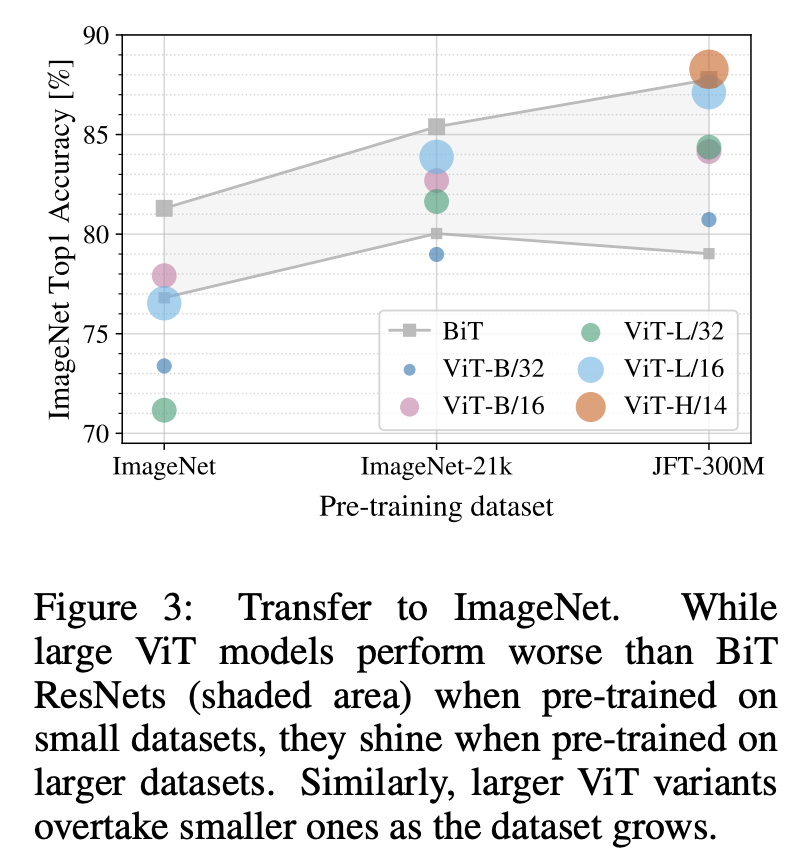
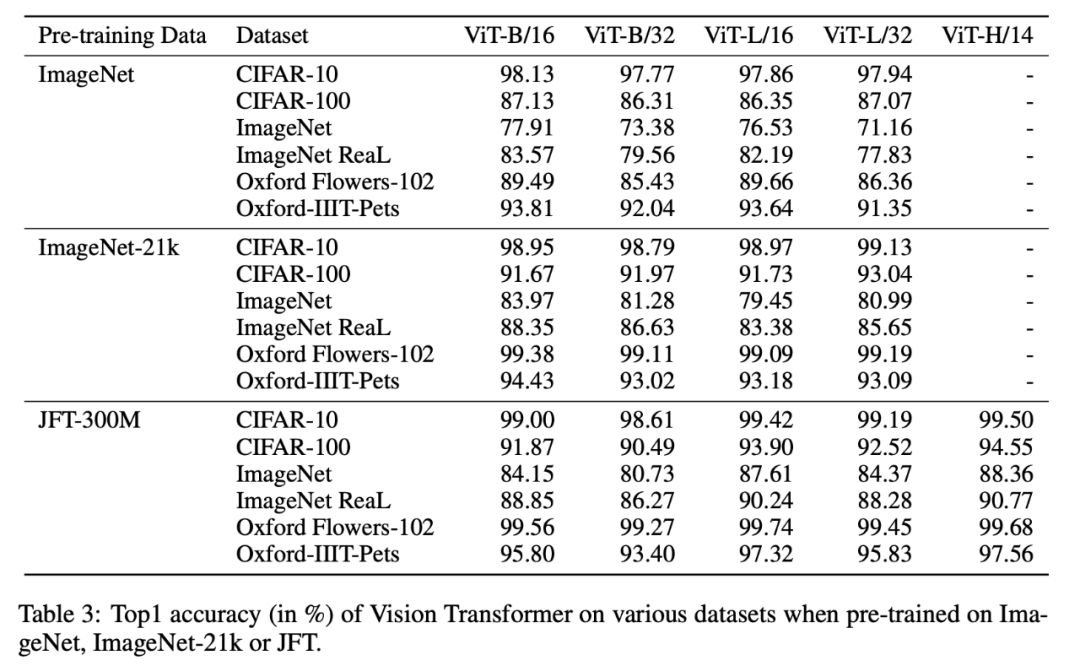
Table 3 shows the performance comparison of the model on the ImageNet, ImageNet-21k, and JFT300M datasets. On the first two smaller datasets, the ViT-Large model’s performance is inferior to that of ViT-Base, but on the larger JFT300M dataset, the larger model shows advantages. This indicates that as the dataset scale increases, larger ViT model variants outperform smaller models.
Secondly, the researchers trained the model on random subsets of 9M, 30M, and 90M from the JFT300M dataset, as well as the full dataset. The results are shown in Figure 4:
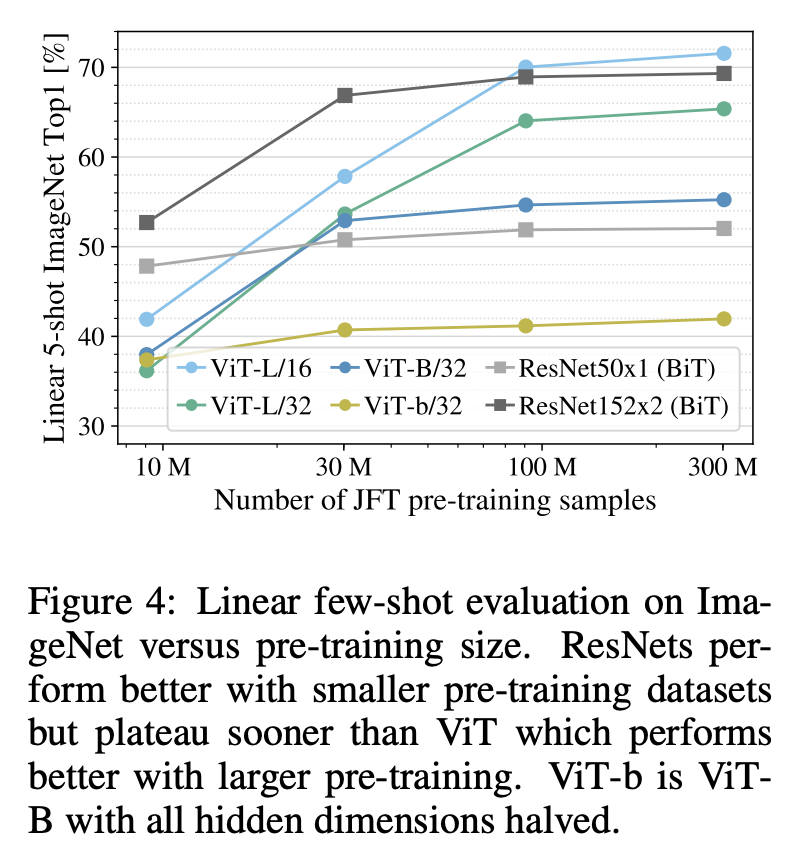
From the figure, it can be seen that, with smaller datasets and the same computational cost, the Vision Transformer overfits more than ResNet. This reinforces the understanding that: Convolutional inductive biases are useful for smaller datasets, but for larger datasets, learning relevant patterns is sufficient and even more effective.
The researchers performed controlled scalability studies on different models. Figure 5 shows the transfer performance of the models under different pre-training computational costs:
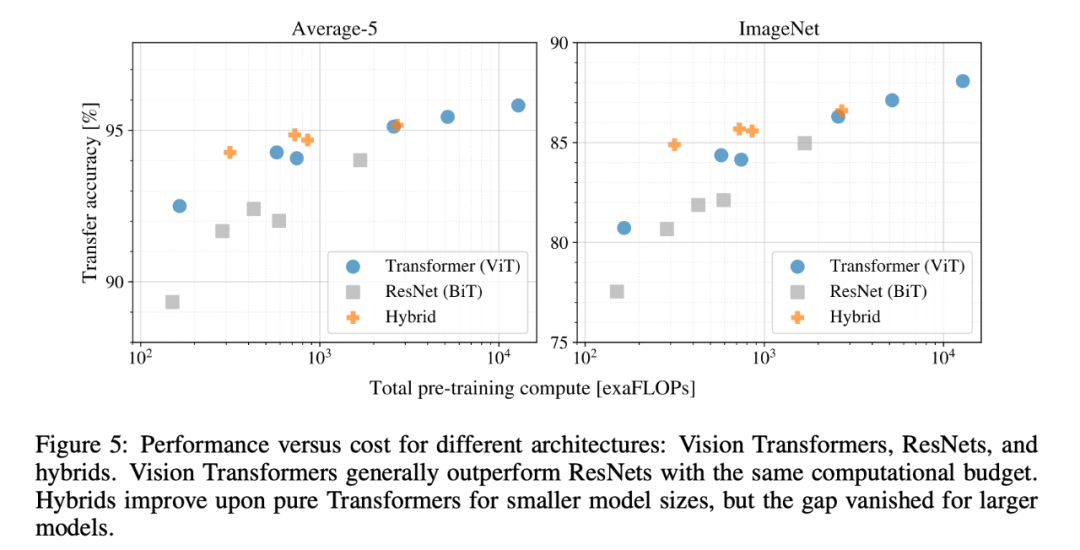
The experimental results indicate:
-
The Vision Transformer significantly outperforms ResNet in performance/computational power trade-offs.
-
The hybrid model slightly outperforms ViT under lower computational costs, but this phenomenon disappears under higher computational costs. This result is surprising.
-
The Vision Transformer does not seem to saturate within the computational range attempted in the experiments, suggesting that further scalability research can be conducted in the future.
How Does ViT Process Image Data?
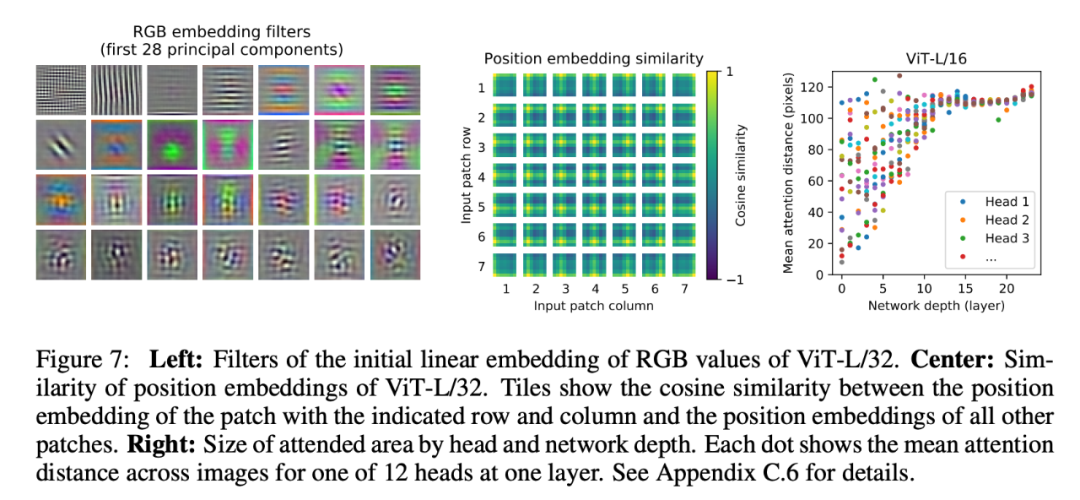
To understand how ViT processes image data, the researchers analyzed its internal representations.
The first layer of ViT linearly projects the flattened image patches into a lower-dimensional space (formula 1), and the left figure shows the main components of the learned embedding filters. After projection, the learned position embeddings are added to the image patch representations. The middle figure shows how the model learns to encode distances within images, indicating that image patches that are closer together are more likely to have similar position embeddings. Self-attention allows ViT to integrate information from the entire image, even in the lowest layers. The researchers investigated the extent to which the ViT network utilizes this capability. Specifically, the study calculated the average distance in image space (based on attention weights), as shown in the right figure. “Attention distance” is similar to the receptive field size in CNNs.
The ViT model focuses on image areas that are semantically relevant to classification, as shown in Figure 6:

In the Zhihu question “What submissions are worth noting in ICLR 2021?”, multiple answers mentioned this paper, with interpretations and critiques. Some netizens even stated: “We are standing on the eve of a major transformation in models; the potential of neural networks has not yet reached its end. A brand new, powerful model capable of overturning the entire CV and AI field is just revealing its tip of the iceberg and is about to arrive in full force.“

https://openreview.net/pdf?id=YicbFdNTTy
https://www.zhihu.com/question/423975807
How to Match the Right Type of Database According to Task Requirements?
In the white paper “Entering the Era of Dedicated Databases” launched by AWS, eight types of databases are introduced: relational, key-value, document, in-memory, relational graph, time series, ledger, and domain-wide columnar, analyzing the advantages, challenges, and main use cases of each type.
Clickto read the original textorscan the QR code, apply to get the white paper for free.

© THE END
For reprints, please contact this public account for authorization
Submission or seeking coverage: [email protected]
