Click above toComputer Vision Alliance get more insights
For academic sharing only, does not represent the position of this public account. Contact for deletion in case of infringement.
Reprinted from: Machine Heart
Recommended notes from 985 AI PhD
Zhou Zhihua’s “Machine Learning” handwritten notes are officially open-source! Includes PDF download link, 2500 stars on GitHub!
The limitation of sequence length in large language models greatly restricts their application in the field of artificial intelligence, such as multi-turn dialogue, long text understanding, and processing and generating multimodal data. The fundamental reason for this limitation lies in the quadratic computational complexity relative to sequence length of the Transformer architecture currently adopted by all large language models. This means that as the sequence length increases, the required computational resources increase geometrically. Efficiently handling long sequences has always been one of the challenges for large language models.
Previous methods often focused on how to adapt large language models to longer sequences during the inference phase. For example, using Alibi or similar relative position encoding methods to allow the model to adapt to different input sequence lengths, or using interpolation methods for relative position encodings like RoPE to perform further short fine-tuning on already trained models to achieve the goal of extending sequence length. These methods only give large models a certain capability for long sequence modeling, but the actual training and inference costs have not decreased.
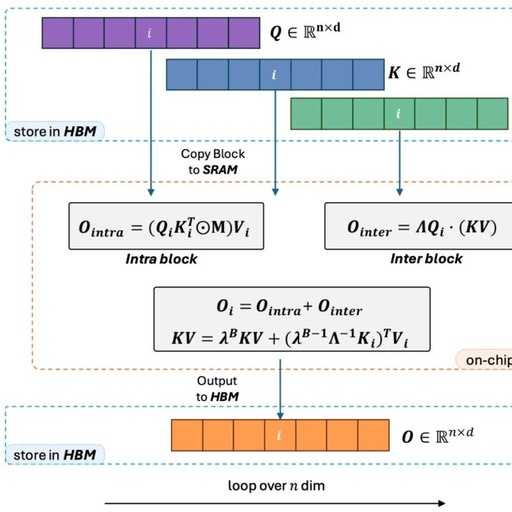
The OpenNLPLab team attempts to solve the long sequence issue in large language models once and for all. They proposed and open-sourced Lightning Attention-2—a new type of linear attention mechanism that aligns the training and inference costs for long sequences with those of a 1K sequence length. Before encountering VRAM bottlenecks, infinitely increasing the sequence length does not negatively impact the model’s training speed. This makes infinite-length pre-training possible. Meanwhile, the inference cost for ultra-long texts is consistent with or even less than that of 1K tokens, which will greatly reduce the current inference costs of large language models. As shown in the figure below, with model sizes of 400M, 1B, and 3B, as the sequence length increases, the training speed of LLaMA with FlashAttention2 begins to decline rapidly, while the speed of TansNormerLLM with Lightning Attention-2 remains virtually unchanged.

-
Paper: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
-
Paper link: https://arxiv.org/pdf/2401.04658.pdf
-
Open-source link: https://github.com/OpenNLPLab/lightning-attention
Introduction to Lightning Attention-2
Keeping the pre-training speed of large models consistent across different sequence lengths sounds like an impossible task. In fact, if the computational complexity of an attention mechanism remains linear relative to sequence length, this can be achieved. Since the advent of linear attention in 2020 【https://arxiv.org/abs/2006.16236】, researchers have been striving to ensure that the practical efficiency of linear attention aligns with its theoretical linear computational complexity. Before 2023, most works on linear attention focused on aligning their accuracy with that of Transformers. Finally, in mid-2023, the improved linear attention mechanism 【https://arxiv.org/abs/2307.14995】 achieved accuracy comparable to state-of-the-art Transformer architectures. However, the key computational trick of turning the computational complexity of linear attention into a linear form, known as “left multiplication turns into right multiplication” (as shown in the figure below), is much slower in practical implementation than the direct left multiplication algorithm. This is because the implementation of right multiplication requires cumulative summation (cumsum) involving a large number of loop operations, and extensive IO operations make right multiplication’s efficiency far lower than left multiplication.
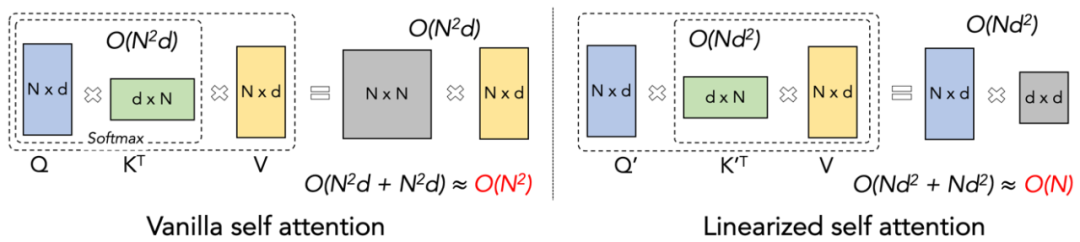
To better understand the concept of Lightning Attention-2, let’s first review the computation formula of traditional softmax attention: O=softmax ((QK^T)⊙M_) V, where Q, K, V, M, O represent query, key, value, mask, and output matrix respectively. Here, M is a lower triangular matrix of all 1s in unidirectional tasks (like GPT), and can be ignored in bidirectional tasks (like Bert), meaning there is no mask matrix in bidirectional tasks.
The author summarizes the overall idea of Lightning Attention-2 into the following three points for explanation:
1. One of the core ideas of linear attention is to remove the costly softmax operator, allowing the attention computation formula to be written as O=((QK^T)⊙M_) V. However, due to the existence of the mask matrix M in unidirectional tasks, this form can still only perform left multiplication calculations, thus failing to achieve O (N) complexity. But for bidirectional tasks, since there is no mask matrix, the computation formula for linear attention can be further simplified to O=(QK^T) V. The brilliance of linear attention lies in the fact that by simply utilizing the associative property of matrix multiplication, its computation formula can be further transformed to: O=Q (K^T V), which is known as right multiplication, while the former is left multiplication. As shown in Figure 2, it can be intuitively understood that linear attention can achieve an attractive O (N) complexity in bidirectional tasks!
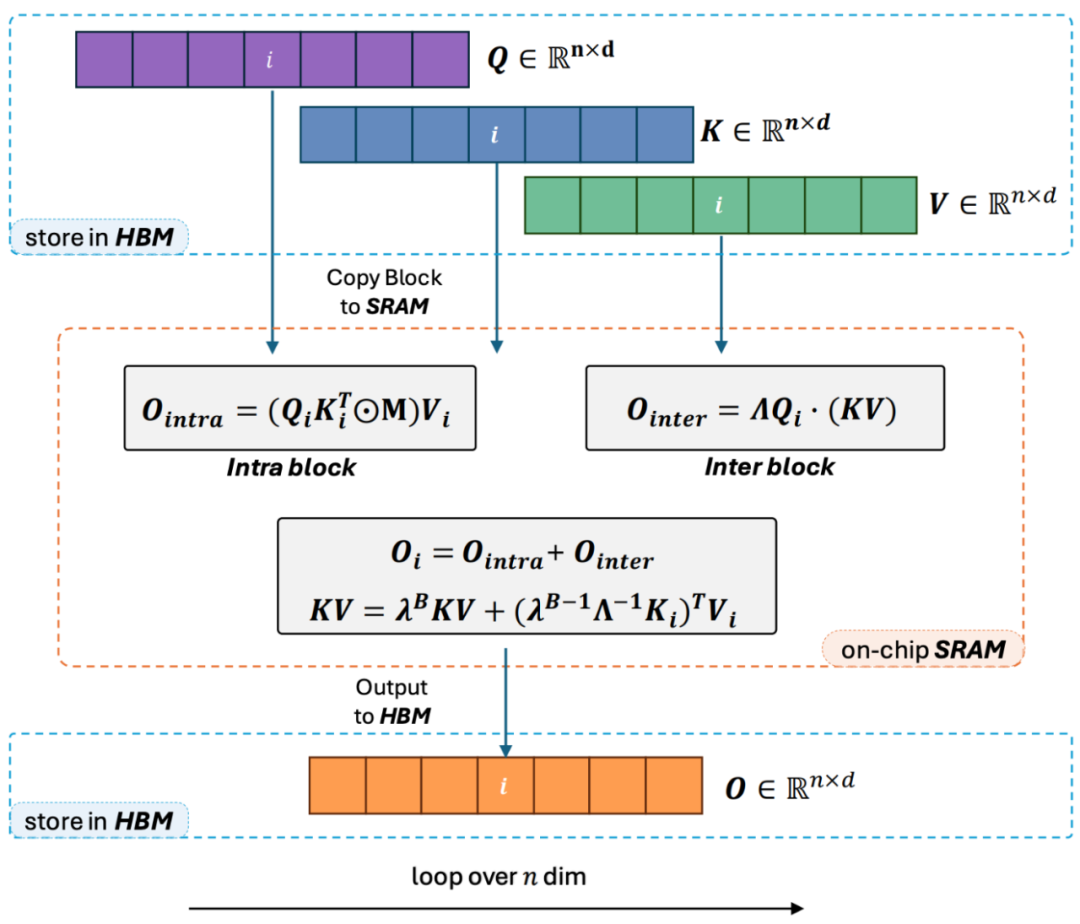
2. However, as decoder-only GPT-style models gradually become the de facto standard for LLMs, how to leverage the right multiplication characteristics of linear attention to accelerate unidirectional tasks has become an urgent problem to solve. To tackle this issue, the author proposes to utilize a “divide and conquer” approach, dividing the computation of the attention matrix into diagonal and non-diagonal forms and adopting different methods for their computations. As shown in Figure 3, Linear Attention-2 utilizes the commonly used Tiling concept in computer science, splitting the Q, K, V matrices into the same number of blocks. The intra-block computation due to the presence of the mask matrix still retains the left multiplication method, having O (N^2) complexity; while inter-block computation, due to the absence of the mask matrix, can adopt the right multiplication method, thus enjoying O (N) complexity. After both are computed, they can be directly added to obtain the corresponding Linear Attention output Oi for the i-th block. Additionally, by using cumsum to accumulate the state of KV for use in the next block’s computation. This yields the overall algorithm complexity of Lightning Attention-2 as a trade-off between intra-block O (N^2) and inter-block O (N). How to achieve a better trade-off is determined by the Tiling block size.
3. Observant readers will notice that the above process is just the algorithm part of Lightning Attention-2. The name Lightning is derived from the author’s full consideration of the efficiency of this algorithmic process in GPU hardware execution. Inspired by the FlashAttention series of works, when performing calculations on the GPU, the author transports the split Q_i, K_i, V_i tensors from the slower, larger HBM inside the GPU to the faster, smaller SRAM for computation, thereby reducing a significant amount of memory IO overhead. Once the block completes the Linear Attention computation, its output O_i is transported back to HBM. This process is repeated until all blocks have been processed.
Readers who want to know more details can carefully read Algorithm 1 and Algorithm 2 in this article, as well as the detailed derivation process in the paper. The algorithms and derivation processes distinguish between the forward and backward processes of Lightning Attention-2, helping readers gain a deeper understanding.

Speed Comparison of Lightning Attention-2
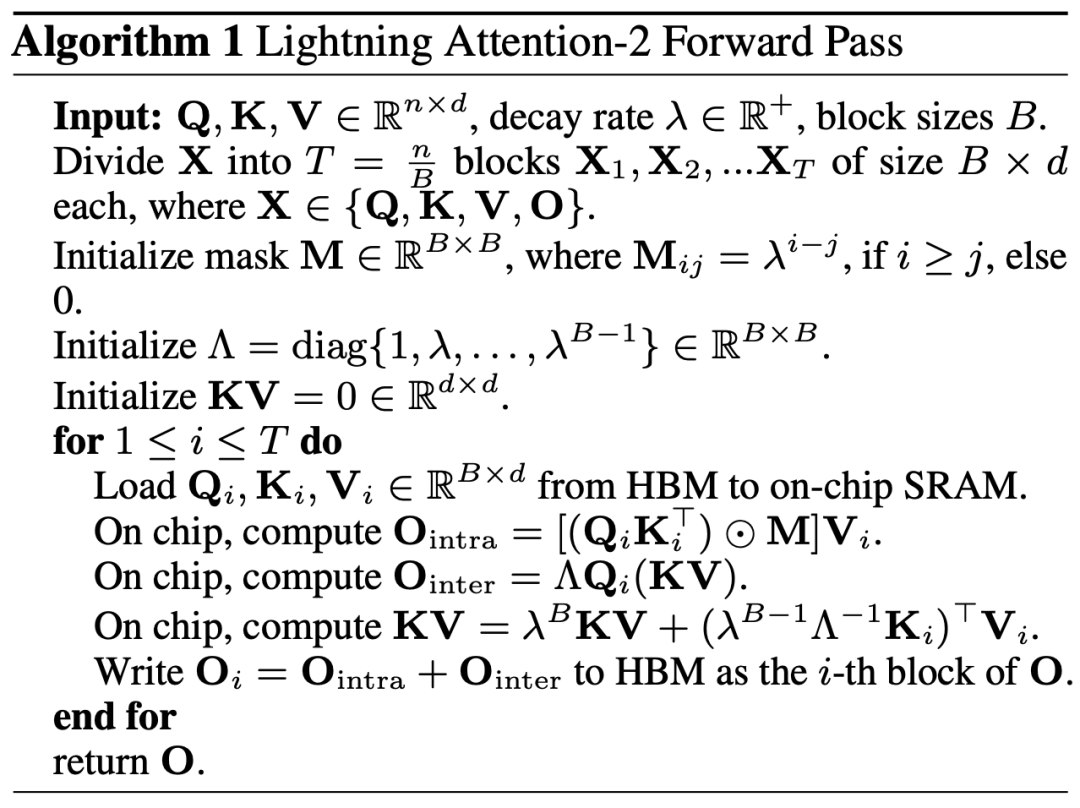
The researchers first compared the accuracy differences between Lightning Attention-2 and Lightning Attention-1 on a small-scale (400M) parameter model, as shown in the figure below, with almost no difference between the two.
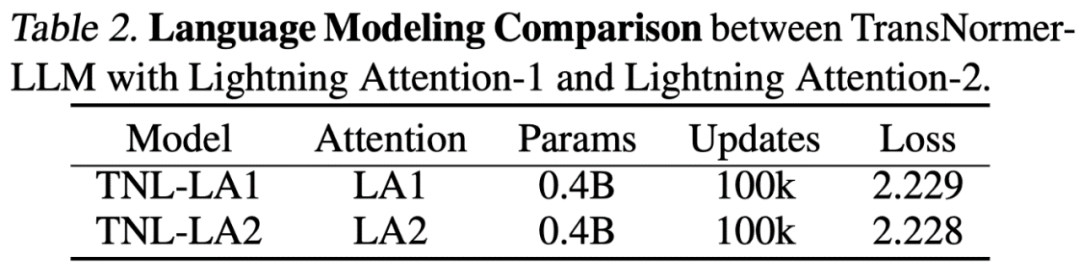
Subsequently, the researchers compared TansNormerLLM (TNL-LA2) powered by Lightning Attention-2 with other advanced non-Transformer architectures and LLaMA powered by FlashAttention2 on the same corpus at 1B and 3B. As shown in the figure below, TNL-LA2 maintained a similar trend to LLaMA and exhibited better loss performance. This experiment indicates that Lightning Attention-2 achieves accuracy performance comparable to that of state-of-the-art Transformer architectures in language modeling.
In large language model tasks, researchers compared TNL-LA2 15B with Pythia on common benchmarks for large models of similar size. As shown in the table below, under the condition of consuming the same tokens, TNL-LA2 slightly outperformed the Pythia model based on Softmax attention in terms of commonsense reasoning and multiple-choice comprehensive abilities.

Speed Comparison of Lightning Attention-2
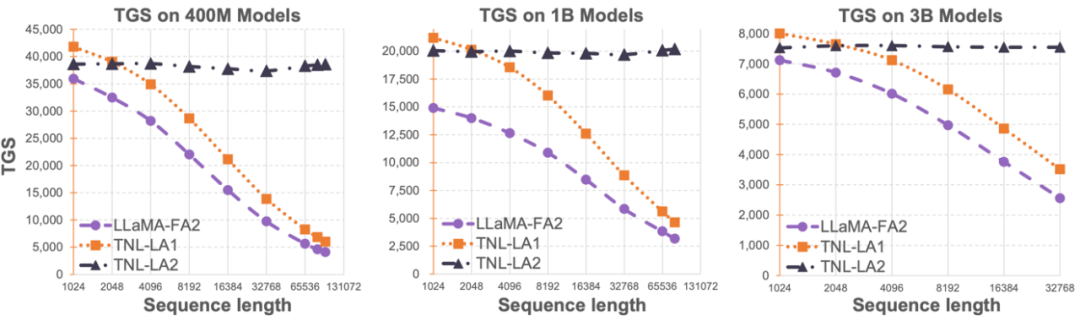
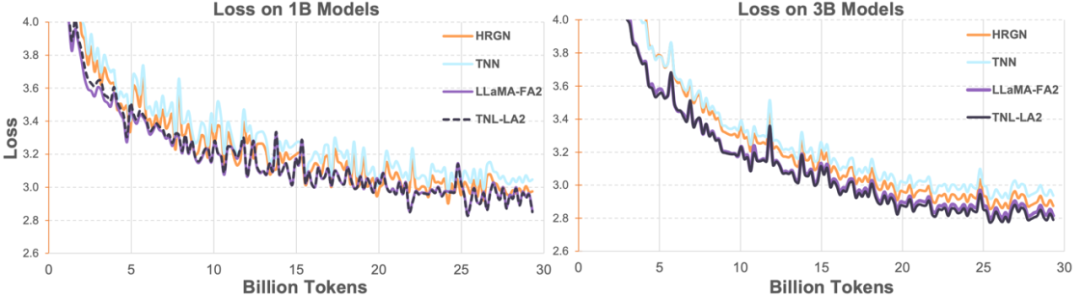
The researchers compared the speed and memory usage of Lightning Attention-2 with FlashAttention2 on a single module. As shown in the figure below, compared to Lightning Attention-1 and FlashAttention2, Lightning Attention-2 exhibited strictly linear growth in speed relative to sequence length. In terms of memory usage, all three showed similar trends, but Lightning Attention-2 had lower memory usage. This is because FlashAttention2 and Lightning Attention-1 also exhibited approximately linear memory usage.
The author notes that this article primarily focuses on addressing the training speed of linear attention networks, achieving training speeds for arbitrary-length long sequences similar to those of 1K sequences. There is not much discussion on inference speed. This is because linear attention can losslessly transform into RNN mode during inference, thereby achieving similar effects, i.e., maintaining a constant speed for inferring a single token. For Transformers, the inference speed of the current token is related to the number of previous tokens.
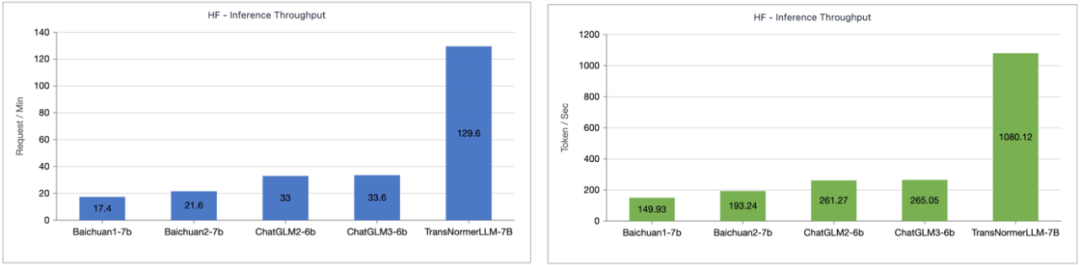
The author tested the inference speed comparison between TransNormerLLM-7B powered by Lightning Attention-1 and common 7B models. As shown in the figure below, at similar parameter sizes, Lightning Attention-1 exhibited a throughput speed 4 times that of Baichuan and over 3.5 times that of ChatGLM, demonstrating excellent advantages in inference speed.
Lightning Attention-2 represents a significant advancement in linear attention mechanisms, allowing it to perfectly replace traditional Softmax attention in both accuracy and speed, providing sustainable scalability for increasingly larger models and offering a pathway to process infinitely long sequences more efficiently. The OpenNLPLab team will explore sequence parallel algorithms based on linear attention mechanisms in the future to address the current memory barrier issues.
I am Wang Bo Kings, a 985 AI PhD, Huawei Cloud expert, and CSDN blog expert (high-quality author in the field of artificial intelligence). A single AI open-source project has now gained over 2100 stars. Currently engaged in AI-related content, welcome to discuss and learn together about various issues in life and study, let’s make progress together!
Our WeChat group covers the following areas (but is not limited to): artificial intelligence, computer vision, natural language processing, object detection, semantic segmentation, autonomous driving, GAN, reinforcement learning, SLAM, face detection, latest algorithms, latest papers, OpenCV, TensorFlow, PyTorch, open-source frameworks, learning methods…
This is my private WeChat, limited spots, let’s improve together!
Wang Bo’s public account, welcome to follow, full of insights
Mind Map | “Model Evaluation and Selection” | “Linear Models” | “Decision Trees” | “Neural Networks” | Support Vector Machines (Upper) | Support Vector Machines (Lower) | Bayesian Classification (Upper) | Bayesian Classification (Lower) | Ensemble Learning (Upper) | Ensemble Learning (Lower) | Clustering | Dimensionality Reduction and Metric Learning | Sparse Learning | Computational Learning Theory | Semi-Supervised Learning | Probabilistic Graph Models | Rule Learning
Is it difficult to graduate from a PhD to a university? | What are some experiences in reading papers? | Let’s talk about job hopping | Let’s discuss the composition of internet salary income | How can master’s and doctoral students in machine learning save themselves? | Let’s talk about the employment choices of Top 2 computer PhDs in 2021 | How can non-computer majors transition to computer science? | What are some research experiences that are regrettable to realize too late? | Experience | How can computer science majors improve their programming skills? | How can a PhD read literature efficiently? | What are some life experiences that are better to know earlier? |
PyTorch tensor Tensor | Convolutional Neural Network CNN architecture | Deep Learning Semantic Segmentation | Deep Understanding of Transformer | Scaled-YOLOv4! | PyTorch installation and introduction | PyTorch Neural Network Box | Numpy Basics | 10 articles on image classification | CVPR 2020 Object Detection | Visual Explanation of Neural Networks | YOLOv4 Full Interpretation and Translation Summary |