Multimodal learning and attention mechanisms are currently hot topics in deep learning research, and cross-attention fusion serves as a convergence point for these two fields, offering significant development space and innovation opportunities.
As a crucial component of multimodal fusion, cross-attention fusion establishes connections between different modules through attention mechanisms, facilitating the exchange and integration of information, thereby enhancing the model’s ability to handle complex tasks and demonstrating its powerful advantages in multimodal learning and clustering analysis.
This article reviews 13 technical achievements related to cross-attention fusion, including the latest research from 2024. I have organized the source articles and code for these modules, hoping to contribute to your papers.
Scan to add Xiao Xiang, reply “Cross Attention”
Getallpapers + module code for free

1. Rethinking Cross-Attention for Infrared and Visible Image Fusion
Method: This paper proposes an end-to-end ATFuse network for fusing infrared images. By introducing a Difference Information Injection Module (DIIM) based on the cross-attention mechanism, it can explore the unique features of source images separately. Additionally, the authors applied an Alternating Common Information Injection Module (ACIIM) to adequately retain common information in the final results. To train ATFuse, the authors designed a segmentation pixel loss function composed of different pixel intensity constraints to achieve a good balance of texture details and brightness information in the fusion results.
Innovations:
-
An end-to-end ATFuse network for fusing IV images has been proposed. Extensive experiments conducted on multiple datasets demonstrate that the proposed ATFuse method exhibits good performance and generalization capability. -
A Difference Information Injection Module (DIIM) based on the cross-attention mechanism has been proposed. This DIIM can explore the unique features of source images separately. -
An Alternating Common Information Injection Module (ACIIM) is applied in the proposed framework, ensuring that common information is adequately retained in the final results. -
A segmentation pixel loss function composed of different pixel intensity constraints is designed to train ATFuse, aiming for a good trade-off between texture details and brightness information in the fusion results.

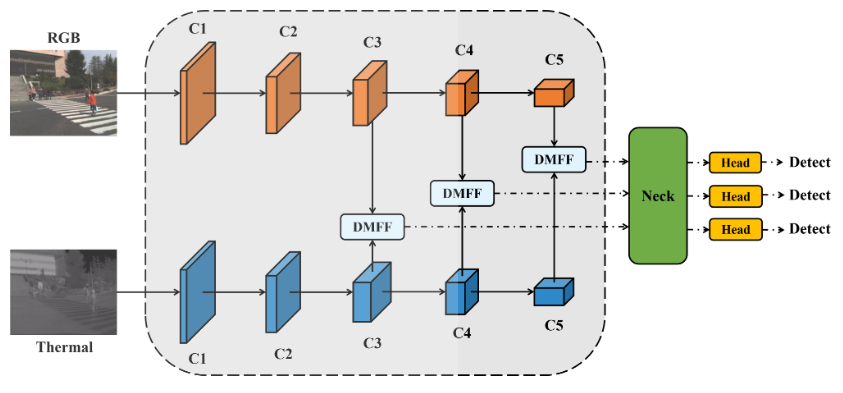
2. ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
Method: The authors propose a novel dual cross-attention feature fusion method for multispectral object detection, aggregating complementary information from RGB and thermal infrared images. This method includes three phases: single-modal feature extraction, dual-modal feature fusion, and detection. In the single-modal feature extraction phase, features from RGB and thermal infrared images are extracted separately. In the dual-modal feature fusion phase, features from different branches are aggregated through the cross-attention mechanism. Finally, the fused features are input into the detector for multi-scale feature fusion, classification, and regression.
Innovations:
-
A dual cross-attention transformer feature fusion framework is proposed, modeling global feature interactions and simultaneously capturing complementary information between modalities. The query-guided cross-attention mechanism enhances the discernibility of object features, thereby improving performance. -
An iterative interaction mechanism is proposed, which reduces model complexity and computational costs by sharing parameters between block-based multimodal transformers. This iterative learning strategy further improves model performance without increasing learnable parameters.
3. 2D-3D Interlaced Transformer for Point Cloud Segmentation with Scene-Level Supervision
Method: This paper proposes a Multimodal Interlaced Attention Transformer (MIT) for weakly supervised point cloud segmentation. The method includes two encoders and a decoder for extracting features from 3D point clouds and 2D multi-view images, respectively. The decoder achieves implicit fusion of 2D and 3D features through cross-attention. The authors alternately switch the roles of queries and key-value pairs, allowing 2D and 3D features to enrich each other.
Innovations:
-
By using multi-view information without additional annotation work, the proposed MIT effectively fuses 2D and 3D features, significantly improving 3D point cloud segmentation. -
Weakly supervised point cloud segmentation. This task aims to learn point cloud segmentation models using weakly labeled data (such as sparse labeled points, bounding box-level labels, sub-cloud-level labels, and scene-level labels). Significant progress has been made in settings using sparse labeled points: state-of-the-art methods achieve comparable performance to supervised methods. -
2D and 3D fusion for point cloud applications. Existing methods rely on camera poses and/or depth images to establish correspondences between 2D and 3D domains. In contrast, this method learns a transformer through interleaved 2D-3D attention to achieve implicit fusion of 2D and 3D features without requiring camera poses or depth images. -
Query and key-value pair exchange. Cross-attention is widely applied in transformer decoders, capturing dependencies between queries and key-value pairs. Unlike their method, this approach applies query and key-value pair exchange for cross-domain feature fusion.

Scan to add Xiao Xiang, reply “Cross Attention”
Getallpapers + module code for free

4. MMViT: Multiscale Multiview Vision Transformers
Method: This paper introduces a novel Multiscale Multiview Vision Transformer (MMViT) model, serving as a backbone model suitable for various modalities. The model combines the advantages of Multiscale Vision Transformers (MViT) and Multiview Transformers (MTV) by feeding multiple views into a multiscale stage hierarchical model. At each scale stage, cross-attention layers are used to fuse information from views of different resolutions, enabling the network to capture complex high-dimensional features.
Innovations:
-
The MMViT model introduces cross-attention layers, allowing the model to acquire multi-view information at each scale stage. By processing multiple views of different resolutions in parallel, the MMViT model can capture multi-resolution temporal context at each scale stage. -
The MMViT model employs a hierarchical scaling system, generating high-dimensional complex features by increasing channel sizes and reducing spatial resolutions. This hierarchical scaling system enables the network to capture more complex features as depth increases.
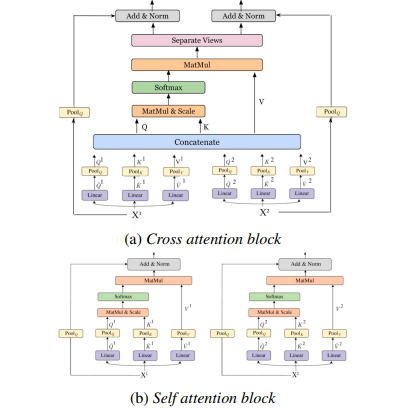
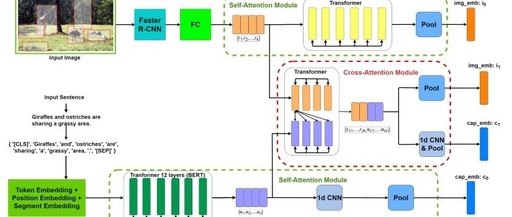
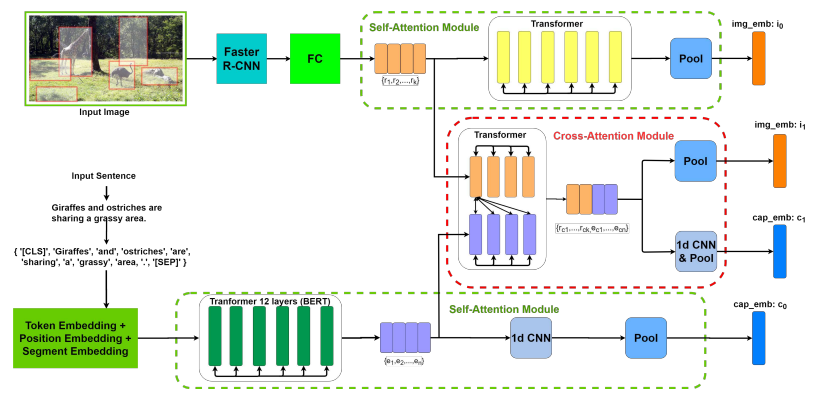
5. Multi-Modality Cross Attention Network for Image and Sentence Matching
Method: The authors propose a novel image and sentence matching method by jointly modeling cross-modal and intra-modal relationships in a unified deep model. The authors first extract salient image regions and sentence tokens. Then, they apply the proposed self-attention module and cross-attention module to leverage the complex fine-grained relationships between segments. Finally, by minimizing a triplet loss based on difficult negative samples, the visual and textual features are updated into a common embedding space.
Innovations:
-
A novel image and sentence matching method is proposed by jointly modeling cross-modal and intra-modal relationships in a unified deep model. First, salient image regions and sentence tokens are extracted. Then, the proposed self-attention module and cross-attention module are applied to leverage the complex fine-grained relationships between segments. Finally, minimizing a triplet loss based on difficult negative samples updates the visual and textual features into a common embedding space. -
A novel multimodal cross-attention network is proposed, which jointly models intra-modal relationships of image regions and sentence words and cross-modal relationships for image and sentence matching. To achieve robust cross-modal matching, the authors propose a novel cross-attention module that can leverage both intra-modal relationships within each modality and cross-modal relationships between image regions and sentence words, complementing and enhancing image and sentence matching.
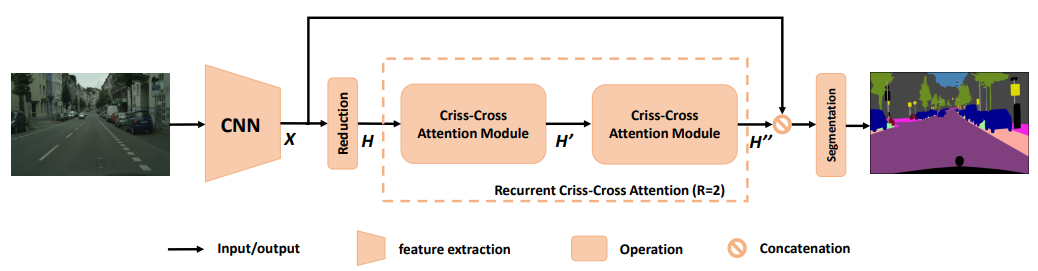
6. CCNet: Criss-Cross Attention for Semantic Segmentation
Method: This paper presents a Criss-Cross network (CCNet) designed to efficiently and effectively capture contextual information from the entire image. Specifically, for each pixel, a novel cross-attention module gathers contextual information from all pixels along its criss-cross path. Through further iterative operations, each pixel ultimately captures dependencies across the entire image. Additionally, a category consistency loss is proposed to enforce the cross-attention module to produce more distinguishable features.
Innovations:
-
Innovative Criss-Cross Attention module: By employing a novel Criss-Cross Attention module on each pixel, it can gather contextual information from all pixels along its criss-cross path. Through further iterative operations, each pixel ultimately captures dependencies across the entire image. -
Category consistency loss introduced: To ensure that the Criss-Cross Attention module produces more distinguishable features, the authors propose a category consistency loss. This loss function maps each pixel in the image to an n-dimensional vector in the feature space, bringing feature vectors of pixels belonging to the same category closer together while keeping those of different categories farther apart.
Scan to add Xiao Xiang, reply “Cross Attention”
Getallpapers + module code for free
