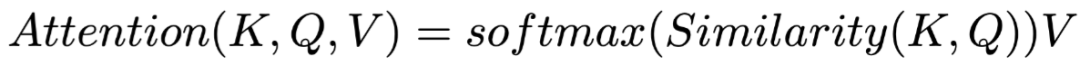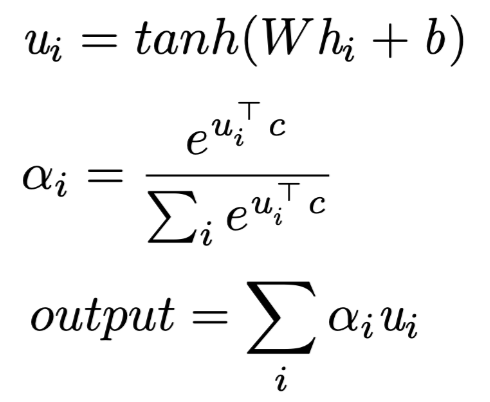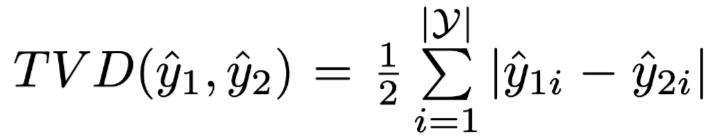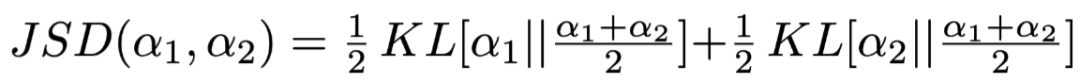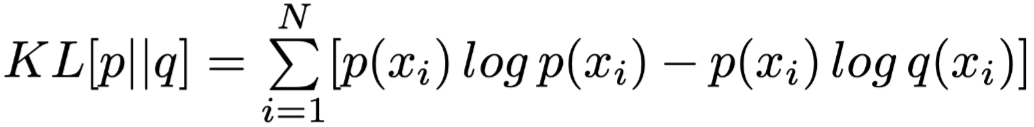Click the “MLNLP” above to select the “Star” public account
Heavy-duty content delivered promptly

Author: Gu Yuxuan, Harbin Institute of Technology SCIR
References
NAACL 2019 “Attention is Not Explanation”
ACL 2019 “Is Attention Interpretable?”
EMNLP 2019 “Attention is Not Not Explanation”
This article will explore the interpretability of the attention mechanism.
Introduction
Since Bahdanau introduced Attention as soft alignment in neural machine translation in 2014, a large amount of natural language processing work has utilized it as an important module for improving performance. Numerous experiments have shown that the Attention mechanism is computationally efficient and effective. This has led to discussions and research on its interpretability, as people hope to better understand its internal mechanisms to optimize models. On the other hand, some scholars have raised questions about it. As a prospective doctoral student in the SCIR laboratory, I have written this paper based on my understanding of the Attention mechanism, hoping to inspire readers. Due to my personal limitations, any errors in the text are welcome to be pointed out.
1 Attention Mechanism
1.1 Background
The Attention mechanism is currently one of the most commonly used methods in the field of natural language processing, as it can significantly improve model performance across a range of tasks, especially in sequence-to-sequence models based on recurrent neural networks. Coupled with Google’s fully Attention-based Transformer model[1] and the extensive use of the Bert model[2], the Attention mechanism is practically a textbook technology. On one hand, Attention intuitively simulates how humans focus on certain keywords while understanding language, as Bahdanau[3] introduced it as soft alignment in neural machine translation. On the other hand, numerous experiments over the years have shown that Attention is indeed a feasible and efficient method for enhancing model performance. Therefore, further exploration of the underlying principles of this mechanism, explaining its effectiveness, and providing evidence is a valuable research direction.
1.2 Structure
Despite the different implementation methods in various papers, the Attention mechanism generally adheres to the same paradigm. It consists of three components:
-
Key corresponds to Value and is also used to compute similarity with Query as the basis for selecting Attention.
-
Query is the query during a single execution of Attention.
-
Value is the data that is attended to and selected.
The corresponding formula is as follows:
Where Value is often the output of the previous layer, generally remains unchanged, while other components such as Key, Query, and similarity functions often have different implementation methods. Here we first introduce the Attention structure implemented by Bahdanau[3] and Yang[7], as subsequent explorations of interpretability by Serrano[4] and Jain[5] are also based on this.
The formula for Attention is as follows:
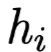 (as Value) is the output tensor at the i-th position of the previous layer; if the previous layer is a bidirectional RNN structure, then
(as Value) is the output tensor at the i-th position of the previous layer; if the previous layer is a bidirectional RNN structure, then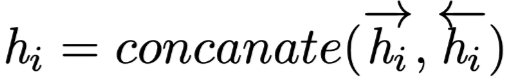 ;
; 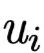 is the Key at the i-th position, computed from the Value through a fully connected layer;
is the Key at the i-th position, computed from the Value through a fully connected layer; 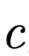 is the Query of this Attention layer, initialized randomly, synchronized during training; if Attention is not a separate layer but built on the decoder, then
is the Query of this Attention layer, initialized randomly, synchronized during training; if Attention is not a separate layer but built on the decoder, then 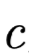 is related to the output at the corresponding position during the encoding phase; the similarity function is matrix dot product, and the computed
is related to the output at the corresponding position during the encoding phase; the similarity function is matrix dot product, and the computed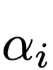 is the Attention weight, and
is the Attention weight, and  is the output of the Attention layer.
The core idea is as follows:
is the output of the Attention layer.
The core idea is as follows:
-
Calculate a non-negative normalized weight for each input element.
-
Multiply these weights by the corresponding component representations.
-
Sum the results to produce a fixed-length representation.
This is the most original form of Attention, and experiments testing its interpretability are based on this model.
2 Definition of Interpretability
There are various definitions of interpretability, and most related articles often derive differences from here, leading to different conclusions. However, there is some consensus that can be summarized.
The conceptual consensus on interpretability can be described as follows: If a model is interpretable, it means that humans can understand this model, which can be divided into two aspects: one is that the model is transparent to humans[9], and corresponding parameters and model decisions can be predicted before training on specific tasks; the second is that after the model makes a decision, humans can understand the reasons behind that decision. There are also other definitions from different angles, such as: interpretability means that the decision-making process of the model can be reconstructed manually.
Specifically for the interpretability of the Attention model, it can generally be refined to:
-
The height of Attention weights should be positively correlated with the importance of the corresponding positional information.
-
High-weight input units have a decisive influence on the output results.
3 Specific Arguments
3.1 Not Explanation
Regarding non-interpretability, Serrano[4] and Jain[5] each proposed some experiments and arguments; their work overlaps and complements each other. The former’s work explores a shallow level, only considering whether the weights of the Attention layer are positively correlated with the corresponding position inputs, using intermediate representation erasure, that is, continuously nullifying some weights to observe changes in the model. The article mainly explores different erasure methods, while the latter’s work is somewhat deeper, exploring not only the impact of removing key weights on the model but also introducing the idea of constructing adversarial Attention weights to test changes in the model.
3.1.1 Intermediate Representation Erasure
Intermediate representation erasure considers a relatively shallow understanding of Attention, where the main logic is that the more important the weight, the greater its impact on the output result; setting it to zero will directly affect the result.
First, introduce evaluation metrics, that is, how much the weights and output results change:
-
Total Variance Distance (TVD) as an indicator of the difference in output result distribution, the formula is as follows:
Where
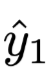 and
and 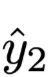 are two different output result distributions.
are two different output result distributions.
-
Jensen-Shannon Divergence (JSD) as an indicator of the difference between output result distribution and Attention weights, the formula is as follows:
Where
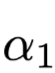 and
and 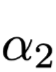 are two different distributions, which can be either output results or Attention weights,
is the Kullback-Leibler Divergence.
are two different distributions, which can be either output results or Attention weights,
is the Kullback-Leibler Divergence.
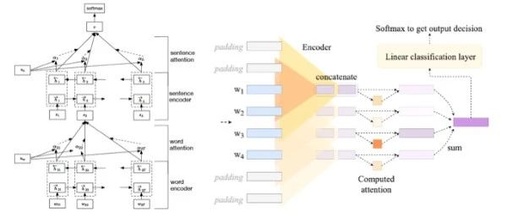
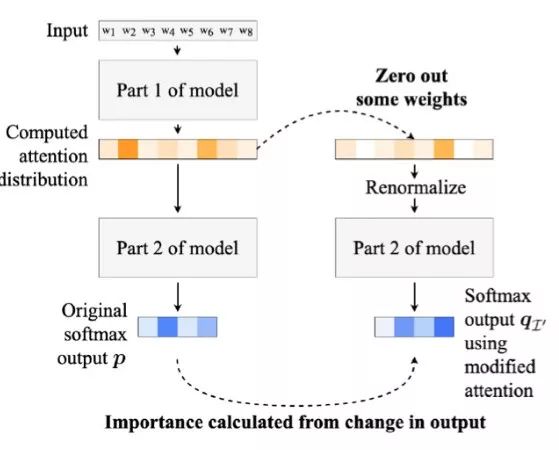
The specific implementation method is shown in Figure 1, where the model is divided into two parts: the first part is the embedding and encoding part, for example, a fully connected layer implements word embedding followed by a bidirectional LSTM layer for encoding; the specific models used in the experiment vary.The second part is the decoding part, which decodes the output tensor obtained from the Attention layer into the results required for specific tasks. In text classification tasks, this is a dimensional transformation implemented by a fully connected layer.It is important to note that the Attention layer here does not act on the decoder like in seq-to-seq models, but is tested as an independent layer.
Figure 1. Overall model of intermediate representation erasure
The entire model runs twice: the first time with normal input-output, retaining the results obtained; the second time, the selected weights on the Attention layer are set to 0, re-normalizing the weights with Softmax, and continuing the subsequent process to obtain results, calculating the TVD metric with the data obtained from the first run.The erasure on the Attention layer rather than at the input end is to isolate its impact from the preceding encoding part.Additionally, the purpose of renormalizing is that when the model sets some high-weight parameters to zero, it causes the output tensor of the Attention layer to approach 0, which is a situation the model has not encountered during training, leading to uncontrollable decision-making behavior.
Serrano[4] designed experiments using a text classification task, employing four datasets, as shown in Figure 2, and also designed four models for comparative testing:
Figure 2. Four text classification datasets
-
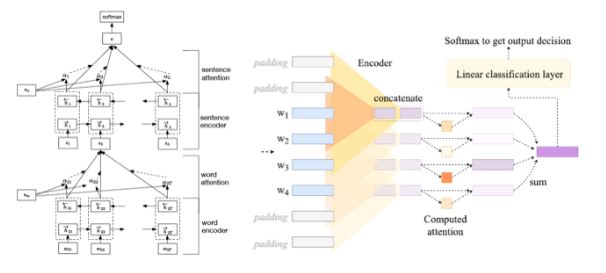
Hierarchical Attention Network proposed by Yang[7], as shown on the left side of Figure 3, consists of two parts: word-level and sentence-level, where the experiment only tests the sentence-level Attention layer, treating the previous part as the encoding phase.
-
Flat Attention Network is modified from the previous model, having only a word-level Attention layer operating on the entire document without distinguishing sentences.
-
Flat Attention Network with CNN replaces the bidirectional RNN structure used as the encoder in the previous model with CNN, as shown on the right side of Figure 3, referencing Kim[8]’s implementation.
-
No Encoder does not use an encoder, directly inputting the results after word embedding into the Attention layer.This control group aims to eliminate the encoder to prevent individual tokens from gaining contextual information.
Figure 3. Two Hierarchical Attention Network structures using BiRNN and CNN as encoding parts
The experiments mainly consist of two modules: single weight nullification and a group of weights nullification, where the former tests the change in the overall model output results after erasing the highest-weight corresponding intermediate representation, while the latter tests how much intermediate representation needs to be erased to change the model’s final decision and how to erase it, thereby finding evidence for interpretability from the experimental data.
Single Attention Weight’s Importance first nullifies the highest-weight intermediate representation, calculating the normal result and the result after erasure using the process shown in Figure 1, calculating the JSD metric.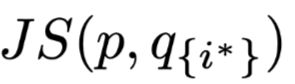 Where
Where 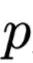 is the distribution of the normal result,
is the distribution of the normal result, 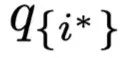 is the result distribution after erasing the highest-weight corresponding position,
is the result distribution after erasing the highest-weight corresponding position,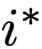 is the intermediate representation after erasing, and to verify how much distance there is, a random position
is the intermediate representation after erasing, and to verify how much distance there is, a random position 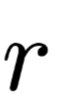 is randomly selected, using the same process to erase the intermediate representation and obtain the corresponding JSD metric
is randomly selected, using the same process to erase the intermediate representation and obtain the corresponding JSD metric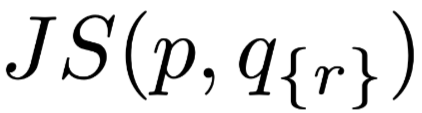 and we can use
and we can use 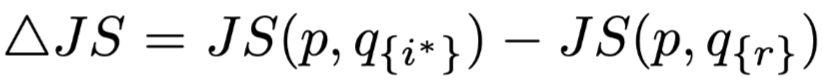 for comparison. Intuitively, if the items with high weights are indeed more important, then this formula should always be positive, and the difference in size between the two nullified weights
for comparison. Intuitively, if the items with high weights are indeed more important, then this formula should always be positive, and the difference in size between the two nullified weights 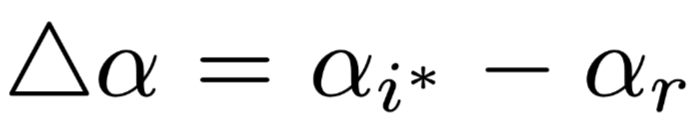 should be larger, and the value of
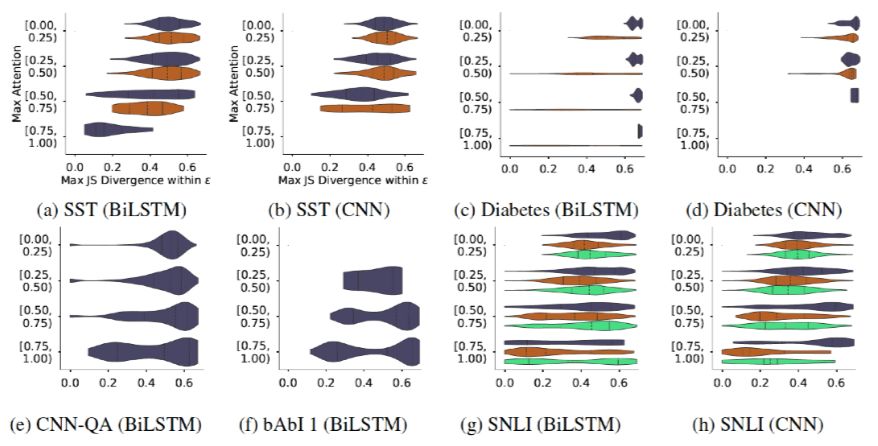
should be larger, and the value of 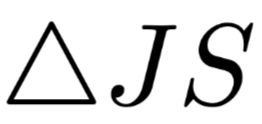 should also be larger.The author presents charts in the text as shown in Figure 4 on the left, where the x-axis is the difference between the two weights and the y-axis is the value of
should also be larger.The author presents charts in the text as shown in Figure 4 on the left, where the x-axis is the difference between the two weights and the y-axis is the value of 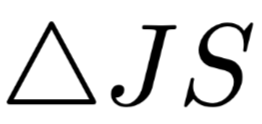 The author states that the data obtained shows almost no negative results, and even if there are, they are close to 0. Furthermore, as the difference between the two weights increases, the degree of change in the model output distribution also increases accordingly, but the author believes that “even if the difference between the two weights reaches 0.4 (the weights satisfy normalization), most positive
The author states that the data obtained shows almost no negative results, and even if there are, they are close to 0. Furthermore, as the difference between the two weights increases, the degree of change in the model output distribution also increases accordingly, but the author believes that “even if the difference between the two weights reaches 0.4 (the weights satisfy normalization), most positive 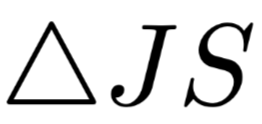 values are still very close to 0,” thus preliminarily concluding that the Attention mechanism has phenomena contrary to intuition.
However, results from the appendix of the article can find results from non-hierarchical models without encoding layers as shown on the right side of Figure 4, indicating that the issue of degree of change being unrelated is not as serious as it seems. In other words, under this set of data, the author’s conclusion is not rigorous. The article proposes a hypothesis that when the encoding layer encodes each position’s token, it contains contextual information, meaning that the amount of information has undergone a similar distribution operation. Thus, the influence of Attention layer weights is weakened. Of course, the article does not conduct experiments to verify this hypothesis.
Figure 4. Comparison of results based on hierarchical models using BiRNN and non-hierarchical models without encoding layers
Subsequently, Serrano[4] designed a set of experiments to strengthen the exploration of the impact of single nullification operations, using the evaluation metric of the probability of model decision reversal, that is, erasing the highest-weight corresponding position
values are still very close to 0,” thus preliminarily concluding that the Attention mechanism has phenomena contrary to intuition.
However, results from the appendix of the article can find results from non-hierarchical models without encoding layers as shown on the right side of Figure 4, indicating that the issue of degree of change being unrelated is not as serious as it seems. In other words, under this set of data, the author’s conclusion is not rigorous. The article proposes a hypothesis that when the encoding layer encodes each position’s token, it contains contextual information, meaning that the amount of information has undergone a similar distribution operation. Thus, the influence of Attention layer weights is weakened. Of course, the article does not conduct experiments to verify this hypothesis.
Figure 4. Comparison of results based on hierarchical models using BiRNN and non-hierarchical models without encoding layers
Subsequently, Serrano[4] designed a set of experiments to strengthen the exploration of the impact of single nullification operations, using the evaluation metric of the probability of model decision reversal, that is, erasing the highest-weight corresponding position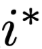 and the randomly selected position
and the randomly selected position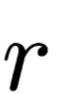 after which the model decision behavior reversal situation was observed. The experimental data is shown in Figure 5, where the orange area indicates the reversal caused by r, while the blue area indicates the opposite. However, in most cases, model decisions do not reverse, indicating that this experiment is not very useful, or further, simply nullifying an intermediate representation does not affect the robustness of the Attention layer, especially when a contextually related encoder is present.
Figure 5. Model decision reversal situations
Jain[5] also designed a set of leave-one-out experiments, using a model framework similar to Serrano[4], but with an increased dataset.Involving text classification, question answering, and natural language inference tasks, the datasets are shown in Figure 6, where text classification tasks were modified into binary classification tasks to simplify the model requirements.
Figure 6. Text classification, question answering, and natural language inference datasets
Jain[5] believes that the Attention weights learned by the model should align with the importance evaluation indicators of feature representations, comparing two evaluation indicators: the model output results after removing different position intermediate representations and the original output results, and a set of TVD values obtained from gradient backpropagation for each position. The former’s rationale is that if an important intermediate representation is removed, the change in the model decision result will be significant, thus corresponding to a large TVD value; the latter relates the gradient values to the model’s decision focus.Both indicators are compared with Attention weights to calculate JSD, obtaining corresponding distributions as shown in Figure 7, where only the data for the gradient indicator is displayed. Here, JSD is converted into correlation, where 0 indicates no correlation and 1 indicates complete consistency. The data for the other indicator is similar and will not be elaborated further. Generally speaking, simply erasing an intermediate representation cannot serve as a strong argument to prove whether Attention is interpretable.
after which the model decision behavior reversal situation was observed. The experimental data is shown in Figure 5, where the orange area indicates the reversal caused by r, while the blue area indicates the opposite. However, in most cases, model decisions do not reverse, indicating that this experiment is not very useful, or further, simply nullifying an intermediate representation does not affect the robustness of the Attention layer, especially when a contextually related encoder is present.
Figure 5. Model decision reversal situations
Jain[5] also designed a set of leave-one-out experiments, using a model framework similar to Serrano[4], but with an increased dataset.Involving text classification, question answering, and natural language inference tasks, the datasets are shown in Figure 6, where text classification tasks were modified into binary classification tasks to simplify the model requirements.
Figure 6. Text classification, question answering, and natural language inference datasets
Jain[5] believes that the Attention weights learned by the model should align with the importance evaluation indicators of feature representations, comparing two evaluation indicators: the model output results after removing different position intermediate representations and the original output results, and a set of TVD values obtained from gradient backpropagation for each position. The former’s rationale is that if an important intermediate representation is removed, the change in the model decision result will be significant, thus corresponding to a large TVD value; the latter relates the gradient values to the model’s decision focus.Both indicators are compared with Attention weights to calculate JSD, obtaining corresponding distributions as shown in Figure 7, where only the data for the gradient indicator is displayed. Here, JSD is converted into correlation, where 0 indicates no correlation and 1 indicates complete consistency. The data for the other indicator is similar and will not be elaborated further. Generally speaking, simply erasing an intermediate representation cannot serve as a strong argument to prove whether Attention is interpretable.
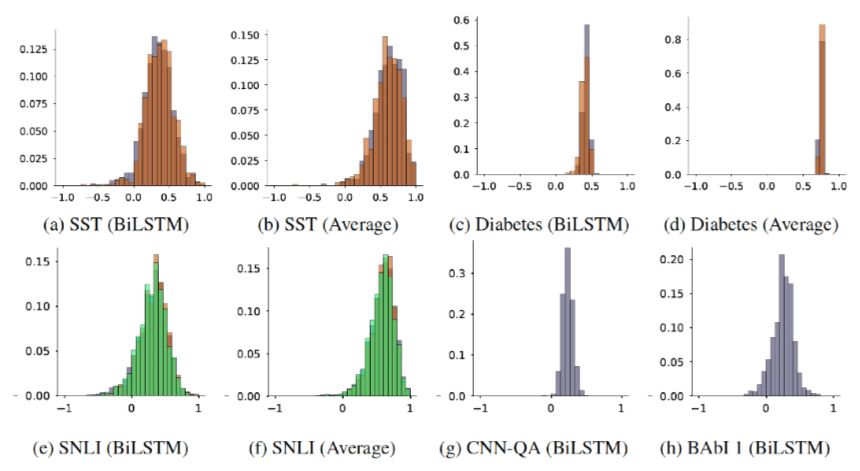 Figure 7. Correlation between Attention distribution and gradient distribution
The idea of Importance is to find a minimal set of intermediate representations that can flip the model’s decision. If the Attention weights for the corresponding positions of this set are the largest, it indicates that the ranking of Attention weights regarding the importance of intermediate representations is reasonable.The author proposed the following process for verification:
Figure 7. Correlation between Attention distribution and gradient distribution
The idea of Importance is to find a minimal set of intermediate representations that can flip the model’s decision. If the Attention weights for the corresponding positions of this set are the largest, it indicates that the ranking of Attention weights regarding the importance of intermediate representations is reasonable.The author proposed the following process for verification:
-
Add Attention weights to the zeroing set in descending order.
-
If the model’s decision flips, stop expanding the set.
-
Check if there is a true subset that can also flip the model’s decision.
However, the problem here is that finding such a true subset requires exponential time complexity, which is nearly unachievable, and the requirements must be relaxed to find an arbitrary smaller set.The author designed three additional sorting schemes to see if they can use fewer elements than the Attention weight sorting scheme to flip the model’s decision.The three sorting schemes are as follows:
-
-
Sorting by the size of the gradient values backpropagated to the Attention layer
-
Sorting by the product of gradient values and Attention weights
These three candidate sortings are not intended to find a golden-standard erasure combination but to compare with the ranking formed by Attention weights.In addition, some data items need to be discarded to prevent experimental effects, such as in some cases, even erasing down to only one intermediate representation, the model’s decision does not flip; or the input sequence length is 1, making sorting impossible.
Figure 8. Proportion of Attention weights set to zero to flip model decisions under different sorting rules
The conclusion drawn by the author is that Attention does not necessarily maximize the description of the model’s decision behavior, and using Attention weights as a basis is effective but not optimal.However, the problem here is that the correlation between nullifying Attention weights and flipping model decisions is merely an intuitive assumption, not a strong prior or axiom.
3.1.2 Constructing Adversarial Weights
Jain[5] believes that changes in Attention weights should have corresponding effects on the model’s predictions. This idea is similar to the reversal of model decisions, but the difference is that here the goal is to construct a set of counterintuitive weight distributions to deceive the model into making the same decision, thereby proving that the Attention mechanism is unreliable.
The adversarial effect the author aims to construct is shown in Figure 9, displaying an example of a negative review, where the left side shows the original weights learned by the model, with the maximum weight corresponding to the word waste, followed by asking, resulting in a classifier output of 0.01 (0 indicating negative, 1 indicating positive, 0.5 indicating neutral). This aligns with human judgment when assessing the sentiment polarity of the sentence.On the right side is the constructed adversarial weight, where the maximum weight corresponds to the word was, followed by myself, yet this counterintuitive Attention method can still yield the same result from the classifier.
Figure 9. Example of text sentiment analysis
The author designs two methods to conduct experiments.The first method is to simply randomize the positions of the original Attention weights, while the second method designs a target function to train adversarial weights that yield a similar model output distribution while having as different Attention weight distributions as possible.
Attention Permutation randomizes Attention weights, observing changes in the model output results and evaluating the degree of change using the TVD metric.Due to randomness and computational complexity constraints, each sample experiment only randomly generates 100 sets of weights, calculating the TVD metric and taking the median for evaluation.Figure 10 shows a heatmap where the x-axis is the median of model output change degrees, and the y-axis is the maximum of the original Attention weights, with different colors representing different categories. The author aims to verify whether a small number of features can explain an output result by classifying according to the range of maximum Attention weights.The author uses the SST dataset as a standard, concluding that randomizing Attention does not significantly impact the model’s output results.However, this conclusion should be debated, as the author attributes the inconsistency in experimental results solely to the dataset. For instance, in the Diabetes dataset, only a few key features can decisively influence the result, and choosing a dataset that aligns with one’s expectations while exhibiting different or even completely opposite results across multiple datasets is biased, especially when concluding without thorough research and experimentation.
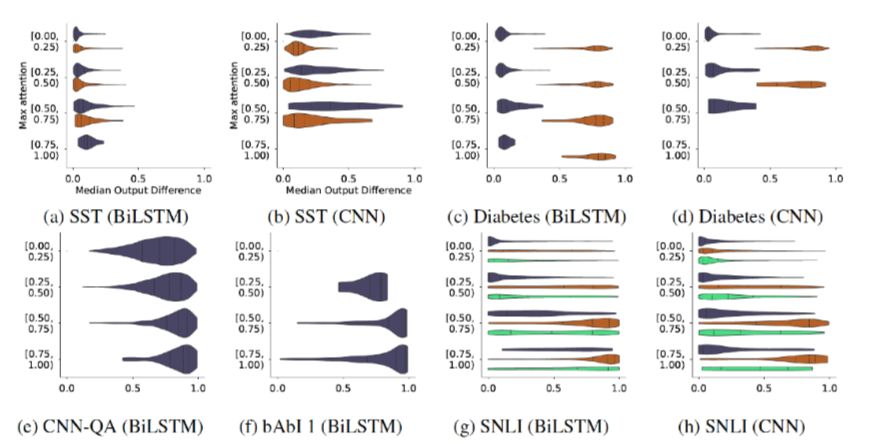 Figure 10. Changes in model output results after randomizing weights
Adversarial Attention is the author’s primary focus, constructing a method for generating adversarial weights, aiming to explicitly find a weight distribution that is as different from the original Attention weights as possible while effectively ensuring that the model’s prediction results remain unchanged.The mathematical expression of the construction method is as follows:
Figure 10. Changes in model output results after randomizing weights
Adversarial Attention is the author’s primary focus, constructing a method for generating adversarial weights, aiming to explicitly find a weight distribution that is as different from the original Attention weights as possible while effectively ensuring that the model’s prediction results remain unchanged.The mathematical expression of the construction method is as follows:
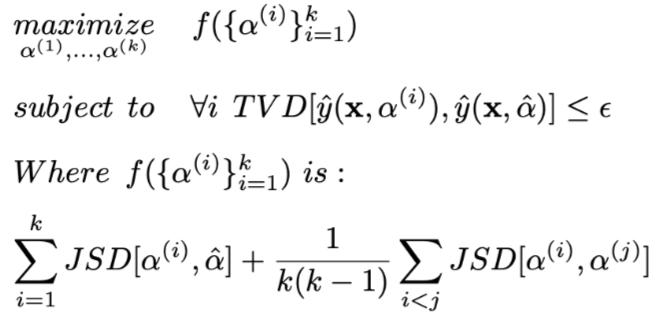 Where
Where  represents a defined small, which is the maximum distance of Tvd between the model’s decision using the constructed weights and the result obtained using the original weights,
represents a defined small, which is the maximum distance of Tvd between the model’s decision using the constructed weights and the result obtained using the original weights, in sentiment classification tasks is 0.01, while in question answering tasks it is 0.05 (because the output vector space for question answering tasks is larger, a smaller perturbation can cause a larger TVD distance).
in sentiment classification tasks is 0.01, while in question answering tasks it is 0.05 (because the output vector space for question answering tasks is larger, a smaller perturbation can cause a larger TVD distance). represents the original Attention weights, and
represents the original Attention weights, and  is the model result obtained using the original weights.
is the model result obtained using the original weights. represents the i-th group of constructed weight distributions, and
represents the i-th group of constructed weight distributions, and  is the model result obtained using the i-th group of constructed weights.The optimization goal is to obtain the Attention weights generated by the i-th group, maximizing the JS distance between each group of weights and the original weights while ensuring that the Tvd distance between the results produced by each group of weights and the original results does not exceed
is the model result obtained using the i-th group of constructed weights.The optimization goal is to obtain the Attention weights generated by the i-th group, maximizing the JS distance between each group of weights and the original weights while ensuring that the Tvd distance between the results produced by each group of weights and the original results does not exceed  The specific implementation of the optimization goal is
The specific implementation of the optimization goal is 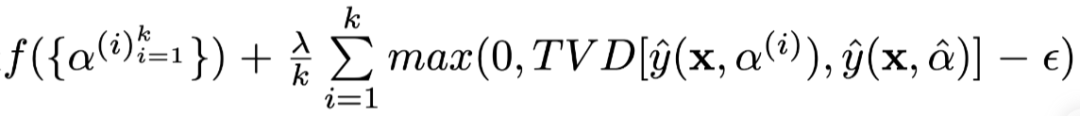 , where λ is a hyperparameter set to 500 during training.
, where λ is a hyperparameter set to 500 during training.
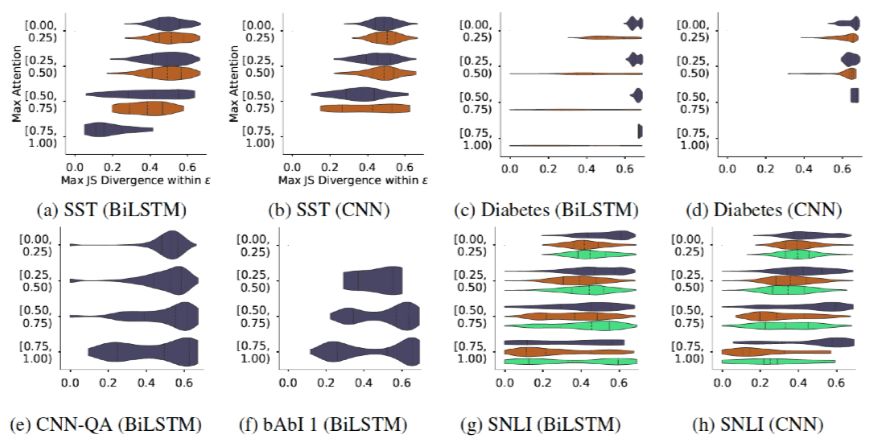 Figure 11 shows the maximum JS distance between the constructed weight distributions and the original weight distributions across various datasets, where the y-axis represents the corresponding quantity ratio. Since the experiments only selected a portion of samples from the datasets, the sum of each bar in the histogram may not equal 1.The colors are also used to distinguish different classification results.Notably, the JSD indicator itself has an upper bound; the maximum JSD between two completely different distributions can reach 0.69. The data indicates that for each dataset, a large number of distributions can be constructed that are close to the upper limit of the original Attention weight distribution while maintaining the model output results’ change degree within
Figure 11 shows the maximum JS distance between the constructed weight distributions and the original weight distributions across various datasets, where the y-axis represents the corresponding quantity ratio. Since the experiments only selected a portion of samples from the datasets, the sum of each bar in the histogram may not equal 1.The colors are also used to distinguish different classification results.Notably, the JSD indicator itself has an upper bound; the maximum JSD between two completely different distributions can reach 0.69. The data indicates that for each dataset, a large number of distributions can be constructed that are close to the upper limit of the original Attention weight distribution while maintaining the model output results’ change degree within  . This indicates that Attention weights can easily be constructed to be completely counterintuitive without affecting results, which the author believes is key evidence proving that the Attention mechanism is not interpretable.
. This indicates that Attention weights can easily be constructed to be completely counterintuitive without affecting results, which the author believes is key evidence proving that the Attention mechanism is not interpretable.
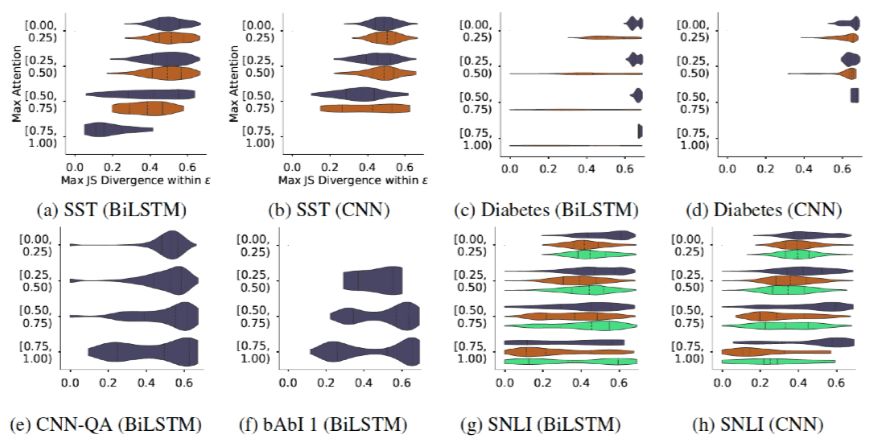 Figure 11. Histogram of JS distance distribution under constraints
The author continues to consider the relationship between the maximum Attention weight value (to consider the impact of effective feature degree, i.e., the larger the maximum weight, the more the model focuses on certain features) and the maximum JS distance of the adversarial weights that can be constructed. Intuitively, if the original Attention weight distribution is steeper, it becomes more difficult to generate effective (large JSD value) adversarial weights. As shown in Figure 12, this is also a heatmap, where the x-axis is the maximum JS distance, and the y-axis is the maximum original Attention weight. The author believes that although there is indeed a trend as previously mentioned, it is undeniable that in each dataset, there exist many examples where high original Attention weights still allow for the construction of adversarial weights with a large JS distance, meaning that the assertion that a specific set of features can completely influence the result is misleading.
Figure 11. Histogram of JS distance distribution under constraints
The author continues to consider the relationship between the maximum Attention weight value (to consider the impact of effective feature degree, i.e., the larger the maximum weight, the more the model focuses on certain features) and the maximum JS distance of the adversarial weights that can be constructed. Intuitively, if the original Attention weight distribution is steeper, it becomes more difficult to generate effective (large JSD value) adversarial weights. As shown in Figure 12, this is also a heatmap, where the x-axis is the maximum JS distance, and the y-axis is the maximum original Attention weight. The author believes that although there is indeed a trend as previously mentioned, it is undeniable that in each dataset, there exist many examples where high original Attention weights still allow for the construction of adversarial weights with a large JS distance, meaning that the assertion that a specific set of features can completely influence the result is misleading.
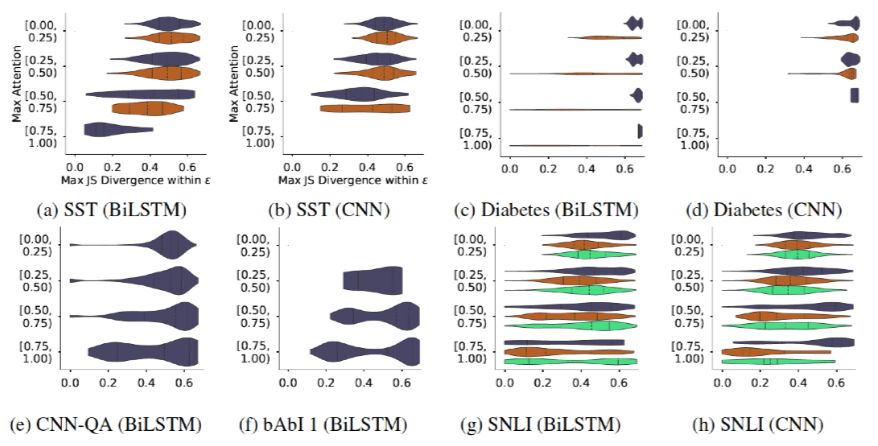 Figure 12. Relationship between JS distance and maximum original Attention weight distribution
To summarize the above conclusions, Serrano[4] designed multiple experiments around intermediate representation erasure to observe changes in model decisions, concluding that: ‘Attention does not necessarily correspond to importance.‘ because Attention often fails to successfully identify the most important intermediate representations that can affect model decisions. Additionally, there is a significant but unverified hypothesis: ‘Attention magnitudes do seem more helpful in uncontextualized cases.‘ suggesting that contextual encoders may hinder the interpretability of the Attention mechanism, but the author did not conduct in-depth research on this.
Jain[5] raised two questions based on the contribution of Attention to the model’s transparency[9]:
Figure 12. Relationship between JS distance and maximum original Attention weight distribution
To summarize the above conclusions, Serrano[4] designed multiple experiments around intermediate representation erasure to observe changes in model decisions, concluding that: ‘Attention does not necessarily correspond to importance.‘ because Attention often fails to successfully identify the most important intermediate representations that can affect model decisions. Additionally, there is a significant but unverified hypothesis: ‘Attention magnitudes do seem more helpful in uncontextualized cases.‘ suggesting that contextual encoders may hinder the interpretability of the Attention mechanism, but the author did not conduct in-depth research on this.
Jain[5] raised two questions based on the contribution of Attention to the model’s transparency[9]:
-
How closely do Attention weights correlate with feature importance indicators?
-
Do different weight distributions necessarily lead to different model decisions?
The answers provided are as follows:
-
‘Only weakly and inconsistently‘, the correlation between Attention weights and feature importance indicators (gradient distributions, TVD distributions after removing certain intermediate representations) is not significant and unstable.
-
‘It is very possible to construct adversarial attention distributions that yield effectively equivalent predictions.‘ It is easy to construct adversarial weights that focus on features completely different from the original weights, and furthermore, randomizing weights often does not significantly affect model decision results.
3.2 Not Not Explanation
This section titled Not Not Explanation is a rebuttal to previous arguments about the non-interpretability of the Attention mechanism, rather than proving that Attention is interpretable. Here, the author mainly references Wiegreffe[6]’s rebuttal to Jain[5].Wiegreffe[6] provides two main reasons:
-
Attention Distribution is not a Primitive. The distribution of Attention weights does not exist independently; due to the entire process of forward and backward propagation, the parameters of the Attention layer cannot be isolated from the entire model, otherwise, it loses practical significance.
-
Existence does not Entail Exclusivity. The existence of Attention distributions does not imply exclusivity; Attention merely provides one explanation rather than the only explanation.Especially when the dimensions of intermediate representations are large and the output result categories are few, the dimensionality reduction mapping function can easily exhibit considerable flexibility.
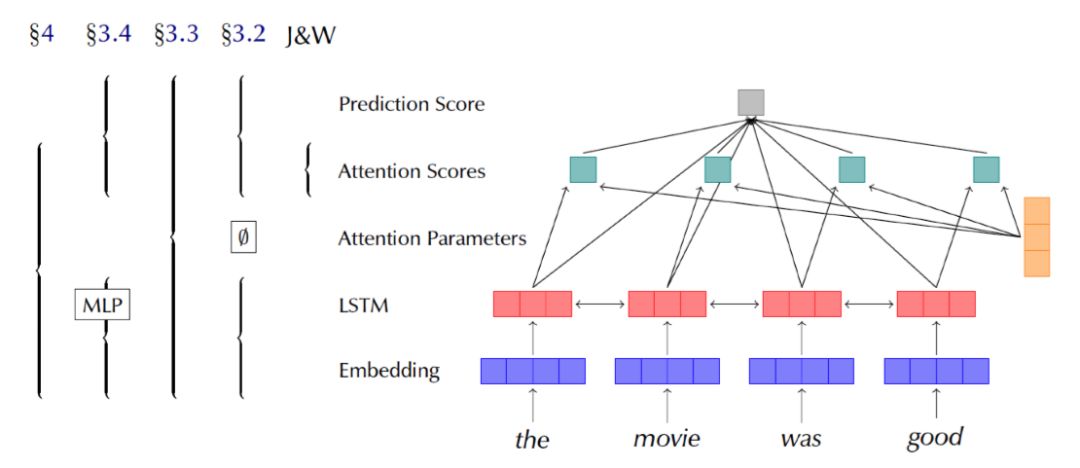
The author designed four sets of control experiments for rebuttal, referring to Figure 13, where the right side shows the models used, consistent with those previously introduced, all having embedding layers, encoding layers, and independent Attention layers, with the task also being text classification.The left side corresponds to the scope of each experiment, J&W refers to Jain[5]’s experiment, which only involves modifying Attention weights. It is important to note that in the figure, Attention Parameters refers to the parameters trained in the Attention layer, and the final α weights are calculated from them.§3.2 is the experiment designed by Wiegreffe[6] in section 3.2 of his paper, with curly brackets indicating the layers involved in each experiment, from right to left, the four experiments are:
-
Uniform as Adversary training a baseline model with fixed Attention weights set to the average.
-
Variance with a Model re-initializing and training the model with a random seed to serve as a normal baseline for the deviation of Attention weight distributions.
-
Diagnosing Attention Distribution by Guiding Simpler Models implementing a diagnostic framework using fixed pre-trained Attention weights.
-
Training an Adversary designing an end-to-end adversarial weight training method, noting that this is not an independent experiment but a specific implementation of the adversarial weight generation from the previous experiment.
Figure 13. Results of the models used and the control experiment section
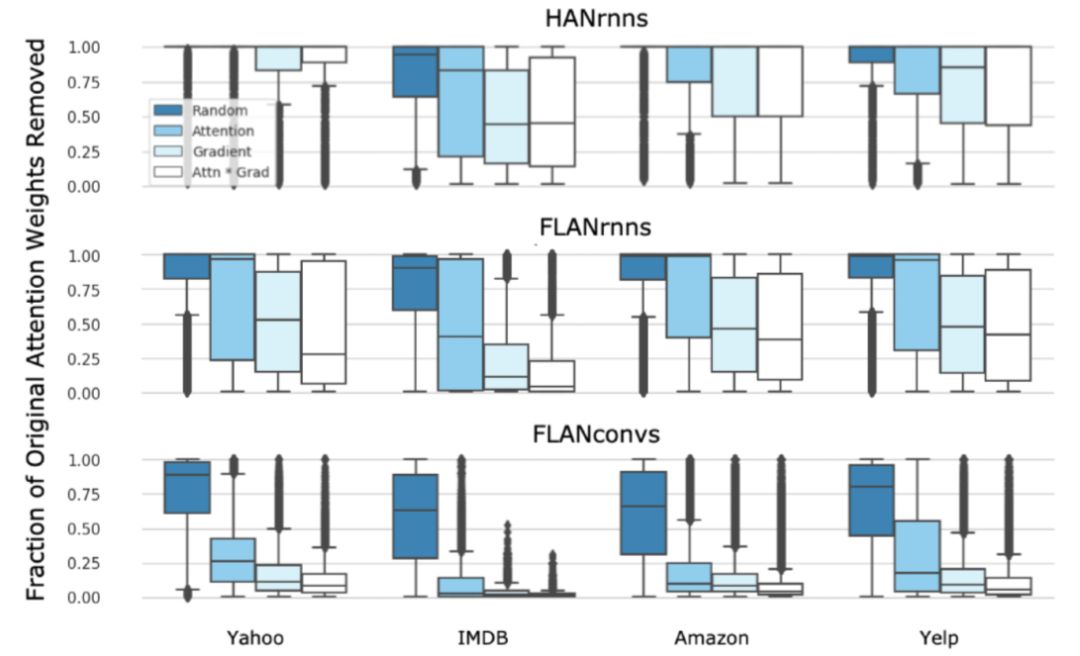
Uniform as Adversary aims to verify whether the Attention mechanism is necessary across datasets, as if the task is too simple and does not require Attention for good performance, then this dataset lacks persuasiveness.Conversely, if Attention is necessary, removing it will lead to a significant decline in model performance.The experimental design is simple: directly set Attention weights to the average and freeze them, training only the other parts, where all intermediate representations passed from the encoding layer are directly computed as the output of the Attention layer.The F1 metric for text classification obtained is shown in Figure 14, where the leftmost is the result given by Jain[5], the middle is the result replicated by Wiegreffe[6], and the rightmost is the result obtained from this experiment. Visually, it can be seen that the performance improvement in most datasets after using Attention is not significant, especially in the last two datasets, where there is almost no growth. The author summarizes this as ‘Attention is not explanation if you don’t need it.’
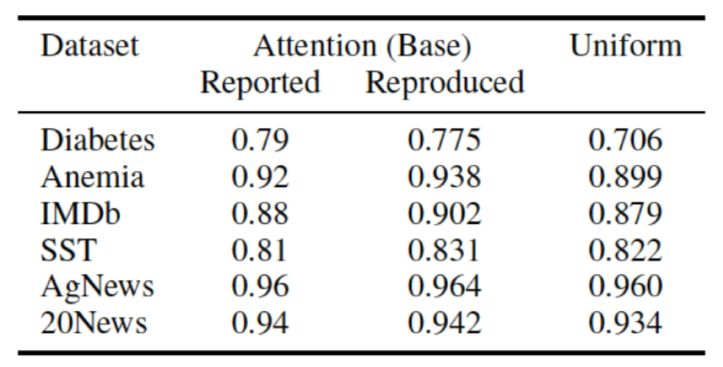 Figure 14. F1 metrics for text classification tasks
Variance with a Model The author uses a random seed to reinitialize and train the model, obtaining different Attention weights viewed as normal weights, which are merely disturbed by noise rather than artificially intervened non-adversarial weights. Comparing the JSD metric between these weights and the original weights yields a normal baseline, with weights exceeding this baseline being deemed abnormal.Figure 15 shows a comparative graph where the x-axis is the JS distance, and the y-axis is the maximum range of Attention weights. This is a set of comparison graphs, from a to d representing the baseline generated using random seeds across various datasets, while e and f are the experimental data from Jain[5]’s adversarial weights. It can be observed that the generated weights on the SST dataset have a JSD distance from the original weights that far exceeds the baseline.This indicates that artificially constructed adversarial data is indeed abnormal, far exceeding the degree of noise. This result aligns with the previous experiment’s phenomenon, indicating that the lesser the role of Attention, the less predictable its weight distribution; however, up to this point, this remains a theoretical discussion without precise data explaining the situation of the constructed Attention weights.
Figure 14. F1 metrics for text classification tasks
Variance with a Model The author uses a random seed to reinitialize and train the model, obtaining different Attention weights viewed as normal weights, which are merely disturbed by noise rather than artificially intervened non-adversarial weights. Comparing the JSD metric between these weights and the original weights yields a normal baseline, with weights exceeding this baseline being deemed abnormal.Figure 15 shows a comparative graph where the x-axis is the JS distance, and the y-axis is the maximum range of Attention weights. This is a set of comparison graphs, from a to d representing the baseline generated using random seeds across various datasets, while e and f are the experimental data from Jain[5]’s adversarial weights. It can be observed that the generated weights on the SST dataset have a JSD distance from the original weights that far exceeds the baseline.This indicates that artificially constructed adversarial data is indeed abnormal, far exceeding the degree of noise. This result aligns with the previous experiment’s phenomenon, indicating that the lesser the role of Attention, the less predictable its weight distribution; however, up to this point, this remains a theoretical discussion without precise data explaining the situation of the constructed Attention weights.
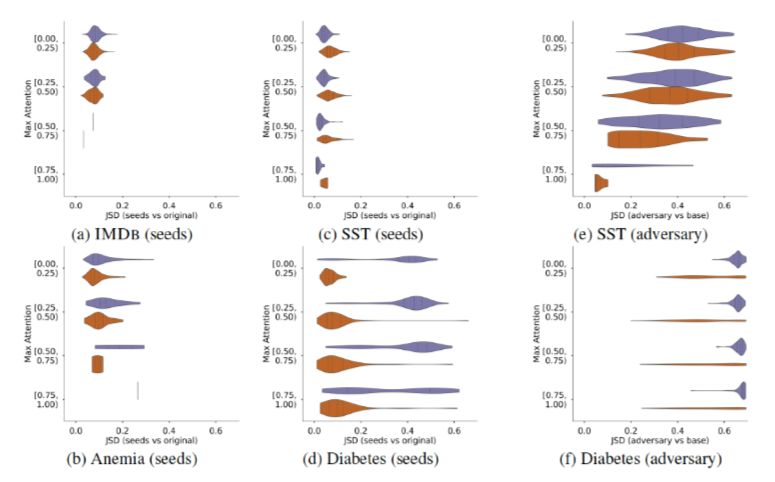 Figure 15. Comparison of weight distributions based on random seed initialization and adversarial weight distributions against the original distribution’s JS distance
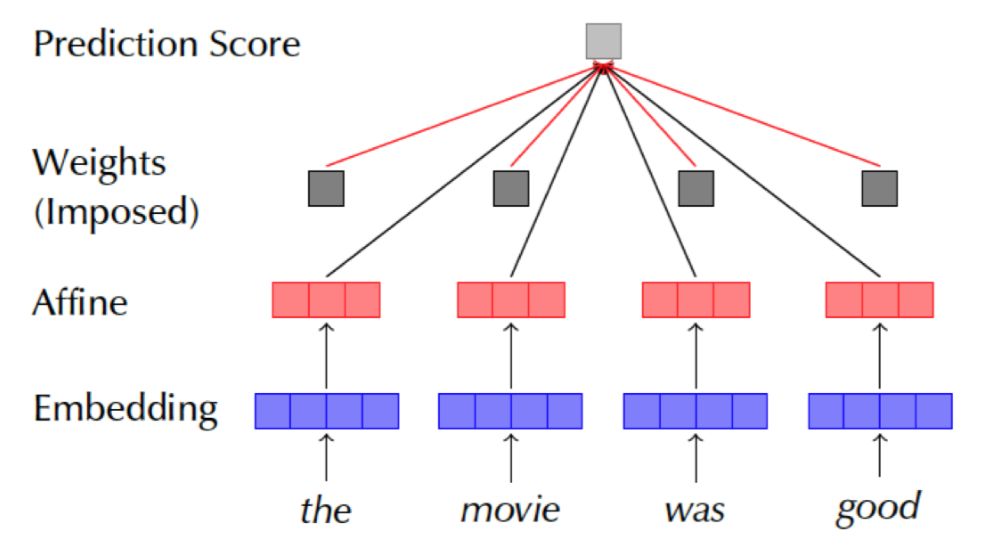
Diagnosing Attention Distribution by Guiding Simpler Models In this part, the model differs from previous ones; here, the aim is to more precisely test the Attention weight distribution, eliminating the influence of context-related structures. Therefore, the previously used LSTM encoding layer is removed, and only a MLP is used to complete the affine transformation from the embedding layer to the classification result. The pre-set non-trainable Attention weights are then directly used, with weighted summation to obtain the model decision results, as shown in Figure 16.The author designs four control experiments based on this:
Figure 15. Comparison of weight distributions based on random seed initialization and adversarial weight distributions against the original distribution’s JS distance
Diagnosing Attention Distribution by Guiding Simpler Models In this part, the model differs from previous ones; here, the aim is to more precisely test the Attention weight distribution, eliminating the influence of context-related structures. Therefore, the previously used LSTM encoding layer is removed, and only a MLP is used to complete the affine transformation from the embedding layer to the classification result. The pre-set non-trainable Attention weights are then directly used, with weighted summation to obtain the model decision results, as shown in Figure 16.The author designs four control experiments based on this:
-
Pre-set Attention weights as the average, serving as the baseline.
-
Not fixing the weights, allowing them to be trained along with the MLP.
-
Using the original Attention weights from when LSTM was used as the encoder.
-
Using adversarially generated Attention weights (implemented in the next section).
Figure 16. Model using pre-set Attention weights
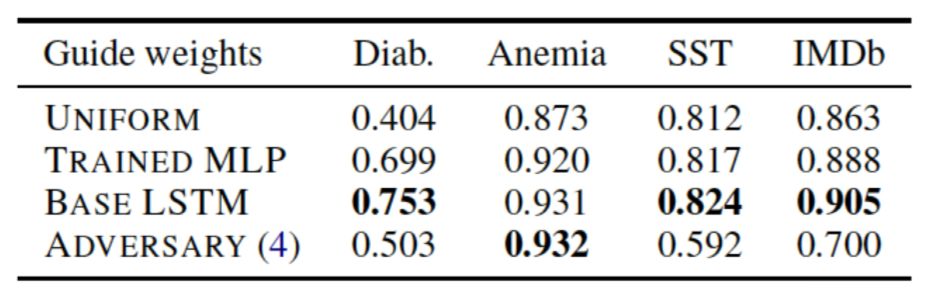
The results of the four control experiments are shown in Figure 17, where replacing the weights trained along with the MLP with original Attention weights improves performance. Additionally, in the first experiment, on datasets where Attention weights are significant, the performance of adversarial weights is much lower than that of original weights, indicating that the importance information encoded by the Attention mechanism is not independent of the model; the same dataset can utilize the token importance information coded by Attention in other models, but the constructed adversarial weights do not discover additional information from the data; they merely exploit specific model vulnerabilities (the model’s capability exceeds the task’s requirements).
Figure 17. F1 metrics obtained from four sets of control experiments
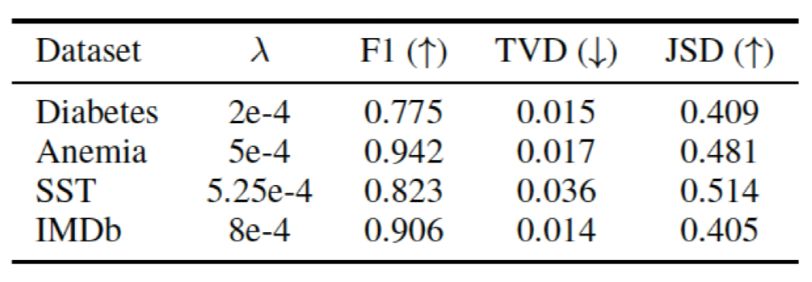
Train an Adversary Here is the specific generation model for adversarial weights, differing mainly from the model proposed by Jain[5] in the loss function: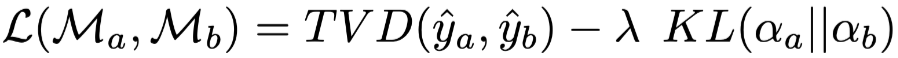 Where
Where  is the model using original weights, and
is the model using original weights, and  is the model using adversarial weights. As shown in Figure 18, it is indeed possible to obtain effective adversarial weights, but the previous experiment has already proven that these weights merely exploit the model’s loopholes and do not uncover more important information.
is the model using adversarial weights. As shown in Figure 18, it is indeed possible to obtain effective adversarial weights, but the previous experiment has already proven that these weights merely exploit the model’s loopholes and do not uncover more important information.
4 Conclusion
The interpretability of the Attention mechanism is currently a hot topic, with many authors designing various experiments to prove or disprove it, but there are always some incompleteness, issues with datasets, model designs, and sometimes even disagreements on the definition of interpretability. However, step-by-step explorations are always necessary.Both Serrano[4] and Jain[5] ultimately aim to find examples where Attention weights do not correctly express token importance, whether through intermediate representation erasure experiments or adversarial weight generation experiments.Both perspectives are limited to the Attention weights themselves, overlooking many factors that significantly influence results, such as whether the dataset requires the Attention mechanism, and the influence of context-related encoders on Attention weights, all of which could undermine the experiments’ validity.Wiegreffe[6] effectively rebutted Jain[5]’s experimental design flaws, but the reliability of his designed method for testing Attention weight migration remains debatable.
In addition, many questions are merely raised but not explored:
-
What types of tasks require the Attention mechanism; is it universal?
-
What impact does the selection of encoding layers have on Attention?
-
Is it reasonable to transfer Attention weights between different models on the same dataset?
-
How do the complexity of models and datasets affect the difficulty of constructing adversarial weights?
Moreover, Serrano[4] also proposed some prospects. Currently, research is still limited to importance based on Argmax, where everyone only considers the impact of Attention weights on the final decision results of the model; however, this is not everything, as there may also be cases where a certain feature decreases the probability of a particular category occurring, meaning that every item in the output Softmax function has research value, not just the one with the maximum result probability.
Finally, we look forward to what new developments the ACL2020 conference, with a submission deadline in December, will bring us.
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, pp. 5998-6008.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171-4186.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations.
[4] Sofia Serrano, and Noah A. Smith. 2019. Is Attention Interpretable. arXiv preprint arXiv:1906.03731.
[5] Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
[6] Sarah Wiegreffe, and Yuval Pinter. 2019. Attention is not not Explanation. arXiv preprint arXiv:1908.04626.
[7] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
[8] Yoon Kim. 2014. Convolutional neural networks for sentence classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing.
[9] Zachary C Lipton. 2016. The mythos of model interpretability. arXiv preprint arXiv:1606.03490.
Recommended Reading:
Longing for GAT (Graph Attention Model)
How to evaluate the fastText algorithm proposed by the author of Word2Vec? Does deep learning have no advantages in simple tasks like text classification?
From Word2Vec to Bert, discussing the past and present of word vectors (Part 1)