Continuing from the last time: Attention Mechanism Series 1 – Why Introduce Attention Mechanism
First, let’s talk about the role of the attention mechanism: It allows the model to dynamically focus on and process any part of the entire input sequence, without being limited by a fixed window size. This way, the model can selectively pay attention to the parts of the sequence that are most important for the current task.
So the question arises, how can we selectively focus?
We will explain this with three images (only discussing the calculation form of self-attention dot product)(Image source from Professor Li Hongyi’s video)
Step 1: Assume our input elements are a1, a2, a3, a4, as shown in the figure
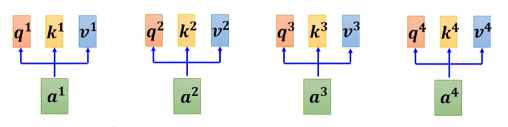
Each input element (to ) is first transformed into three different vectors: query (‘ ‘), key (‘ ‘), and value (‘ ‘). This is achieved by multiplying the input element with different weight matrices to generate the corresponding query, key, and value vectors. For example:
For input ‘ ‘, it is transformed into through weight matrix .
For input ‘a^2’, it is transformed into through weight matrix .
For input ‘ ‘, it is transformed into through weight matrix .
For input ‘a^4’, it is transformed into through weight matrix .
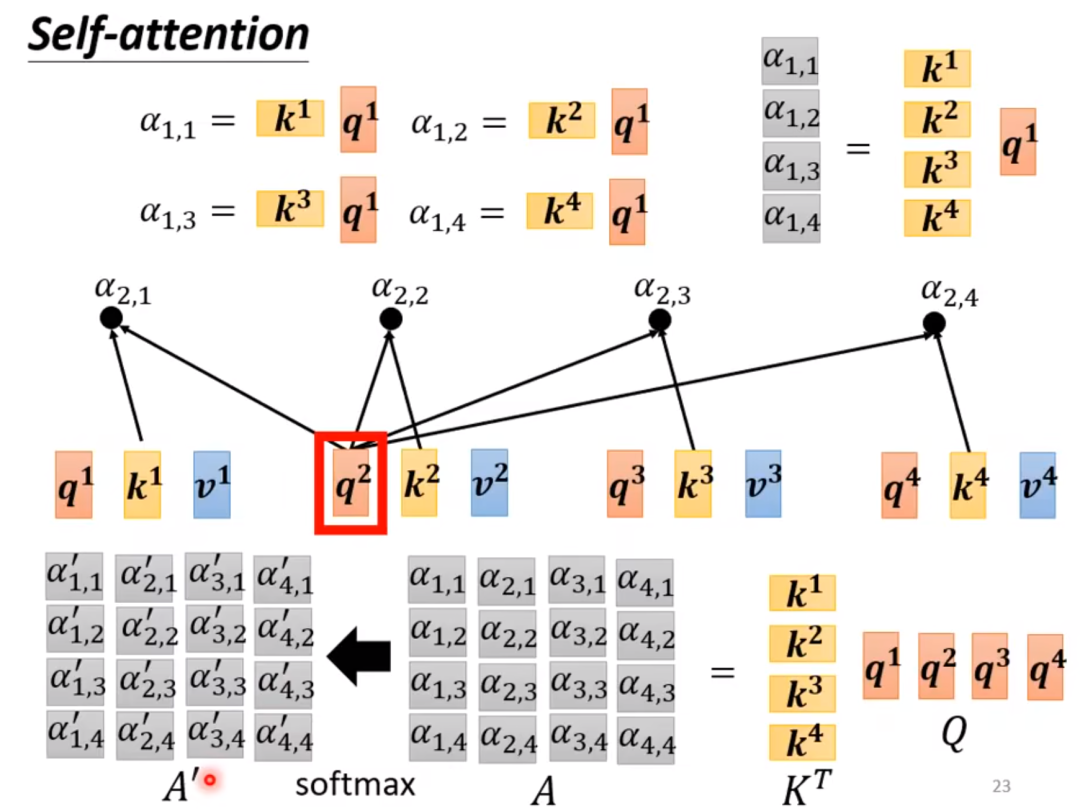
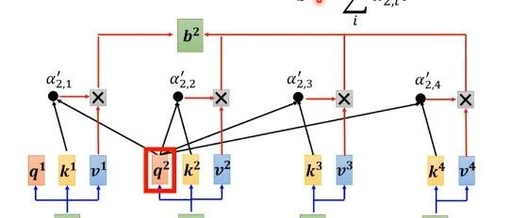
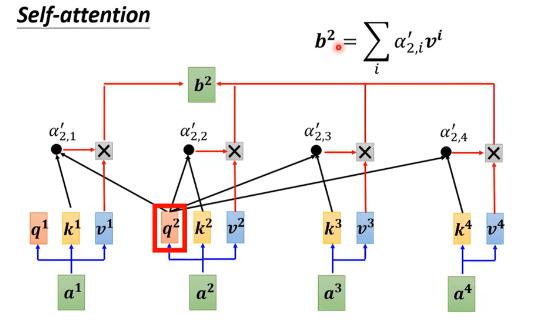
Step 2: Calculate the relationship between the current output vector and other vectors: taking a2 as an example
The overall steps are as follows: (For the formula, please note, I really can’t modify it )
First, perform dot product operation between and all keys , obtaining the raw attention scores.
Apply the softmax function to normalize the raw attention scores into a probability distribution (i.e., a”_2,1, a”_2,2, a”_2,3, a”_2,4).
Multiply each normalized attention score a” with the corresponding value (V) vector.
Sum all the product results to get the output vector ‘.
The red path in the figure highlights the process of calculating . This process can be executed in parallel to compute other output vectors.
Step 3: Further analyze using matrices
1. Calculate attention scores: For each and , calculate the dot product between them. This dot product indicates how much attention the element at position in the sequence should give to the element at position .2. Construct attention score matrix: The above calculation is performed for all and , resulting in a complete attention score matrix . Each element of matrix corresponds to a specific dot product between and .3. Apply softmax function: Use the softmax function to normalize each row of the attention score matrix , so that the sum of scores in each row equals 1, resulting in a normalized attention weight matrix .4. Obtain weighted value vector: Finally, the normalized attention weights are used to weight the value (value) vectors to compute the output vector. Each output vector is a weighted sum of all value vectors , with weights provided by .Step 4: Summarize why the attention mechanism can selectively focus on the parts of the sequence that are most important for the current task?1. Transformation of queries, keys, and values: Each sequence element is transformed into corresponding query , key , and value vectors. This is done by multiplying the input vector with different weight matrices . The weight matrices are learned through training, allowing the model to learn which features to extract from the data.2. Dot product and softmax normalization: The dot product of each query vector with all key vectors is calculated, generating a raw attention score. These scores are then normalized through the softmax function, turning them into a probability distribution representing relevance weights. This distribution indicates how much weight should be given to other elements in the sequence when calculating the new representation of the current element.3. Weighted sum: Through these normalized attention weights, the model computes the weighted sum of each value vector. This means that each output element is a weighted combination of all input elements, with weights reflecting their importance to the current output element.4. Selective focus: Since each output element is calculated by weighting all input elements, the model can selectively focus on those elements that are indicated as more important by the attention weights. In practical applications, for example, when translating a sentence, the model may pay more attention to other words that are semantically closely related to the current translation vocabulary.
 )
)