
Translated by AI
Source: news.mit.edu
Translator: Wen Qiang
[Introduction by AI]MIT’s new research takes a significant step toward unraveling the black box of deep neural networks: at this year’s CVPR, researchers submitted a new study that fully automates the analysis of ResNet, VGG-16, GoogLeNet, and AlexNet performing over 20 tasks. Their proposed Network Dissection can quantify the interpretability of CNNs, revealing that deep neural networks are not entirely black box structures.

Neural networks are powerful and widely used, but they have a fatal flaw: once trained, even the designers cannot understand how they operate. Indeed, this is what is referred to as a black box.
Two years ago, a team of computer vision researchers at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) proposed a method to “peek” inside the black box of neural networks. This method provided some interesting insights; however, it required data to be manually labeled in advance, which is time-consuming and labor-intensive.
At this year’s top computer vision conference CVPR, MIT CSAIL researchers will release a fully automated version of the same system. Automating the entire process is crucial, as it means that the results are generated by machines rather than humans, marking an important step in unraveling the black box of neural networks.
In previous research papers, the CSAIL research group analyzed a neural network capable of completing a single task. In the new paper, the authors analyze four neural networks: ResNet, VGG-16, GoogLeNet, and AlexNet, which can perform 20 tasks, including scene and object recognition, colorizing grayscale images, and solving puzzles.
The researchers also conducted several sets of experiments on these networks, yielding results that are not only useful for studying computer vision and computational photography algorithms but also provide insights into how the human brain is organized.

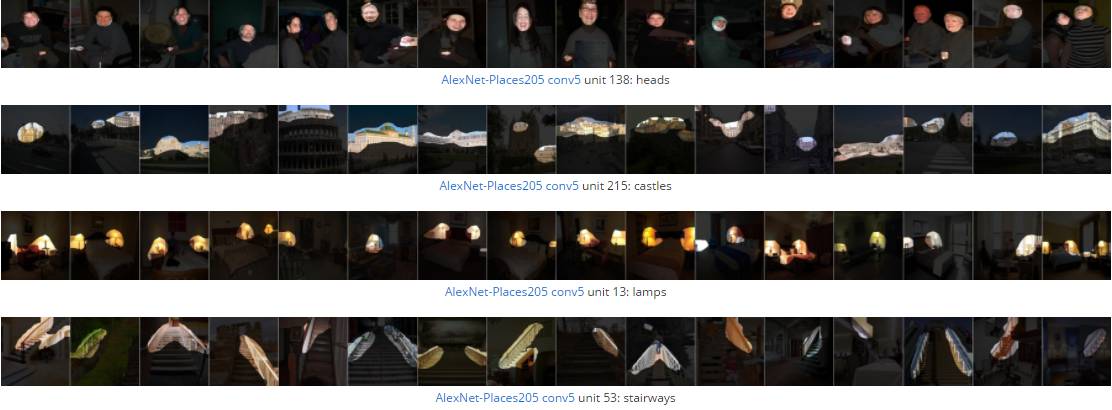
The above image shows that selected units in VGG-16, GoogLeNet, and ResNet can classify locations (from the Places-365 dataset) after training. Many individual units respond to specific high-level concepts (object segmentation), which the network has not encountered in the training dataset (scene classification).
Similar to the way neurons are connected in the human brain, neural networks consist of numerous nodes. When receiving information from adjacent nodes, a network node either “fires” a signal, meaning it produces a response, or does nothing. The intensity of the signals fired by different nodes also varies.
In both the new and old papers, MIT researchers trained neural networks to perform computer vision tasks. As designed, the response of individual nodes to different inputs can be detected. The researchers then selected 10 images that maximally stimulated the neurons to produce responses.
David Bau, one of the co-first authors of the paper and a graduate student in electrical engineering at MIT, said, “We cataloged 1,100 visual concepts, such as green, swirling texture, wooden materials, faces, bicycle wheels, or snow-capped mountains.” “We borrowed several datasets developed by others and merged them into a visual concept dataset. This dataset has many labels, and for each label, we know which pixel in which image corresponds to that label.”
The researchers also know which image pixels correspond to the strongest responses of a given network node. Neural networks are composed of layers. Data is first fed into the lowest layer, processed, and then passed on to the next layer, and so on. When processing visual data, the input image is divided into small patches, each fed into a separate input node.
For strong responses from high-level nodes in the network, researchers can trace back to their triggering patterns, identifying the corresponding specific image pixels. Because the system developed by the researchers can quickly identify the labels corresponding to such pixels, it can accurately characterize the behavior of nodes.
The researchers organized the visual concepts in the database into a hierarchy. Each level combines concepts from the following levels, starting from color, to texture, material, parts, objects, and scenes. Typically, lower layers of the neural network respond to simpler visual features (such as color and texture), while higher layers respond to more complex features.
Moreover, the hierarchy also allows researchers to quantify the emphasis assigned by trained networks when performing tasks with different visual characteristics. For instance, a network that colorizes black-and-white images allocates most nodes to recognizing textures. Another network used for tracking objects in multi-frame videos assigns a higher proportion of nodes to scene recognition.
These explainable units are fascinating because their existence indicates that deep neural networks are not entirely black box structures. However, it is still unclear whether these explainable units can prove the existence of so-called “disentangled representations.”
The researchers aim to answer the following three questions in the paper:
-
What is disentangled representation? How can its factors be quantified and detected?
-
Do explainable hidden units reflect a special consistency in feature space? Or is explainability non-existent (chimera)?
-
What conditions in current state-of-the-art training methods create entanglement in representations?
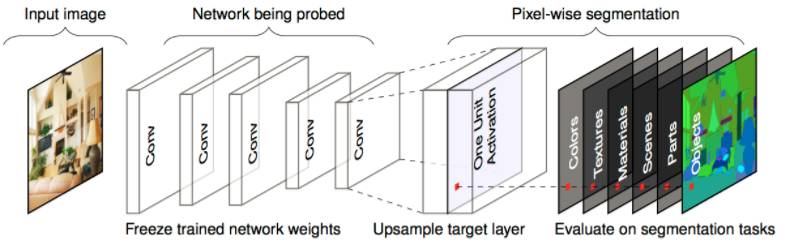
The researchers proposed a comprehensive framework called Network Dissection (see below) to quantify the interpretability of CNNs. They also analyzed the impact of CNN training techniques on interpretability, finding that representations at different layers reveal different categories of meaning, and that different training techniques significantly affect the interpretability of hidden unit learning.
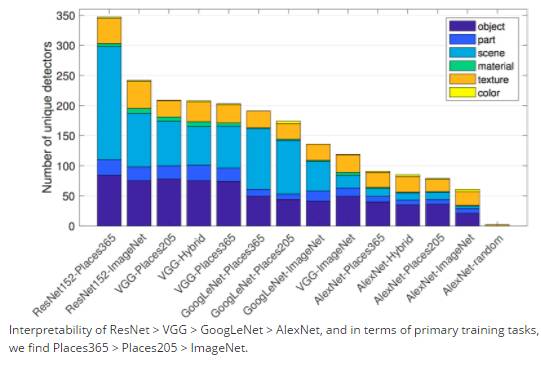
Results show that the interpretability of networks is in the order of ResNet > VGG > GoogLeNet > AlexNet, and in training tasks, the results of datasets also differ, with Places365 > Places205 > ImageNet.
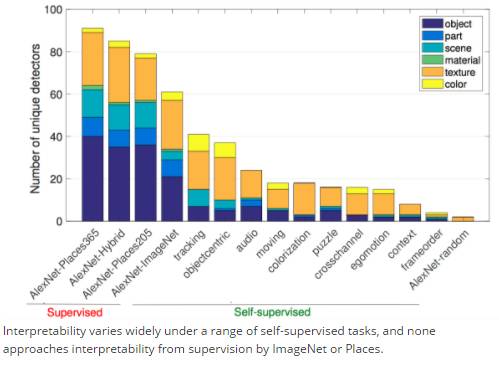
In self-supervised tasks, interpretability also varies for different tasks.
Moreover, Network Dissection also allows researchers to “see” the process by which the network “forms concepts” during training.
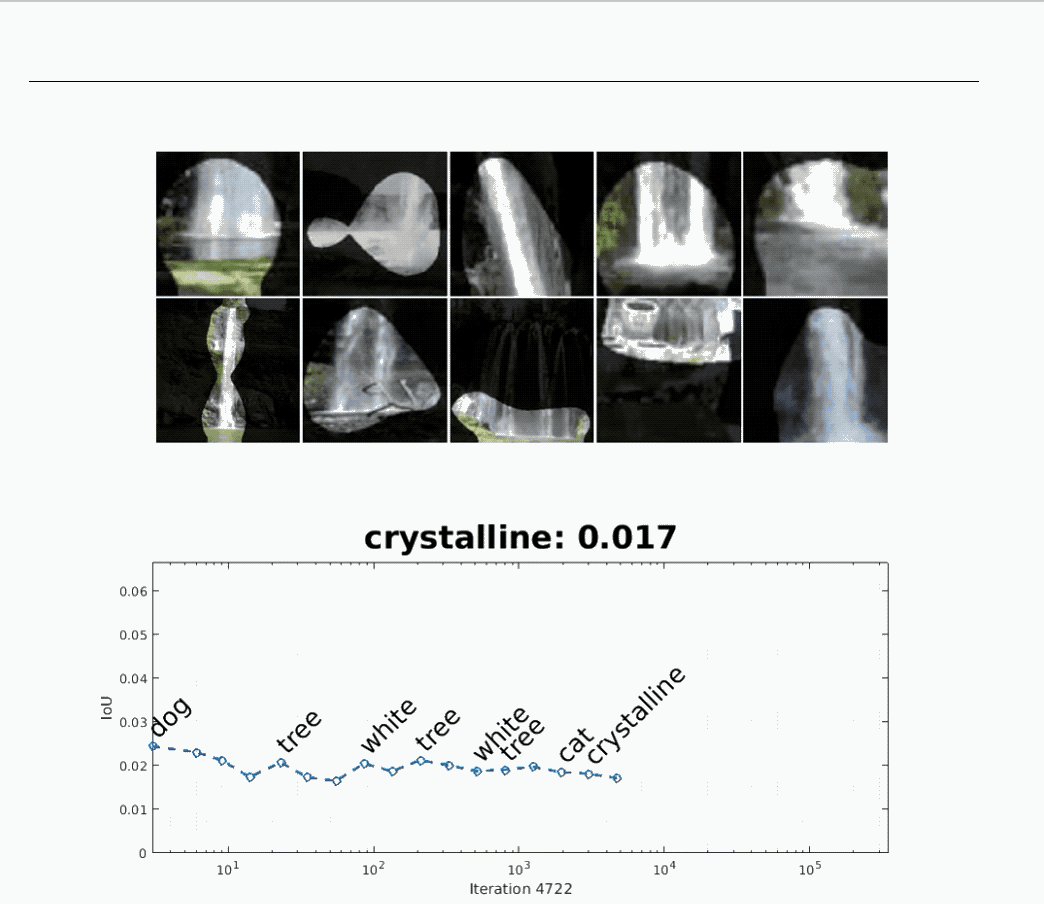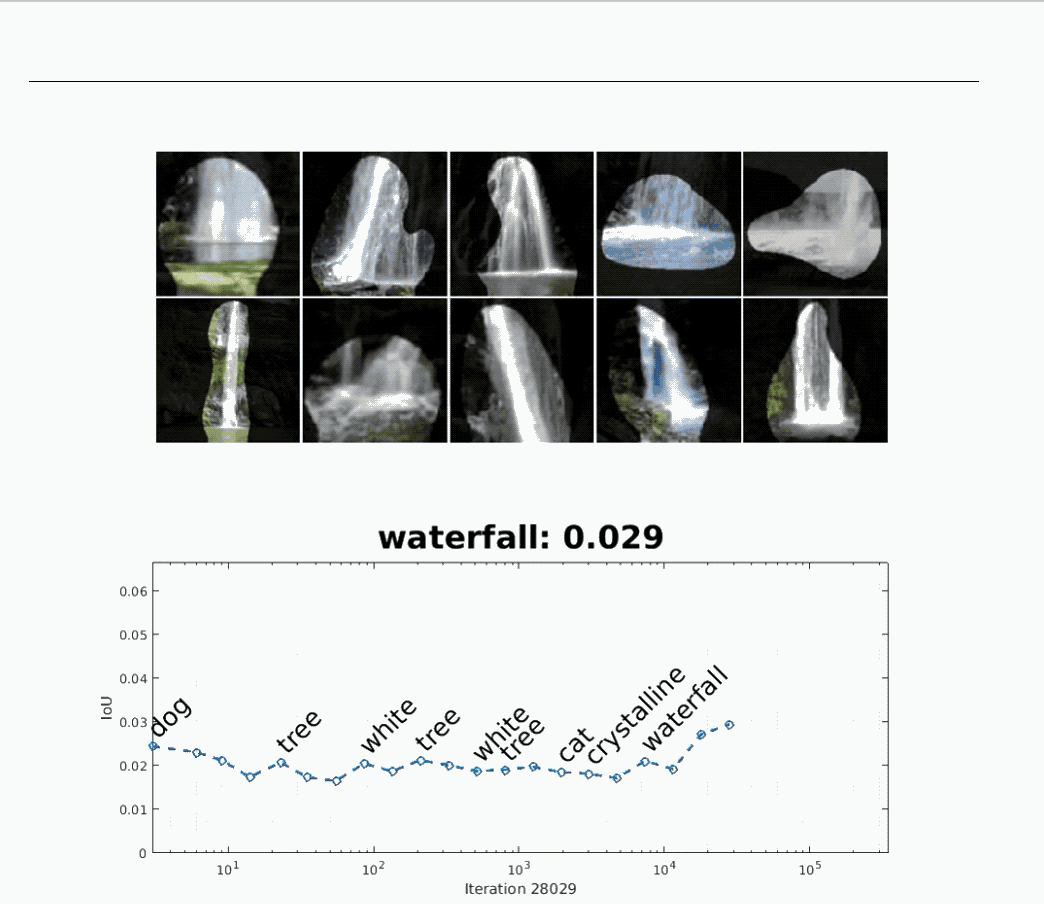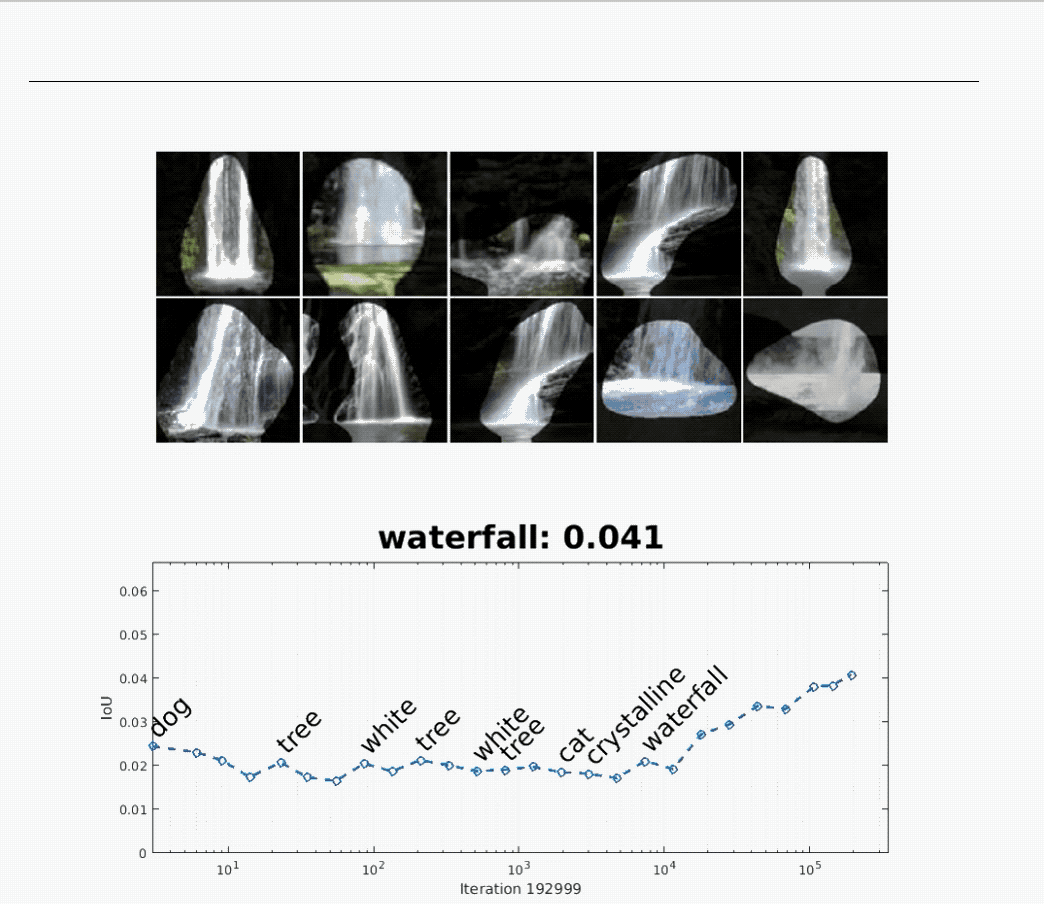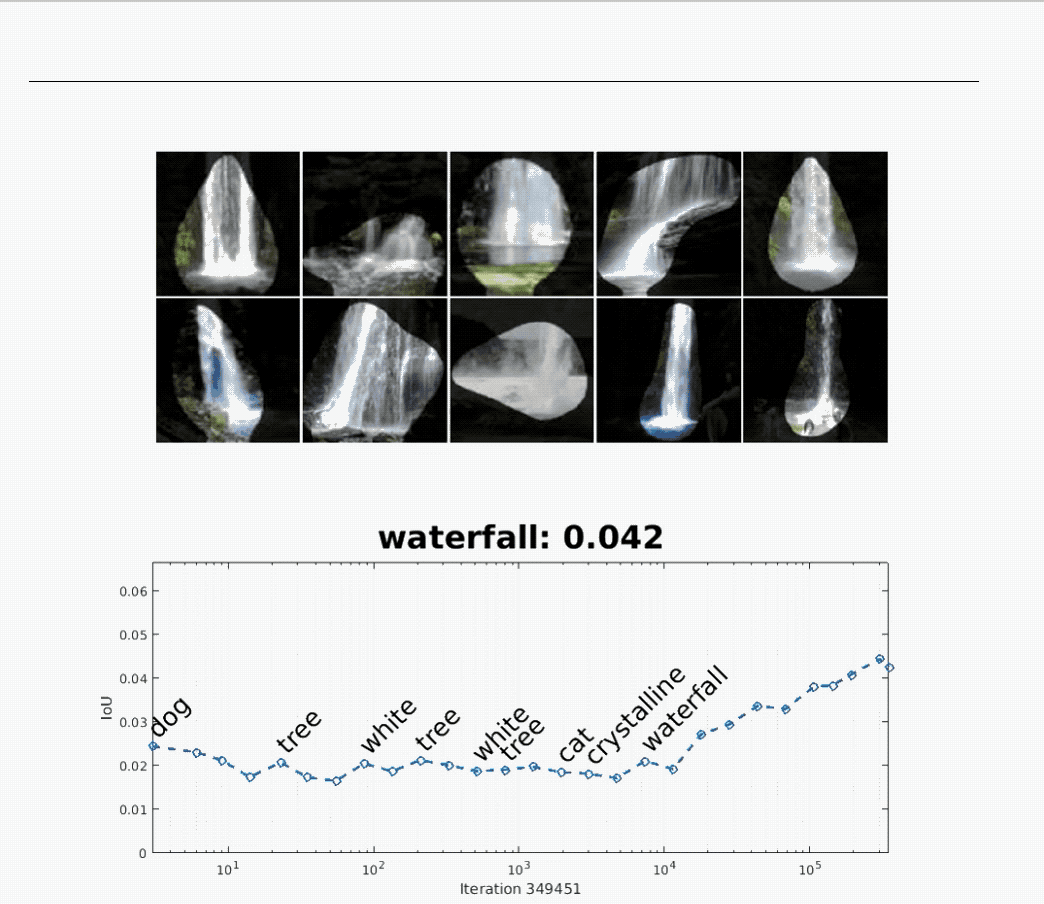
The above animation shows that a neural network initially used for recognizing “dogs” later becomes one for recognizing “waterfalls.”
In experiments conducted by the researchers, one also provided an answer to a long-standing debate in neuroscience. Previous studies suggested that individual neurons in the brain respond to specific stimuli. This hypothesis was initially known as the grandmother cell hypothesis and later became widely known as the “Jennifer Aniston neuron hypothesis.” Scientists who proposed the Jennifer Aniston neuron hypothesis found that several patients in their experiments had neurons that seemed to respond only to the faces of specific Hollywood celebrities.
Many neuroscientists disagreed with this hypothesis. They argued that it is combinations of different neurons, rather than single neurons, that are responsible for determining perceptual discrimination in the brain. Thus, the so-called Jennifer Aniston neuron is just one of many neurons, part of the neurons that respond to images of Jennifer Aniston’s face. This part of the neurons could also be part of many other combinations of neurons, just that those combinations have not been observed yet.
Since the new analysis technique proposed by MIT researchers is fully automated, it can test whether a similar phenomenon occurs in neural networks. In addition to identifying individual network nodes that respond to specific visual concepts, the researchers also considered randomly selected combinations of nodes. However, the results showed that the visual concepts chosen from combinations of nodes were significantly fewer than those from individual nodes—about an 80% reduction.
Bau said, “In my view, this suggests that neural networks are indeed striving to approximate a grandmother cell. Neurons do not want to distribute the concept of grandmother everywhere, but rather assign this concept to a single neuron. This aspect of the structure is something that most people do not believe is that simple.”

Abstract
We propose a general framework called Network Dissection, which quantifies the interpretability of CNN representations by assessing the consistency degree between individual hidden units and a set of semantic concepts. Given any CNN model, our proposed method utilizes a dataset containing a vast number of visual concepts to evaluate the semantics of each hidden unit in intermediate convolutional layers. Semantic units are assigned a range of different labels, including objects, parts, scenes, textures, materials, and colors. We use the proposed method to test a hypothesis that the interpretability of a unit is equivalent to the random linear combination of that unit. We then apply our method to compare the potential representations of various networks trained to solve different supervised and self-supervised tasks. We further analyze the effects of training iterations, compare networks initialized with different training, examine the impacts of network depth and width, and measure the effects of dropout and batch normalization on the interpretability of deep visual representations. We demonstrate that the proposed method can reveal the characteristics of CNN models and related training methods.
Paper link: http://netdissect.csail.mit.edu/final-network-dissection.pdf

Click to read the original text to see job information from AI.