LLM (Large Language Model) is a powerful new platform, but they are not always trained on data relevant to our tasks or the latest data.
RAG (Retrieval Augmented Generation) is a general method that connects LLMs with external data sources (such as private or up-to-date data). It allows LLMs to use external data to generate their outputs.
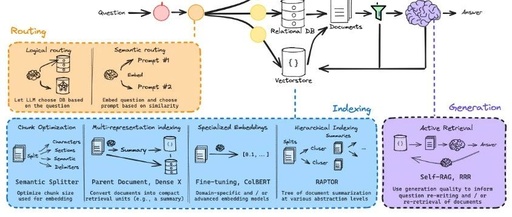
To truly master RAG, we need to learn the techniques shown in the diagram below:
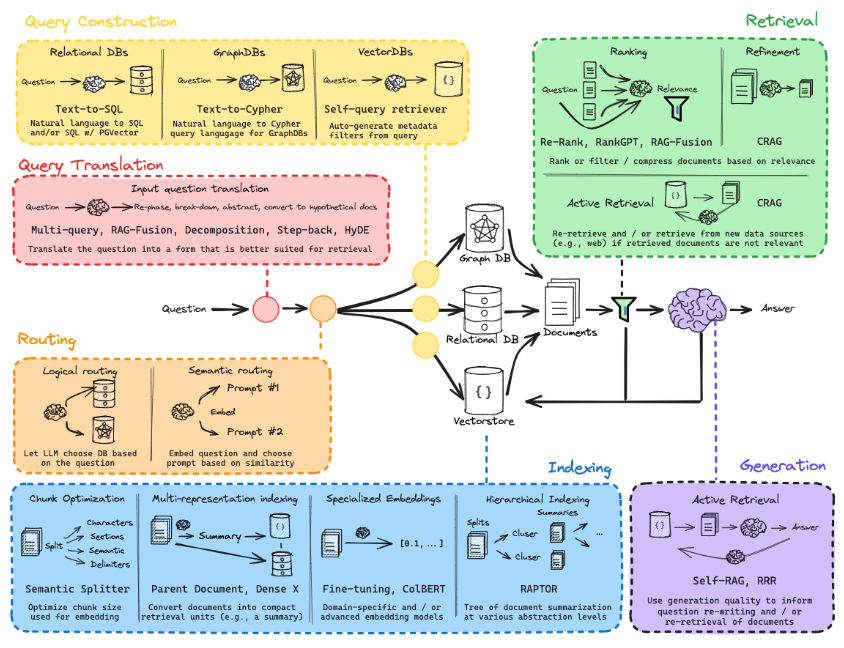
This diagram may seem overwhelming, but don’t worry, you are in the right place.
This tutorial series will introduce how to build an understanding of RAG from scratch.
We will start with the basics of Indexing, Retrieval, and Generation.
The following flowchart illustrates the process of basic RAG:
-
We index external documents (Indexing);
-
Retrieve relevant documents based on user questions (Retrieval);
-
Input the question and relevant documents into the LLM to generate the final answer (Generation).
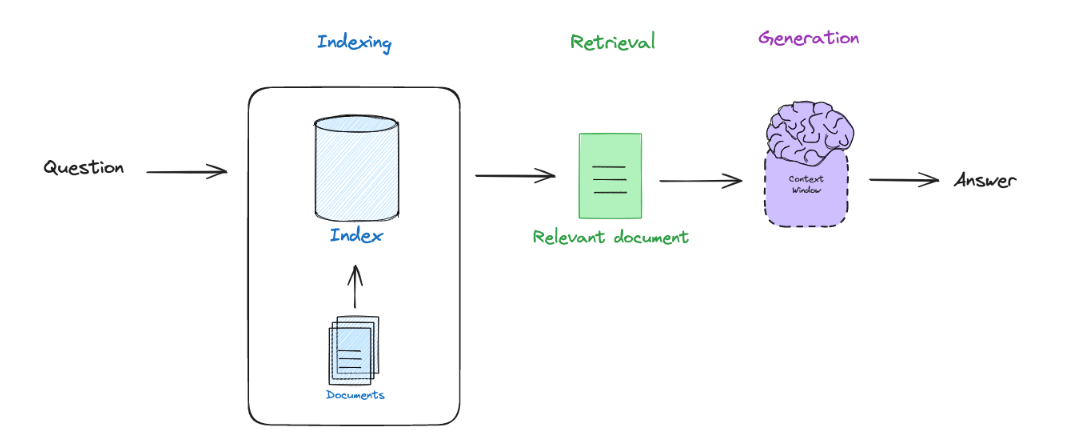
Indexing
We start learning Indexing by loading documents. LangChain has over 160 different document loaders that we can use to scrape data from many different sources for Indexing.
https://python.langchain.com/docs/integrations/document_loaders/
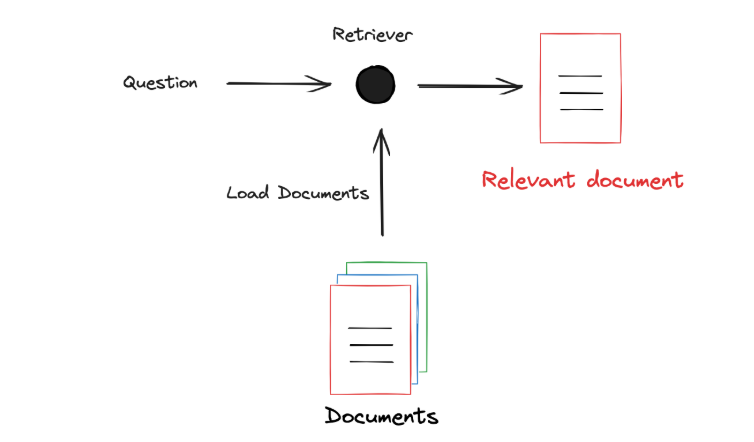
We input the Question into the Retriever, which also loads external documents (knowledge) and filters out the documents related to the Question:
We need to convert Text Representation to Numerical Representation to better achieve relevance (for example, cosine similarity) filtering:
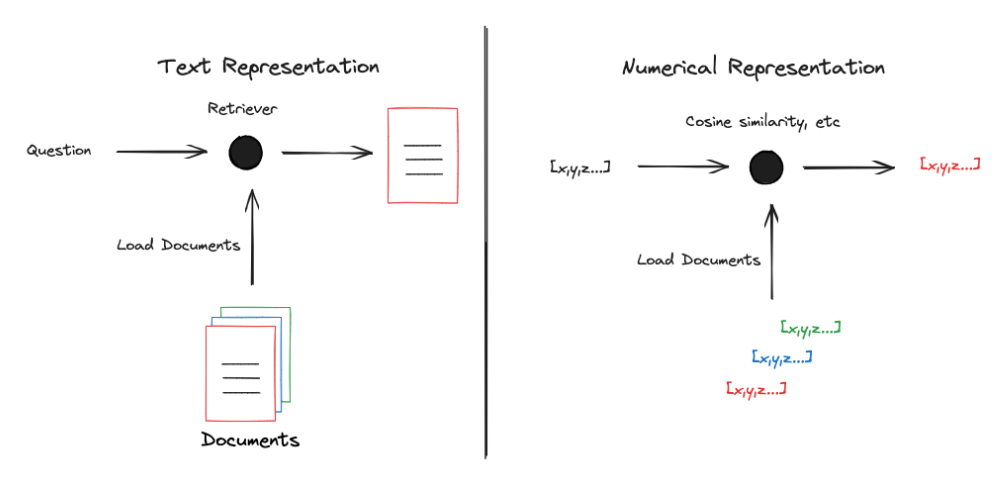
There are many ways to convert text into numerical representation, typically including:
-
Statistical (based on statistics)
-
Machine Learned (based on machine learning)

The most commonly used method now is to use machine learning methods to convert text into fixed-length Embedding Vectors that capture the semantic meaning of the text.
There are many open-source Embedding Models (such as the BAAI series) that can convert text into Embedding Vectors. However, these models have a limited Context Window, generally between 512 to 8192 tokens (if you don’t know what a token is, please skip to the end).
So the normal process is to split external documents into chunks so that these chunks can meet the Embedding Model’s Context Window:
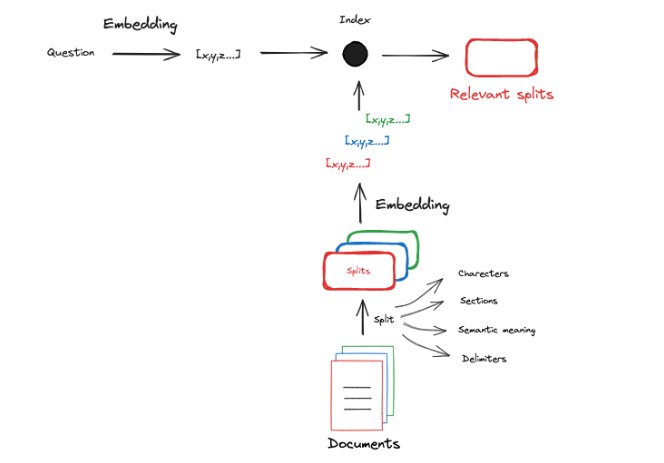
By now, we have mastered the theory of Indexing, and we can practice using Qwen + BAAI + LangChain + Qdrant.
First, configure the LLM and Embedding Model:

Then load external documents, here the document is a web blog:
As I mentioned earlier, the Embedding Model’s Context Window is limited, so we cannot directly input the entire document. We must split the original document into chunks:

Next, we configure the Qdrant vector database:

You can read Qdrant: An Open-Source Vector Database & Vector Search Engine Written in Rust to learn about Qdrant.
The final step is to index the document chunks and store them in the vector database:

Retrieval
Retrieval is finding the k most similar chunks of semantic vectors based on the semantic vector of our question (i.e., the Embedding Vector).
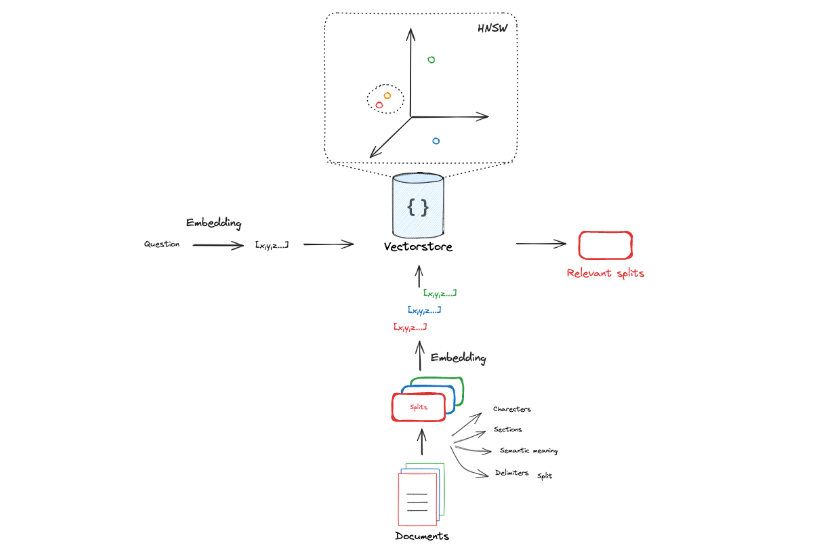
The following diagram demonstrates Embedding Vector Retrieval in a 3D space:
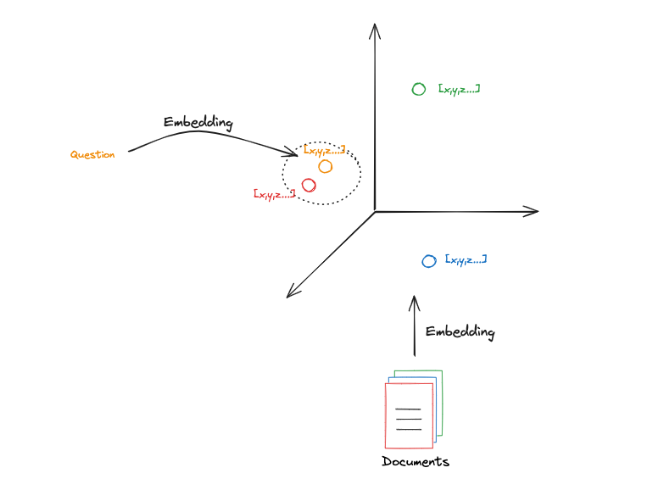
Embedding Vectors are typically stored in a Vector Store (vector database), which implements various methods to compare the similarity between Embedding Vectors.
Next, we build a retriever using the Vector Store constructed during Indexing, input the question, and perform the retrieval:
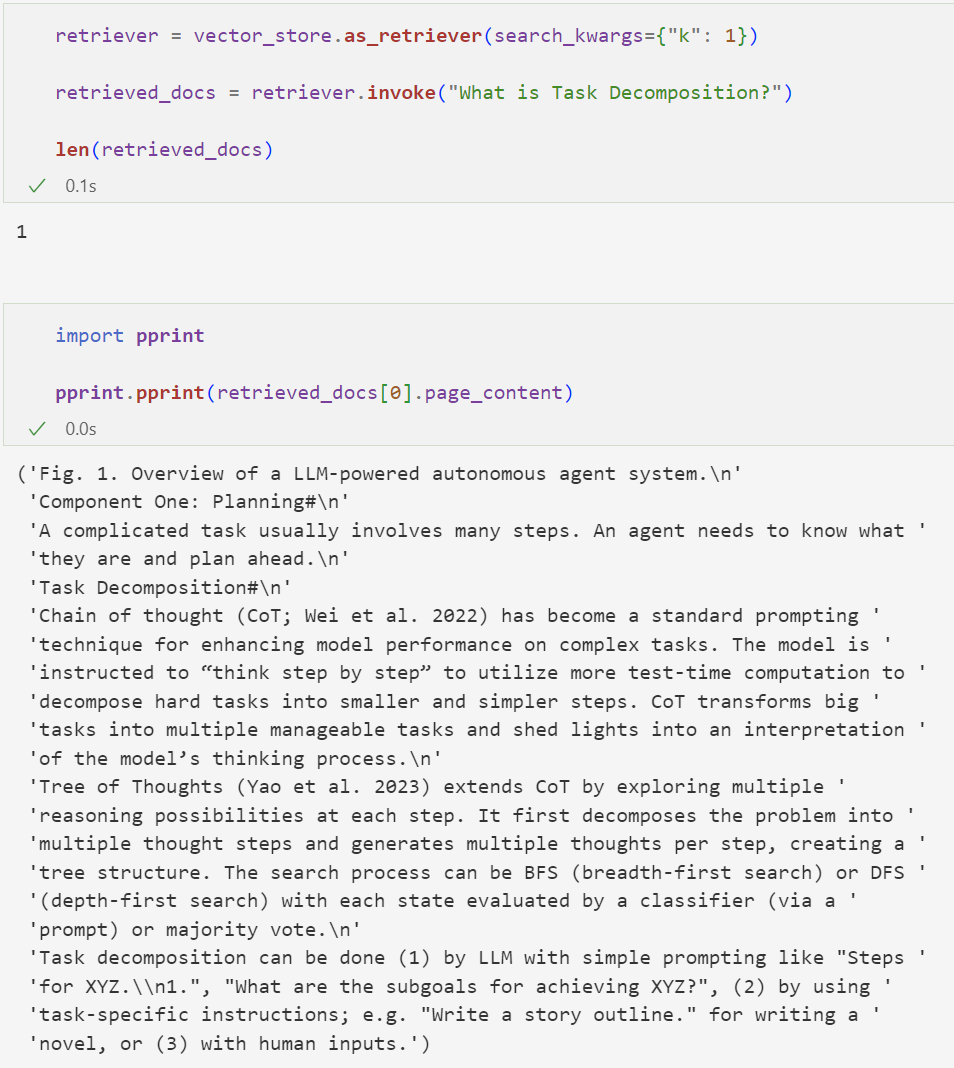
According to the k value we set, we retrieved a document chunk related to the question.
Generation
Now that we can retrieve knowledge chunks (Splits) related to user questions, we need to input this information (question + knowledge chunks) into the LLM to generate a fact-based answer:
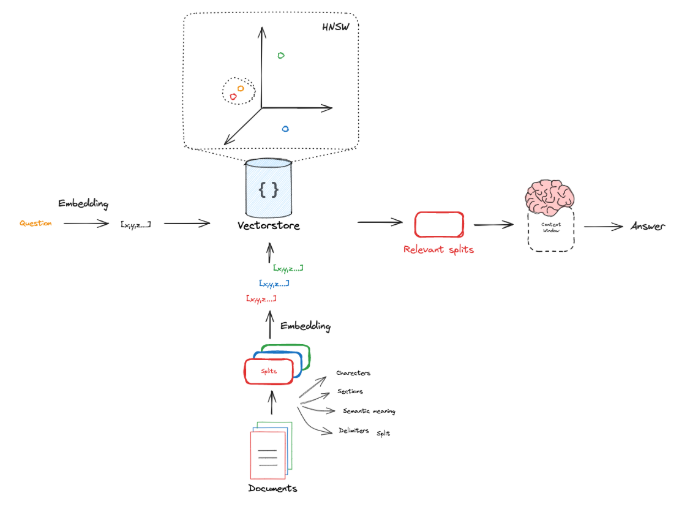
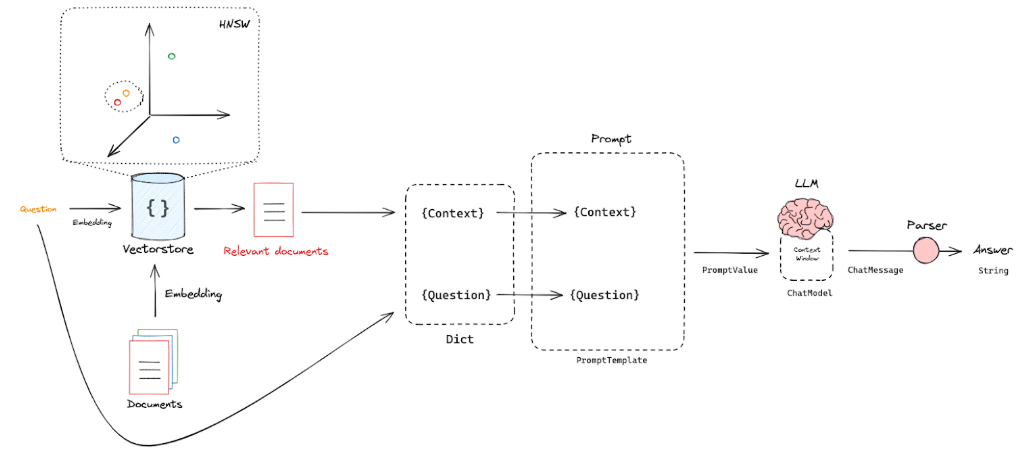
We need to:
-
Put the question and knowledge chunks into a dictionary, with the question under the key Question and the knowledge chunks under the key Context;
-
Then compose a Prompt String using PromptTemplate;
-
Finally, input the Prompt String into the LLM, which will generate the answer.
It seems complicated, but that’s the purpose of frameworks like LangChain and LlamaIndex:
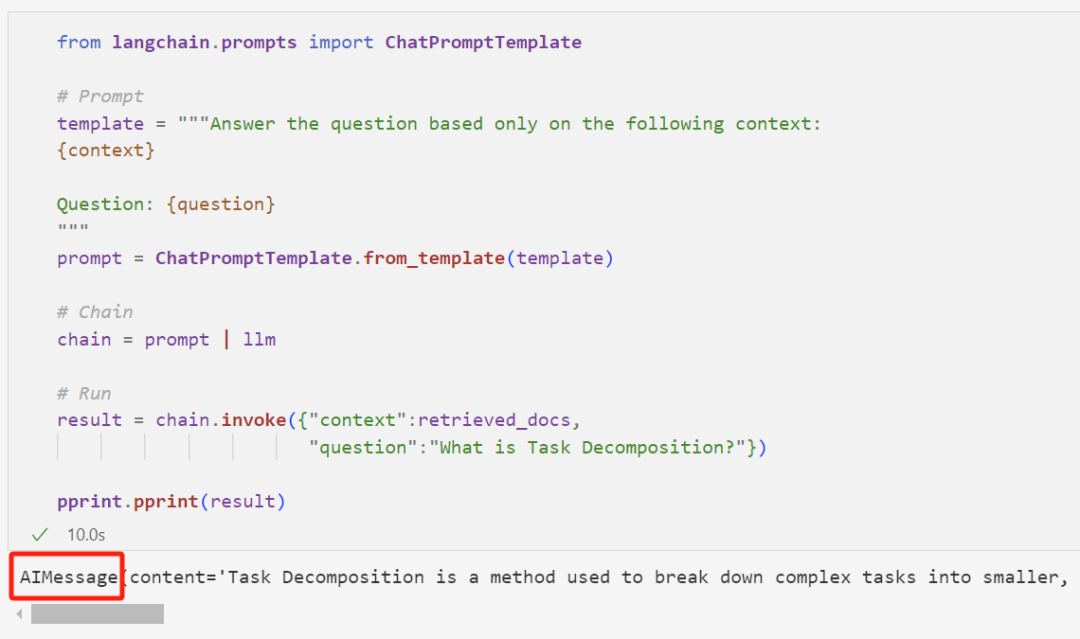
Those of you who are observant will notice that the returned result is an AIMessage object; we may need a pure string output; and the retrieval and generation processes are separate, which is inconvenient.
However, we can use LangChain to chain the retrieval and generation processes together:

LangSmith
If you are still unfamiliar with the entire RAG pipeline process, you might want to check the LangSmith page to see how the entire process is linked step by step:
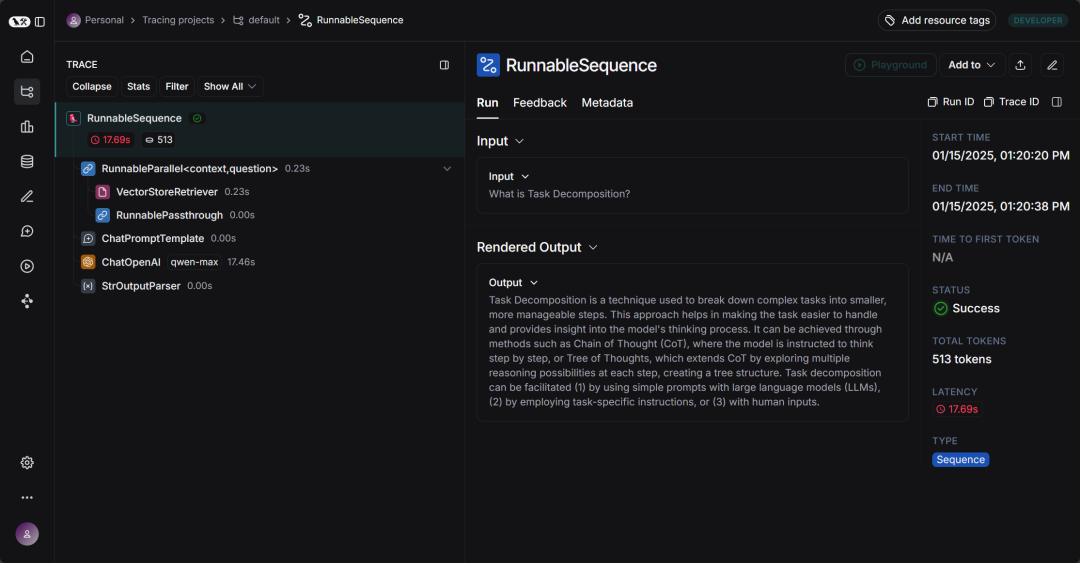
LangSmith is a platform for building production-level LLM applications. It allows us to closely monitor and evaluate our applications so that we can deliver quickly and confidently. With LangSmith, we can:
-
Track LLM applications
-
Understand other parts of the LLM calls and application logic.
What is a token?
A token is the basic unit that models use to represent natural language text, which can intuitively be understood as a “word” or “term”.
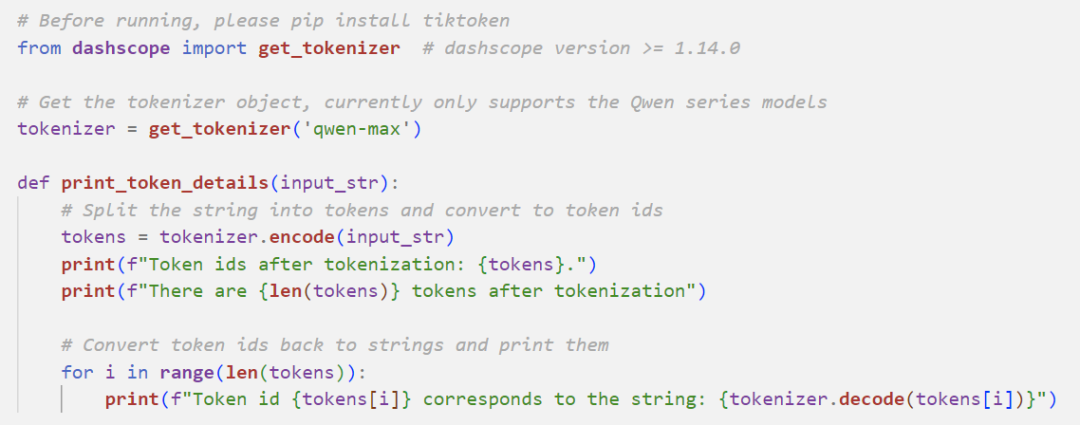
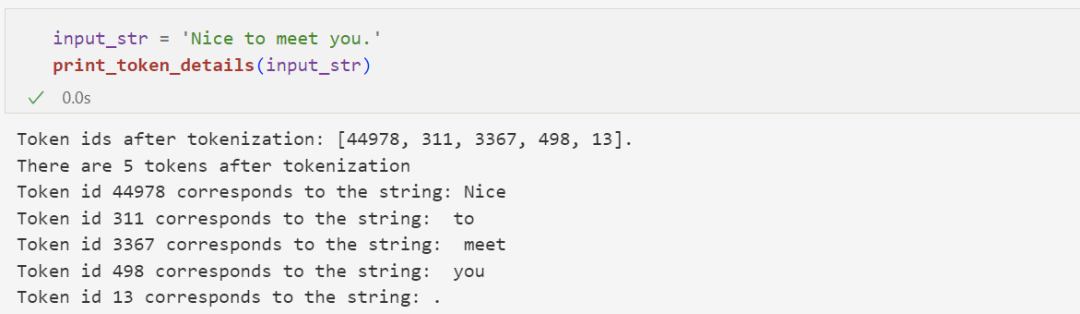
For English text, 1 token usually corresponds to 3 to 4 letters:
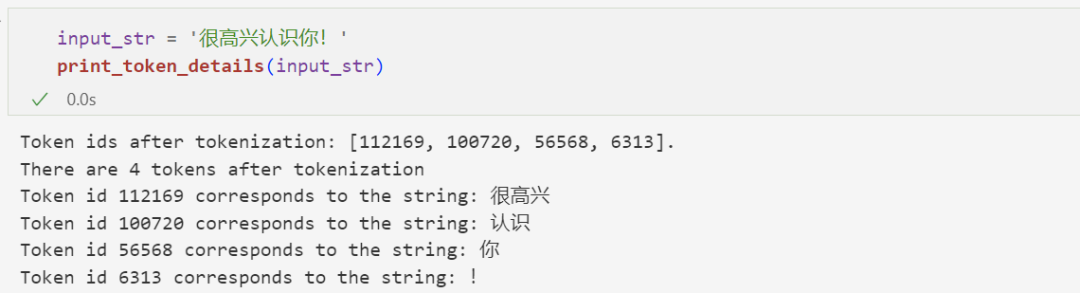
For Chinese text, 1 token usually corresponds to a Chinese character:
GitHub Link:
https://github.com/realyinchen/RAG/blob/main/01_Indexing_Retrieval_Generation.ipynb
Source: PyTorch Study Group