
Video understanding faces immense challenges due to significant spatiotemporal redundancy and complex spatiotemporal dependencies. Overcoming these two issues is extremely difficult, and CNNs, Transformers, and Uniformers struggle to meet these demands. Mamba presents a promising approach; let’s explore how this article creates video understanding with VideoMamba.
The core goal of video understanding lies in mastering spatiotemporal representations, which presents two significant challenges: short video clips contain substantial spatiotemporal redundancy and complex spatiotemporal dependencies. Although the previously dominant 3D Convolutional Neural Networks (CNNs) and video Transformers effectively address one of these challenges by leveraging local convolutions or long-range attention, they fall short in simultaneously tackling both issues. UniFormer attempts to integrate the advantages of both methods, but it faces difficulties in modeling long videos.
Low-cost solutions like S4, RWKV, and RetNet have opened new avenues for visual models in the field of natural language processing. Mamba stands out with its Selective State Space Model (SSM), achieving a balance that promotes long-term dynamic modeling while maintaining linear complexity. This innovation has driven its application in visual tasks, as evidenced by Vision Mamba and VMamba, which utilize multi-directional SSM to enhance two-dimensional image processing. These models perform comparably to attention-based architectures while significantly reducing memory usage.
Given that the sequences generated by videos are inherently longer, a natural question arises: Can Mamba perform well in video understanding?
Inspired by Mamba, this article introduces VideoMamba, a pure SSM (Selective State Space Model) tailored for video understanding. VideoMamba combines the advantages of convolution and attention in the style of Vanilla ViT. It offers a method with linear complexity for dynamic spatiotemporal background modeling, making it highly suitable for high-resolution long videos. The relevant evaluations focus on four key capabilities of VideoMamba:
Scalability in Visual Domains: This article examines the scalability of VideoMamba, finding that the pure Mamba model tends to overfit as it scales up. A simple yet effective self-distillation strategy is introduced, enabling VideoMamba to achieve significant performance enhancements without the need for large-scale dataset pre-training as model and input sizes increase.
Sensitivity to Short-Term Action Recognition: The analysis extends to evaluating VideoMamba’s ability to accurately distinguish short-term actions, particularly those with subtle motion differences, such as opening and closing. The findings indicate that VideoMamba demonstrates superior performance over existing attention-based models. More importantly, it is also applicable to mask modeling, further enhancing its temporal sensitivity.
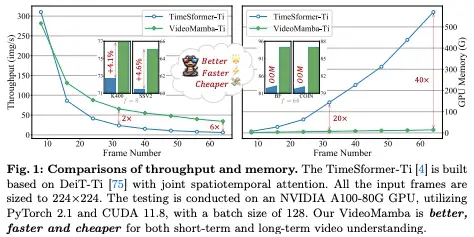
Superiority in Long Video Understanding: This article assesses VideoMamba’s capability to interpret long videos. Through end-to-end training, it showcases significant advantages compared to traditional feature-based methods. Notably, VideoMamba runs 6 times faster than TimeSformer on 64-frame videos and reduces GPU memory requirements by 40 times (as shown in Figure 1).
Compatibility with Other Modalities: Finally, this article evaluates VideoMamba’s adaptability to other modalities. Results in video-text retrieval show improved performance compared to ViT, especially in long videos with complex scenes. This highlights its robustness and multimodal integration capabilities.
In-depth experiments in this article reveal VideoMamba’s immense potential for understanding both short-term (K400 and SthSthV2) and long-term (Breakfast, COIN, and LVU) video content. Given its efficiency and effectiveness, VideoMamba is destined to become a cornerstone in the field of long video understanding. All code and models have been open-sourced to facilitate future research efforts.

-
Paper Address: https://arxiv.org/pdf/2403.06977.pdf
-
Project Address: https://github.com/OpenGVLab/VideoMamba
-
Paper Title: VideoMamba: State Space Model for Efficient Video Understanding
Method Introduction
Figure 2a displays the details of the Mamba module.
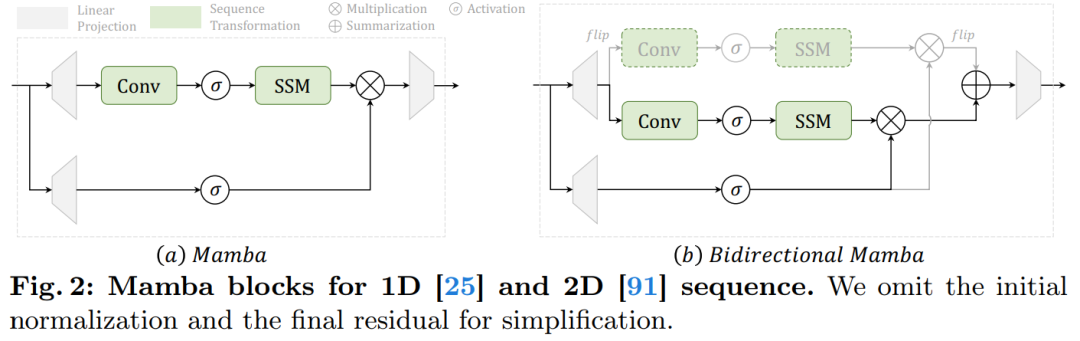
Figure 3 illustrates the overall framework of VideoMamba. This article first projects the input video Xv ∈ R3×T×H×W into L non-overlapping spatiotemporal patches Xp ∈ R L×C using 3D convolution (i.e., 1×16×16), where L=t×h×w (t=T, h=H/16, and w=W/16). The token sequence input to the subsequent VideoMamba encoder is 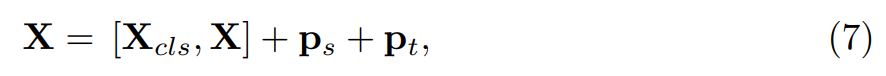
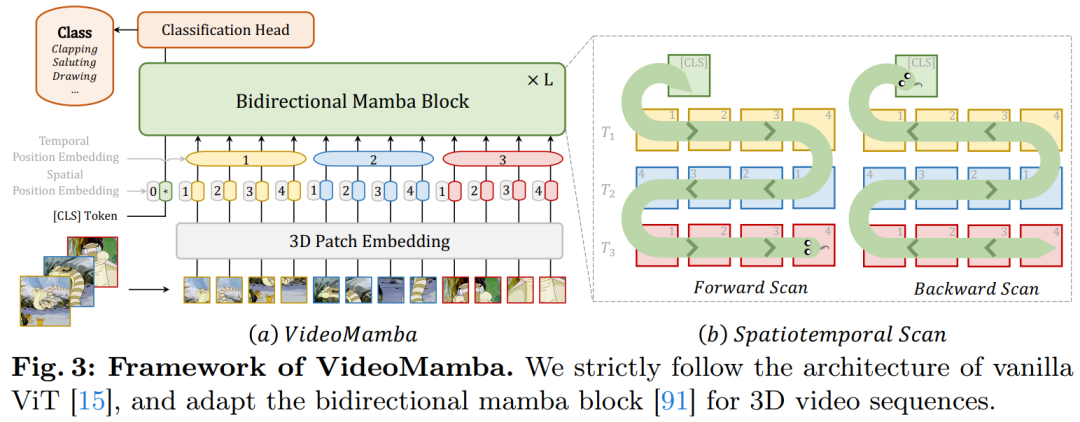
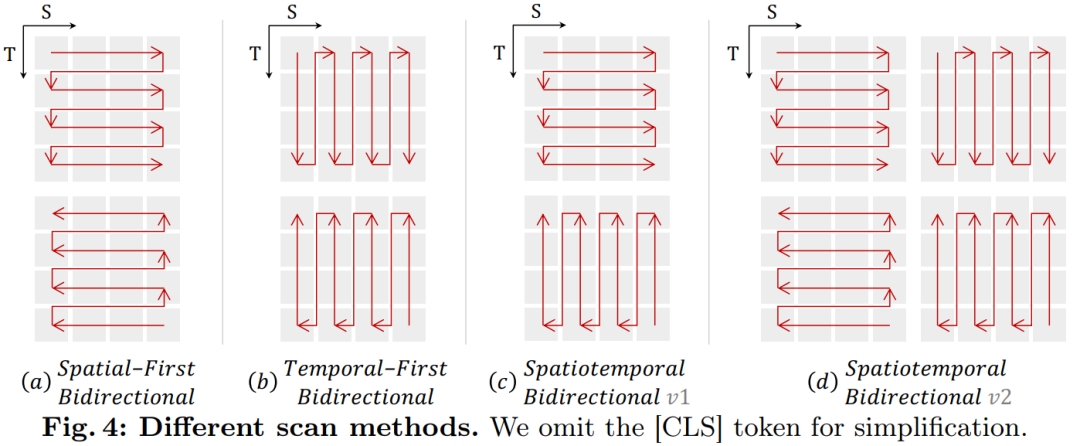
Spatiotemporal Scanning: To apply the B-Mamba layer to spatiotemporal input, this article extends the original 2D scanning into different bidirectional 3D scans as shown in Figure 4:
(a) Spatial-first, organizing spatial tokens by position and stacking them frame by frame;
(b) Temporal-first, arranging temporal tokens by frame order and stacking them along the spatial dimension;
(c) Spatiotemporal mix, combining both spatial-first and temporal-first, where v1 performs half of one and v2 performs all (2 times the computational load).
Experiments in Figure 7a indicate that the spatial-first bidirectional scan is the most efficient yet simplest. Due to Mamba’s linear complexity, this article’s VideoMamba can efficiently handle high-resolution long videos.
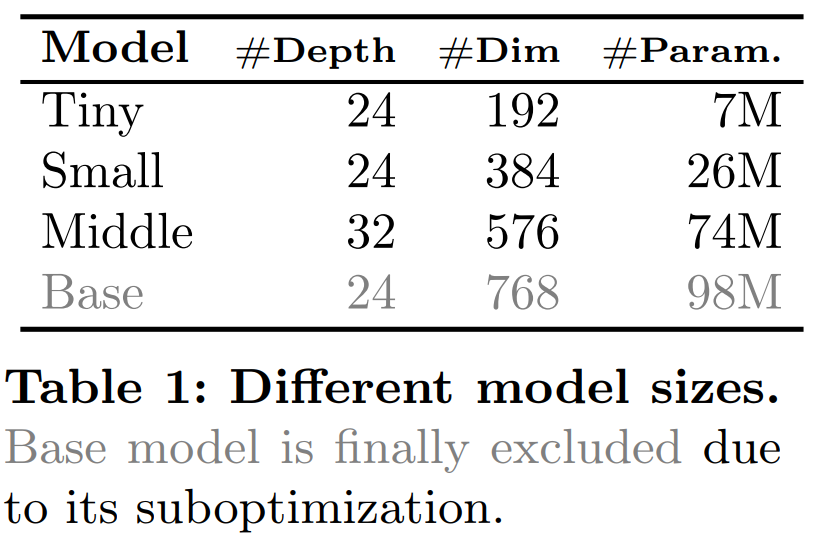
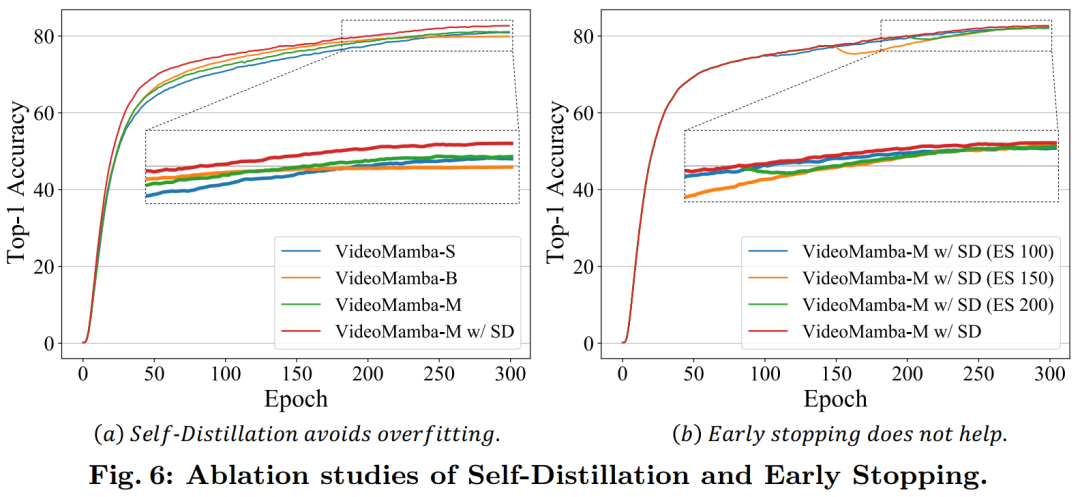
For the SSM in the B-Mamba layer, this article adopts the same default hyperparameter settings as Mamba, setting the state dimension and expansion ratio to 16 and 2, respectively. Following ViT’s approach, this article adjusts the depth and embedding dimensions to create models of comparable size to those in Table 1, including VideoMamba-Ti, VideoMamba-S, and VideoMamba-M. However, larger VideoMamba models tend to overfit in experiments, leading to suboptimal performance as shown in Figure 6a. This overfitting issue is not only present in the model proposed in this article but also in VMamba, where the best performance of VMamba-B is reached at three-quarters of the total training period. To combat the overfitting problem of larger Mamba models, this article introduces an effective self-distillation strategy, using a smaller well-trained model as a “teacher” to guide the training of the larger “student” model. As indicated by the results in Figure 6a, this strategy leads to the expected better convergence.
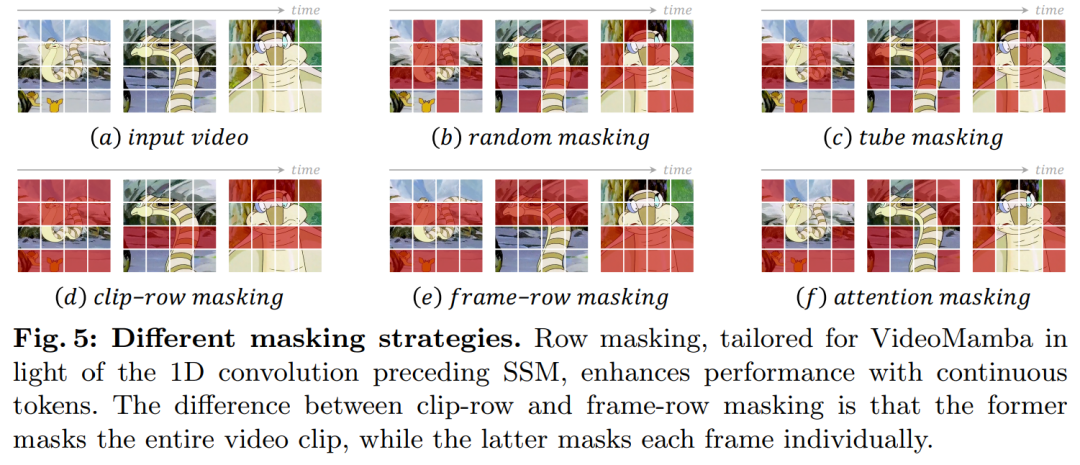
Regarding masking strategies, this article proposes different row masking techniques as shown in Figure 5, specifically targeting the B-Mamba block’s preference for continuous tokens.
Experiments
Table 2 presents results on the ImageNet-1K dataset. Notably, VideoMamba-M significantly outperforms other isotropic architectures, improving by +0.8% compared to ConvNeXt-B and +2.0% compared to DeiT-B, while using fewer parameters. VideoMamba-M also excels in the hierarchical feature-based non-isotropic backbone structure aimed at enhancing performance. Given Mamba’s efficiency in handling long sequences, this article further improves performance by increasing resolution, achieving a top-1 accuracy of 84.0% with just 74M parameters.
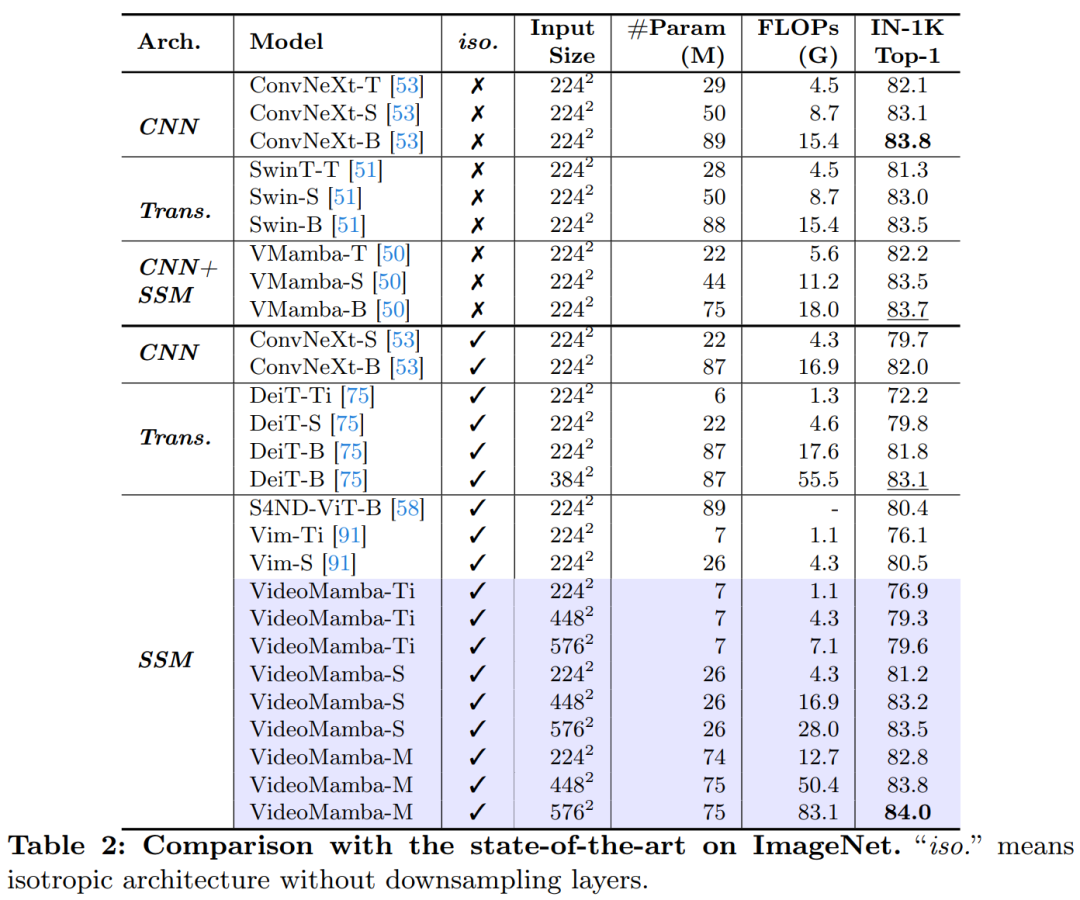
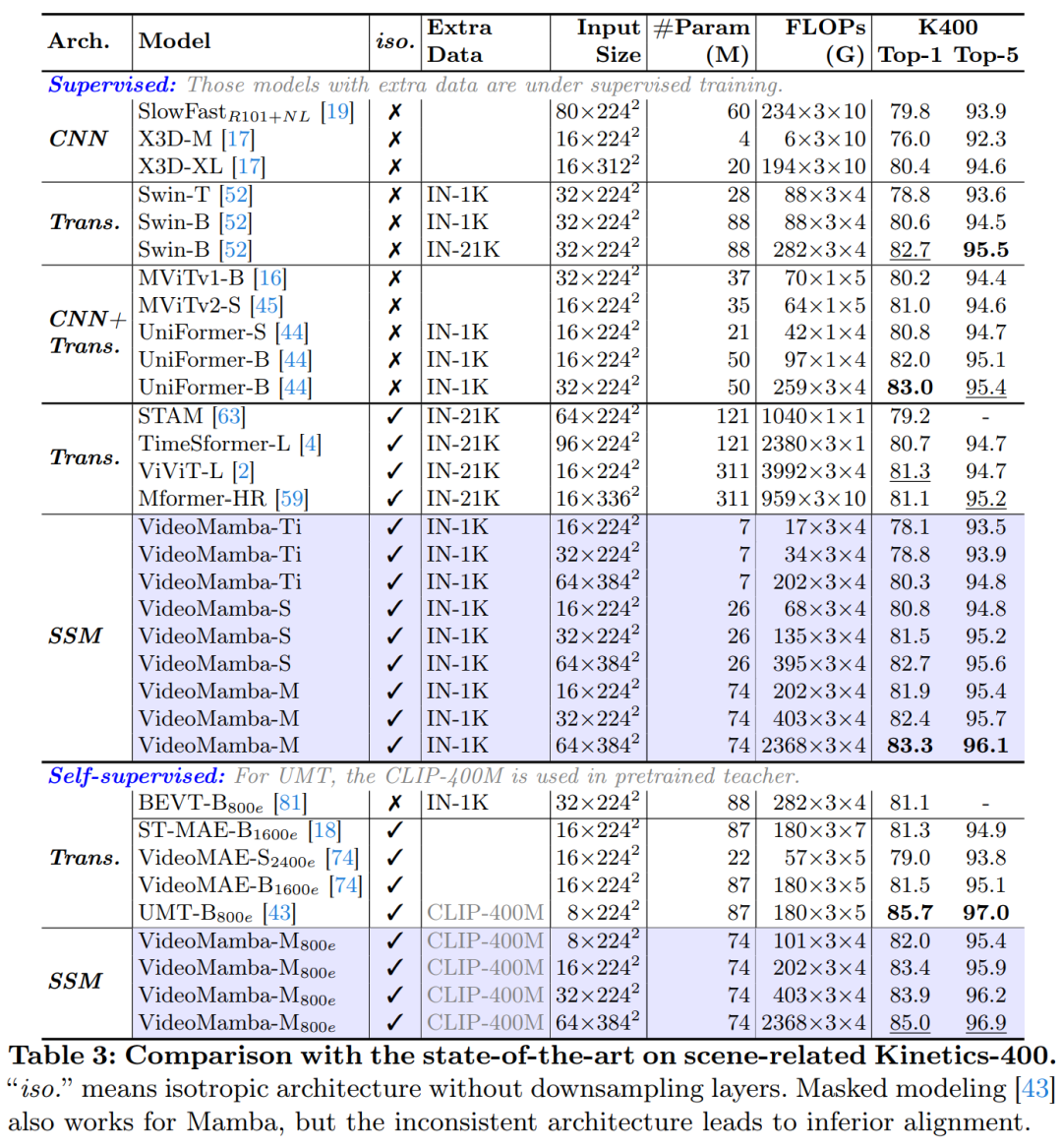
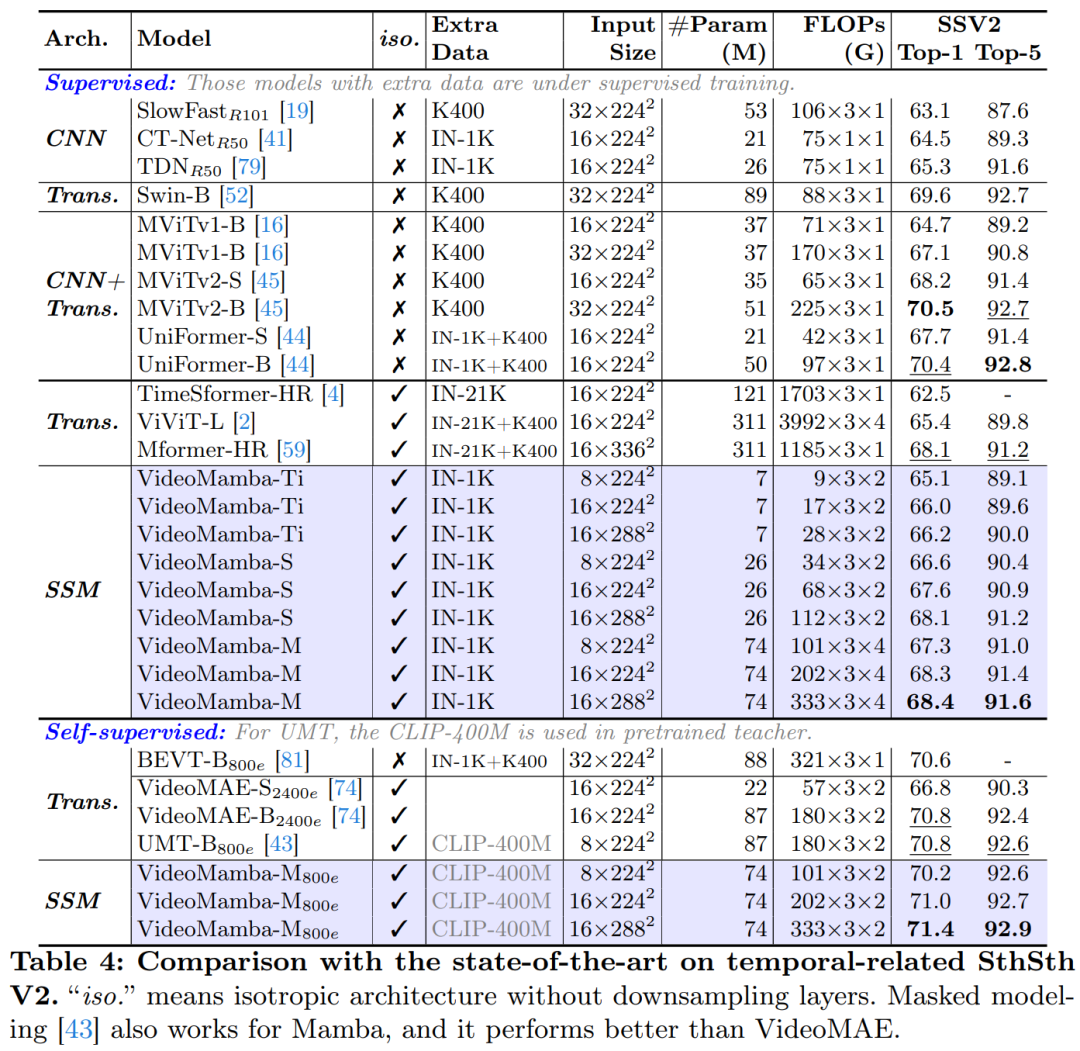
Tables 3 and 4 list results on short-term video datasets. (a) Supervised Learning: Compared to pure attention methods, the SSM-based VideoMamba-M gains a significant advantage, outperforming ViViT-L by +2.0% on the scene-related K400 and +3.0% on the time-related Sth-SthV2 datasets. This improvement is accompanied by significantly reduced computational demands and less pre-training data. The results of VideoMamba-M are on par with the SOTA UniFormer, which cleverly integrates convolution with attention in a non-isotropic structure. (b) Self-supervised Learning: Under masked pre-training, VideoMamba’s performance surpasses VideoMAE, known for its fine-grained action skills. This achievement highlights the potential of the pure SSM-based model proposed in this article to understand short-term videos efficiently and effectively, emphasizing its applicability to both supervised and self-supervised learning paradigms.
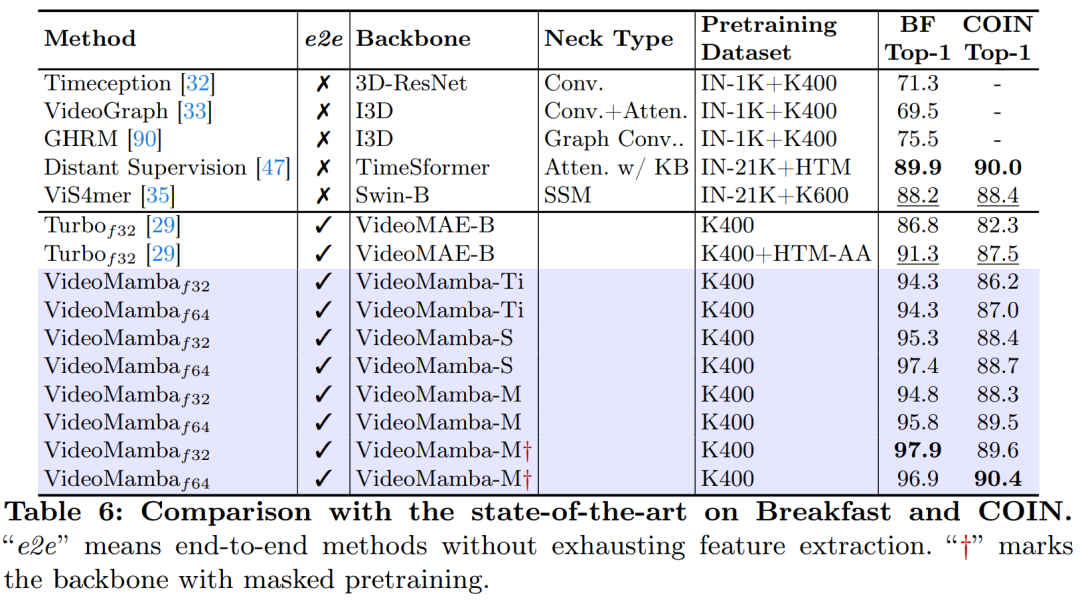
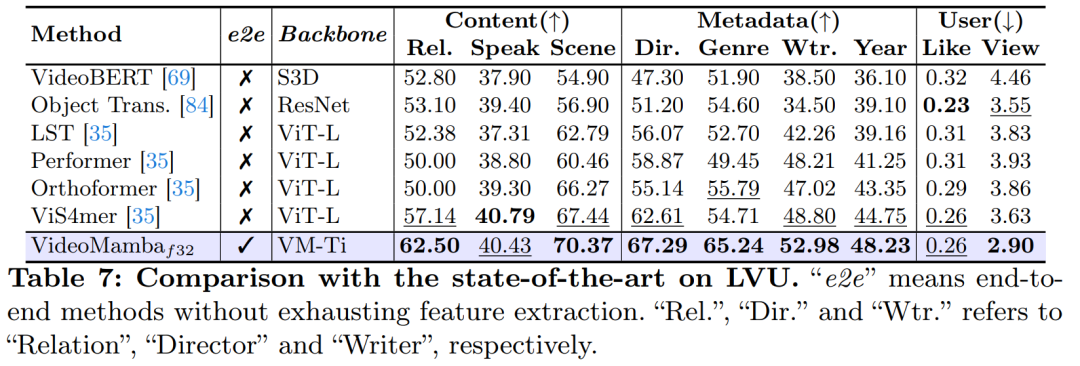
As shown in Figure 1, VideoMamba’s linear complexity makes it highly suitable for end-to-end training with long-duration videos. Comparisons in Tables 6 and 7 highlight VideoMamba’s simplicity and effectiveness relative to traditional feature-based methods in these tasks. It brings significant performance improvements, achieving SOTA results even with smaller model sizes. VideoMamba-Ti shows a remarkable +6.1% increase compared to ViS4mer using Swin-B features and also a +3.0% improvement over Turbo’s multimodal alignment method. Notably, the results emphasize the positive impact of scaling models and frame counts for long-term tasks. In the nine diverse and challenging tasks proposed by LVU, this article fine-tunes VideoMamba-Ti in an end-to-end manner, achieving results comparable to or superior to current SOTA methods. These achievements not only highlight the effectiveness of VideoMamba but also demonstrate its immense potential for future long video understanding.
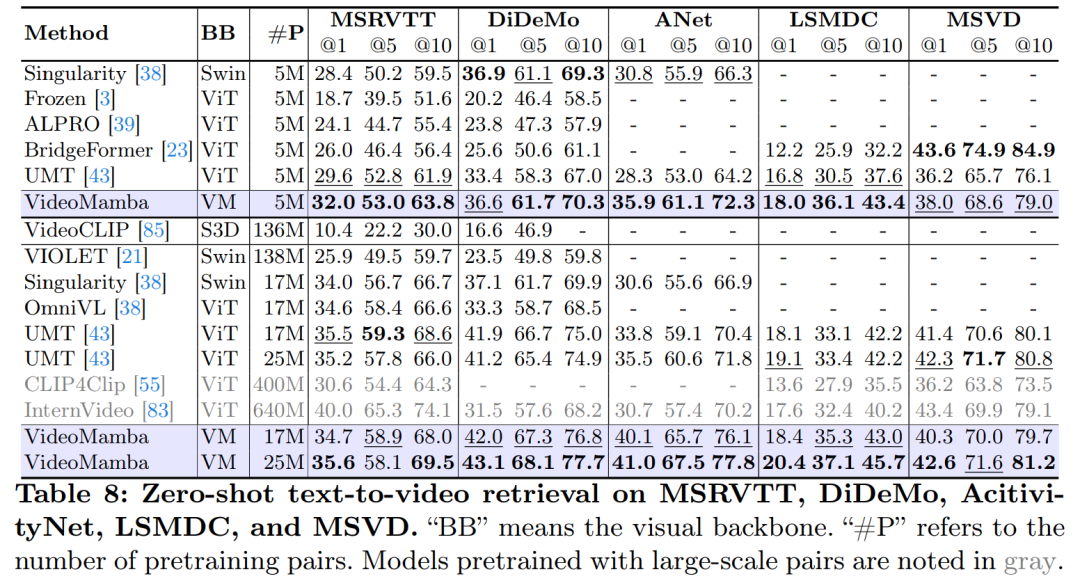
As shown in Table 8, under the same pre-training corpus and similar training strategies, VideoMamba outperforms the ViT-based UMT in zero-shot video retrieval performance. This highlights Mamba’s comparable efficiency and scalability in handling multimodal video tasks compared to ViT. Notably, for datasets with longer video lengths (e.g., ANet and DiDeMo) and more complex scenes (e.g., LSMDC), VideoMamba shows significant improvements. This indicates Mamba’s capability in challenging multimodal environments, even in cases requiring cross-modal alignment.
For more research details, please refer to the original paper.

© THE END
For reprints, please contact this public account for authorization
For submissions or inquiries: [email protected]