LSTM + Attention Mechanism is very useful for improving the prediction accuracy of models when processing long sequence data, making it a powerful tool! For example, the MALS-Net model combines these two elements, achieving a significant accuracy improvement of 47.7% in predictions.
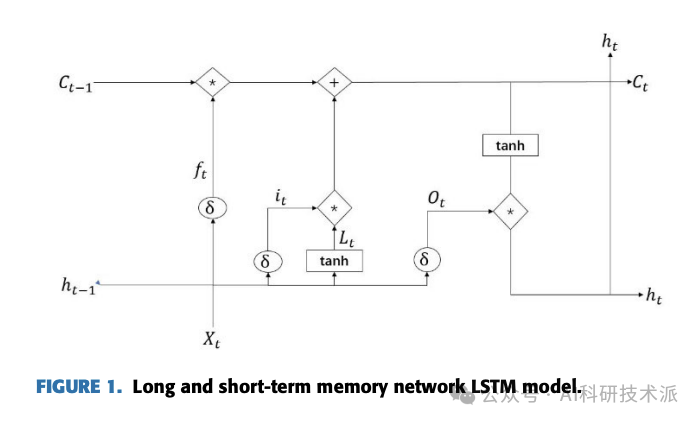
The main advantage lies in LSTM’s ability to learn long-term dependencies, making it suitable for processing and predicting important events in time series that have very long intervals and delays. The attention mechanism allows the model to focus differently on various parts of the input data. The combination of the two enables the model to focus more on key information, thereby improving performance. Common integration approaches include: introducing a self-attention mechanism at each time step of LSTM; LSTM + multi-head self-attention mechanism; using a fully connected layer to calculate attention weights at each time step of LSTM.
To give everyone a comprehensive understanding of these methods and to apply them to their own papers, I have also prepared 9 innovative methods for everyone to explore.
Scan the QR code below and reply with 「ALSTM」
to get all the papers and project code for free.

Paper Sharing
1. Time Series Prediction Based on LSTM-Attention-LSTM Model
「Paper Summary」
Time series prediction utilizes past data to forecast future information, which is significant in many applications. Existing time series prediction methods still face issues like low accuracy when dealing with non-stationary multivariate time series data. To address the shortcomings of existing methods, this paper proposes a new time series prediction model called LSTM-attention-LSTM. This model uses two LSTM models as an encoder and decoder, introducing an attention mechanism between them. It has two notable features: it computes the relationships between sequence data using the attention mechanism, overcoming the limitations of the encoder-decoder model that cannot obtain sufficiently long input sequences; secondly, it is suitable for long time-step sequence predictions.
「Innovations」
- The model utilizes the attention mechanism to compute the relationships between sequence data, overcoming the limitation of the encoder-decoder model in obtaining sufficiently long input sequences;
- It is suitable for long time-step sequence predictions;
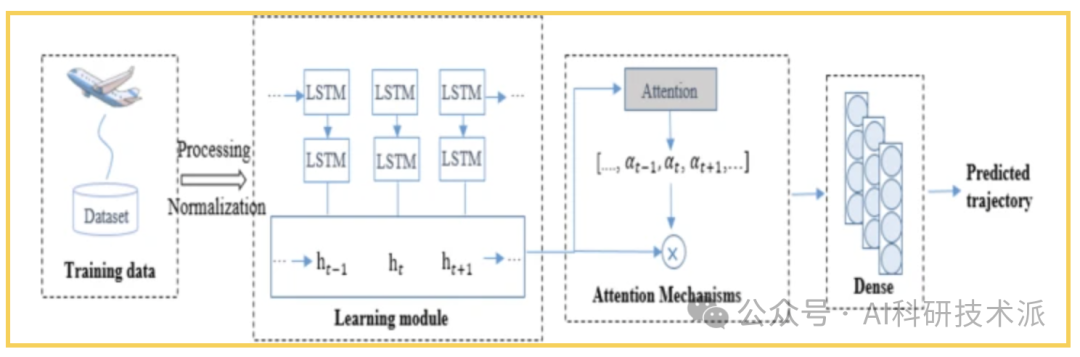
2. Attention-LSTM Based Prediction Model for Aircraft 4-D Trajectory
「Paper Summary」
To accelerate the intelligent operation of air traffic control and promote the development of intelligent ATM systems, improving the accuracy of trajectory prediction has become very important. However, due to issues like sparse flight trajectories and varying flight altitudes, enhancing the accuracy of trajectory prediction is challenging. To address this problem, this paper proposes an attention-LSTM trajectory prediction model. This model uses Long Short-Term Memory (LSTM) networks to extract the time series features of trajectories and employs an attention mechanism to extract important factors affecting the changes at the current point, thereby improving the accuracy of trajectory prediction.
「Innovations」
- Building on time series prediction, it focuses more on the influencing factors between data, further extracting data features, and using the attention mechanism to enhance the impact of specific data while reducing the influence of unnecessary factors, thus improving the accuracy of aircraft 4D trajectory prediction;
- This experiment considers not only 4D aircraft trajectory data but also speed and yaw angle to enhance data diversity and predictability;
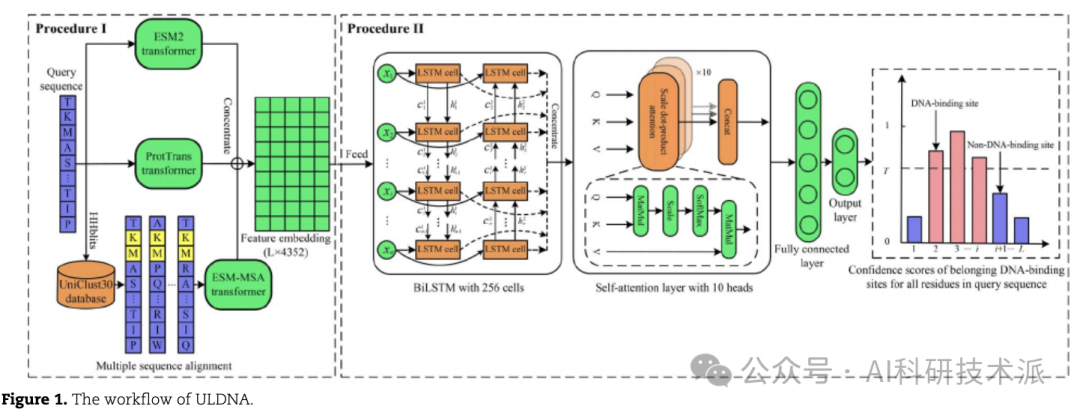
3. ULDNA: Integrating Unsupervised Multi-Source Language Models with LSTM-Attention Network for High-Accuracy Protein–DNA Binding Site Prediction
「Paper Summary」
This paper proposes a new deep learning method called ULDNA, which embeds LSTM-attention architecture with three unsupervised language models pre-trained on multiple large-scale sequence databases to predict DNA binding sites from protein sequences. Using annotations of DNA binding sites from the protein database, systematic tests were conducted on 1287 proteins. Experimental results show that ULDNA significantly improves the accuracy of DNA binding site prediction compared to the current state-of-the-art methods. Detailed data analysis indicates that ULDNA’s main advantage lies in utilizing three pre-trained transformer language models, which can extract complementary DNA binding patterns hidden in feature embeddings based on evolutionary diversity at the residual level. Meanwhile, the designed LSTM-attention network can further enhance the correlation between evolutionary diversity and protein-DNA interactions.
「Innovations」
- This study designs a novel deep learning model ULDNA by integrating three unsupervised protein language models from multiple database sources with the designed LSTM-attention network;
- ULDNA’s main advantage is its use of three transformer language models, which can effectively capture the evolutionary diversity highly correlated with complex DNA binding patterns;
Scan the QR code below and reply with 「ALSTM」
to get all the papers and project code for free.

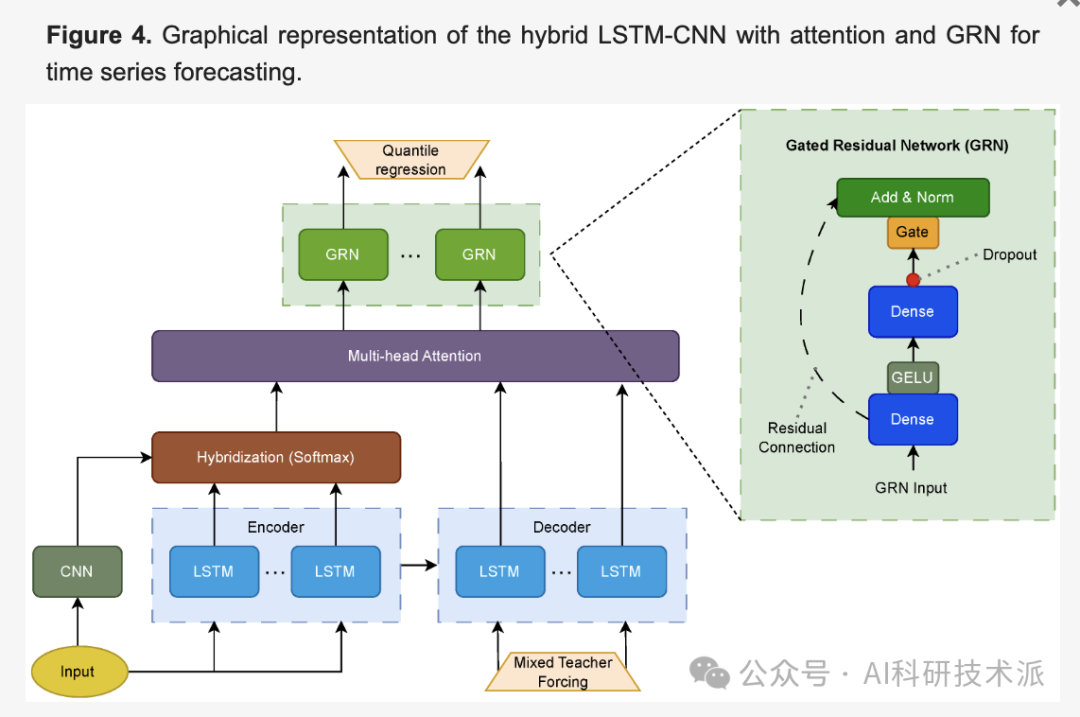
4. Machine Fault Detection Using a Hybrid CNN-LSTM Attention-Based Model
「Paper Summary」
This paper addresses the problem of predicting electrical equipment failures through time series analysis. The time series data comes from sensors installed on electrical equipment (motors) that measure vibration changes on three axes (X, Y, and Z). A hybrid convolutional neural network (CNN) with Long Short-Term Memory (LSTM) architecture is trained using this dataset. By applying quantile regression at the network’s output, this method aims to manage uncertainty in the data. The application of the hybrid CNN-LSTM attention model, combined with quantile regression to capture uncertainty, achieves better results than traditional reference models. These results can assist companies in optimizing their maintenance schedules and improving the overall performance of their electrical equipment.
「Innovations」
- The model architecture is based on an LSTM-CNN hybrid architecture with an attention mechanism and gated residual networks (GRN);
- Using wavelet transforms and Savitzky-Golay filters helps reduce noise in the signals and extract relevant features for analysis;
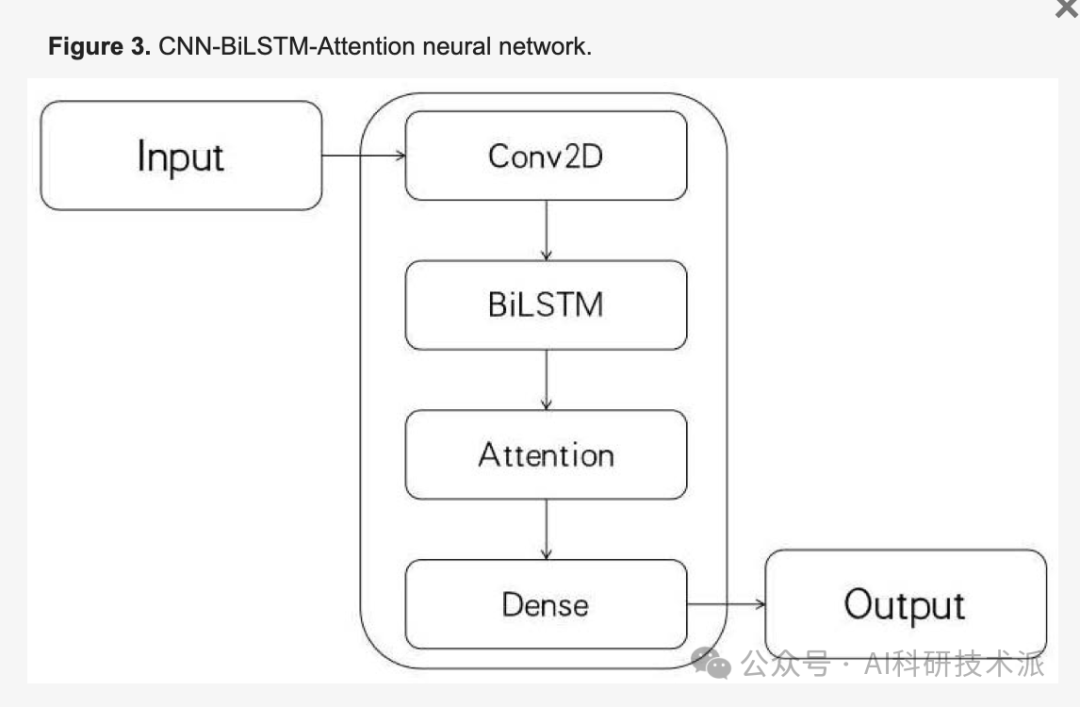
5. Stock Price Prediction Using CNN-BiLSTM-Attention Model
「Paper Summary」
This paper presents a model based on Convolutional Neural Networks (CNN), Bidirectional Long Short-Term Memory (BiLSTM) networks, and attention mechanisms to improve the accuracy of stock price and index predictions. First, Convolutional Neural Networks (CNN) and Bidirectional Long Short-Term Memory (BiLSTM) networks are used to extract temporal features from sequence data. Then, the attention mechanism is introduced to automatically adapt the weight distribution of information features; finally, a fully connected layer outputs the final prediction results. The proposed method was initially used to predict the price of the Chinese stock index – CSI300, and the results showed higher accuracy than three other methods – LSTM, CNN-LSTM, and CNN-LSTM-Attention.
「Innovations」
- Using CNN to extract the nonlinear local features of stock data;
- Using BiLSTM to remove the bidirectional temporal features of sequence data;
- The attention mechanism reduces the impact of redundant information on the accuracy of stock price predictions by automatically adapting weight distribution, assigning greater weight to more important feature components extracted by the BiLSTM layer;
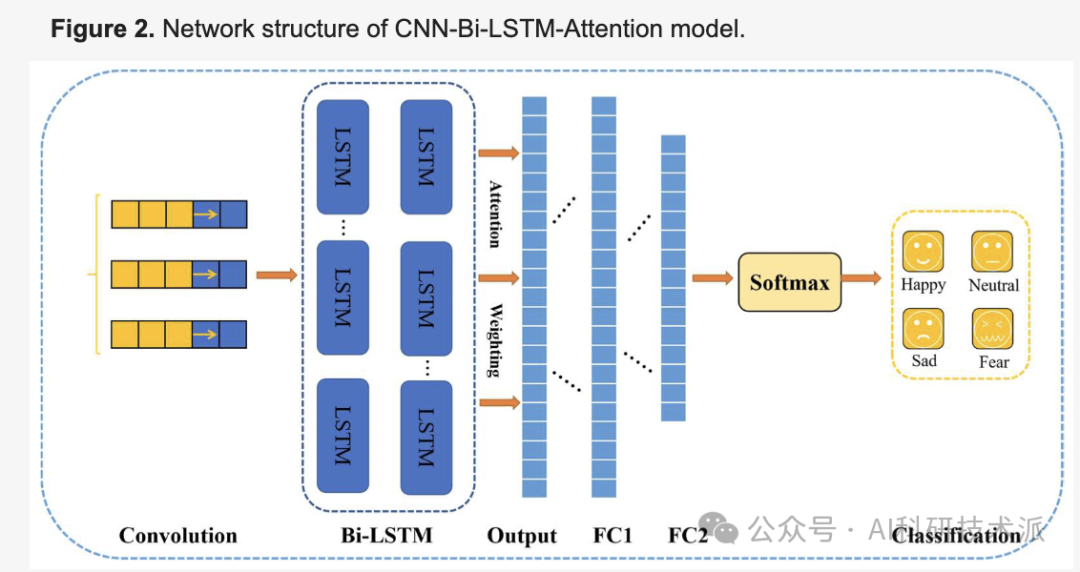
6. A Model for EEG-Based Emotion Recognition: CNN-Bi-LSTM with Attention Mechanism
「Paper Summary」
This paper proposes a CNN-Bi-LSTM-Attention model for automatically extracting features from EEG signals and classifying emotions. The raw EEG data is used as input, and CNN and Bi-LSTM networks are employed for feature extraction and fusion, followed by a layer of attention mechanism to balance the weights of electrode channels. Finally, the EEG signals are classified to distinguish different types of emotions. Experiments on EEG emotion classification were conducted on the SEED dataset to evaluate the performance of the proposed model. The experimental results indicate that the proposed method can effectively classify EEG emotions. The method was evaluated on two different classification tasks with three and four target classes.
「Innovations」
- First, features from EEG data are extracted using convolution, followed by processing through Bi-LSTM;
- Finally, the attention mechanism layer automatically captures the most important features from the entire EEG recording;
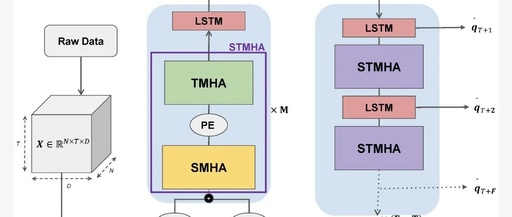
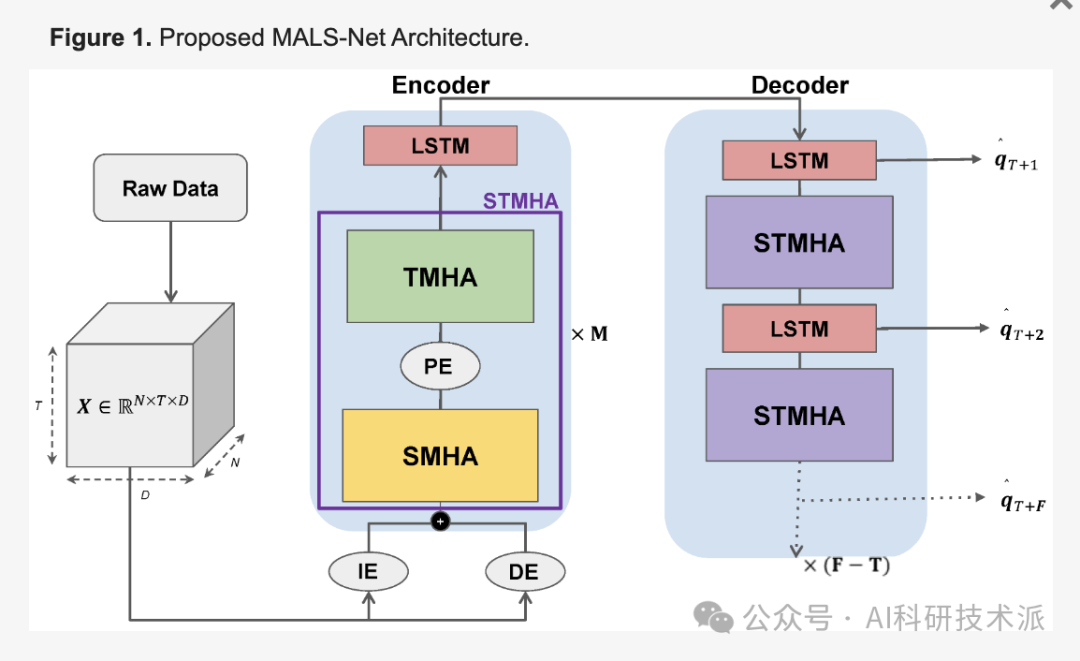
7. MALS-Net: A Multi-Head Attention-Based LSTM Sequence-to-Sequence Network for Socio-Temporal Interaction Modelling and Trajectory Prediction
「Paper Summary」
This paper presents MALS-Net, a multi-head attention-based LSTM sequence-to-sequence model that utilizes the mechanism of Transformers and avoids cumulative errors through an attention-based LSTM encoder-decoder architecture. Subsequently, the proposed model was evaluated on the BLVD dataset (a more practical dataset) without overfitting issues. Compared to other related methods, the proposed model demonstrated state-of-the-art performance in both short-term and long-term predictions.
「Innovations」
- It uses a continuous spatiotemporal multi-head attention (TMHA) mechanism to focus attention on social and temporal interactions and encode input data;
- A similar MHA-based LSTM decoding step is proposed to extract predicted social-temporal interactions in continuous decoding steps;
Scan the QR code below and reply with 「ALSTM」
to get all the papers and project code for free.
