Do Time Series Forecasts Really Need Deep Learning Models?
Introduction Time series forecasting is a common task in machine learning with very wide applications, such as predicting energy consumption, traffic flow, and air quality. Traditional time series forecasting models often rely on rolling averages, vector autoregression, and autoregressive integrated moving averages. On the other hand, recent studies have proposed deep learning and matrix factorization models to tackle time series forecasting problems and have achieved more competitive performance, although these models tend to be overly complex.Recently, several scholars from Germany published an interesting comparative review article on arXiv, comparing GBRT with various novel models presented at major conferences, and they released their code and results.In this article, we will briefly share the key points from this paper for researchers and developers to reference.
Time series forecasting is a common task in machine learning with very wide applications, such as predicting energy consumption, traffic flow, and air quality. Traditional time series forecasting models often rely on rolling averages, vector autoregression, and autoregressive integrated moving averages. On the other hand, recent studies have proposed deep learning and matrix factorization models to tackle time series forecasting problems and have achieved more competitive performance, although these models tend to be overly complex.Recently, several scholars from Germany published an interesting comparative review article on arXiv, comparing GBRT with various novel models presented at major conferences, and they released their code and results.In this article, we will briefly share the key points from this paper for researchers and developers to reference.

Paper Address: https://arxiv.org/abs/2101.02118
Paper Source Code: https://github.com/Daniela-Shereen/GBRT-for-TSF
Existing Methods
Time series forecasting problems can be divided into two categories:
(1) Univariate time series forecasting problems, where the data has only one channel, and the predicted values consist solely of the target channel vector sequence; (2) Multivariate time series forecasting problems, where the predictors consist of vector pairs (x, y), but the task is to predict only a single target channel.
ARIMA Model (Autoregressive Integrated Moving Average model), also known as the integrated moving average autoregressive model (moving can also be referred to as sliding), is one of the methods for time series forecasting analysis.
Time Regularized Matrix Factorization (TRMF) model is a highly scalable method based on matrix factorization, as it can model the global structure in the data. As one of the earlier methods in this study, this model is limited to capturing linear dependencies in time series data but still shows very competitive results.
Long Short-Term Time Series Network (LSTNet) emphasizes local multivariate patterns modeled by convolutional layers, as well as long-term dependencies captured by recurrent network structures.
Attention-Based Dual-Stage RNN (DARNN) first passes the model input through an input attention mechanism and then uses an encoder-decoder model equipped with an additional temporal attention mechanism.
Deep Global Local Forecaster (DeepGlo) is based on a global matrix factorization structure, which is normalized by a temporal convolutional network. This model includes additional channels from dates and times.
Temporal Fusion Transformer model is the latest DNN method in this study, combining recurrent layers for local processing with typical self-attention layers of transformers that capture long-term dependencies in the data. This model can dynamically focus on relevant features during the learning process and suppress features deemed irrelevant through gating mechanisms.
DeepAR Model is an autoregressive probabilistic RNN model that estimates parameter distributions from time series with the help of additional temporal and categorical covariates.
Deep State Space Model (DeepState) is a probabilistic generative model that learns parameterized linear state space models using RNNs.
Deep Air Quality Forecasting Framework (DAQFF) includes a two-stage feature representation; data is predicted through three one-dimensional convolutional layers, followed by two bidirectional LSTM layers and a secondary linear layer.
Model Comparison
The authors of this paper attempt to answer the question: how does a simple yet well-configured GBRT model compare with the results of state-of-the-art deep learning time series forecasting methods?
Similar to deep neural network (DNN) models, the authors of this paper transformed the time series forecasting task into a window-based regression problem and designed features for the input and output structure of the GBRT model. For each training window, target values are connected with external features, and then flattened to form an input instance for a multi-output GBRT model. The authors conducted a comparative study on 9 datasets using 8 state-of-the-art deep learning models, all of which have been published in major conferences over the past few years. The comparison results show that the window-based input transformation elevates the performance of a simple GBRT model to exceed that of all the state-of-the-art DNN models evaluated in this paper.
01
GBRT Algorithm Design

The GBRT training method proposed in this paper mainly includes two modifications:
-
Transforming window inputs into one-dimensional vectors. It is important to note that covariates only use the covariates from the last time step. The experimental section demonstrates that this approach leads to better model performance compared to using all covariates from the window.
-
Wrapping the predictors as a MultiOutputRegressor that supports multiple outputs. This setup results in the target variables within the prediction range being independently predicted, and the model cannot benefit from the potential relationships between them. However, the GBRT input setting based on window data not only transforms the prediction problem into a regression task but also captures the autocorrelation effects in the target variables, compensating for the drawbacks of independent multi-output predictions.
Below is the training loss function:
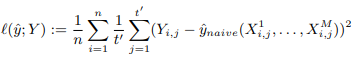
Experimental Results
01
Univariate Time Series Forecasting
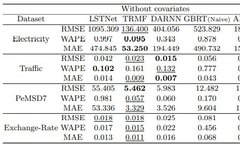
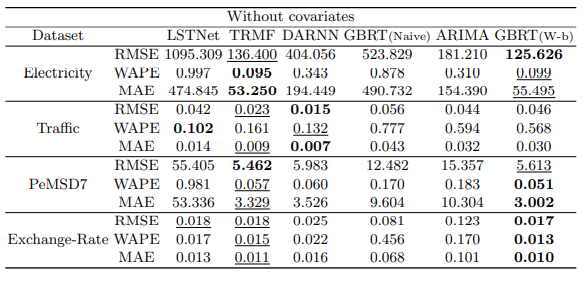
No covariates
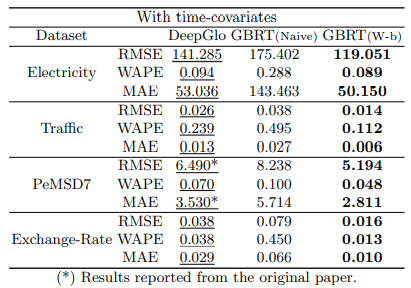
With covariates
02
Deep Learning Model Comparison
vs. LSTNet
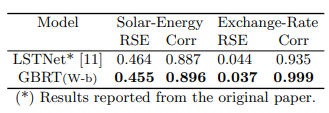
vs. DeepAR, DeepState, TFT
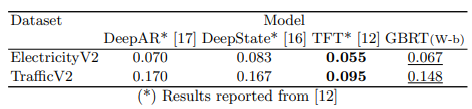
03
Multivariate Time Series Forecasting
vs. DARNN
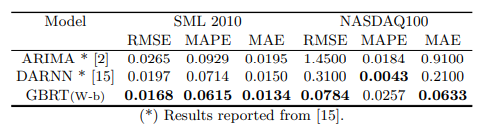
vs. DNNs
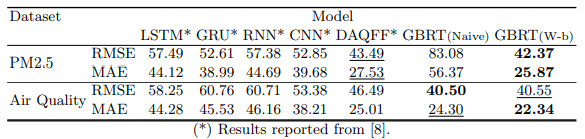
Summary and Outlook
This paper reproduces some recent works in deep learning for time series forecasting and compares them with GBRT across various datasets. The experimental results demonstrate that while GBRT is conceptually simple, it can surpass state-of-the-art DNN models through effective feature engineering of the input and output structures of GBRT. The authors propose that simple machine learning baseline methods should not be overlooked and that caution should be exercised in configuring them to better suit the task, which may yield significant improvements.
Thoughts:
-
Machine learning methods generally include feature engineering, model architecture, and loss functions. The most important are feature engineering and loss functions, which define where to learn and what to learn. When optimizing a method, these two aspects cannot be overlooked. Under the correct conditions of feature engineering and loss functions, innovations in model architecture are often very difficult and yield limited improvements.
-
Directly wrapping the predictor as a MultiOutputRegressor that supports multiple outputs, the input setting of window data can somewhat compensate for the drawbacks of independent multi-output predictions, but the constraints are not very strong. It may be worth considering adding stronger constraints to improve performance.
Editor / Zhang Zhihong
Reviewer / Fan Ruiqiang
Rechecker / Zhang Zhihong
Click below
Follow us
Read the original text