
Selected from arXiv
Authors: Andrea Banino et al.
Compiled by Machine Heart
Editors: Chen Ping, Du Wei
Researchers from DeepMind proposed the CoBERL agent for reinforcement learning, which combines a new contrastive loss with a hybrid LSTM-transformer architecture to improve data processing efficiency. Experiments show that CoBERL can continuously improve performance across the entire Atari suite, a set of control tasks, and challenging 3D environments.
In recent years, multi-agent reinforcement learning has made groundbreaking progress, such as DeepMind’s AlphaStar defeating professional StarCraft II players, surpassing 99.8% of human players; OpenAI Five repeatedly defeating world champion teams in DOTA2, becoming the first AI system to defeat champions in esports competitions.However, many reinforcement learning (RL) agents require extensive experimentation to solve tasks.Recently, researchers from DeepMind proposed the CoBERL (Contrastive BERT for RL) agent, which combines a new contrastive loss and a hybrid LSTM-transformer architecture to enhance data processing efficiency. CoBERL enables efficient and robust learning using pixel-level information from a broader domain.Specifically, the researchers employed bidirectional masked prediction and combined it with recent contrastive methods to generalize better representations of transformers in RL, without the need for manual data augmentation. Experiments indicate that CoBERL can continuously improve performance across the entire Atari suite, a set of control tasks, and challenging 3D environments.

Paper link: https://arxiv.org/pdf/2107.05431.pdfMethod IntroductionTo address the data efficiency issue in deep reinforcement learning, the researchers proposed two modifications to current studies:
-
First, they proposed a new representation learning objective aimed at learning better representations by enhancing the self-attention consistency in masked input prediction;
-
Secondly, they proposed an architectural improvement that combines the advantages of LSTM and transformer.
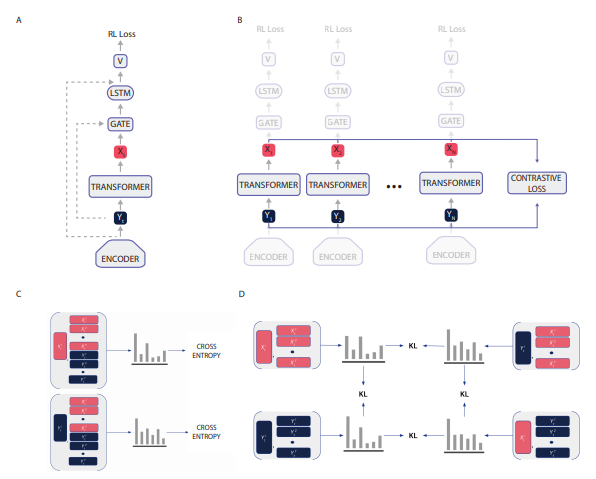
Overall architecture diagram of CoBERL.Representation LearningThe researchers combined BERT with contrastive learning. Based on the BERT method, this study integrates the bidirectional processing mechanism of transformers with the masked prediction setup. The bidirectional processing mechanism allows the agent to understand the context of specific states according to the temporal environment. On the other hand, the predicted inputs at the masked positions mitigate the issues of relevant inputs by reducing the probability of predicting subsequent time steps.The researchers also employed contrastive learning. While many contrastive losses (e.g., SimCLR) rely on data augmentation to create comparable data groupings, this study does not require manual data augmentation to construct proxy tasks. Instead, it relies on the sequential nature of input data to create the necessary groupings of similarities and differences required for contrastive learning, without solely depending on data augmentation from image observations (such as cropping and pixel variations). For the contrastive loss, the researchers used RELIC, which is also adaptable to the temporal domain; they created data groupings by aligning GTrXL transformer inputs and outputs and used RELIC as KL regularization to improve the performance of the employed methods, such as SimCLR in image classification and Atari in RL.CoBERL ArchitectureIn natural language processing and computer vision tasks, transformers are very effective in connecting long-range data dependencies, but in RL settings, transformers are difficult to train and prone to overfitting. In contrast, LSTMs have proven very useful in RL. Although LSTMs do not capture long-range dependencies well, they can efficiently capture short-range dependencies.This study proposed a simple yet powerful architectural change:an LSTM layer was added on top of GTrXL, with an additional gated residual connection between the LSTM and GTrXL, modulated by the input of GTrXL. Additionally, this architecture includes a skip connection from the transformer input to the LSTM output. More specifically, the output of the encoder network at time t, Y_t, can be defined by the following equation:
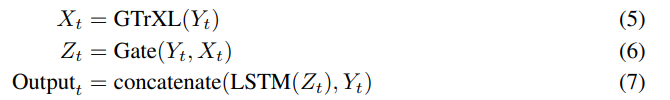
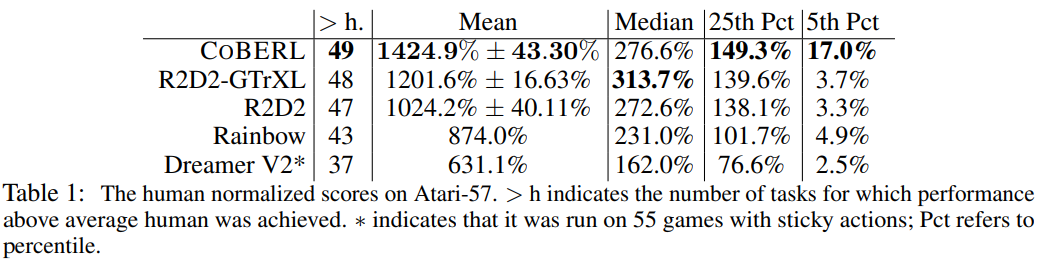
These modules are complementary because transformers do not have recent biases, while the biases of LSTMs can represent recent inputs—the Gate in equation 6 allows mixing of encoder representations and transformer outputs. This memory architecture is independent of the choice of RL mechanisms, and the researchers evaluated this architecture in both on-policy and off-policy settings. For the on-policy setting, this study used V-MPO as the RL algorithm. V-MPO uses the target distribution for policy updates and shifts parameters partially toward that target under KL constraints. For the off-policy setting, the researchers used R2D2.R2D2 Agent: R2D2 (Recurrent Replay Distributed DQN) demonstrates how to adjust replay and RL learning objectives to suit agents with recurrent architectures. Given its competitive performance on Atari-57 and DMLab-30, the researchers implemented the CoBERL architecture in the context of R2D2. They effectively replaced LSTM with a gated transformer and added a contrastive representation learning loss. Thus, through R2D2 and the benefits of distributed experience collection, the recurrent agent’s state is stored in the replay buffer and “burned in” during training with a part of the replay sequence unfolded.V-MPO Agent: Given V-MPO’s strong performance on DMLab-30, especially when combined with the GTrXL architecture as a key component of CoBERL, this study used V-MPO and DMLab30 to demonstrate the use of CoBERL with on-policy algorithms. V-MPO is an on-policy adaptive algorithm based on Maximum a Posteriori Policy Optimization (MPO). To avoid the high variance often encountered in policy gradient methods, V-MPO uses the target distribution for policy updates, under sample-based KL constraints, calculating gradients that shift parameters partially toward the target, which is also subject to KL constraints. Unlike MPO, V-MPO uses a learnable state-value function V(s) instead of a state-action value function.Experimental DetailsThe researchers demonstrated that 1) CoBERL can improve performance across a broader range of environments and tasks, and 2) maximizing performance requires all components. Experiments showed CoBERL’s performance in Atari57, DeepMind Control Suite, and DMLab-30. Table 1 presents the results of different agents currently available. The results indicate that CoBERL performs above human average in most games and significantly outperforms the average performance of similar algorithms. The median of R2D2-GTrXL is slightly better than CoBERL, suggesting that R2D2-GTrXL is indeed a powerful variant on Atari. The researchers also observed that when examining the “25th Pct and 5th Pct,” the performance differences of CoBERL and other algorithms were larger, indicating that CoBERL enhances data efficiency.
To test CoBERL in challenging 3D environments, this study ran it in DmLab30, as shown in Figure 2:
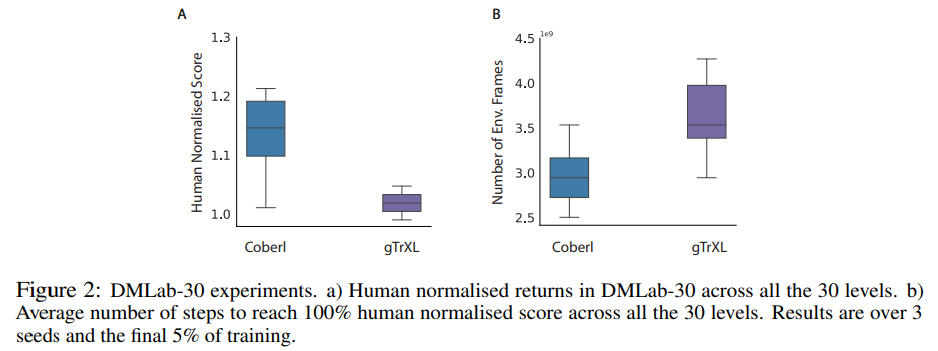
Table 3’s results indicate that compared to CoBERL without contrastive loss, contrastive loss can significantly improve performance in Atari and DMLab-30. Furthermore, in challenging environments like DmLab-30, CoBERL without additional loss still outperforms baseline methods.
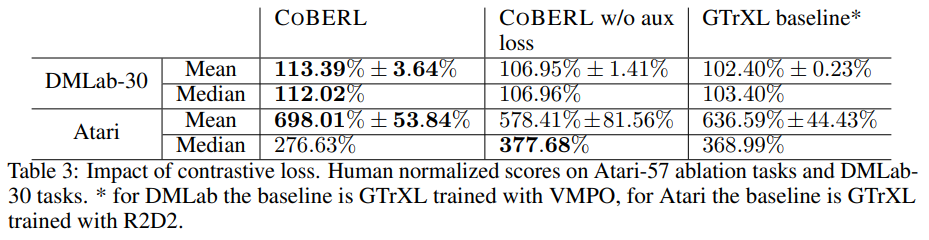
Table 4 compares the proposed contrastive loss with SimCLR and CURL: the results show that this contrastive loss, while simpler than SimCLR and CURL, performs better.

Table 5 shows the effects of removing LSTM from CoBERL (as in the w/o LSTM column) and removing the gate and its related skip connection (as in the w/o Gate column). In both cases, CoBERL’s performance significantly decreased, indicating that CoBERL requires both components (LSTM and Gate).
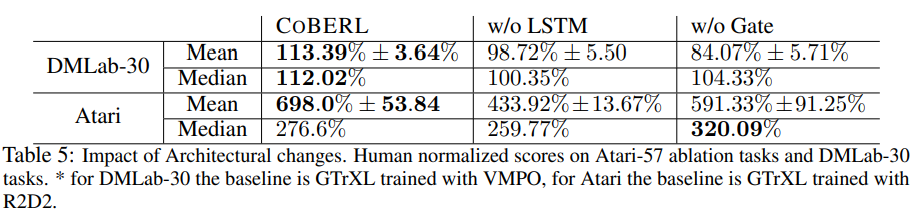
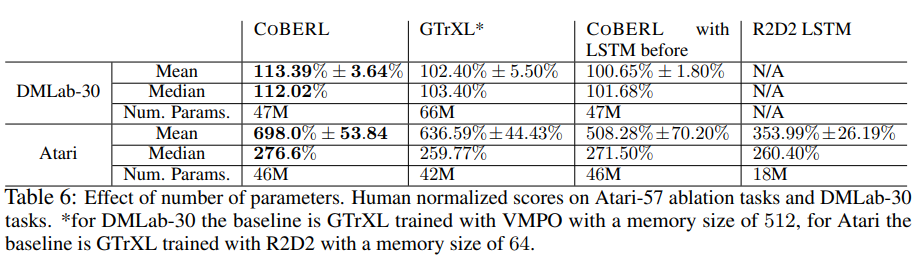
Table 6 compares the models based on the number of parameters. For Atari, CoBERL adds a limited number of parameters on top of the R2D2(GTrXL) baseline; however, CoBERL still produces a significant performance improvement. The study also attempted to move LSTM before the transformer module; in this case, the contrastive loss representation was taken from before LSTM.
Discussing the Future Development of ML with Andrew Ng at the 2021 Amazon Cloud Technology China Summit
The “second stop” of the 2021 Amazon Cloud Technology China Summit will be held online from September 9 to September 14.For AI developers, the “Artificial Intelligence and Machine Learning Summit” on September 14 is the most noteworthy event.
On that day, Dr. Swami Sivasubramanian, Vice President of Amazon Cloud Technology AI and Machine Learning, will engage in a “fireside chat” with Dr. Andrew Ng, a renowned scholar in the AI field and founder of Landing AI.
Moreover, the “Artificial Intelligence and Machine Learning Summit” will feature four major sub-forums: “Machine Learning Science,” “The Impact of Machine Learning,” “Machine Learning Practice Without Expert Knowledge,” and “How Machine Learning is Implemented,” elaborating on the development of machine learning from multiple aspects, including technical principles, practical applications in real scenarios, and impacts on various industries.
Click to read the original article and register immediately.

© THE END
For reprints, please contact this public account for authorization.
Submissions or inquiries: [email protected]