Author Michael NguyenTranslated by Wang Xiaoxin from Towards Data ScienceProduced by QbitAI | WeChat Official Account
 AI recognizes your voice, answers your questions, and helps you translate foreign languages, all relying on a special type of Recurrent Neural Network (RNN): Long Short-Term Memory Network (LSTM).Recently, there has been a very popular illustrated tutorial abroad about LSTM and its variant GRU (Gated Recurrent Unit). The tutorial first introduces the basic knowledge of these two networks and then explains the internal mechanisms that enable LSTM and GRU to perform well. Of course, through this article, you can also learn some background about these two networks.The author of the illustrated tutorial, Michael Nguyen, is a machine learning engineer specializing in AI voice assistants.Now, let’s learn together~
AI recognizes your voice, answers your questions, and helps you translate foreign languages, all relying on a special type of Recurrent Neural Network (RNN): Long Short-Term Memory Network (LSTM).Recently, there has been a very popular illustrated tutorial abroad about LSTM and its variant GRU (Gated Recurrent Unit). The tutorial first introduces the basic knowledge of these two networks and then explains the internal mechanisms that enable LSTM and GRU to perform well. Of course, through this article, you can also learn some background about these two networks.The author of the illustrated tutorial, Michael Nguyen, is a machine learning engineer specializing in AI voice assistants.Now, let’s learn together~
Short-Term Memory Problem
RNNs are limited by the short-term memory problem. If a sequence is long enough, they find it difficult to transfer information from earlier time steps to later ones. Therefore, if you try to process a piece of text for prediction, RNNs may miss important information right from the start.During backpropagation, there is a vanishing gradient problem in RNNs. The gradient is the value used to update the weights of the neural network, and the vanishing gradient problem refers to the decrease of the gradient during propagation over time. If the gradient value becomes very small, learning will not continue.
△ Gradient Update Rule
Therefore, in RNNs, the network layers that update the gradient slightly will stop learning, usually those are the earlier layers. Because these layers do not learn, RNNs cannot remember what they learned in longer sequences, thus their memory is short-term.For more introduction about RNNs, visit: https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9
Solutions: LSTM and GRU
LSTM and GRU are proposed solutions to overcome the short-term memory problem. They introduce an internal mechanism called “gates” to regulate the flow of information.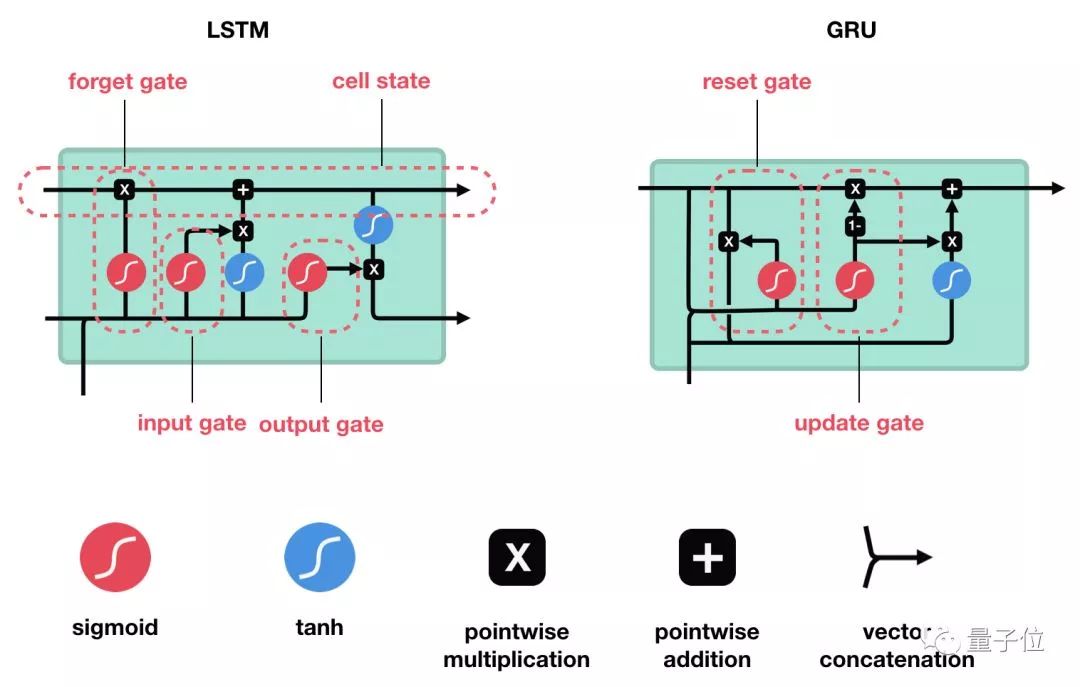 These gate structures can learn which data to retain as important information and which to delete. By doing so, they can transmit relevant information along long chain sequences to make predictions. Almost all state-of-the-art results based on RNNs are achieved through these two networks. LSTM and GRU are frequently used in areas such as speech recognition, speech synthesis, and text generation, and can also be used to generate subtitles for videos.When you finish reading this article, I believe you will have a thorough understanding of the outstanding capabilities of LSTM and GRU in handling long sequences. Below, I will introduce them through intuitive explanations and illustrations while avoiding mathematical calculations as much as possible.
These gate structures can learn which data to retain as important information and which to delete. By doing so, they can transmit relevant information along long chain sequences to make predictions. Almost all state-of-the-art results based on RNNs are achieved through these two networks. LSTM and GRU are frequently used in areas such as speech recognition, speech synthesis, and text generation, and can also be used to generate subtitles for videos.When you finish reading this article, I believe you will have a thorough understanding of the outstanding capabilities of LSTM and GRU in handling long sequences. Below, I will introduce them through intuitive explanations and illustrations while avoiding mathematical calculations as much as possible.
Intuitive Understanding
Let’s start with a thought experiment. When you buy daily necessities online, you usually read product reviews to judge the quality of the product and decide whether to purchase it.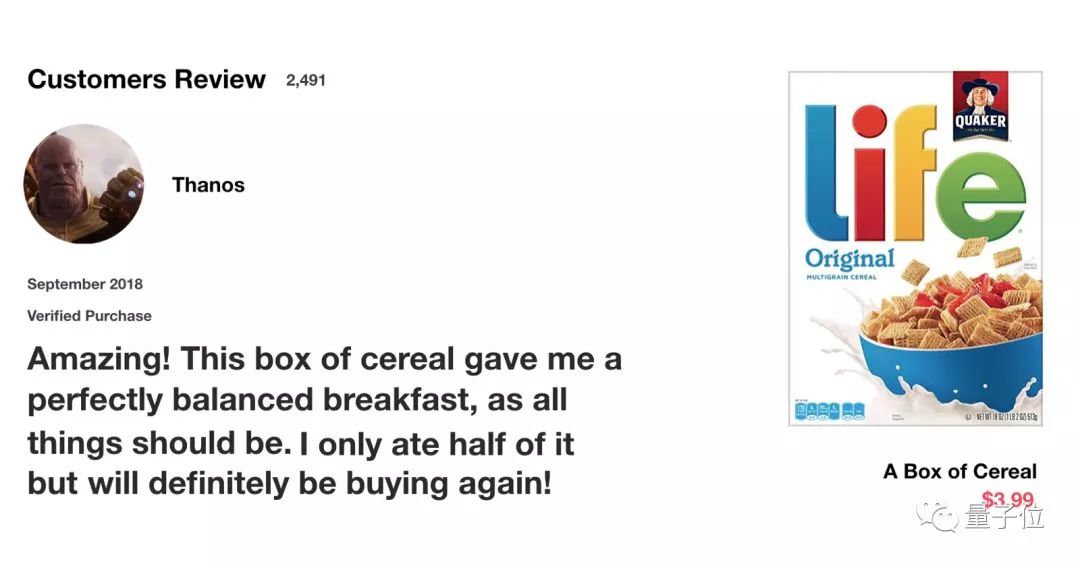 When you look at the reviews, your brain subconsciously only remembers important keywords. You might choose words like “amazing” and “perfectly balanced breakfast,” while not paying much attention to words like “this,” “give,” “all,” “should,” etc. If someone asks you about the review the next day, you might not remember it word for word, but you will recall the main point, such as “I will definitely buy again next time,” while some minor details will naturally fade from memory.
When you look at the reviews, your brain subconsciously only remembers important keywords. You might choose words like “amazing” and “perfectly balanced breakfast,” while not paying much attention to words like “this,” “give,” “all,” “should,” etc. If someone asks you about the review the next day, you might not remember it word for word, but you will recall the main point, such as “I will definitely buy again next time,” while some minor details will naturally fade from memory. In this case, the words you remember determine the quality of the restaurant. This is basically the role of LSTM or GRU, which can learn to retain only relevant information for prediction and forget irrelevant data.
In this case, the words you remember determine the quality of the restaurant. This is basically the role of LSTM or GRU, which can learn to retain only relevant information for prediction and forget irrelevant data.
RNN Review
To understand how LSTM or GRU achieves this, let’s review RNNs. The way RNNs work is as follows: first, words are converted into machine-readable vectors, and then RNNs process the vector sequences one by one.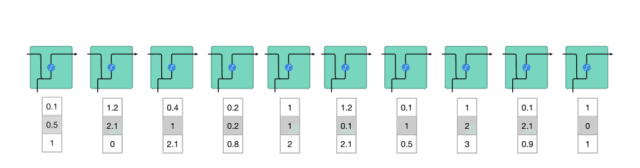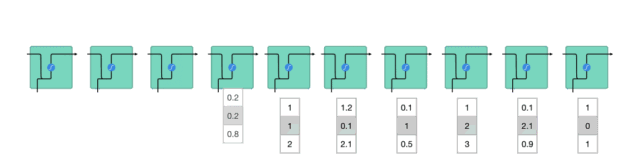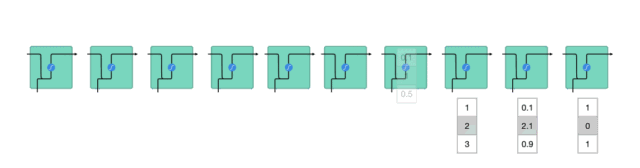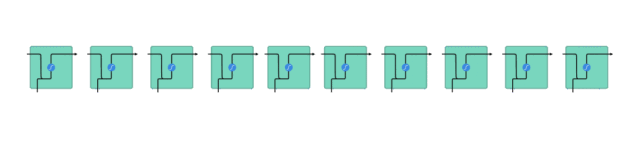
△ Processing Vector Sequences One by One
During processing, it transmits the previous hidden state to the next step in the sequence, where the hidden state acts as the memory of the neural network, containing information about the data processed by the relevant network.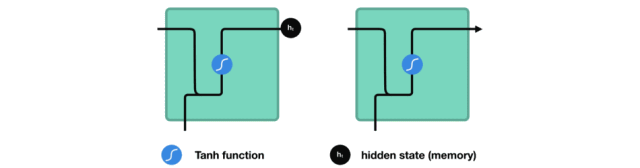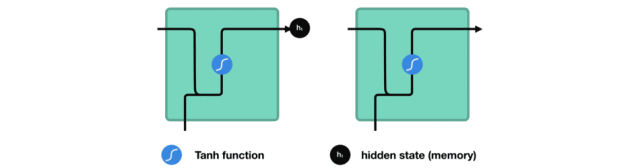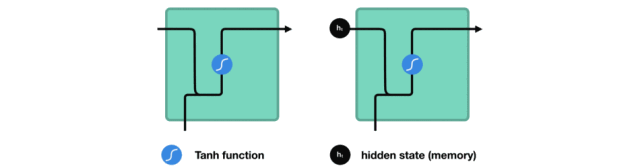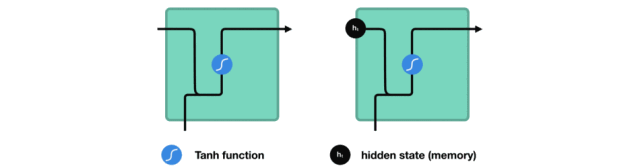
△ Passing the Hidden State to the Next Time Step
Next, let’s introduce how each cell unit in RNN computes the hidden state.First, the input and previous hidden state are combined into a vector, which contains information from the current input and the previous input. This vector is then passed through the activation function Tanh, resulting in a new hidden state or network memory.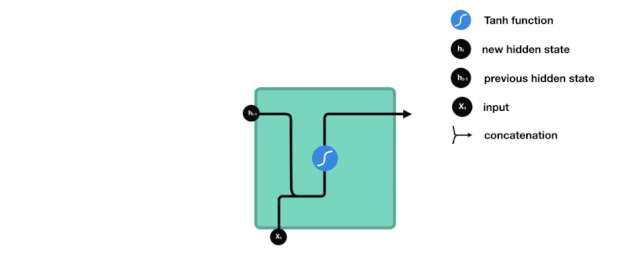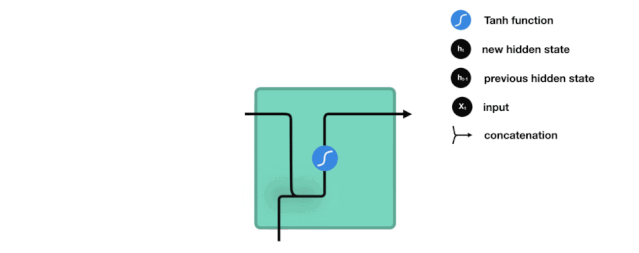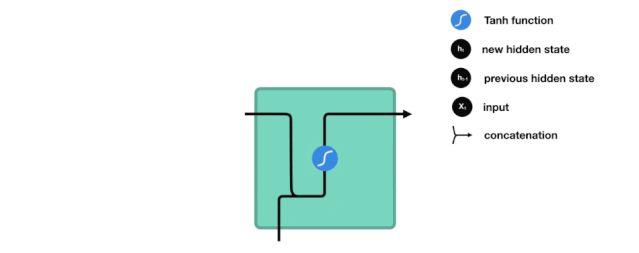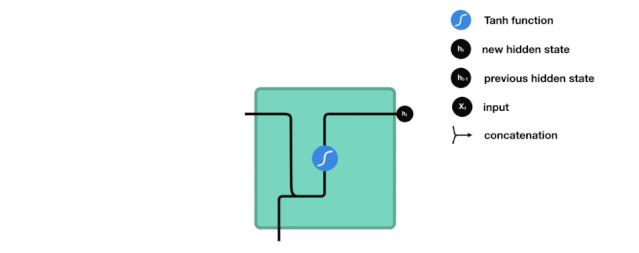
△ RNN Unit
Activation Function Tanh
The activation function Tanh helps regulate the values flowing through the network, and the output of the Tanh function always lies within the range (-1, 1).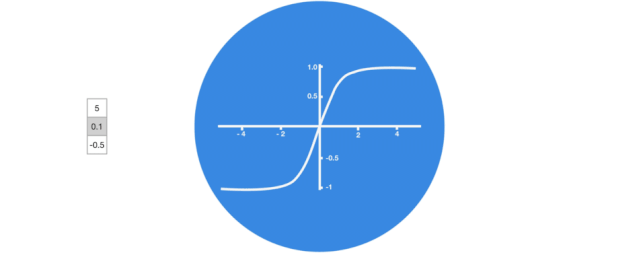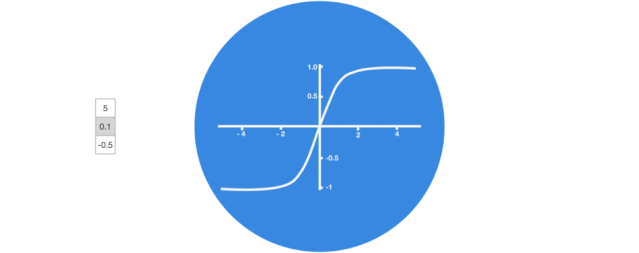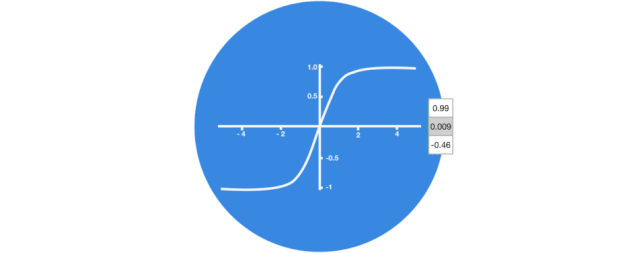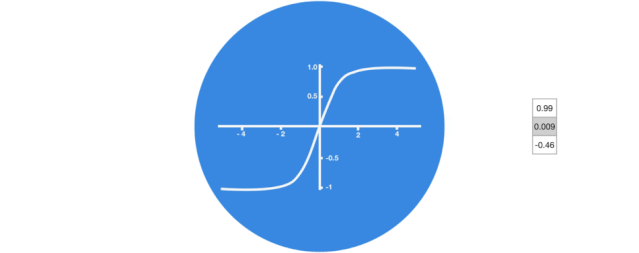 As the vector flows through the neural network, it undergoes many transformations due to various mathematical operations. Therefore, imagine continuously multiplying a value by 3; it will gradually grow larger and become astronomical, making other values seem insignificant.
As the vector flows through the neural network, it undergoes many transformations due to various mathematical operations. Therefore, imagine continuously multiplying a value by 3; it will gradually grow larger and become astronomical, making other values seem insignificant.
△ Vector Transformation Without Tanh Function
The Tanh function keeps the output within the range (-1, 1), thus regulating the neural network output. You can see how these values are maintained within the allowed range of the Tanh function.
△ Vector Transformation With Tanh Function
This is RNN, which has very few internal operations but works well in appropriate situations (like short sequence analysis). RNNs use far fewer computational resources than their evolved variants, LSTM and GRU.
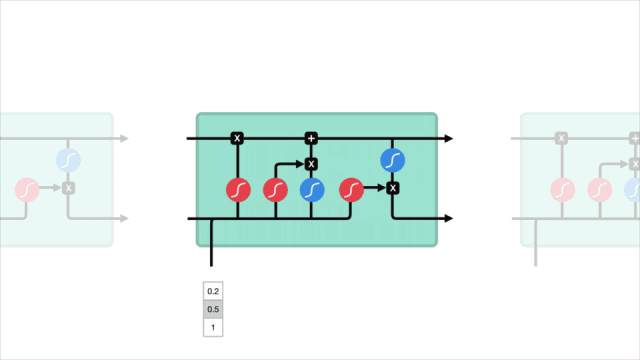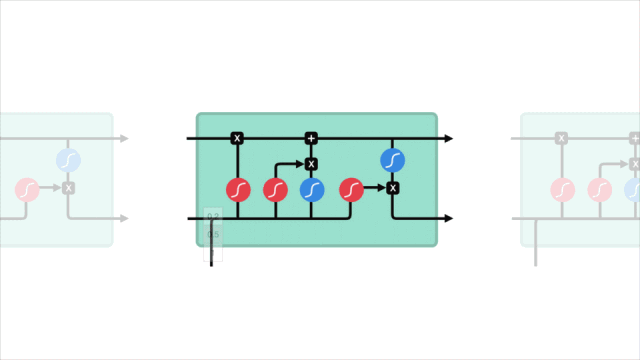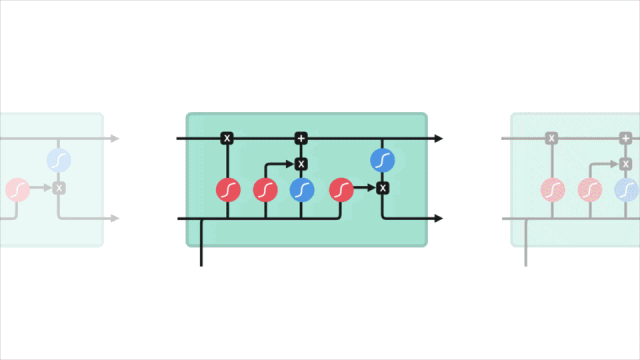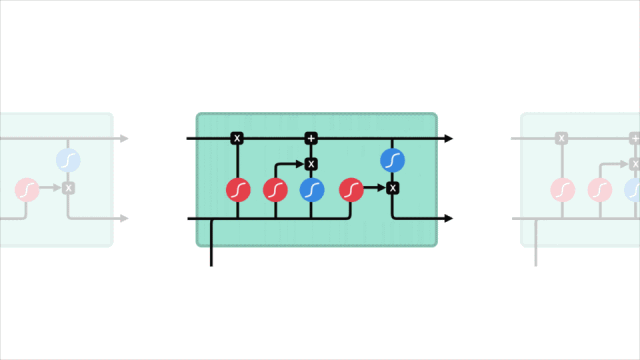
LSTM
The control flow of LSTM is similar to that of RNNs; both process the data for information transfer during the forward propagation. The difference lies in the structure and operations of the LSTM unit.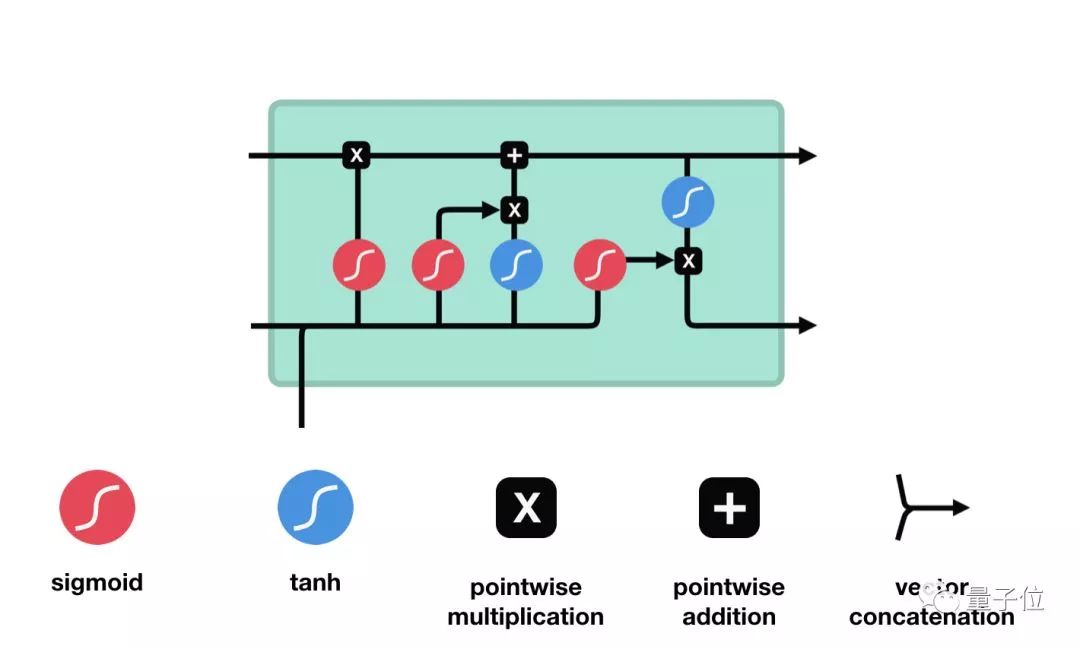
△ LSTM Unit and Its Operations
These operations allow LSTM to selectively retain or forget certain information. Below, we will gradually introduce these seemingly complex operations.
Core Concepts
The core concepts of LSTM are its cell state and various gate structures.The cell state acts as a pathway for transmitting relevant information, allowing information to flow through the sequence chain; this part can be seen as the network’s “memory.” Theoretically, the cell state can carry relevant information throughout the sequence processing, thus allowing information obtained in earlier time steps to be transmitted to later time step units, which can mitigate the impact of short-term memory.During the network training process, information can be added or removed through gate structures, and different neural networks can decide which relevant information to remember or forget through the gate structures on the cell state.
Sigmoid
The gate structures include the Sigmoid function, which is an activation function similar to the Tanh function. However, its output range is not (-1, 1), but rather (0, 1), which helps to update or forget data because any number multiplied by 0 equals 0, meaning this part of the information will be forgotten. Likewise, any number multiplied by 1 remains the same, meaning this part of the information will be fully retained. In this way, the network can understand which data is unimportant and needs to be forgotten, and which numbers are important and need to be retained.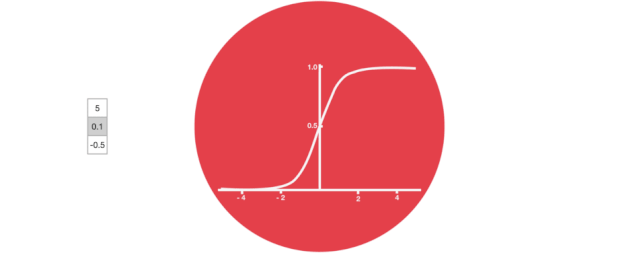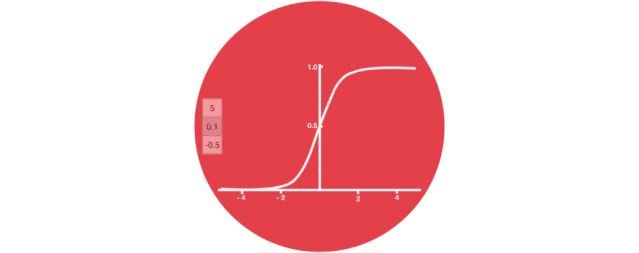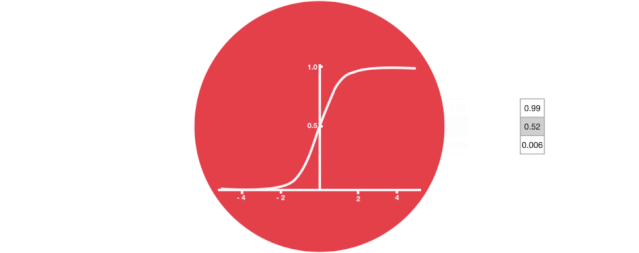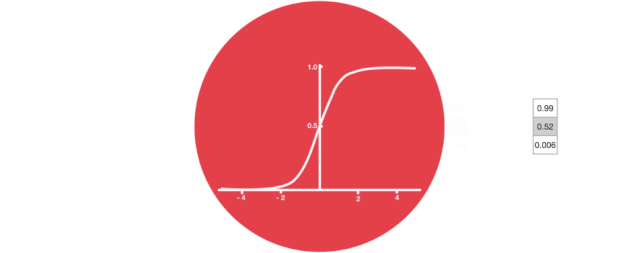
△ Sigmoid Output Range is (0, 1)
Next, we will delve into the functions of different gate structures. The LSTM unit has three gate structures that regulate information flow: the forget gate, input gate, and output gate.
Forget Gate
The forget gate determines which information should be discarded or retained. Information from the previous hidden state and the current input is simultaneously input into the Sigmoid function, and the output value lies between 0 and 1; the closer to 0, the more it should be forgotten, and the closer to 1, the more it should be retained.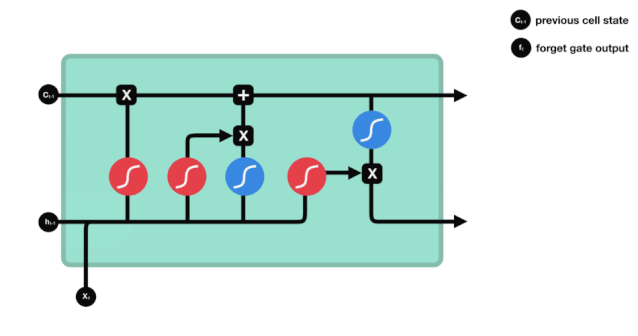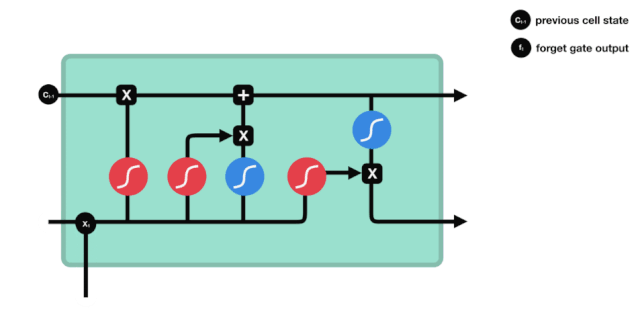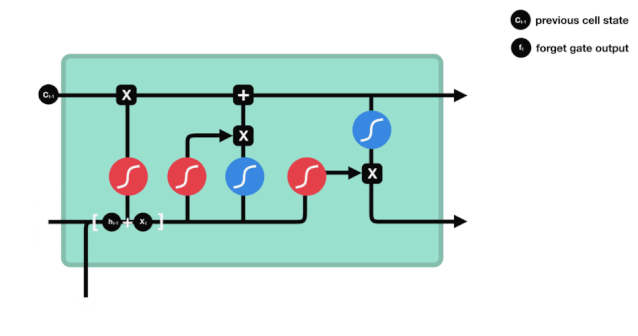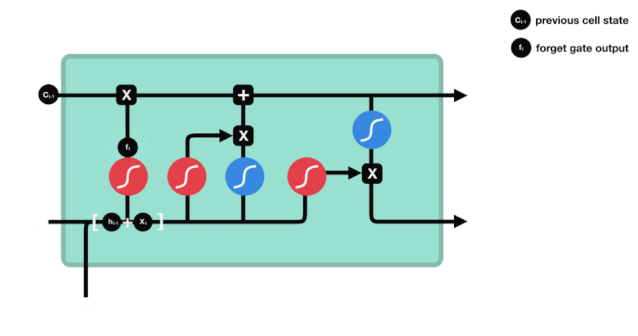
△ Forget Gate Operation
Input Gate
The input gate is used to update the cell state. First, it inputs the information from the previous hidden state and the current input into the Sigmoid function, adjusting the output value between 0 and 1 to decide which information to update; 0 means unimportant, and 1 means important. You can also pass the hidden state and the current input to the Tanh function and compress the values between -1 and 1 to regulate the network, and then multiply the Tanh output with the Sigmoid output, where the Sigmoid output will determine which information in the Tanh output is important and needs to be retained.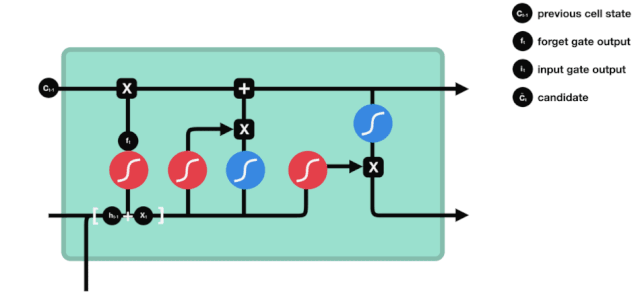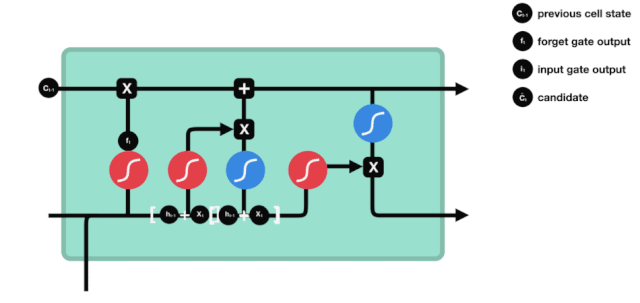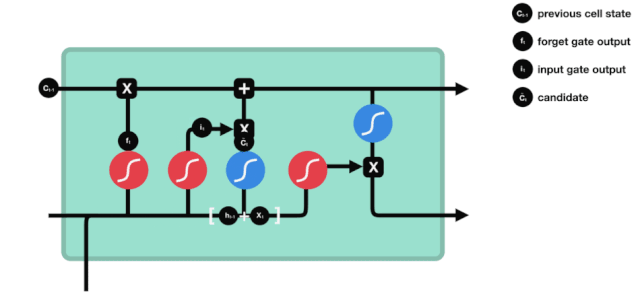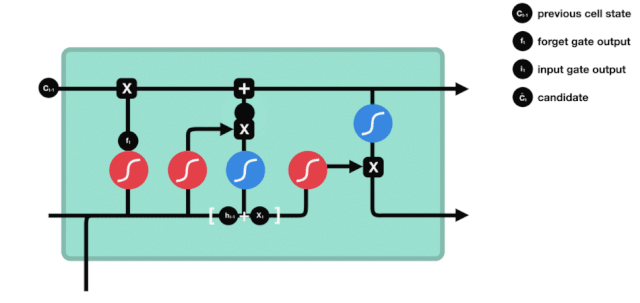
△ Input Gate Operation
Cell State
Here, we have enough information to calculate the cell state. First, multiply the previous cell state and the forget vector element-wise. If it is multiplied by a value close to 0, it means these values may be discarded in the new cell state; then add it element-wise to the output value of the input gate, updating the new information discovered by the neural network into the cell state, thus obtaining the new cell state.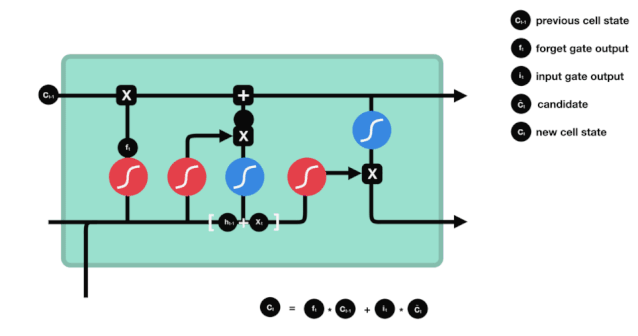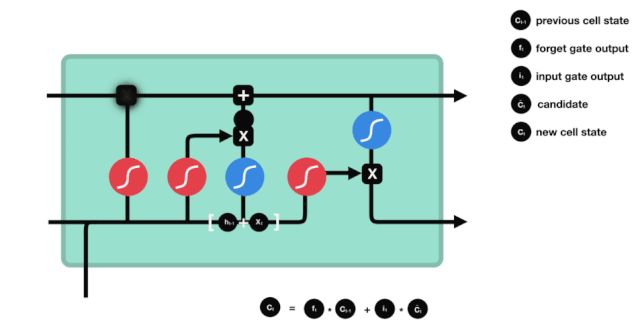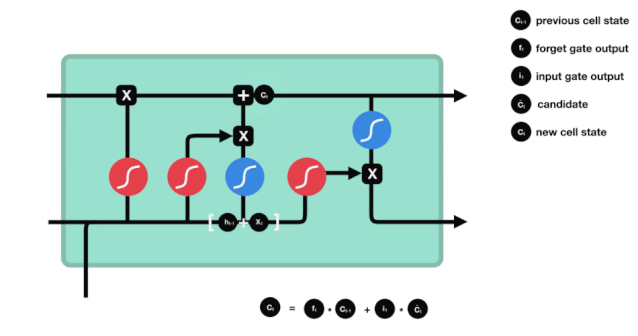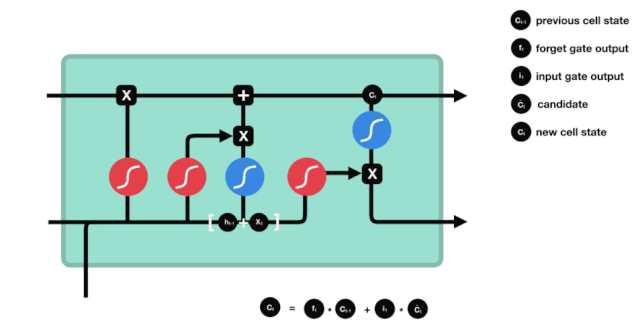
△ Calculating Cell State
Output Gate
The output gate determines the value of the next hidden state, which contains relevant information from the previous input. Of course, the hidden state can also be used for predictions. First, pass the previous hidden state and the current input to the Sigmoid function; then pass the newly obtained cell state to the Tanh function; multiply the Tanh output with the Sigmoid output to determine what information the hidden state should carry; finally, take the hidden state as the current unit output and transmit the new cell state and new hidden state to the next time step.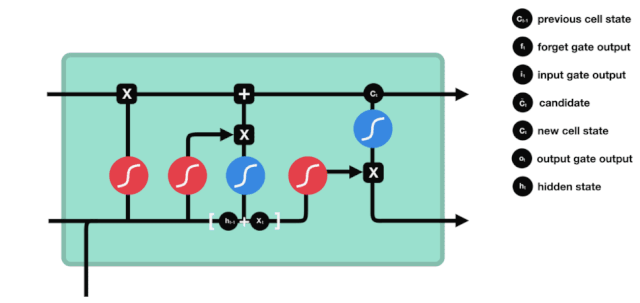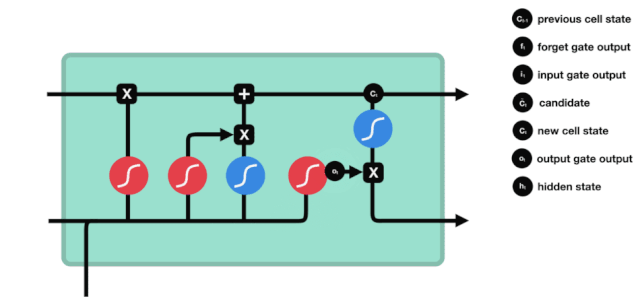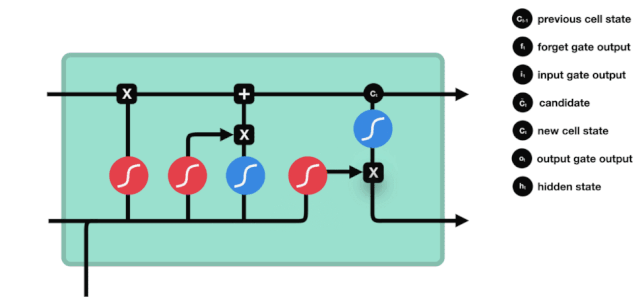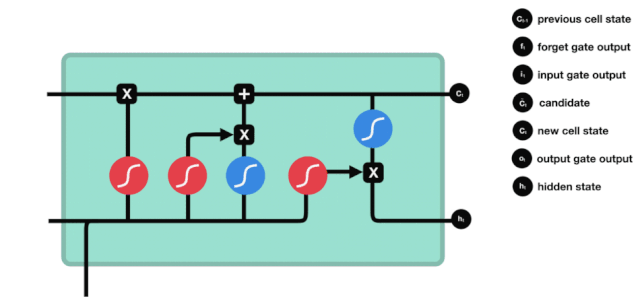
△ Output Gate Operation
Here, to summarize, the forget gate determines which relevant information from the previous time steps should be retained, the input gate decides which important information in the current input should be added, and the output gate determines the next hidden state.
Code Example
Here is also a sample code written in Python to help everyone better understand this structure.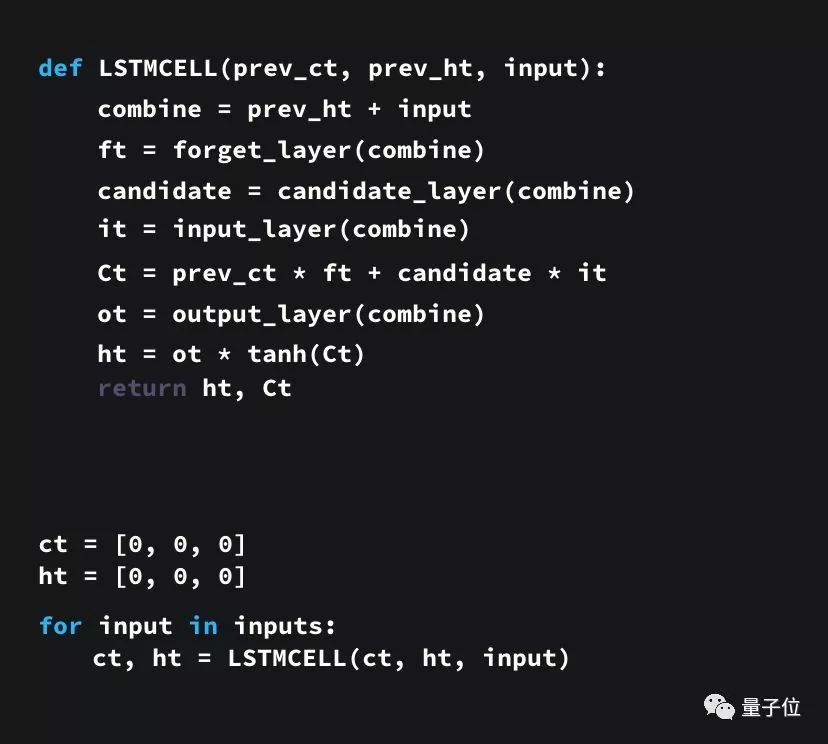
-
First, we connect the previous hidden state and the current input, defined as the variable combine;
-
Pass the combine variable to the forget layer to delete irrelevant data;
-
Create a candidate layer from the combine variable to retain values that may be added to the cell state;
-
The combine variable should also be passed to the output layer to decide which data from the candidate layer should be added to the new cell state;
-
The new cell state can be calculated based on the forget layer, candidate layer, input layer, and previous cell state;
-
Then calculate the current cell output;
-
Finally, the output and new cell state can be multiplied element-wise to obtain the new hidden state.
From the above, it can be seen that the control flow of the LSTM network is actually just a few tensor operations and a for loop. You can also make predictions using the hidden state. With these mechanisms, LSTM can selectively retain or forget certain information during sequence processing.
GRU
After introducing how LSTM works, let’s look at the Gated Recurrent Unit (GRU). GRU is another evolved variant of RNN, very similar to LSTM. The GRU structure removes the cell state and uses the hidden state to transmit information. It has only two gate structures: the update gate and the reset gate.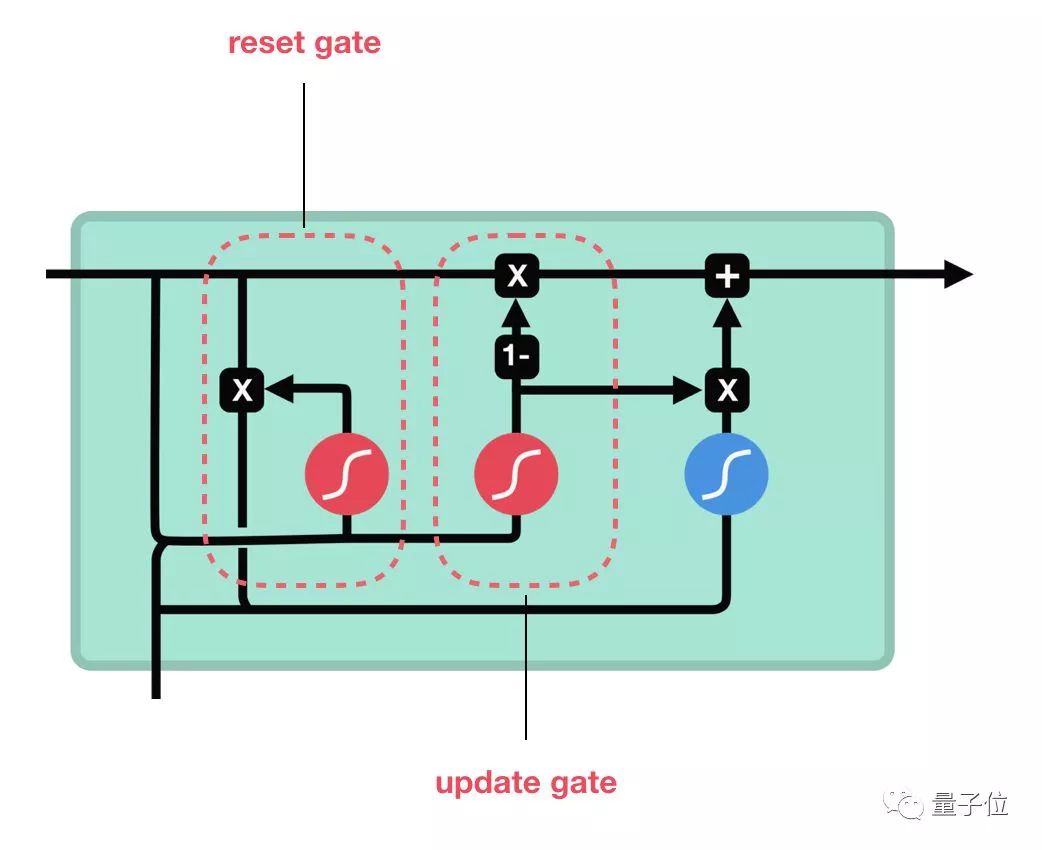
△ GRU Unit Structure
Update Gate
The update gate functions similarly to the forget gate and input gate in LSTM, determining which information to discard and which new information to add.
Reset Gate
The reset gate determines the degree to which previous information should be discarded.This makes up the GRU, which has fewer tensor operations, thus training it is slightly faster than LSTM. It is often difficult to determine which is better when choosing a network; researchers usually try both and select the structure that is more suitable for the current task by comparing performance.
Conclusion
In summary, RNNs are suitable for processing sequential data and prediction tasks but are affected by short-term memory. LSTM and GRU are two evolved variants that introduce gate structures to mitigate the impact of short-term memory, where gate structures are used to regulate the flow of information through the sequence chain. Currently, LSTM and GRU are frequently used in various deep learning applications, such as speech recognition, speech synthesis, and natural language understanding.If you are very interested in this area, the author has listed some valuable links to help understand LSTM and GRU structures from more perspectives.Implementing GRU and LSTM Networks in Pythonhttp://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theanoUnderstanding Long Short-Term Memory Modelshttp://colah.github.io/posts/2015-08-Understanding-LSTMs/Finally, here are the original text link and video version of this article:Original:https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21Feel free to scan the QR code to add the editor’s WeChat (please note the direction) and join the machine learning WeChat group to learn and improve together:
