
1. Test using the trained weights
from transformers import AutoModelForCausalLM,AutoTokenizer,TextGenerationPipeline
import torch
tokenizer = AutoTokenizer.from_pretrained(r"E:\大模型AI开发\AI大模型\projects\gpt2\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
model = AutoModelForCausalLM.from_pretrained(r"E:\大模型AI开发\AI大模型\projects\gpt2\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
# Load our own trained weights (Chinese poetry)
model.load_state_dict(torch.load("net.pt"))
# Use the system's built-in pipeline tool to generate content
pipline = TextGenerationPipeline(model,tokenizer,device=0)
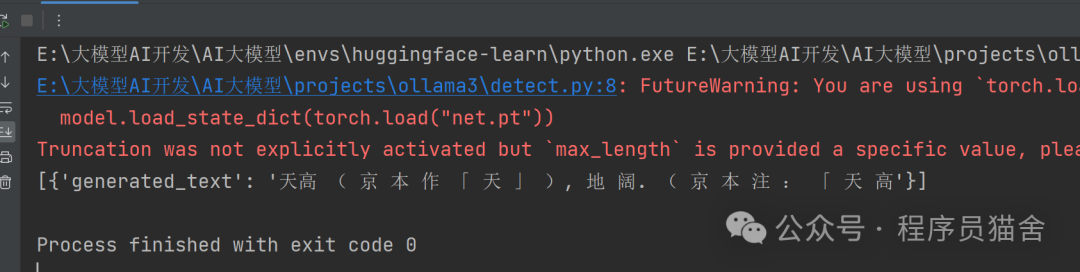
print(pipline("天高", max_length=24))The performance is actually not good:
2. Post-process the AI-generated results
# Customized content generation
from transformers import AutoModelForCausalLM,AutoTokenizer,TextGenerationPipeline
import torch
tokenizer = AutoTokenizer.from_pretrained(r"E:\大模型AI开发\AI大模型\projects\gpt2\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
model = AutoModelForCausalLM.from_pretrained(r"E:\大模型AI开发\AI大模型\projects\gpt2\model\models--uer--gpt2-chinese-cluecorpussmall\snapshots\c2c0249d8a2731f269414cc3b22dff021f8e07a3")
# Load our own trained weights (Chinese poetry)
model.load_state_dict(torch.load("net.pt"))
# Define a function to generate 5-character quatrains text is the prompt, row is the number of lines to generate, col is the number of characters per line.
def generate(text,row,col):
# Define an internal recursive function to generate text
def generate_loop(data):
# Disable gradient calculation
with torch.no_grad():
# Use the data in the dictionary as input to the model and get the output
out = model(**data)
# Get the last word (logits unnormalized probability output)
out = out["logits"]
# Select the last logits of each sequence, corresponding to the prediction of the next word
out = out[:,-1]
# Find the top 50 values to serve as a boundary, all values below this will be discarded
topk_value = torch.topk(out,50).values
# Get the top 50 largest logits from each output sequence (to maintain the original dimension, we need to add a dimension to the result because indexing will reduce dimensions)
topk_value = topk_value[:,-1].unsqueeze(dim=1)
# Set all logits less than the 50th largest value to negative infinity, reducing the probability of low probability words being selected
out = out.masked_fill(out< topk_value,-float("inf"))
# Mask [UNK]
out[:, tokenizer.get_vocab()["[UNK]"]] = -float("inf")
# Set the logits of special symbols to negative infinity to prevent the model from generating these symbols.
for i in ",.()《》[]「」{}":
out[:,tokenizer.get_vocab()[i]] = -float("inf")
# Sample based on probabilities, without replacement, to avoid generating duplicate content
out = out.softmax(dim=1)
# Randomly sample the next word's ID from the probability distribution
out = out.multinomial(num_samples=1)
# Forcibly add punctuation
# Calculate the ratio of the current generated text length to the expected length
c = data["input_ids"].shape[1] / (col+1)
# If the current length is an integer multiple of the expected length, add punctuation
if c %1 ==0:
if c%2==0:
# Add a period at even positions
out[:,0] = tokenizer.get_vocab()["."]
else:
# Add a comma at odd positions
out[:,0] = tokenizer.get_vocab()[","]
# Append the newly generated word ID to the end of the input sequence
data["input_ids"] = torch.cat([data["input_ids"],out],dim=1)
# Update the attention mask, marking all valid positions
data["attention_mask"] = torch.ones_like(data["input_ids"])
# Update the token ID type, usually used in BERT models, but not in GPT
data["token_type_ids"] = torch.ones_like(data["input_ids"])
# Update labels, here copy the input ID to the labels, usually used to predict the next word in language generation models
data["labels"] = data["input_ids"].clone()
# Check if the generated text length meets or exceeds the specified function and column count
if data["input_ids"].shape[1] >= row*col + row+1:
# If the length requirement is met, return the final data dictionary
return data
# If the length requirement is not met, recursively call the generate_loop function to continue generating text
return generate_loop(data)
# Generate 3 poems
# Use the tokenizer to encode the input text and repeat 3 times to generate 3 samples
data = tokenizer.batch_encode_plus([text]*3,return_tensors="pt")
# Remove the last token (end symbol) from the encoded sequence
data["input_ids"] = data["input_ids"][:,:-1]
# Create a tensor of ones with the same shape as input_ids for the attention mask
data["attention_mask"] = torch.ones_like(data["input_ids"])
# Create a tensor of ones with the same shape as input_ids for the token ID type
data["token_type_ids"] = torch.ones_like(data["input_ids"])
# Copy input to labels for model targets
data["labels"] = data["input_ids"].clone()
# Call the generate_loop function to start generating text
data = generate_loop(data)
# Iterate through the generated 3 samples
for i in range(3):
print(i,tokenizer.decode(data["input_ids"][i]))
if __name__ == '__main__':
generate("白",row=4,col=5)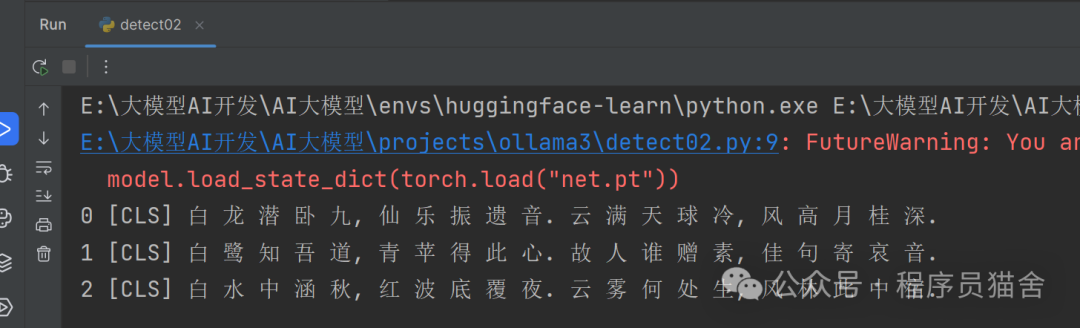
3. Download the llama3 model from modelscope
Install modelscope
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download(model_id='LLM-Research/Llama-3.2-1B-Instruct',cache_dir=r'E:\大模型AI开发\AI大模型\projects\ollama3\model')4. Use transformers to call llama3
# Use transformer to load the llama3 model
from transformers import AutoModelForCausalLM,AutoTokenizer
DEVICE = "cuda"
# Load local model path as the root directory where the model configuration file is located
model_dir = r"E:\大模型AI开发\AI大模型\projects\ollama3\model\LLM-Research\Llama-3___2-1B-Instruct"
# Use transformer to load the model torch_dtype data types are: float32,float16
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype="auto",device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
# Call the model
# Define the prompt
prompt = "你好,请介绍下你自己。"
# Wrap the prompt into a message
message = [{"role":"system","content":"You are a helpful assistant system"},{"role":"user","content":prompt}]
# Use the tokenizer's apply_chat_template() method to convert the above-defined message list; tokenize=False means no tokenization at this time
text = tokenizer.apply_chat_template(message,tokenize=False,add_generation_prompt=True)
# Tokenize the processed text and convert it to the model's input tensor
model_inputs = tokenizer([text],return_tensors="pt").to(DEVICE)
# Input the model to get output
generated = model.generate(model_inputs.input_ids,max_new_tokens=512)
print(generated)
# Decode the output content
responce = tokenizer.batch_decode(generated,skip_special_tokens=True)
print(responce)