Source: DeepHub IMBA
This article is about 2500 words long and is recommended to be read in 5 minutes.
This article will introduce the integration of LLMLingua with the proprietary LlamaIndex for efficient inference.
The emergence of large language models (llm) has spurred innovation across multiple fields. However, with strategies driven by chain of thought (CoT) prompting and in-context learning (ICL), the complexity of prompts has been increasing, posing challenges for computation. These lengthy prompts require substantial resources for inference, thus necessitating efficient solutions. This article will introduce the integration of LLMLingua with the proprietary LlamaIndex for efficient inference.
LLMLingua is a paper published by researchers at Microsoft at EMNLP 2023, LongLLMLingua is a method that enhances the ability of LLMs to perceive key information in long context scenarios through rapid compression.
Collaboration Between LLMLingua and LlamaIndex
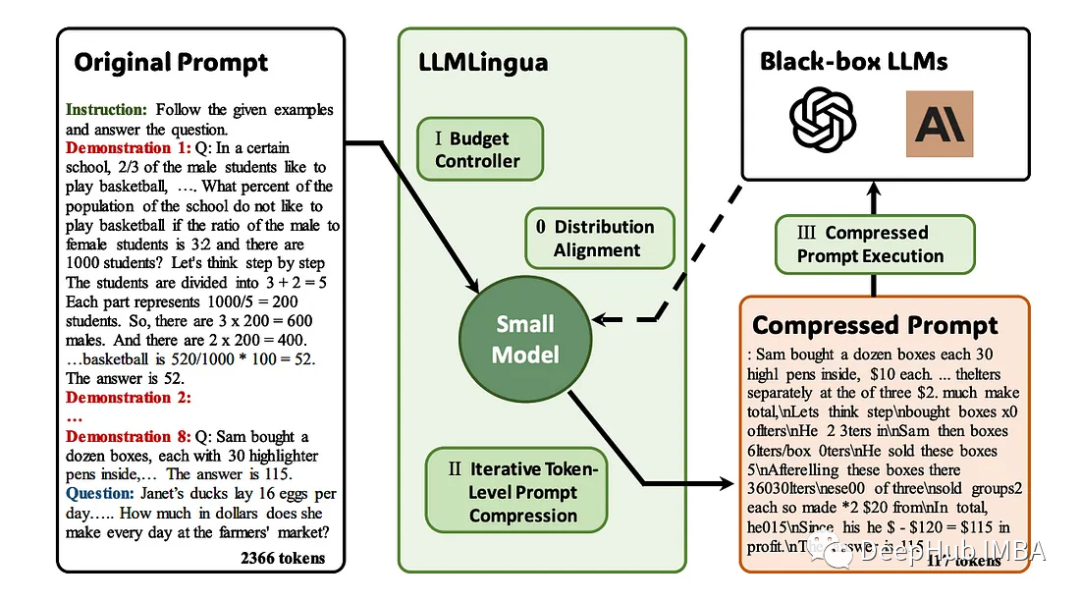
LLMLingua emerges as a groundbreaking solution to lengthy prompts in LLM applications. This method focuses on compressing lengthy prompts while ensuring semantic integrity and improving inference speed. It combines various compression strategies to provide a nuanced approach to balancing prompt length and computational efficiency.
Here are the advantages of the integration of LLMLingua with LlamaIndex:
The integration of LLMLingua with LlamaIndex marks a significant step forward in rapid optimization for LLMs. LlamaIndex is a dedicated repository containing pre-optimized prompts tailored for various LLM applications, allowing LLMLingua to access a wealth of domain-specific, fine-tuned prompts, thereby enhancing its prompt compression capabilities.
The synergy between LLMLingua’s prompt compression techniques and LlamaIndex’s optimized prompt library enhances the efficiency of LLM applications. Utilizing LLAMA‘s specialized prompts, LLMLingua can fine-tune its compression strategies, ensuring the retention of domain-specific context while reducing prompt length. This collaboration greatly accelerates inference speed while preserving the nuances of key domains.
The integration of LLMLingua with LlamaIndex extends its impact on large-scale LLM applications. By leveraging LLAMA’s specialized prompts, LLMLingua optimizes its compression techniques, alleviating the computational burden of handling lengthy prompts. This integration not only accelerates inference but also ensures the retention of critical domain-specific information.
Workflow of LLMLingua with LlamaIndex
Implementing LLMLingua using LlamaIndex involves a structured process that leverages a specialized prompt library for efficient prompt compression and enhanced inference speed.
First, a connection needs to be established between LLMLingua and LlamaIndex. This includes access permissions, API configurations, and establishing connections for timely retrieval.
2. Retrieval of Pre-optimized Prompts
LlamaIndex acts as a dedicated repository containing pre-optimized prompts tailored for various LLM applications. LLMLingua accesses this repository to retrieve domain-specific prompts and utilizes them for prompt compression.
3. Prompt Compression Techniques
LLMLingua uses its prompt compression methods to simplify the retrieved prompts. These techniques focus on compressing lengthy prompts while ensuring semantic consistency, thereby improving inference speed without compromising context or relevance.
4. Fine-tuning Compression Strategies
LLMLingua fine-tunes its compression strategies based on the specialized prompts obtained from LlamaIndex. This refining process ensures the retention of domain-specific nuances while effectively reducing prompt length.
5. Execution and Inference
Once the compressed prompts are generated using LLMLingua’s customized strategies and LlamaIndex’s pre-optimized prompts, the compressed prompts can be utilized for LLM inference tasks. This stage involves executing the compressed prompts within the LLM framework for efficient context-aware inference.
6. Iterative Improvement and Enhancement
The code implementation undergoes iterative refinement continuously. This process includes improving compression algorithms, optimizing prompt retrieval from LlamaIndex, and fine-tuning integration to ensure consistency and enhanced performance between compressed prompts and LLM inference.
7. Testing and Validation
If necessary, testing and validation can be performed to evaluate the efficiency and effectiveness of the integration of LLMLingua with LlamaIndex. Performance metrics are assessed to ensure that the compressed prompts maintain semantic integrity and improve inference speed without compromising accuracy.
Code Implementation
Next, we will delve into the code implementation of LLMLingua with LlamaIndex.
# Install dependency. !pip install llmlingua llama-index openai tiktoken -q
# Using the OAI import openai openai.api_key = "<insert_openai_key>"
!wget "https://www.dropbox.com/s/f6bmb19xdg0xedm/paul_graham_essay.txt?dl=1" -O paul_graham_essay.txt
Load the model:
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
load_index_from_storage,
StorageContext,
)
# load documents documents = SimpleDirectoryReader(
input_files=["paul_graham_essay.txt"] ).load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k=10)
question = "Where did the author go for art school?"
# Ground-truth Answer answer = "RISD"
contexts = retriever.retrieve(question)
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts] len(context_list)
#Output #10
Original prompt and return
# The response from original prompt from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-16k") prompt = "\n\n".join(context_list + [question])
response = llm.complete(prompt) print(str(response))
#Output The author went to the Rhode Island School of Design (RISD) for art school.
from llama_index.query_engine import RetrieverQueryEngine from llama_index.response_synthesizers import CompactAndRefine from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder,
"dynamic_context_compression_ratio": 0.3,
},
)
Compression through LLMLingua
retrieved_nodes = retriever.retrieve(question) synthesizer = CompactAndRefine()
from llama_index.indices.query.schema import QueryBundle
# postprocess (compress), synthesize new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=question) )
original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes])
original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts) compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
Print the comparison of two results:
print(compressed_contexts) print() print("Original Tokens:", original_tokens) print("Compressed Tokens:", compressed_tokens) print("Comressed Ratio:", f"{original_tokens/(compressed_tokens+ 1e-5):.2f}x")
The printed results are as follows:
next Rtm's advice hadn' included anything that. I wanted to do something completely different, so I decided I'd paint. I wanted to how good I could get if I focused on it. the day after stopped on YC, I painting. I was rusty and it took a while to get back into shape, but it was at least completely engaging.1]
I wanted to back RISD, was now broke and RISD was very expensive so decided job for a year and return RISD the fall. I got one at Interleaf, which made software for creating documents. You like Microsoft Word? Exactly That was I low end software tends to high. Interleaf still had a few years to live yet. []
the Accademia wasn't, and my money was running out, end year back to the lot the color class I tookD, but otherwise I was basically myself to do that for in993 I dropped I aroundidence bit then my friend Par did me a big A rent-partment building New York. Did I want it Itt more my place, and York be where the artists. wanted [For when you that ofs you big painting of this type hanging in the apartment of a hedge fund manager, you know he paid millions of dollars for it. That's not always why artists have a signature style, but it's usually why buyers pay a lot for such work. [6]
Original Tokens: 10719 Compressed Tokens: 308 Comressed Ratio: 34.80x
response = synthesizer.synthesize(question, new_retrieved_nodes) print(str(response))
#Output #The author went to RISD for art school.
Conclusion
The integration of LLMLingua with LlamaIndex demonstrates the transformative potential of collaborative relationships in optimizing large language model (LLM) applications. This collaboration fundamentally changes the game for instant compression methods and inference efficiency, paving the way for context-aware, streamlined LLM applications.
This integration not only accelerates inference speed but also ensures the semantic integrity is maintained in the compressed prompts. The compression strategies fine-tuned based on LlamaIndex’s domain-specific prompts strike a balance between reduced prompt length and fundamental context retention, thus enhancing the accuracy of LLM inference.
Essentially, the integration of LLMLingua with LlamaIndex transcends traditional prompt compression methods, laying the groundwork for the optimization of future large language model applications, context accuracy, and effective customization for different domains. This collaborative integration heralds a new era of efficiency and refinement in the field of large language model applications.
If you are interested in LLMLingua, online DEMO, papers, source code, etc. can be found here:https://huggingface.co/spaces/microsoft/LLMLingua
Edited by: Wang Jing
Proofread by: Yang Xuejun