
Originally from Akash Mathur’s Blog
Abstract:
In the field of information retrieval, Retrieval-Augmented Generation (RAG) models signify a paradigm shift, empowering large language models (LLMs) to generate responses that are rich in context and accurate. However, unlocking the full potential of RAG often transcends the limitations of its default query-retrieve-generate framework.
This article delves into the transformative power of advanced query transformation techniques, aiming to bridge the gap between preliminary user prompts and the most relevant information within vast databases.
Challenges of Inconsistent Retrieval
At the core of query transformation lies a fundamental challenge: user-generated prompts often lack the precise language or structure that seamlessly aligns with relevant documents. This inconsistency can hinder retrieval efforts, leading even the most sophisticated LLMs to provide suboptimal responses. Query transformation addresses this challenge by strategically modifying queries before the retrieval phase, enhancing their relevance, and guiding LLMs to extract information more effectively.
Issues of Zero-Shot Challenges
Recent research has revealed the benefits of breaking down complex queries into smaller, more manageable steps, particularly effective for queries requiring knowledge augmentation. However, fully zero-shot dense retrieval systems, where relevance labels are absent, still pose significant challenges. Advanced query transformation emerges as a promising approach to tackle these challenges, offering innovative strategies to address this issue.
The idea behind query transformation is that the retriever may not consider the user’s initial prompt to retrieve semantically similar documents. However, it modifies the query to increase its relevance to our information sources before retrieval and feeding it to the language model.
There are numerous techniques to enhance RAG, creating additional challenges regarding when to apply each technique. In this article, we will analyze five powerful query transformation techniques and see how they help bridge the retrieval gap and elevate search to the next level.
1. Hypothetical Document Embeddings (HyDE)
2. Sub-Question Query Engine
3. Routing Query Engine
4. Single-Step Query Decomposition
5. Multi-Step Query Decomposition
Knowledge and Action, Closely Linked
This journey is not merely theoretical insights. Alongside each technique, you will find references to a dedicated GitHub repository providing code examples and implementation details.
Let’s dive in.
Open Source LLM and Embeddings
LLM: In this exploration, we will leverage the powerful capabilities of Zephyr-7b-alpha, a highly regarded advanced open-source LLM known for its excellence in understanding and generating text.
Embeddings: We will use BGE embeddings (bge-large-en-v1.5), a universal embedding model designed for effective semantic search and knowledge extraction.
This embedding model ranks fifth in the MTEB embedding benchmark. Meanwhile, check out their repository at https://github.com/FlagOpen/FlagEmbedding
Let’s take a look at the code.




Before applying any query transformations, please configure the index and retriever.

Let’s discuss and apply the aforementioned query transformations one by one.
1. Hypothetical Document Embeddings (HyDE)
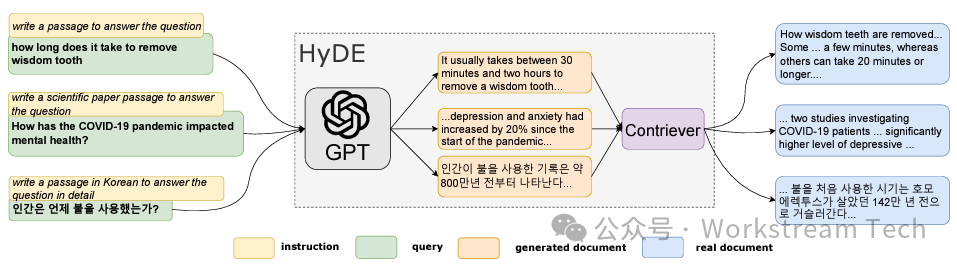
HyDE (Hypothetical Document Embeddings) is a novel approach for dense retrieval, involving two distinct phases:
1. Generating Hypothetical Answers
Unlike directly searching for relevant documents based on the original query, HyDE first constructs a hypothetical document that could answer the query.
This is achieved by utilizing a language model that follows instructions, which is responsible for generating potential responses to the query.
While this hypothetical document may not be accurate in every detail, it serves as a valuable example, showcasing what a relevant document might look like, capturing the essence of relevance.
2. Encoding and Retrieval
Then, the hypothetical document is processed by an unsupervised contrastive encoder, which distills its key features into a compact embedding vector.
Importantly, the dense bottleneck of the encoder acts as a lossy compressor, filtering out irrelevant details.
This embedding vector is then compared with the database of embeddings representing actual documents.
The document-document similarity encoded during contrastive training is encoded in the inner product, enabling the identification of documents closely aligned with the hypothetical answer.
The most similar actual documents are retrieved and presented as potential responses to the query, enhancing the accuracy of retrieval.
Let’s look at the code.
First, we perform a query without transformation. Then, the same query string is used for embedding lookup and summarization.

Response:

Let’s apply the HyDE transformation and see the results.

Response:

Let’s take a look at the hypothetical document. We use `HyDEQueryTransform` to generate a hypothetical document and use it for embedding lookup.
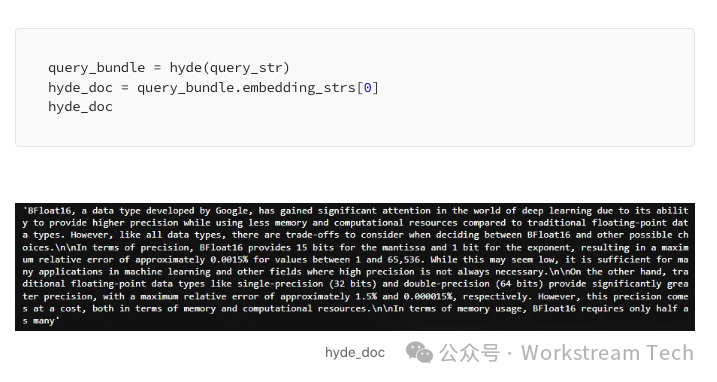
Conclusion — You can see that HyDE significantly improves output quality by accurately generating hallucinations, thereby enhancing embedding quality and final output.
2. Sub-Question Query Engine
Understanding Traditional Query Engines
Common query engines are designed to locate relevant information within vast datasets. They act as intermediaries between user questions and stored data. When a user submits a query, the engine carefully analyzes it, identifies relevant data, and presents a comprehensive response.
Limitations of Traditional Query Engines
Although traditional query engines excel at handling direct questions, they often face challenges when confronted with multifaceted queries that span multiple documents.
Simply merging documents and extracting the top k elements often fails to capture the nuances required for truly informative responses.
Introducing Sub-Question Query Engines
Decomposition Strategy: To address this complexity, sub-question query engines adopt a divide-and-conquer approach. They elegantly break down complex queries into a series of sub-questions, each targeting a specific aspect of the original query.
Implementation involves defining a sub-question query engine for each data source.Instead of treating all documents equally, the engine strategically handles sub-questions relevant to each data source.To generate the final response, the top-level sub-question query engine then aggregates results from various sub-questions.
Given an initial complex problem, we generate sub-questions using LLM and execute them on the selected data sources.It collects all sub-responses and then synthesizes a final response.
Let’s look at the code.

Build a sub-question query engine and run some queries!
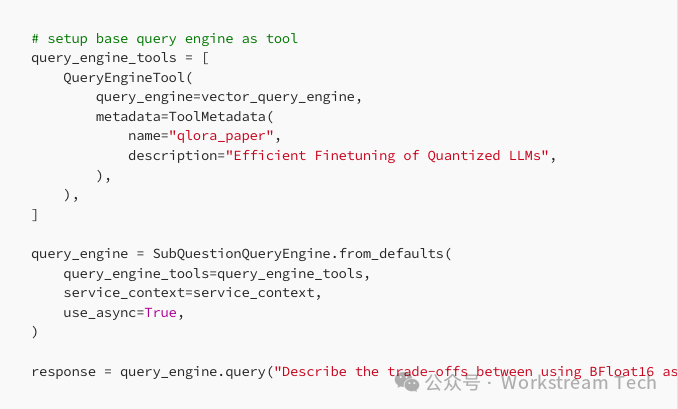
Here are the generated sub-questions:

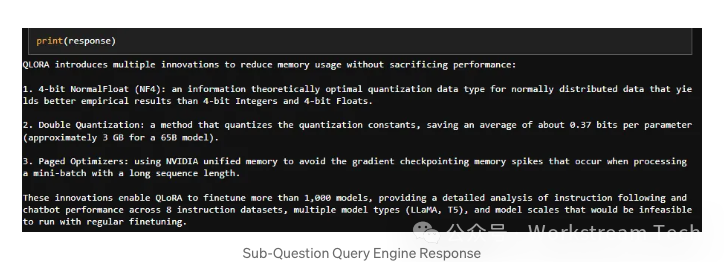
Response:
3. Routing Query Engine
Now, we will define a routing query engine that selects one from multiple candidate query engines to execute the query.
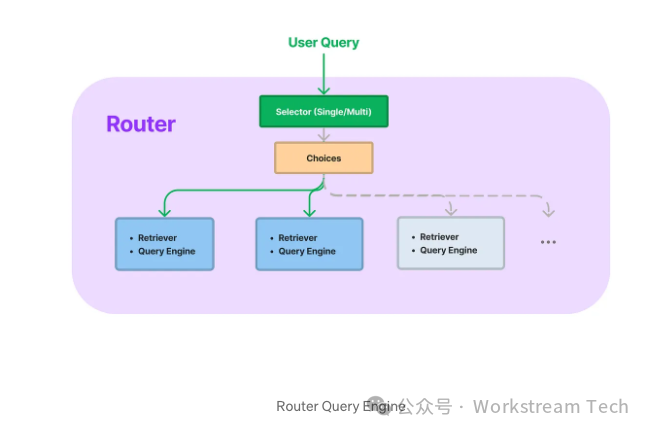
The routing query engine serves as a powerful decision module, playing a crucial role in selecting the most appropriate option from choices defined based on user queries and metadata. These routers are versatile modules that can operate independently as ‘selector modules’ or as part of a top-level query engine or retriever.
Routers excel in various use cases, including selecting the appropriate data source from multiple options and deciding whether to perform summarization or semantic search based on user queries.They can also handle more complex tasks, such as attempting multiple choices simultaneously and merging results using multi-routing capabilities.
We also define a ‘selector’.Users can easily use the router as a query engine or retriever, with the router responsible for selecting the query engine or retriever to effectively route user queries.
Several selectors are available, each with unique properties.
The LLM selector uses LLM to output a JSON, which is then parsed to query the corresponding index.
The Pydantic selector (currently only supported by gpt-4 and gpt-3.5 (default)) generates pydantic selection objects using the OpenAI Function Call API instead of parsing raw JSON.
For each type of selector, one or more indices can also be selected for routing.
Then, the RouterQueryEngine is defined using the desired selector module. Here, we use LLMSingleSelector, which uses LLM to select the underlying query engine for routing queries.
Let’s look at the code.
We will define a custom routing query engine that selects one from multiple candidate query engines to execute the query.

Next, we define query engines for each index. Then we wrap them with QueryEngineTool.

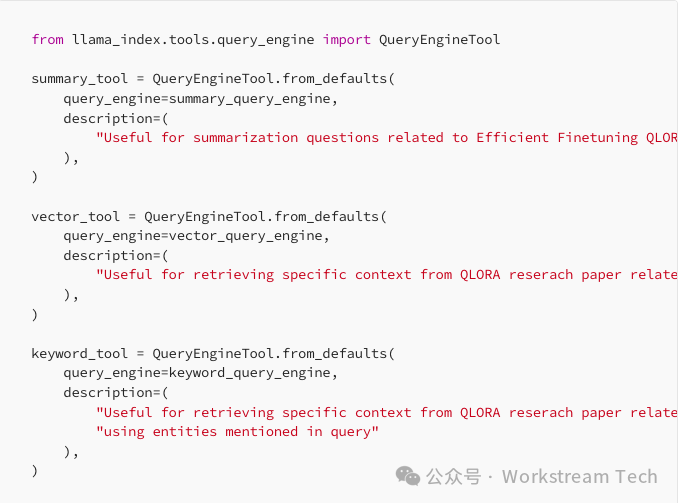
Then, we will use the LLM selector, which can use OpenAI or any other LLM to parse the generated JSON in the background to select a sub-index for routing.
LLMSingleSelector

Response:
LLMMultiSelector
If we want to route the query to multiple indices, we can use the multi-selector.The multi-selector sends the query to multiple sub-indices and then uses a summarization index to consolidate all responses, forming a complete answer.

4. Single-Step Query Decomposition
Recent studies indicate that LLMs tend to perform better when breaking down complex problems into smaller, more manageable steps. In cases of complex queries, different parts of the knowledge base may relate to different ‘sub-queries’ within the overall problem. Single-step query transformation acknowledges this and aims to address each sub-query independently.
Single-step query decomposition features are designed to transform complex problems into simpler questions, specifically tailored to extract relevant information from the dataset.By breaking the original question into smaller, more focused sub-queries, the model can provide sub-answers that collectively contribute to resolving the complexity of the original question.
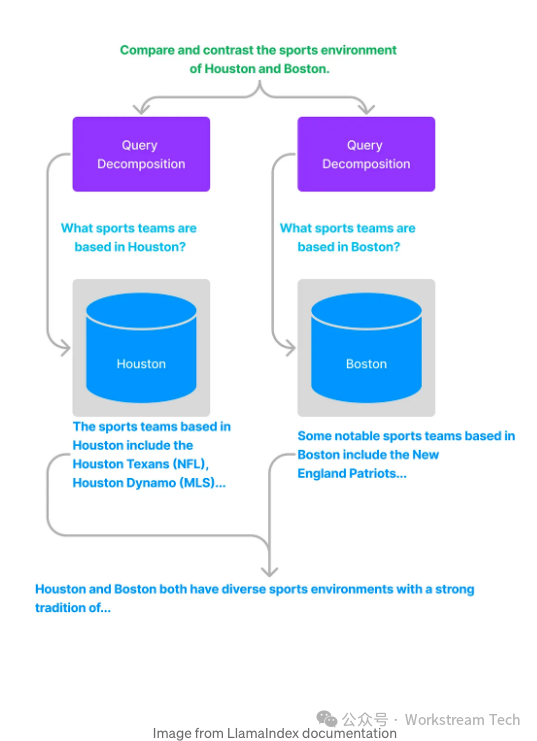
5. Multi-Step Query Decomposition
Multi-step query transformation represents an innovative approach known as the self-questioning method. This approach is rooted in the concept that a language model poses and answers subsequent questions to itself before providing an answer to the original query. Its goal is to enable the model to seamlessly integrate information from its independent learning.
This model connects dispersed facts, synthesizes insights, and reveals relationships that may remain obscure in a single-step approach.
Thus, multi-step query transformation overcomes a common limitation of LLMs:the difficulty of combining individual facts to draw new conclusions.By iteratively exploring knowledge, the model reveals connections that might remain hidden in other circumstances.
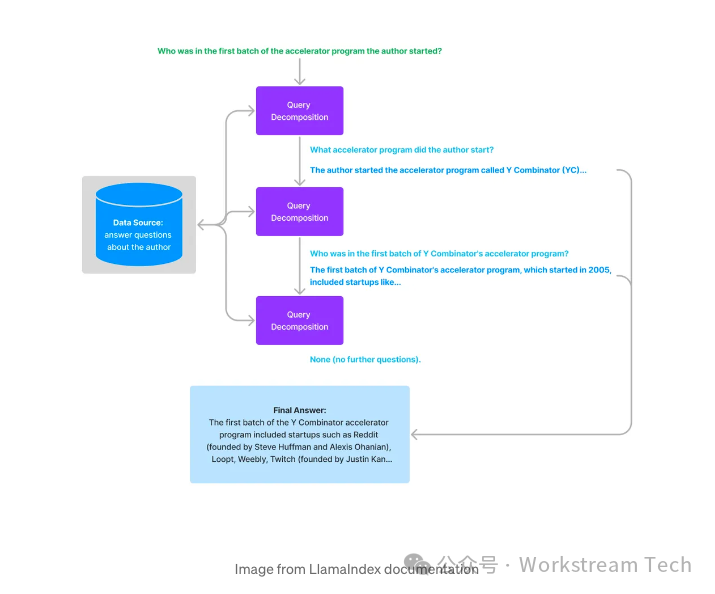
Let’s get into the code.

“`python
from llama_index.query_engine.multistep_query_engine import MultiStepQueryEngine
# Set Logging to DEBUG for more detailed output
from llama_index.query_engine.multistep_query_engine import (
MultiStepQueryEngine,
)
step_decompose_transform = StepDecomposeQueryTransform(llm=llm, verbose=True)
query_engine = vector_index.as_query_engine(service_context=service_context)
query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform
)
“`
Note: When running MultiStepQueryEngine, I encountered a ValueError — Could not load OpenAI model.
Currently, it seems that MultiStepQueryEngine only supports OpenAI GPT-4 and GPT-3.5 models. I will continue to delve into this area and update the code accordingly. I will also keep this as an open issue, welcoming everyone to share their responses in the comments.
Which one suits me?
The sub-question query engine and single/multi-step query decomposition in RAG both handle complex queries, but they address the problem from different angles:
Sub-Question Query Engine
It focuses on a divide-and-conquer approach.It breaks down complex queries into a series of smaller, focused sub-questions.Each sub-question is sent to a dedicated sub-question query engine that retrieves relevant information from its specific data source.
Thus, it ensures that each sub-question receives the appropriate data source, leading to more precise results.By aggregating insights from various sub-questions, it provides comprehensive answers to deliver thorough responses.
Single/Multi-Step Query Decomposition
It focuses on sequential refinement of queries.It breaks down complex queries into intermediate steps, enriching the search with retrieved information step by step.Each step searches for relevant documents based on the current query state, updating the query with extracted knowledge.
Thus, by refining the query at each step, it avoids redundant retrieval.
Conclusion
The exploration of advanced query enhancement is not an end, but an exciting beginning. While the methods covered in this article possess transformative potential, the boundaries of information retrieval are continually expanding.
Future research may delve into hybrid approaches that combine these techniques for greater synergies. We may witness the rise of personalized transformations tailored to individual user needs and preferences. Ultimately, the journey of bridging the retrieval gap is an ongoing process, driven by innovation and fueled by the desire to connect users with the most accurate and insightful information, wherever it may be.