
In today’s AI era, how to enable AI models to understand and answer questions based on specific documents has become a hot topic. LlamaIndex, as a powerful data framework, can help us easily build document Q&A systems based on large language models. This article will guide you to set up a simple yet fully functional document Q&A system in 10 minutes.
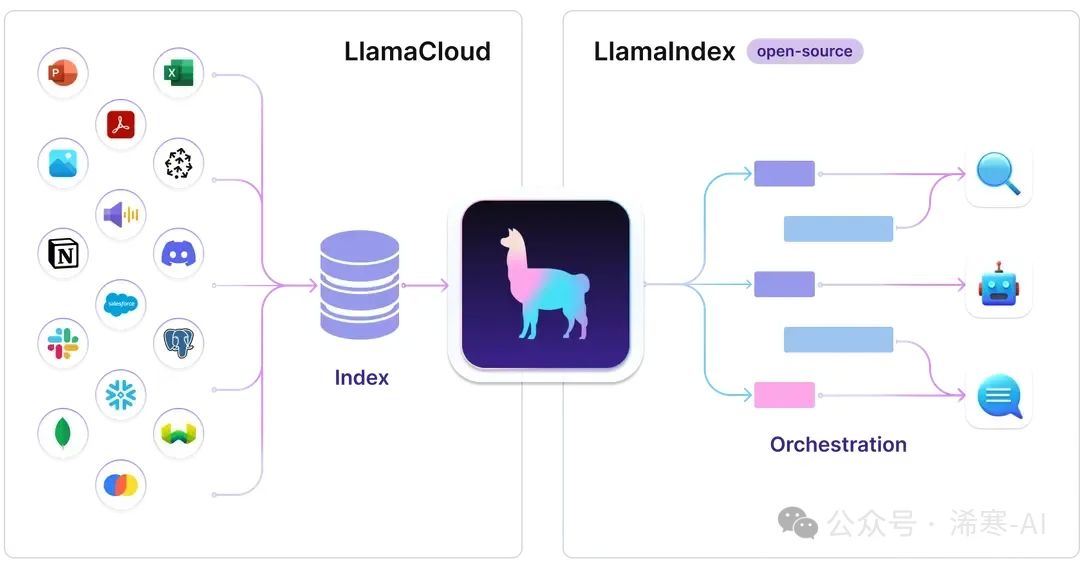
1. Environment Preparation
First, we need to install the necessary dependencies. Create a requirements.txt file containing the following:
llama-index-core
python-dotenv
openai
Then run:
pip install -r requirements.txt
2. Configure Environment Variables
Create a .env file and add your OpenAI API key:
OPENAI_API_KEY=your_OpenAI_API_key3. Code Implementation
Let’s look at a basic implementation:
# Import necessary libraries
# VectorStoreIndex is used to create vector indexes
# SimpleDirectoryReader is used to read documents
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# For loading environment variables
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Read all PDF documents from the pdf directory
documents = SimpleDirectoryReader("pdf/").load_data()
# Convert documents to vector index
index = VectorStoreIndex.from_documents(documents)
# Create query engine
query_engine = index.as_query_engine()
# Execute query, asking about design goals and details
response = query_engine.query("What are the design goals and give details about it please.")
# Print query results
print(response)
4. Code Analysis
Let’s analyze this code line by line:
-
Import Necessary Libraries
-
VectorStoreIndex: Used to create a vector index for documents -
SimpleDirectoryReader: Used to read document directories -
load_dotenv: Used to load environment variables -
Load Documents
-
SimpleDirectoryReader("pdf/").load_data(): This line reads all documents in the pdf directory -
LlamaIndex supports various document formats, including PDF, TXT, DOCX, etc.
-
Create Index
-
VectorStoreIndex.from_documents(documents): This step converts the documents into vector form -
Under the hood, LlamaIndex uses language models to split documents into smaller chunks and create vector embeddings
Query Engine
-
index.as_query_engine(): Creates a query engine -
The query engine is responsible for handling user questions and generating answers
5. Core Concept Explanation
-
Vector Index
-
The vector index is a core concept of LlamaIndex
-
It converts documents into vector form, enabling AI to understand and retrieve document content
-
Query Engine
-
The query engine is responsible for understanding user questions
-
Retrieving relevant content from the vector index
-
Using language models to generate final answers
6. Practical Application Example
Suppose we have some PDF documents, we can use it like this:
Create Query Engine
query_engine = index.as_query_engine()
Example Questions
questions = [
"What is the main content of the document?",
"What key concepts are mentioned in the document?",
"Can you summarize the core points of the document?"
]
Iterate Through Questions and Get Answers
for question in questions:
response = query_engine.query(question)
print(f"Question: {question}")
print(f"Answer: {response}\n")
7. Performance Optimization Suggestions
-
Document Storage
-
Consider persisting the index to avoid recreating it each time
-
You can use
storage_contextto achieve this -
Memory Management
-
For large documents, it is recommended to adjust the document chunk size appropriately
-
You can control this by setting the
chunk_sizeparameter
Conclusion
Through this simple example, we have implemented a basic document Q&A system. LlamaIndex‘s strength lies in its simplicity and extensibility; you can build upon this basic version:
-
Add support for more document formats
-
Implement more complex Q&A logic
-
Integrate it into existing applications
This is just the tip of the iceberg of LlamaIndex’s capabilities; in the upcoming series of articles, we will explore more advanced features and application scenarios.