
Welcome to LlamaIndex 🦙
LlamaIndex (formerly GPT Index) is a data framework for ingesting, structuring, and accessing private or domain-specific data for LLM applications.
🚀 Why Choose LlamaIndex?[1]
At their core, LLMs provide a natural language interface between humans and inferred data. The widely available models are pre-trained on a large amount of publicly available data, from Wikipedia and mailing lists to textbooks and source code. Applications built on LLMs often need to utilize private or domain-specific data to enhance these models. Unfortunately, this data may be scattered across different applications and data stores. It can be data behind APIs, data in SQL databases, or trapped in PDFs and slides.
This is where LlamaIndex comes in.
🦙 How Can LlamaIndex Help?[2]
LlamaIndex provides the following tools:
•Data Connectors ingest your existing data from its native source or format. These can be APIs, PDFs, SQL, and many other formats.•Data Indexing structures your data, generating an intermediate representation that is easy for LLMs to use and efficient.•Engines provide natural language access to your data. For example: • The Query Engine is a powerful retrieval interface for knowledge-enhanced outputs.• The Chat Engine is a conversational interface for multi-turn interactions with data.•Data Agents are knowledge workers powered by LLMs, enhanced through various tools, including simple assistant functions, API integrations, and more.•Application Integration connects LlamaIndex with other parts of your ecosystem. This can be LangChain, Flask, Docker, ChatGPT, or… anything else! Who Is LlamaIndex Designed For?
LlamaIndex provides tools for beginners, advanced users, and everyone in between.
Our high-level API allows beginner users to utilize LlamaIndex for data ingestion and querying with just five lines of code.
For more complex applications, our low-level API allows advanced users to customize and extend any module—data connectors, indexing, retrievers, query engines, re-ranking modules—to meet their needs.
Getting Started[3]
pip install llama-index
Our documentation contains detailed installation instructions[4] and a getting started tutorial[5] to build your first application with just five lines of code! Once you are up and running, High-Level Concepts[6] provides an overview of the modular architecture of LlamaIndex. For more practical examples, check out our end-to-end tutorials[7] or learn how to customize[8] components to fit your specific needs. Note: We also have a TypeScript package! Repository[9], Documentation[10]
🗺️ Ecosystem
To download or contribute code, find LlamaIndex here:
•Github: https://github.com/jerryjliu/llama_index•PyPi:•LlamaIndex: llama-index · PyPI[11].•GPT Index (duplicate): gpt-index · PyPI[12].•NPM (Typescript/Javascript):•Github: GitHub – run-llama/LlamaIndexTS: LlamaIndex is a data framework for your LLM applications[13]•Docs: https://ts.llamaindex.ai/•LlamaIndex.TS: Downloads[14]
Community[15]
Need help? Have feature suggestions? Join the LlamaIndex community:
•Twitter: https://twitter.com/llama_index•Discord https://discord.gg/dGcwcsnxhU
Related Projects[16]
•🏡 LlamaHub: https://llamahub.ai[17] | A large (and growing!) collection of custom data connectors•🧪 LlamaLab: GitHub – run-llama/llama-lab[18] | Ambitious projects built on LlamaIndex
Advanced Concepts
LlamaIndex helps you build LLM-based applications on custom data (e.g., Q&A, chatbots, and agents).
In this advanced concepts guide, you will learn about:
•Retrieval-Augmented Generation (RAG) paradigm combining LLMs with custom data.•Key concepts and modules in LlamaIndex for composing your own RAG pipeline. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a paradigm for enhancing natural language models (LLMs) using custom data. It generally includes two phases:
1.Indexing Phase: Preparing the knowledge base,2.Query Phase: Retrieving relevant context from the knowledge base to assist the LLM in answering questions.
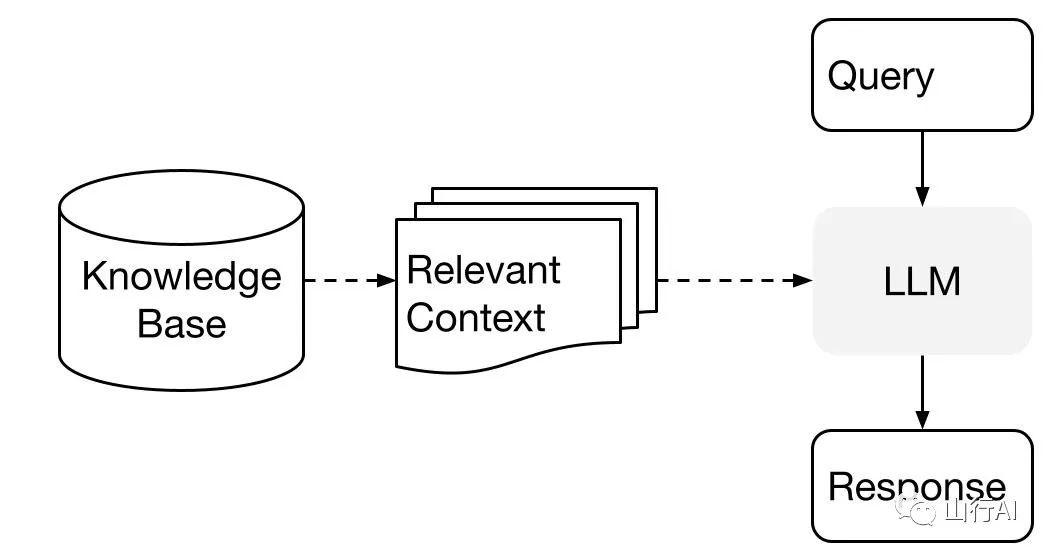
LlamaIndex provides the necessary toolkit to make these two steps very easy. Let’s explore each phase in detail.
Indexing Phase
LlamaIndex helps you prepare the knowledge base through a set of data connectors and indexing.

Data Connectors[19]: Data connectors (i.e., Reader) import data from various data sources and formats, transforming it into a simple Document representation (text and simple metadata).
Documents/Nodes[20]: A Document is a universal container around any data source, such as PDFs, API outputs, or data retrieved from a database. A Node is the atomic unit of data in LlamaIndex, representing a “chunk” of the source Document. It is a rich representation containing metadata and relationships (to other nodes) for accurate and expressive retrieval operations. Data Indexing: Once you import data, LlamaIndex will help you index the data into an easily retrievable format. Behind the scenes, LlamaIndex parses the raw documents into an intermediate representation, computes vector embeddings, and infers metadata. The most commonly used index is the VectorStoreIndex[21].
Query Phase
In the query phase, the RAG pipeline retrieves the most relevant context based on user queries and passes it along with the query to the LLM (language model) to synthesize a response. This provides the LLM with up-to-date knowledge not present in its original training data (while reducing hallucinations). The key challenge in the query phase is retrieval, orchestration, and reasoning (possibly across multiple) knowledge bases. LlamaIndex provides composable modules to help you build and integrate RAG pipelines for Q&A (query engine), chatbots (chat engine), or as agents. These building blocks can be customized based on ranking preferences and reason in a structured way to handle multiple knowledge bases.
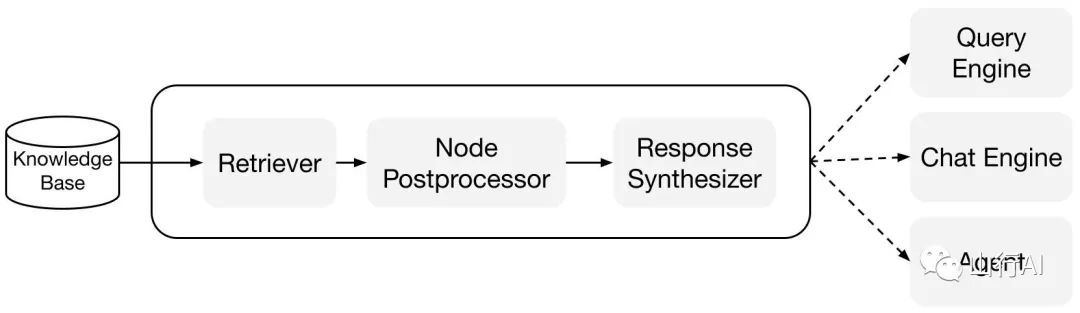
Building Blocks
Retrievers[22]: Retrievers define how to efficiently retrieve relevant context from the knowledge base (i.e., index) given a query. The specific retrieval logic varies for different indexes, with dense retrieval being the most popular for vector indexes.
Node Postprocessors[23]: Node postprocessors receive a set of nodes and apply transformations, filtering, or reordering logic to them. Response Synthesizers[24]: Response synthesizers generate responses from the LLM based on the user query and the given set of retrieved text blocks.
Pipelines[25]
Query Engine[26]: The query engine is an end-to-end pipeline that allows you to ask questions of the data. It receives a natural language query and returns an answer while retrieving and passing relevant context to the LLM.
Chat Engine[27]: The chat engine is an end-to-end pipeline for conversing with data (not just single question and answer interactions). Agents[28]: Agents are automated decision-makers powered by LLMs that interact with the world through a set of tools. Agents can be used like query engines or chat engines. The main difference is that agents dynamically decide the best sequence of actions rather than operating according to predetermined logic. This gives them added flexibility to handle more complex tasks.
•Document Q&A[29]•Chatbots[30]•Agents[31]•Knowledge Graphs[32]•Structured Data[33]•Full-Stack Web Applications[34]•Private Settings[35]•Fine-tuning Llama 2 for Text-to-SQL[36]•Fine-tuning GPT-3.5 to GPT-4[37]
Disclaimer
This article is translated and organized by Shanhang from: https://gpt-index.readthedocs.io/en/latest/index.html, primarily for the purpose of learning and organizing AI technology knowledge. If you find it useful, please follow, like, and bookmark!
References
[1] Permalink to this heading: https://gpt-index.readthedocs.io/en/latest/index.html#why-llamaindex[2] Permalink to this heading: https://gpt-index.readthedocs.io/en/latest/index.html#how-can-llamaindex-help[3] Permanent link to this heading: https://gpt-index.readthedocs.io/en/latest/index.html#getting-started[4] Installation instructions: https://gpt-index.readthedocs.io/en/latest/getting_started/installation.html[5] Getting started tutorial: https://gpt-index.readthedocs.io/en/latest/getting_started/starter_example.html[6] High-Level Concepts: https://gpt-index.readthedocs.io/en/latest/getting_started/concepts.html[7] End-to-end tutorials: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/use_cases.html[8] Customization: https://gpt-index.readthedocs.io/en/latest/getting_started/customization.html[9] Repository: https://github.com/run-llama/LlamaIndexTS[10] Documentation: https://ts.llamaindex.ai/[11] llama-index · PyPI: https://pypi.org/project/llama-index/[12] gpt-index · PyPI: https://pypi.org/project/gpt-index/[13] GitHub – run-llama/LlamaIndexTS: LlamaIndex is a data framework for your LLM applications: https://github.com/run-llama/LlamaIndexTS[14] Downloads: https://www.npmjs.com/package/llamaindex[15] Permalink to this heading: https://gpt-index.readthedocs.io/en/latest/index.html#community[16] Permalink to this heading: https://gpt-index.readthedocs.io/en/latest/index.html#associated-projects[17] https://llamahub.ai: https://llamahub.ai/[18] GitHub – run-llama/llama-lab: https://github.com/run-llama/llama-lab[19] Data Connectors: https://gpt-index.readthedocs.io/en/latest/core_modules/data_modules/connector/root.html[20] Documents/Nodes: https://gpt-index.readthedocs.io/en/latest/core_modules/data_modules/documents_and_nodes/root.html[21] VectorStoreIndex: https://gpt-index.readthedocs.io/en/latest/core_modules/data_modules/index/vector_store_guide.html[22] Retrievers: https://gpt-index.readthedocs.io/en/latest/core_modules/query_modules/retriever/root.html[23] Node Postprocessors: https://gpt-index.readthedocs.io/en/latest/core_modules/query_modules/node_postprocessors/root.html[24] Response Synthesizers: https://gpt-index.readthedocs.io/en/latest/core_modules/query_modules/response_synthesizers/root.html[25] Permalink to this heading: https://gpt-index.readthedocs.io/en/latest/getting_started/concepts.html#pipelines[26] Query Engine: https://gpt-index.readthedocs.io/en/latest/core_modules/query_modules/query_engine/root.html[27] Chat Engine: https://gpt-index.readthedocs.io/en/latest/core_modules/query_modules/chat_engines/root.html[28] Agents: https://gpt-index.readthedocs.io/en/latest/core_modules/agent_modules/agents/root.html[29] Document Q&A: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/question_and_answer.html[30] Chatbots: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/chatbots.html[31] Agents: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/agents.html[32] Knowledge Graphs: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/graphs.html[33] Structured Data: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/structured_data.html[34] Full-Stack Web Applications: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/apps.html[35] Private Settings: https://gpt-index.readthedocs.io/en/latest/end_to_end_tutorials/privacy.html[36] Fine-tuning Llama 2 for Text-to-SQL: https://medium.com/llamaindex-blog/easily-finetune-llama-2-for-your-text-to-sql-applications-ecd53640e10d[37] Fine-tuning GPT-3.5 to GPT-4: https://colab.research.google.com/drive/1vWeJBXdFEObuihO7Z8ui2CAYkdHQORqo?usp=sharing