What Is LlamaIndex?
LlamaIndex is a data framework designed to enable LLM-based applications to ingest, structure, and access private or domain-specific data. It offers both Python and TypeScript versions.
https://docs.llamaindex.ai/en/stable/index.html
LLMs provide a natural language interface between humans and data. The widely available models are pre-trained on a large amount of publicly available data, such as Wikipedia, mailing lists, textbooks, source code, and more. However, while LLMs are trained on vast datasets, they have not encountered your data, which may be private or specifically related to the problem you are trying to solve. This data may reside in APIs, SQL databases, or be trapped in PDFs and slides.
LlamaIndex Features
LlamaIndex adopts a different approach called Retrieval-Augmented Generation (RAG). Unlike requiring LLMs to generate answers immediately, LlamaIndex:
-
First retrieves information from your data source, -
Adds it to your question as context, -
Asks LLMs to respond based on the enriched prompt.
RAG overcomes all three disadvantages of fine-tuning methods:
-
It is cheap since it does not involve training. -
It retrieves data only when you request it, so it always stays up to date. -
LlamaIndex can show you the retrieved documents, making it more trustworthy.
LlamaIndex imposes no restrictions on how you use LLMs. You can still use LLMs for autocomplete, chatbots, semi-autonomous agents, etc. (see use cases on the left). It simply makes LLMs more relevant to you.
LlamaIndex Tools
LlamaIndex provides the following tools:
-
Data Connectors to ingest your existing data from its native sources and formats. This can be APIs, PDFs, SQL, and more. -
Data Indexing to structure your data into an intermediate representation that LLMs can easily and efficiently use. -
Engines to provide natural language access to your data. For example: -
The query engine is a powerful retrieval interface for knowledge-enhanced outputs. -
The chat engine is a conversational interface for multi-message, back-and-forth interactions with the data. -
Data Agents are LLM-driven knowledge workers enhanced by tools, ranging from simple assistive functions to API integrations and more. -
Application Integration connects LlamaIndex with the rest of your ecosystem. This can be LangChain, Flask, Docker, ChatGPT, or anything else!
Installing LlamaIndex
pip install llama-index
Methods for installing optional dependencies that are typically required. Currently, these dependencies are divided into three groups:
-
pip install llama-index[local_models]installs tools useful for private LLMs, local inference, and HuggingFace models. -
pip install llama-index[postgres]is useful if you are using Postgres, PGVector, or Supabase. -
pip install llama-index[query_tools]provides tools for mixed search, structured output, and node post-processing.
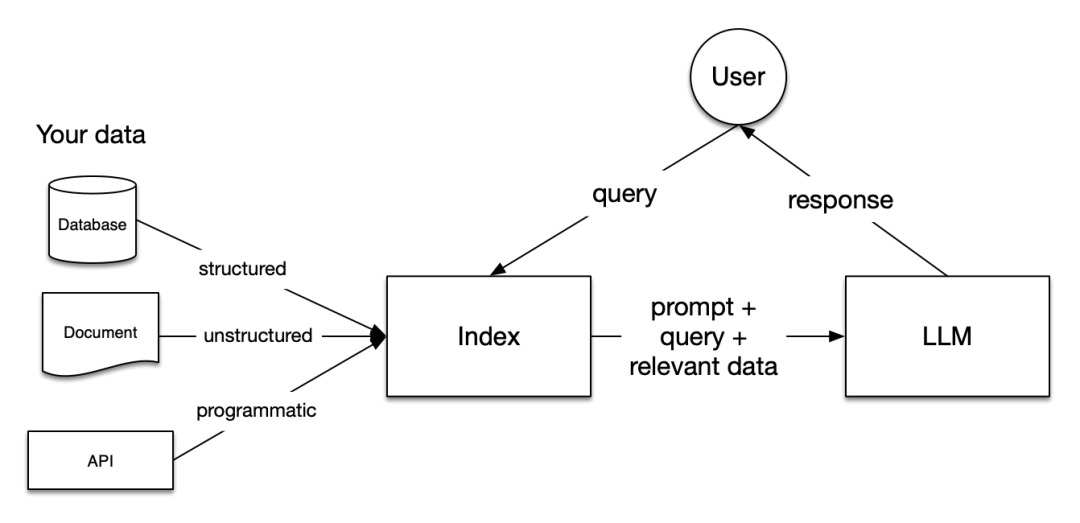
Retrieval-Augmented Generation (RAG)
LLMs are trained on massive datasets, but they have not encountered your data. Retrieval-Augmented Generation (RAG) addresses this by adding your data to what LLMs already have access to. Throughout this document, you will often see references to RAG.
In RAG, your data is loaded and prepared for querying or “indexing.” User queries act on the index, filtering your data down to the most relevant context. This context and your query are then passed to an LLM along with a prompt, which will provide a response.
Even if you are building a chatbot or agent, you will want to understand RAG techniques to bring data into your application.
Stages in RAG
There are five key stages in RAG that will be part of any larger application you build. These stages are:
-
Loading: This refers to getting your data from where it resides (be it text files, PDFs, another website, a database, or an API) into your pipeline. LlamaHub offers hundreds of connectors to choose from. -
Indexing: This means creating a data structure that allows querying of the data. For LLMs, this almost always means generating vector embeddings, which are numerical representations of the meaning of your data, along with many other metadata strategies to make it easy to accurately find contextually relevant data. -
Storage: Once your data is indexed, you almost always want to store your index and other metadata to avoid having to re-index it. -
Querying: For any given indexing strategy, you can query using LLMs and LlamaIndex data structures in various ways, including sub-queries, multi-step queries, and hybrid strategies. -
Evaluation: In any pipeline, checking its effectiveness relative to other strategies or when making changes is a crucial step. Evaluation provides an objective measure of the accuracy, fidelity, and speed of your responses to queries.

Important Concepts in Each Step
In each stage, you will also encounter some terms relevant to these stages.
Loading Stage
Nodes and Documents: A document is a container around any data source, such as a PDF, API output, or data retrieved from a database. A node is the atomic unit of data in LlamaIndex, representing a “block” of the source document. Nodes have metadata that associates them with the document they are in and other nodes.
Connectors: Data connectors (often referred to as readers) ingest data from different data sources and formats into documents and nodes.
Indexing Stage
Index: Once your data is ingested, LlamaIndex will help you index the data into a structure that is easy to retrieve. This often involves generating vector embeddings, which are stored in a dedicated database called vector storage. The index can also store various metadata about your data.
Embedding: LLMs generate numerical representations of data called embeddings. When filtering data for relevance, LlamaIndex converts queries into embeddings, and your vector storage will find data that is numerically similar to the query embeddings.
Querying Stage
Retriever: The retriever defines how to efficiently pull relevant context from the index given a query. Your retrieval strategy is crucial for the relevance of the data retrieved and the efficiency of doing so.
Router: The router determines which retriever will be used to pull relevant context from the knowledge base. More specifically, the RouterRetriever class is responsible for selecting one or more candidate retrievers to execute the query. They use selectors to choose the best option based on the metadata and queries of each candidate.
Node Post-Processor: The node post-processor takes a set of retrieved nodes and applies transformation, filtering, or reordering logic to them.
Response Synthesizer: The response synthesizer generates responses from the LLM using user queries and a set of retrieved text blocks.
Bringing It All Together
There are countless use cases for data-supported LLM applications, but they can broadly be categorized into three types:
Query Engines: A query engine is an end-to-end pipeline that allows you to ask questions of the data. It receives natural language queries and returns a response, along with the retrieved context that was passed to the LLM.
Chat Engines: A chat engine is an end-to-end pipeline for conversing with your data (as opposed to a single Q&A).
Agents: Agents are LLM-driven automated decision-makers that interact with the world through a set of tools. Agents can take any number of steps to complete a given task, dynamically deciding on the best course of action rather than following a predetermined sequence. This provides them with additional flexibility to handle more complex tasks.