

Every 3 hours on average, Llama 3.1 405B pre-training fails, is H100 the culprit?
Recently, someone discovered key points from the 92-page long Llama 3.1 paper released by Meta:

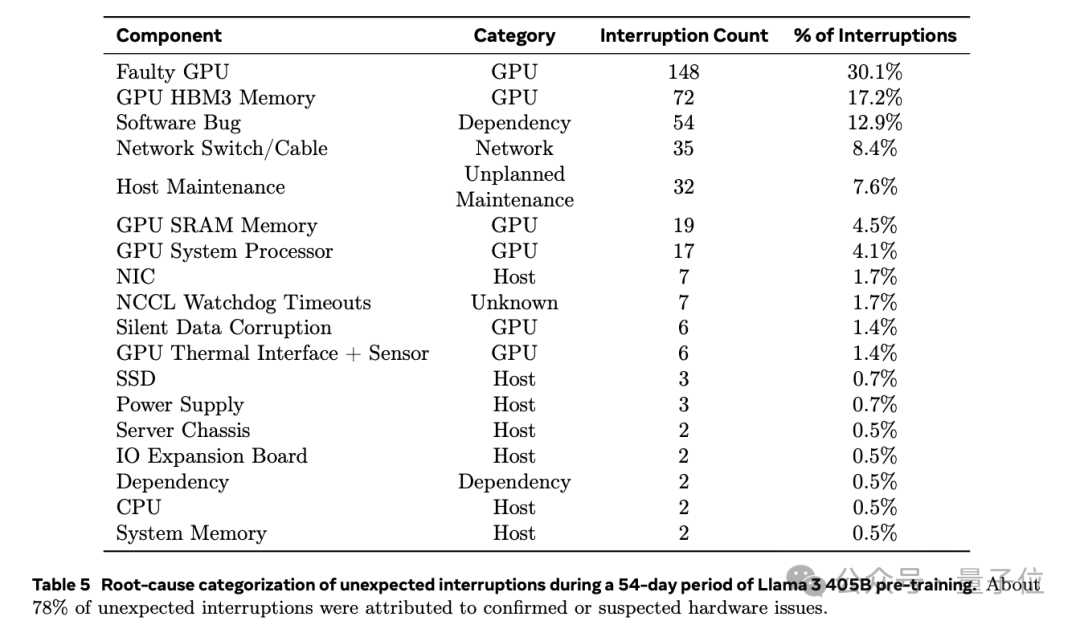
Llama 3.1 experienced a total of 466 task interruptions during its 54-day pre-training period. Only 47 of these were planned, 419 were purely accidental, with 78% of the accidents confirmed or suspected to be caused by hardware issues.
Moreover, GPU problems were the most severe, accounting for 58.7%.

Llama 3.1 405 model was trained on a cluster containing 16,384 Nvidia H100 80GB GPUs. Although there is an old saying about large-scale systems: the only certainty is that there will be failures.
However, this issue has attracted considerable attention from netizens.
Slow down, check the product.
Constant Failures, What to Do?
Specifically, among the 419 accidental interruptions, 148 times (30.1%) were caused by various GPU failures (including NVLink failures), and 72 times (17.2%) were specifically due to HBM3 memory failures.
Given the high power consumption of H100 at 700W and thermal stress, such results are not surprising.
Interestingly, only twice during the 54 days did the CPU experience failures.
Other failures not related to GPUs were caused by various factors, such as software bugs, network cables, etc.
Ultimately, the Llama 3.1 team maintained over 90% effective training time. Only three failures required significant manual intervention, while the rest were handled automatically.
So how did they cope?
To increase effective training time, the Llama 3.1 team stated they reduced task startup and checkpointing times and developed some tools for quick diagnosis and resolution of issues.
Among them, they extensively used PyTorch’s built-in NCCL flight recorder (developed by Ansel et al. in 2024), which is a feature that can record collective metadata and stack traces into a circular buffer, allowing for quick diagnosis of large-scale stalls and performance issues, especially those related to NCCLX.

With this tool, the team can effectively record the duration of each communication event and each collective operation, and automatically export trace data in the event of NCCLX Watchdog or Heartbeat timeouts.
They can also selectively enable some more computationally intensive tracking operations and metadata collection through online configuration changes (a method proposed by Tang et al. in 2015), without needing to re-release code or restart tasks.

The team noted that debugging issues in large-scale training is complex because the network uses both NVLink and RoCE simultaneously. Data transmission via NVLink is typically accomplished through load/store operations issued by CUDA kernels, and if remote GPUs or NVLink connections encounter problems, they often manifest as stalls in load/store operations within CUDA kernels without returning explicit error codes.
NCCLX, in close cooperation with PyTorch, has improved the speed and accuracy of fault detection and localization, allowing PyTorch to access the internal state of NCCLX and track relevant information.
Although it is impossible to completely avoid stalls caused by NVLink failures, the system monitors the status of the communication library and automatically times out when stalls are detected.
Additionally, NCCLX tracks kernel and network activity for each NCCLX communication and provides a “snapshot” of the internal state of collective operations in case of failure, including all completed and pending data transfers between all levels. The team analyzes this data to debug NCCLX scaling issues.
Sometimes, hardware issues may cause certain parts to appear to be running while slowing down, making it difficult to detect this situation. Even if only one part slows down, it can drag down the speed of thousands of other GPUs.
To address this, the team developed tools that prioritize communication from groups of processes that may have issues. Usually, investigating just a few of the most suspicious objects can effectively identify the slowing parts.
The team also observed an interesting phenomenon—the impact of environmental factors on large-scale training performance. During the training of Llama 3.1 405B, throughput varied by 1-2% depending on the time of day. This was due to higher temperatures at noon affecting GPU dynamic voltage and frequency adjustments.
During training, tens of thousands of GPUs may simultaneously increase or decrease power consumption, such as when all GPUs are waiting for checkpointing or collective communication to complete, or during the startup/shutdown of the entire training task. Such occurrences may cause instantaneous power fluctuations in data centers reaching tens of megawatts, posing a significant challenge to the power grid.
Finally, the team stated:
As future larger Llama models expand training scales, this challenge will persist.

AI Cluster Issues Awaiting Resolution
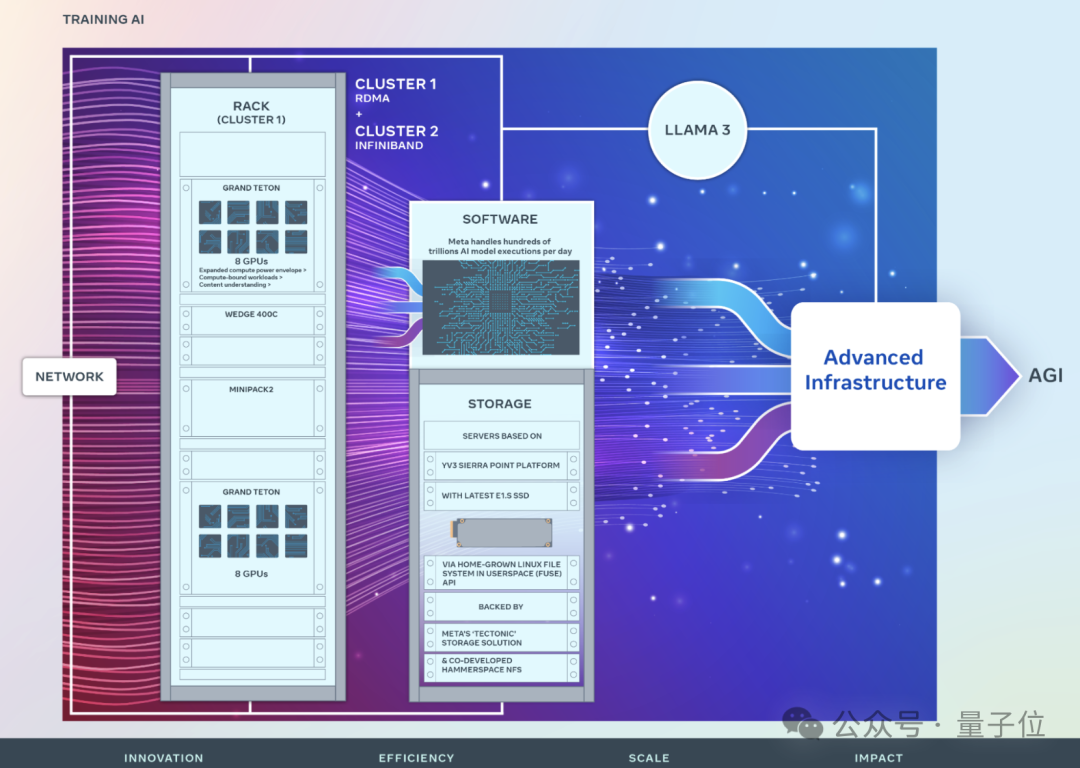
Meta first shared detailed information about its AI research supercluster (RSC) in 2022, which had 16,000 NVIDIA A100 GPUs, helping to build the first generation of AI models and playing a significant role in the development of the initial Llama and Llama 2.
△ From Meta
This March, Meta publicly revealed an AI cluster with 24,576 NVIDIA H100 GPUs, supporting Llama 3 and subsequent models.
They have also set a goal to add 350,000 NVIDIA H100 GPUs by the end of this year, as part of an overall computing power of nearly 600,000 H100 GPUs.

Such a large scale is certainly not a sustainable challenge. Of course, the issue of large-scale AI clusters causing failures during model training is somewhat an “ancient” problem that has been studied long ago.
The value of H100 itself goes without saying.

In the latest MLPerf training benchmark test last year, the NVIDIA H100 cluster swept all eight tests, setting new records in each and performing particularly well in large language model tasks.

Training GPT-3 in 11 minutes and finishing BERT in 8 seconds. In large language model tasks, the acceleration performance of the H100 cluster approaches linear growth. That is, as the number of processors in the cluster increases, the acceleration effect also increases almost proportionally.
This indicates that the communication efficiency between GPUs in the cluster is very high.

In addition, the H100 has also completed tasks such as recommendation algorithms, CV, medical image recognition, and speech recognition, being the only cluster to participate in all eight tests.
However, a month ago, an article by SemiAnalysis pointed out that building large-scale AI computing power clusters is very complex, and it is far more than just having the money to buy cards.
There are limitations in many aspects such as power, network design, parallelism, and reliability.


References: [1]https://ai.meta.com/research/publications/the-llama-3-herd-of-models/[2]https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/[3]https://www.semianalysis.com/p/100000-h100-clusters-power-network

Scan the QR code to add the assistant on WeChat
About Us
