1 New Intelligence Compilation
Source: distill.pub/2016/augmented-rnns
Authors: Chris Olah & Shan Carter, Google Brain
Translator: Wen Fei
[New Intelligence Guide] The Google Brain team, led by Chris Olah & Shan Carter, has summarized the development of Recurrent Neural Networks (RNNs) in 2016, highlighting four models that enhance conventional RNNs using attention mechanisms: the Neural Turing Machine, Attention Interface, Adaptive Computation Time, and Neural Programmer. They vividly illustrate related concepts with dynamic graphs and believe these four models will significantly impact the future development of RNNs. New Intelligence provides this Chinese translation, and you can access the original page for more information. All images are sourced from the original article. GitHub code: https://github.com/distillpub/post–augmented-rnns

(Image/Chris Olah & Shan Carter, Google Brain) Recurrent Neural Networks (RNNs) are one of the common methods in deep learning, allowing neural networks to process sequential data such as text, audio, and video. RNNs can distill a high-level understanding of a sequence, annotate it, or even generate new sequences from scratch!
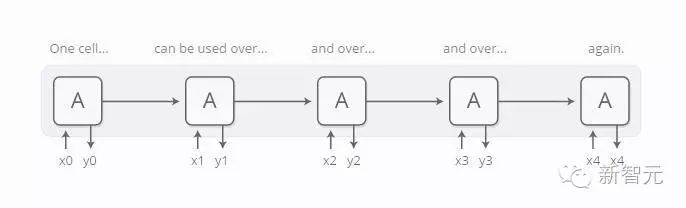 Each unit can be reused multiple times.
Each unit can be reused multiple times.
The basic design of RNNs involves complex long sequences, but a special type of RNN—Long Short-Term Memory (LSTM) networks—can handle this issue. LSTM models are very powerful and have achieved remarkable results in tasks such as translation, speech recognition, and image description. Consequently, RNNs have been widely used over the past few years.
As a result, we have seen many attempts to enhance RNNs with additional functionalities. Among them, the following four directions are particularly exciting:
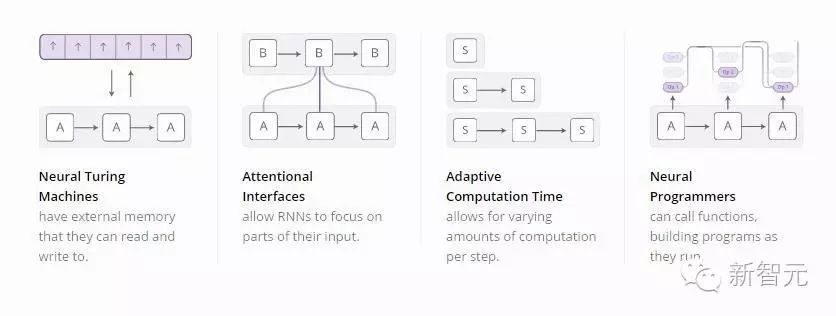
Individually, these techniques are sufficient to serve as extensions of RNNs, but even more astonishingly, they can be combined to apply to a broader range of scenarios. Furthermore, they all rely on the same underlying technique—attention.
We speculate that these “augmented RNNs” will play a significant role in expanding the capabilities of deep learning in the future.
The Neural Turing Machine (Graves, et al., 2014) combines RNNs with an external memory repository. Since vectors are the natural language of neural networks, memory becomes a set of vectors:
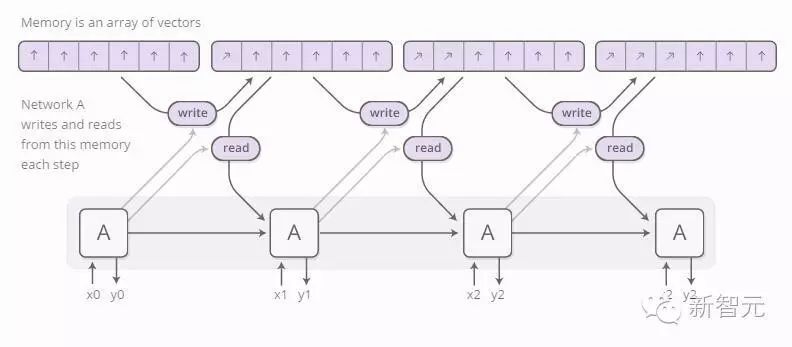
But how does reading and writing occur? The challenge lies in distinguishing each read and write operation. Specifically, we want to differentiate reads and writes that occur at different locations so that we can know where the information was read or written. This is not easy because storage addresses seem inherently discrete. To address this, NTM employs a very clever solution: it reads and writes everywhere at each step, just with varying degrees.
For example, let’s look at the case of reading information. The RNN does not have a specific single location but provides an “attention distribution” that describes how we distribute our attention across different storage locations. Therefore, the result of the reading operation becomes a weighted sum.
Similarly, we read information across all locations at once with different degrees. Here, there will also be an attention distribution that describes how we read information at each location. The form is as follows:
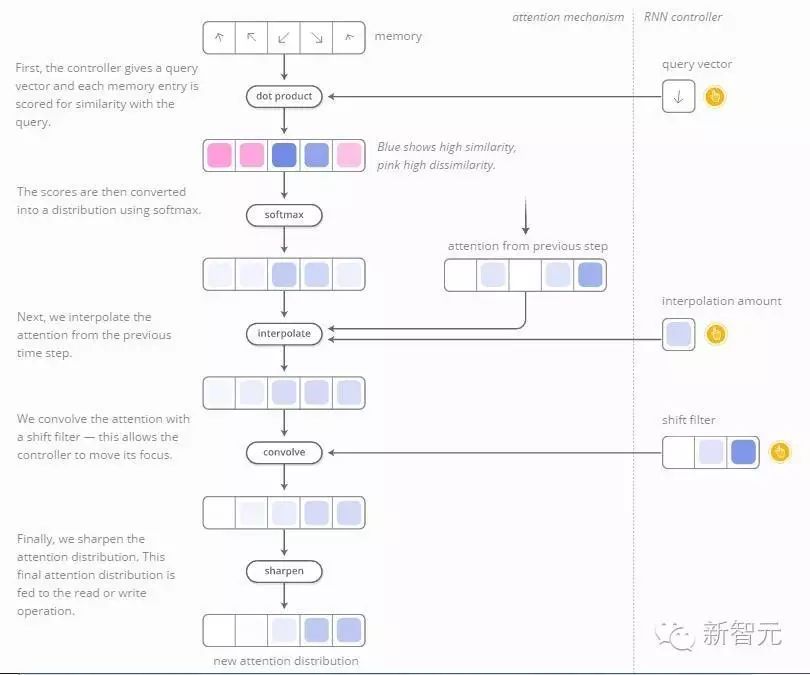
But how does NTM decide to focus attention on a particular location? They actually combine two different methods: content-based attention and location-based attention. Content-based attention allows NTM to search integrated storage and focus attention on the locations they are looking for, while location-based attention enables NTM to loop.
This reading and writing capability enables NTM to perform many simple algorithms that previous neural networks could not. For example, NTM can learn to store a long sequence in memory and loop, repeating it continuously. During this process, we can observe where they are reading and writing, allowing us to better understand NTM’s behavior.
NTM can also learn to imitate sorting tables and even learn to sort (though the method is somewhat cheating!). However, on the other hand, NTM still struggles with simple tasks like addition and multiplication.
Since the initial paper proposing NTM, several exciting explorations have been conducted in this direction. Neural GPU (Kaiser & Sutskever, 2015) overcame the addition and multiplication limitations of NTM. A paper by Zaremba & Sutskever in 2016 trained NTM using reinforcement learning, improving upon the original differential read/write basis. The Neural Random Access Machine proposed by Kurach et al. in 2015 is based on pointers. Other papers have explored differential data structures such as stacks and sequences (Grefenstette et al. 2015; Joulin & Mikolov, 2015). Memory networks (Weston et al., 2014; Kumar et al., 2015) are also a different means of solving similar problems.
Objectively speaking, the tasks these models can perform, such as learning to count, are not that difficult. Traditional program synthesis can easily achieve this. However, neural networks can accomplish many other things, and models like Neural Turing Machines (NTM) break through a significant limitation of neural networks.
Code (Access the original page for code)
Many of these models have open-source implementations. The open-source implementation for Neural Turing Machines includes Taehoon Kim’s TensorFlow, Shawn Tan’s Theano, Fumin’s Go, Kai Sheng Tai’s Torch, and Snip’s Lasagne. The open-source code related to Neural GPU has been included in TensorFlow’s model library. The open-source implementations of memory networks include Facebook’s Torch/Matlab, YerevaNN’s Theano, and Taehoon Kim’s TensorFlow.
When I translate a sentence, I pay special attention to the word I am currently translating. When I listen to audio, I pay close attention to the segment I am writing. If you ask me to describe the room I am sitting in, I will look around at the objects while describing it to you.
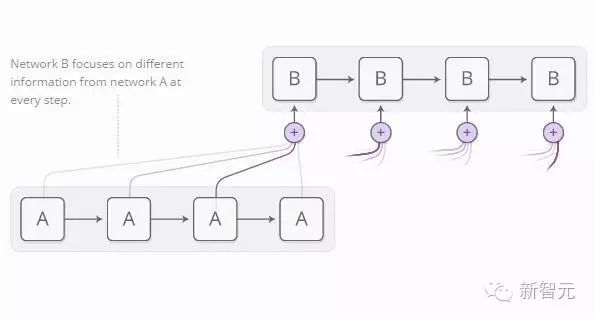
By using attention, neural networks can behave similarly, focusing only on a portion of the information provided to them. For example, one RNN can pay attention to the output of another RNN. At each step, this RNN focuses on different positions of the other RNN.
We want the attention to be differentiable so that we can learn where to concentrate. To achieve this, we use the same technique as the Neural Turing Machine: paying attention to every location but with varying degrees.
The attention distribution is usually generated based on content-based attention. The monitoring RNN generates a query that describes what it wants to focus on. The query’s dot product with each item generates a value that is input into SOFTMAX to create the attention distribution.
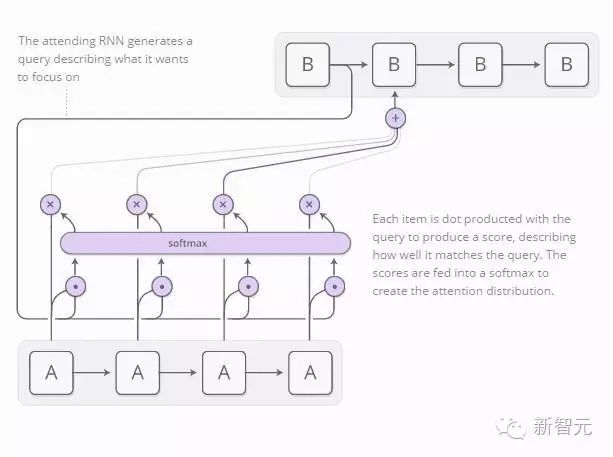
One major application of using attention between RNNs is translation (Bahdanau, et al., 2014). Traditional sequence-to-sequence models must convert the entire input into a single vector before expanding it back out. Attention allows the processing RNN to pass information and focus on it after the words have formed associations.
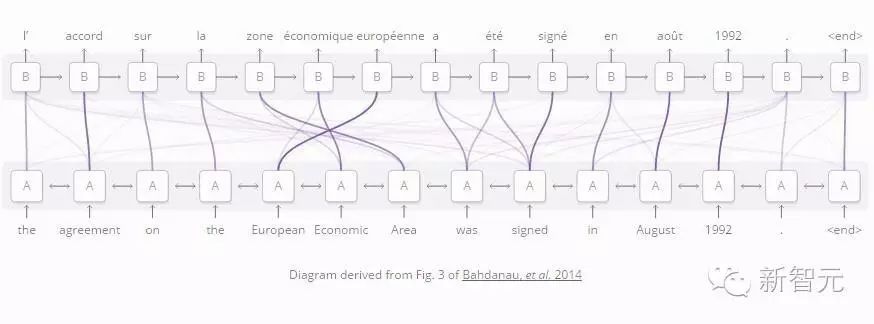
This type of attention between RNNs has many applications. In a paper by Chan et al. in 2015, it was used for speech recognition, where one RNN processed audio input while another RNN filtered the information, focusing only on the relevant parts to generate recordings.
Other applications include text analysis; for example, in a paper by Vinyals et al. in 2014, the model was allowed to scan its generated analysis tree. Additionally, a paper by Vinyals and Le in 2015 allowed the model to focus on previous parts of the dialogue when generating responses, establishing a dialogue model in this way.

Attention can also be used as an interface between convolutional neural networks and RNNs. This allows RNNs to focus on different locations during the image processing process. A popular application of this type of attention is image description. First, a convolutional network processes the image, and as this convolutional network generates individual words of the description, the RNN focuses on the convolutional network’s interpretation of the associated parts of the image. We can illustrate this process with an image:

More broadly, when you want to interact with a neural network that has repetitive outputs, attention interfaces can be used.
Attention interfaces are a powerful and versatile technique that has seen increasing use recently.
Standard RNNs perform the same amount of computation at each step, which seems counterintuitive. Of course, when things get a bit more challenging, the thinking should be more complex, right? This also limits RNNs to performing O(n) operations on a sequence of length n.
Adaptive Computation Time, proposed by Graves in 2016, is a method that allows RNNs to perform varying amounts of computation at each step. The principle is quite simple: let the RNN carry out multiple computation steps within each time period.
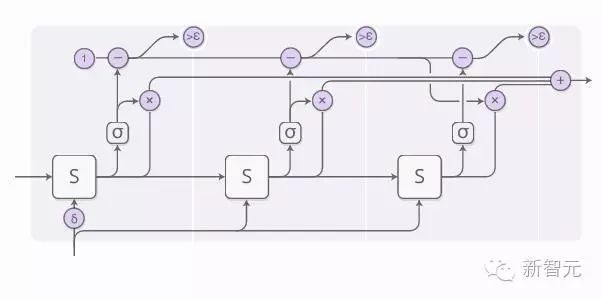
To enable the network to learn how many steps to take, we want the number of steps to be differentiable. We achieve this by implementing attention distribution on the number of steps required. The output is a weighted sum of each step’s output.
The previous image omitted some details. The following image is a complete illustration of performing 3 computation steps.
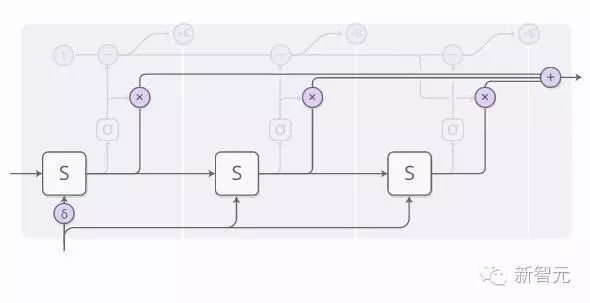
It looks a bit complex, so let’s explain it step by step. From a higher level, we are still running the RNN and outputting a weighted sum of each state.
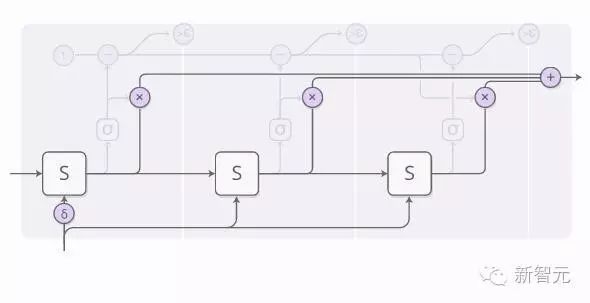
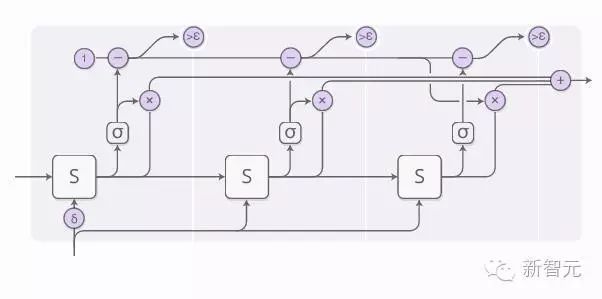
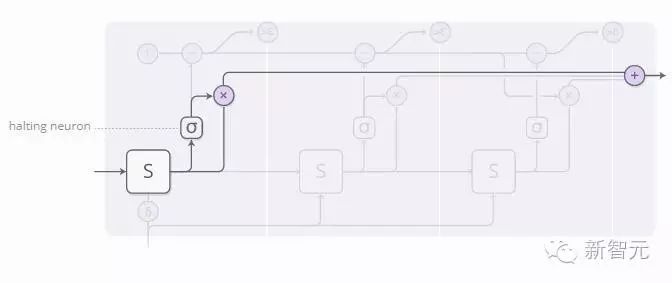
The weight of each step is determined by a “halting neuron.” This halting neuron is a sigmoid neuron that looks at the state of the RNN and provides a halting weight, which we can view as the probability of stopping at that step.
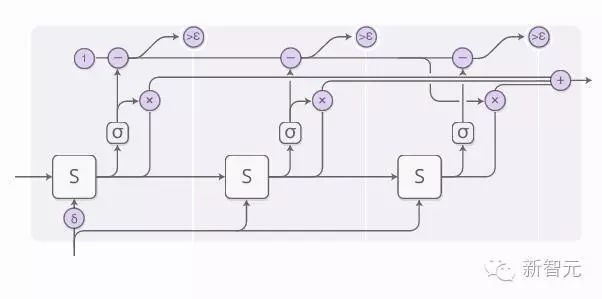
The sum of the halting weights we have equals 1. Following this line, when it is < ε, we stop.
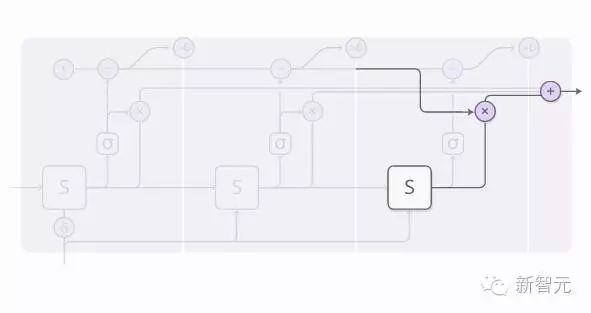
When we stop, there may still be some halting values left. What should we do then? These values will be given to the next steps, but we will not compute these steps. Therefore, we will aggregate all of these remaining values to the last step.
When training the adaptive computation time model, a “ponder cost” must be added to the cost function. The ponder cost penalizes the model based on the computational load it incurs. The larger the ponder cost, the smaller the time sacrifice the model makes to improve performance. In other words, the less computation time the model spends, the corresponding accuracy of the computation results will also decrease.
Adaptive Computation Time is a very new concept, but we believe it and other similar concepts will be of great significance.
Code
Currently, there is only an open-source implementation of Adaptive Computation Time by Mark Neumann in TensorFlow.
Neural networks can perform many tasks, but some of the simplest things, such as basic arithmetic calculations, they cannot manage. It becomes necessary to find a way to combine neural networks with conventional programming to leverage the strengths of both.
The Neural Programmer proposed by Neelakantan et al. in 2015 is one such method. The Neural Programmer can create programs to solve problems. In fact, the Neural Programmer can generate these programs without correct programming samples. In other words, the Neural Programmer discovers how to generate programs to complete certain tasks.
The generated program is a series of operations. Each operation takes the output of the previous operation as input. Therefore, a command might be “add the output of operation 2 from the previous step to the output of operation 1 from the previous step.”

Each operation generates a program, which is managed by a controller RNN. At each step, the controller RNN outputs a probability distribution describing the next operation. For example, we might be very clear that we want to perform addition as the first step, but whether the second step is multiplication or division might be uncertain, and so on…
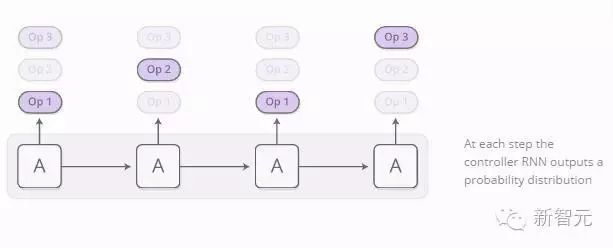
The distribution of each operation can be evaluated. We focus on all operations and then take the mean of the outputs, weighted by the probabilities of each operation.
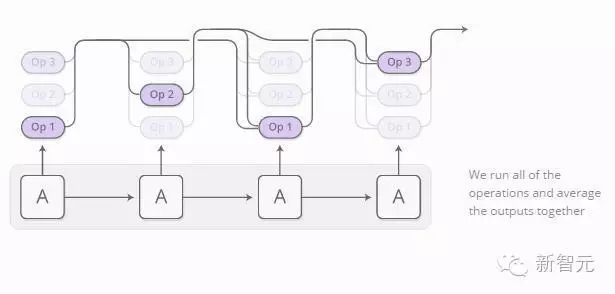
As long as we determine the derivative through operations, the output of the program concerning the probabilities is differentiable. We can establish a loss and then train the neural network to generate programs that yield correct answers. Through this method, the Neural Programmer learns to generate programs without good program samples. The only supervision needed is the answer generated by the program.
The Neural Programmer has other versions as well. The Neural Programmer is not the only method to enable neural networks to program. The Neural Programmer-Interpreter proposed by Reed & de Freitas in 2015 can also accomplish some interesting tasks, but it requires supervision of the correct program format.
Overall, the Neural Programmer bridges the gap between traditional programming and neural networks, which is very important. The Neural Programmer may not be the ultimate solution, but many important lessons can be learned from it.
Code
Currently, it seems there is no open-source implementation of the Neural Programmer. However, there is a Neural Programmer-Interpreter in Keras by Ken Morishita.
References
-
Alemi, A. A., Chollet, F., Irving, G., Szegedy, C., & Urban, J. (2016). DeepMath-Deep Sequence Models for Premise Selection. arXiv preprint arXiv:1606.04442.
-
Andrychowicz, M., & Kurach, K. (2016). Learning Efficient Algorithms with Hierarchical Attentive Memory. arXiv preprint arXiv:1602.03218.
-
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
-
Chan, W., Jaitly, N., Le, Q. V., & Vinyals, O. (2015). Listen, attend and spell. arXiv preprint arXiv:1508.01211.
-
Graves, A., Wayne, G., & Danihelka, I. (2014). Neural Turing Machines. arXiv preprint arXiv:1410.5401.
-
Graves, A. (2016). Adaptive Computation Time for Recurrent Neural Networks. arXiv preprint arXiv:1603.08983.
-
Grefenstette, E., Hermann, K. M., Suleyman, M., & Blunsom, P. (2015). Learning to transduce with unbounded memory. In Advances in Neural Information Processing Systems (pp. 1828-1836).
-
Joulin, A., & Mikolov, T. (2015). Inferring algorithmic patterns with stack-augmented recurrent nets. In Advances in Neural Information Processing Systems (pp. 190-198).
-
Kaiser, Ł., & Sutskever, I. (2015). Neural GPUs learn algorithms. arXiv preprint arXiv:1511.08228.
-
Kumar, A., Irsoy, O., Su, J., Bradbury, J., English, R., Pierce, B., Ondruska, P., Gulrajani, I. & Socher, R., (2015). Ask me anything: Dynamic memory networks for natural language processing. arXiv preprint arXiv:1506.07285.
-
Kurach, K., Andrychowicz, M., & Sutskever, I. (2015). Neural random-access machines. arXiv preprint arXiv:1511.06392.
-
Neelakantan, A., Le, Q. V., & Sutskever, I. (2015). Neural programmer: Inducing latent programs with gradient descent. arXiv preprint arXiv:1511.04834.
-
Olah, C. (2015). Understanding LSTM Networks.
-
Reed, S., & de Freitas, N. (2015). Neural programmer-interpreters. arXiv preprint arXiv:1511.06279.
-
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M. & Dieleman, S. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
-
Vinyals, O., Kaiser, Ł., Koo, T., Petrov, S., Sutskever, I., & Hinton, G. (2015). Grammar as a foreign language. In Advances in Neural Information Processing Systems (pp. 2773-2781).
-
Vinyals, O., & Le, Q. (2015). A neural conversational model. arXiv preprint arXiv:1506.05869.
-
Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer networks. In Advances in Neural Information Processing Systems (pp. 2692-2700).
-
Weston, J., Chopra, S., & Bordes, A. (2014). Memory networks. arXiv preprint arXiv:1410.3916.
-
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R.S. & Bengio, Y., 2015. (2015). Show, attend and tell: Neural image caption generation with visual attention. arXiv preprint arXiv:1502.03044, 2(3), 5.
-
Zaremba, W., & Sutskever, I. (2015). Reinforcement learning neural Turing machines. arXiv preprint arXiv:1505.00521, 362.
Compiled from: Chris Olah & Shan Carter, “Attention and Augmented Recurrent Neural Networks”, Distill, 2016. distill.pub/2016/augmented-rnns/
The AI WORLD 2016 World Artificial Intelligence Conference, co-hosted by the Chinese Automation Society and New Intelligence, is about to grandly open. Conference official website:http://aiworld2016.com/