
Click the above “MLNLP” to select the “star” public account
Essential content delivered promptly
Author: Yulin Ling
Vanishing Gradient

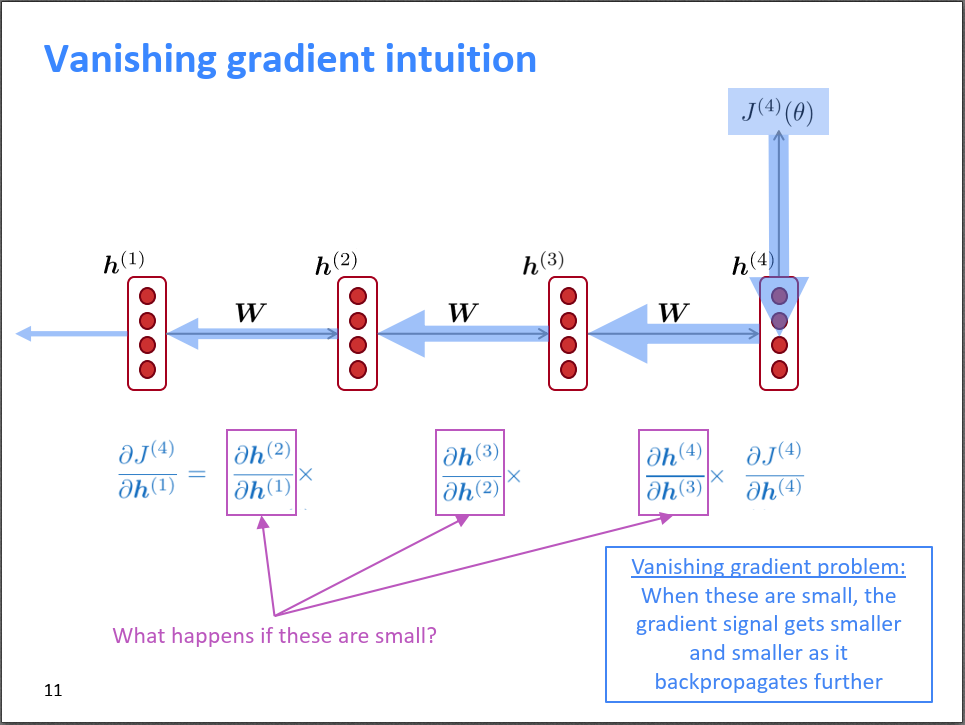

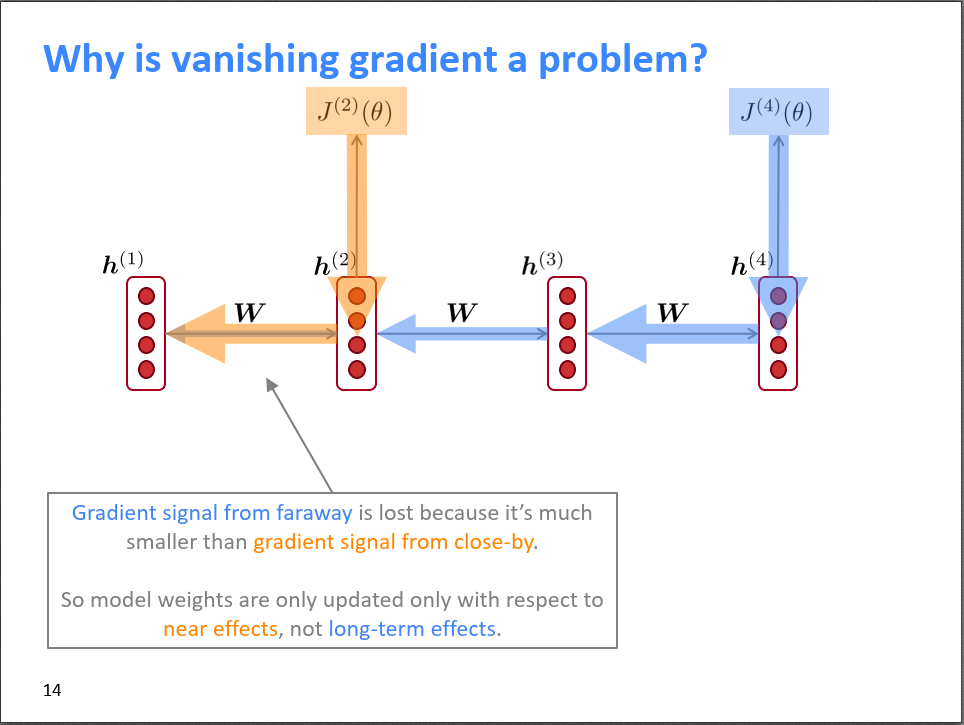

Similarly, if there is gradient explosion, according to the gradient descent update formula, the parameters will update very significantly in an instant, causing the network to oscillate, and even resulting in Inf or NaN.

A better solution for gradient explosion is gradient clipping, which means if the gradient norm exceeds a certain threshold, the gradient norm is reduced by a certain proportion without changing its direction. As shown in the figure below, the left subplot shows the situation without gradient clipping. Due to the gradient explosion problem of RNN, as it approaches a local minimum, the gradient is large, causing the parameters to suddenly climb up the cliff and then fly to a random area on the right, missing the local minimum in between. The right subplot shows the situation after gradient clipping is applied, where the update step becomes smaller, and the parameters stabilize near the local minimum.

In summary, gradient explosion is relatively easier to solve, but the vanishing gradient problem is not so simple. In RNN, at each time point t
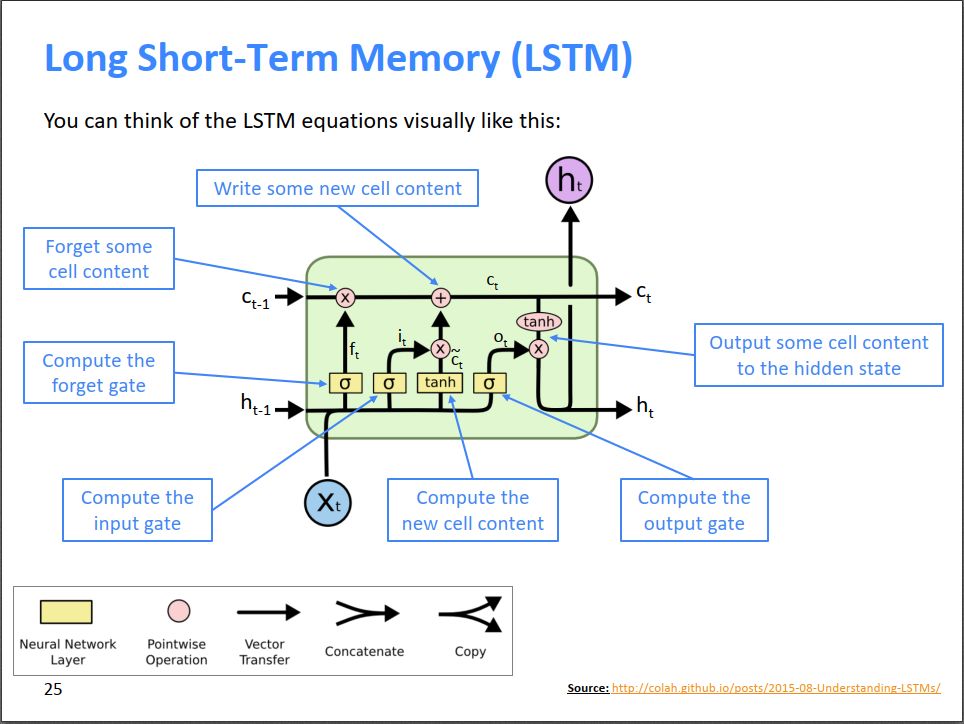
LSTM
LSTM is such an idea. Please understand it in conjunction with the following two diagrams:
It is not difficult to understand when combining the formulas in the above figure and the schematic diagram below.


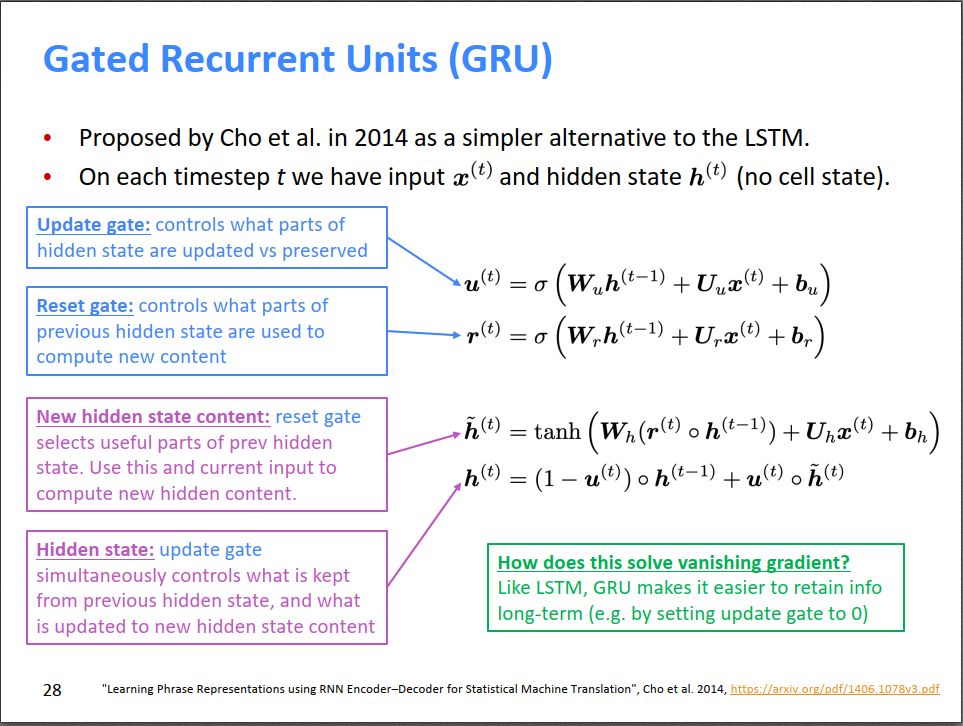
GRU


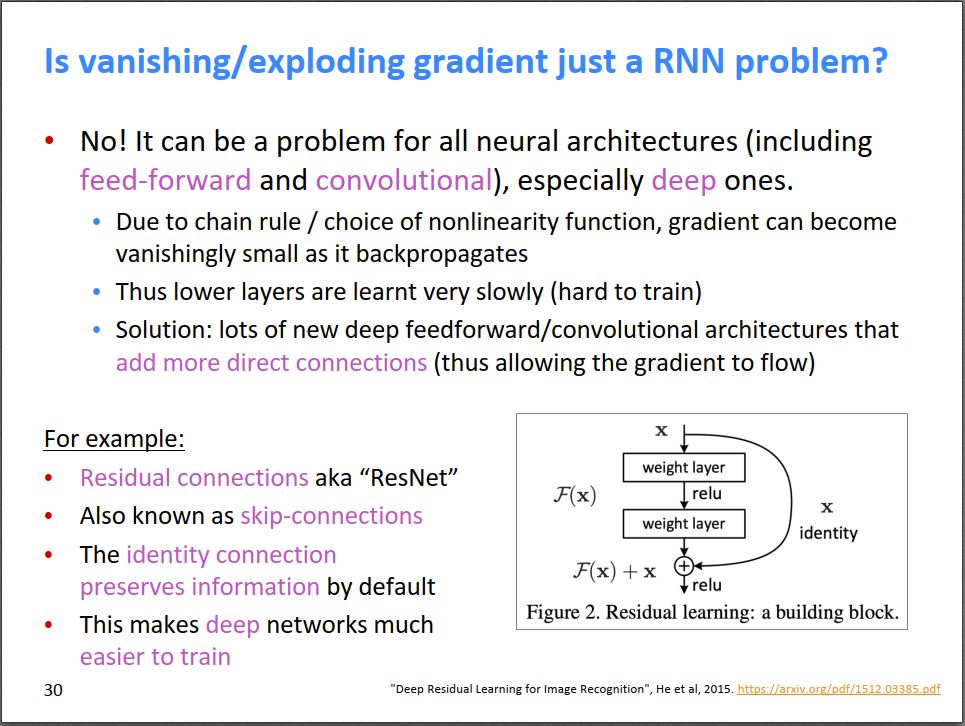
More radical is DenseNet, which connects many neurons across multiple layers, meaning there are more pathways without intermediaries, further reducing the vanishing gradient problem.



Although all neural networks have the problem of vanishing gradients, this issue is more severe in RNNs because they multiply the same weight matrix W, and RNNs are aimed at sequence problems, which tend to be deeper.
Bidirectional RNN
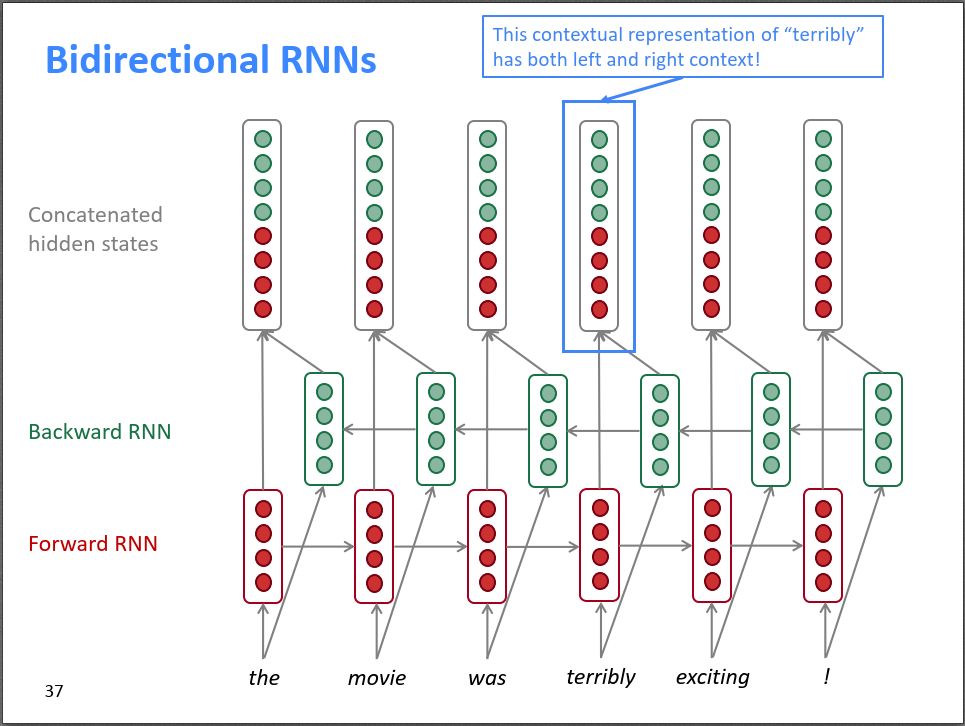
Assuming we are performing sentiment classification on a sentence, as shown in the figure below. For the word “terribly”, a conventional RNN can only see the information on the left and cannot see the information on the right, because the network processes from left to right. Looking at “terribly” alone or from left to right, without seeing “exciting”, one might think “terribly” is a negative word, but when combined with “exciting” on the right, it becomes a strong positive word, thus it is necessary to consider information from both the left and right sides simultaneously.
Bidirectional RNNs consist of two RNNs, one processing from left to right and the other from right to left. The parameters of the two RNNs are independent. Finally, the outputs of the two RNNs are concatenated to form the overall output. Therefore, for the word “terribly”, its gradient can simultaneously see information from both the left and right sides.

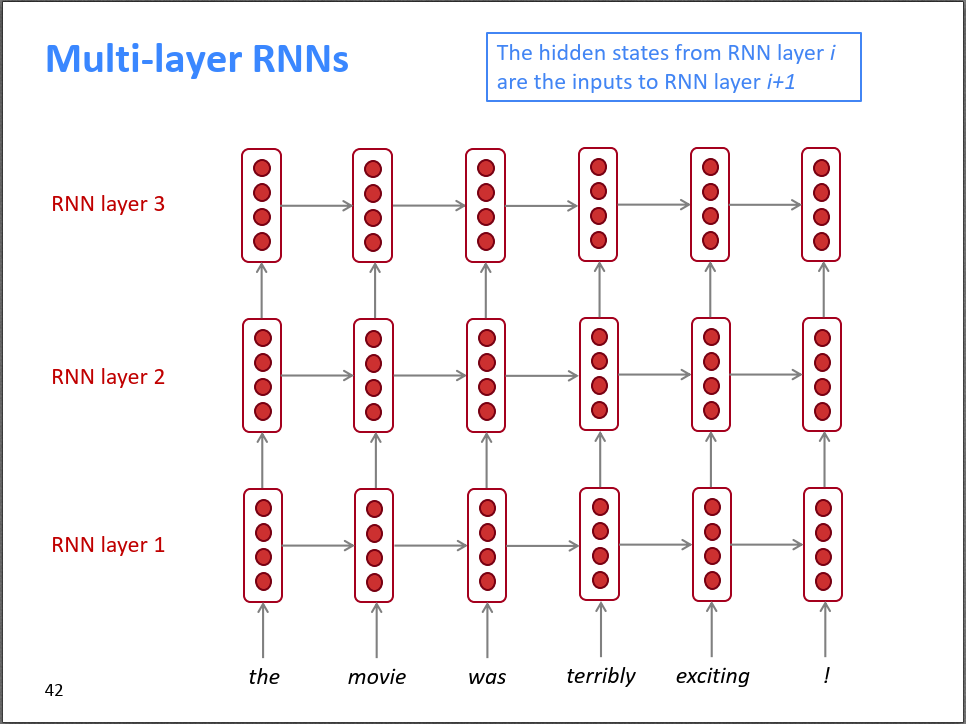
RNNs typically do not have many layers, usually not more than 8 layers. On one hand, this is due to the serious vanishing gradient problem in RNNs, and on the other hand, RNNs are trained in a serial manner, making it time-consuming to train if the network is too deep.
In summary, a picture is worth a thousand words.

Recommended Reading:
ByteDance announces plans for a comprehensive web search, marking a real crisis for Baidu
From Word2Vec to Bert, discussing the evolution of word vectors (Part 1)
Chen Lijie, a PhD student from Tsinghua’s Yao Class, wins Best Student Paper at a top theoretical computer science conference
