

With the explosive popularity of large language models (LLM), communities and scholars have gradually focused on the weaknesses of LLMs, such as their inadequacies in numerical reasoning with large numbers or their inability to acquire the latest data beyond the pre-training data. To compensate for these shortcomings, a wave of interaction between LLMs and external tools (such as search engines, calculators, APIs, etc.) has recently emerged. ReAct is currently the most common and general augmented language model paradigm, inspired by traditional reinforcement learning, which constructs a thought (Thought), action (Action), and observation (Observation) chain of reasoning through prompts, gradually prompting the large language model to generate observations based on the outputs of the current tools, thereby producing further reasoning. This paradigm has been widely applied in the recent popular projects such as Auto-GPT and LangChain.
However, recent research on ReWOO (Reasoning WithOut Observation) points out that augmented language models based on ReAct suffer from a general redundancy problem, leading to excessive computational overhead and lengthy token usage. In contrast, ReWOO decouples the “foreseeable reasoning” of the large language model from tool execution through modularization, achieving several times the token efficiency on tasks like HotpotQA, while also improving model performance and robustness in complex environments.
Paper title:
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Paper link:
https://arxiv.org/abs/2305.18323
Project link:
https://github.com/billxbf/ReWOO
Method Overview
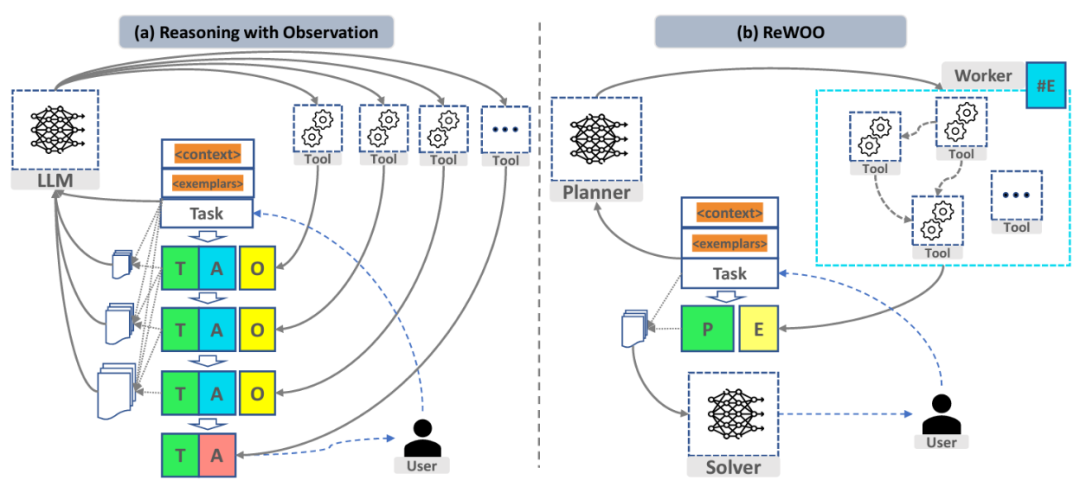
Augmented language models achieve information acquisition or environmental influence by encouraging LLMs to interact with tools. If we compare large prediction models to the human brain, augmented language models provide them with limbs. The figure below (a) illustrates the current general ReAct paradigm. When a user inputs a task, the context prompt (Context) and possible samples (Exemplar) are fed into the LLM, which then generates a thought (T), an action (A), and subsequently calls tools to produce an observation (O). Since LLMs are stateless, all previous prompts, samples, tasks, and the history of T, A, and O are accumulated and input into the next LLM, leading to iterative new reasoning. As the number of reasoning steps increases or if any step has long tokens, it results in excessively long input tokens for the next LLM call and additional computational expenses due to high repetition.
In contrast, (b) shows the design paradigm of ReWOO, where a planner decomposes the task into a blueprint for calling tools. After obtaining all tool outputs, the plan (P) and clues (E) are fed into an interpreter (Solver) for summarization and output. In this process, there are no repeated token prompts for tool outputs, and only two LLM calls are needed.
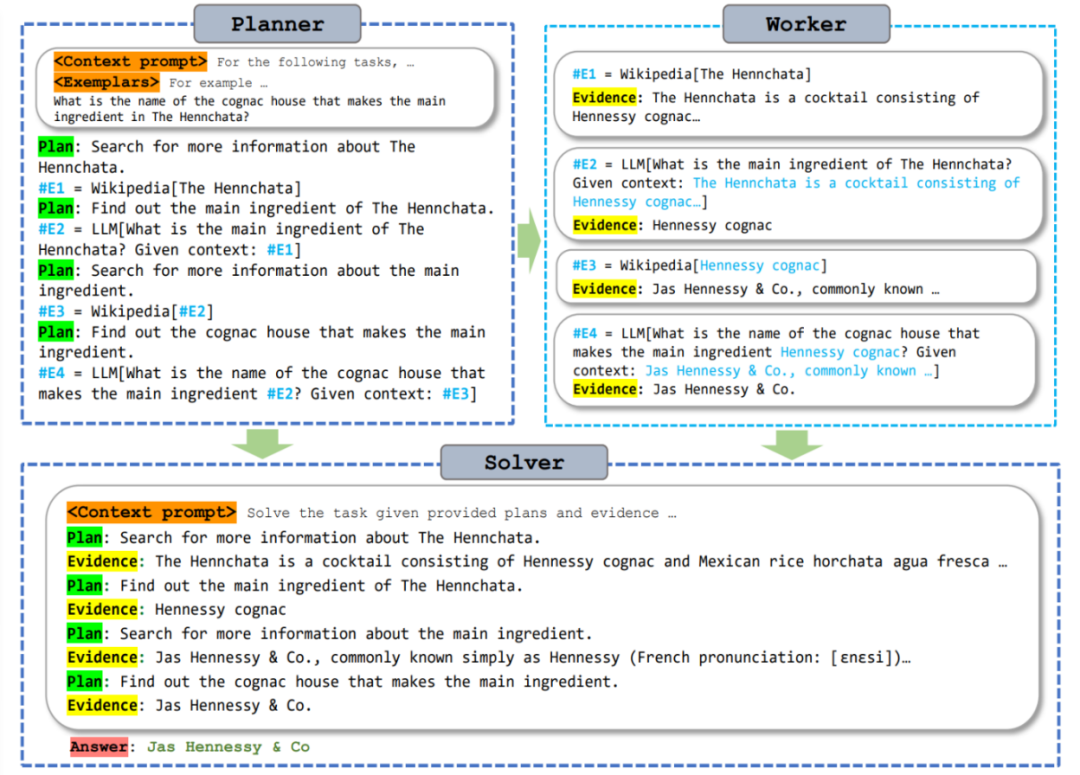
The following diagram provides a specific example of how the ReWOO paradigm uses context learning to instruct the planner to generate interdependent plans and tool blueprints, which also form a directed acyclic graph (DAG). Tools are called based on the blueprint, while the results are stored as “evidence”; finally, an interpreter outputs the final result.
Experimental Analysis
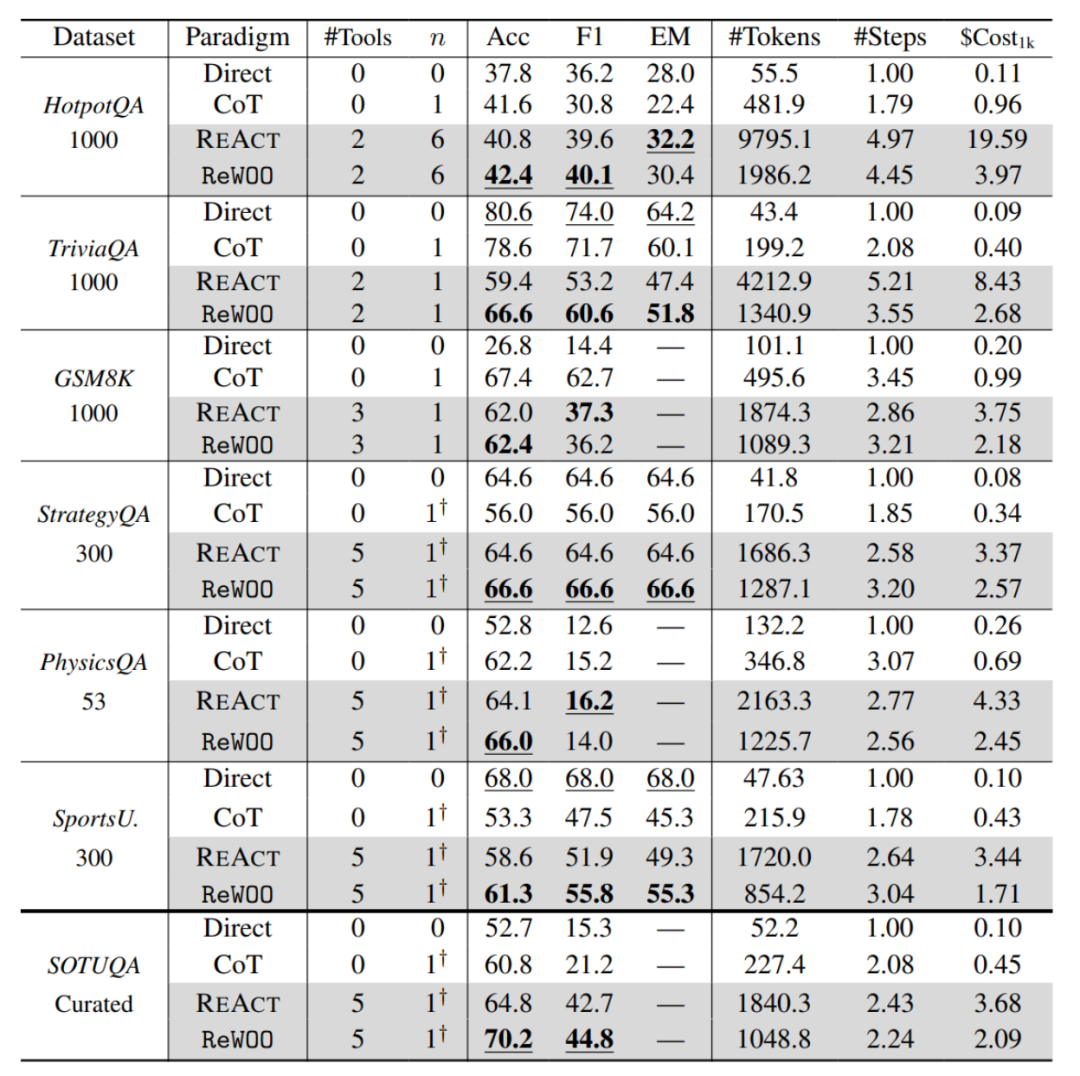
The authors compared the overhead and performance differences between ReWOO and ReAct across multiple NLP benchmarks and found that, whether in zero-shot or few-shot learning scenarios, ReWOO significantly reduced token overhead. Moreover, counterintuitively, even without observations from current tools to inspire the next step of thinking, LLMs under the ReWOO framework generally exhibited higher performance. Further case analysis indicated that this is due to the excessive load on reasoning caused by long contexts and potential tool errors or irrelevant information, which mislead LLMs into incorrect reasoning and even forgetting the original task.
To validate this hypothesis, when the authors allowed all tools to output errors and further compared the performance of the two paradigms, they found that even in such extreme environments, ReWOO still maintained some accuracy (because the interpreter could self-answer some questions). However, ReAct nearly completely failed and fell into a deadlock, unable to answer any remaining questions. This indirectly demonstrates the relative robustness of ReWOO in complex real-world environments.
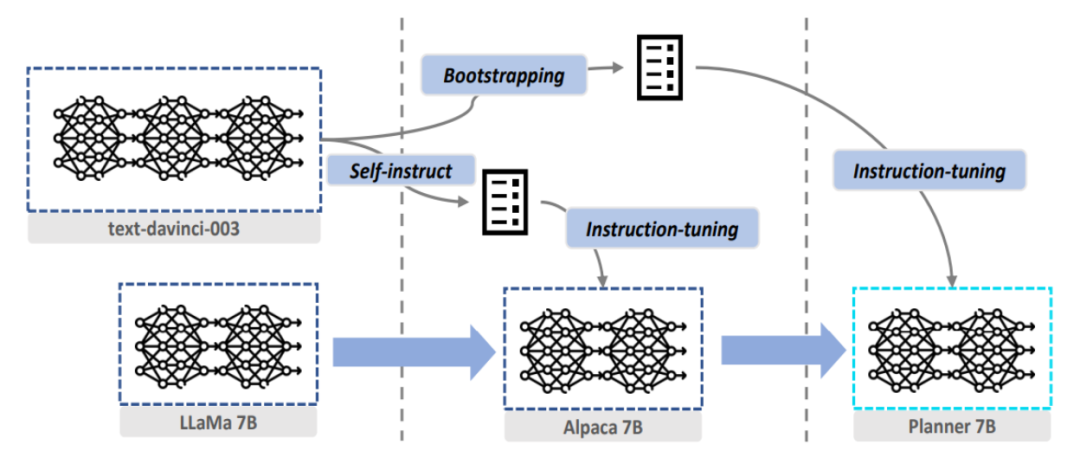
Furthermore, due to the diversity of tool types and the uncertainty of outputs, recent instruction tuning widely used in LLMs makes it difficult to generalize the tool usage ability to smaller models in augmented language models. In ReAct, instruction tuning inevitably causes smaller models to “memorize” the tool outputs in the training set. However, since ReWOO separates explicit tool outputs from the model’s reasoning steps, it allows instruction tuning to help learn the generalized “foreseeable reasoning” ability. This process is referred to as “specialization.” The authors attempted to transfer foreseeable reasoning from the 175 billion parameter GPT-3.5 to the 7 billion parameter LLaMa and observed good results. Due to space limitations, further discussion is not provided here; interested readers can refer to the original text. Additionally, all models, parameters, and data used in the experiments are open-sourced on GitHub.
Conclusion
This work proposes a new paradigm that efficiently addresses the high computational complexity, deployment difficulties, and costs associated with augmented language models. Its theoretical basis partly lies in the fact that through extensive pre-training, LLMs have a certain “fuzzy expectation” for the outputs of the vast majority of tools. For example, using Google to search for “Elon Musk Age” will yield results related to his age, from which his current “age” can be extracted and used in a calculator for computation. Therefore, such foreseeable reasoning can be leveraged to reduce the redundancy generated by iterative step-by-step reasoning. This advantage is particularly prominent in multi-hop tasks.
Additionally, the authors’ analysis of context learning (ICL) in augmented language models and the generalization of tools is also worth pondering. In Future Work, the authors mention a modular solution that combines linear thinking and graph thinking, which may point towards directions for future deployable lightweight augmented models.

Scan the QR code to add the assistant WeChat
About Us
