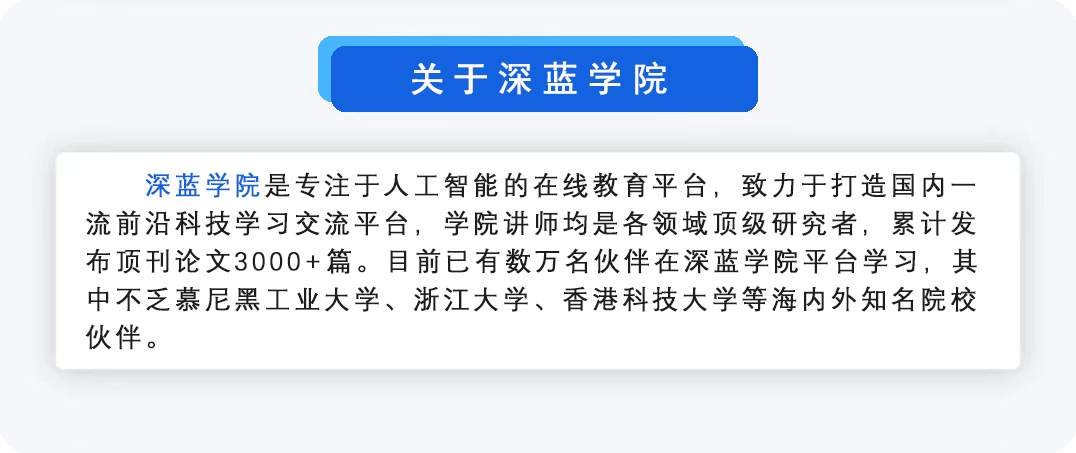
Autonomous vehicles require continuous environmental perception to understand the distribution of obstacles for safe driving. Specifically, 3D object detection is a crucial functional module as it can predict the category, location, and size of surrounding objects simultaneously. Generally, autonomous cars are equipped with multiple sensors, including cameras and LiDAR. The unsatisfactory detection performance of single-modal methods has prompted the use of multi-modal inputs to compensate for single-sensor failures. Despite the existence of numerous multi-modal fusion detection algorithms, there is still a lack of comprehensive analysis of these methods to elucidate how to effectively fuse multi-modal data. Therefore, this article reviews the latest advancements in fusion detection methods. It first introduces the broad context of multi-modal 3D detection and identifies the characteristics of widely used datasets and their evaluation metrics. Secondly, it classifies and analyzes all fusion methods from three aspects: feature representation, alignment, and fusion, rather than the traditional pre-, feature-, and post-fusion classification method, revealing how these fusion methods are inherently realized. Thirdly, it deeply compares their advantages and disadvantages and compares their performance on mainstream datasets. Finally, it further summarizes the current challenges and research trends to fully leverage the potential of multi-modal 3D detection.
-
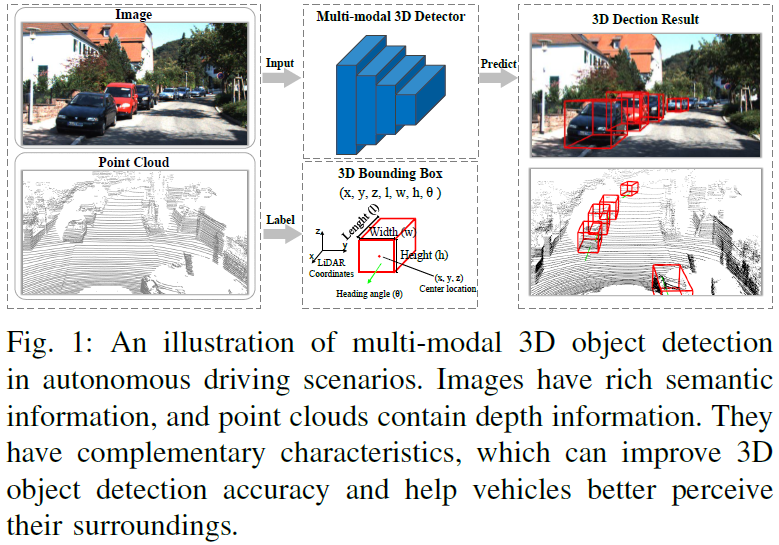
This is the first comprehensive review of multi-modal 3D detection in autonomous driving, rather than treating it as a trivial subset of 3D detection;
-
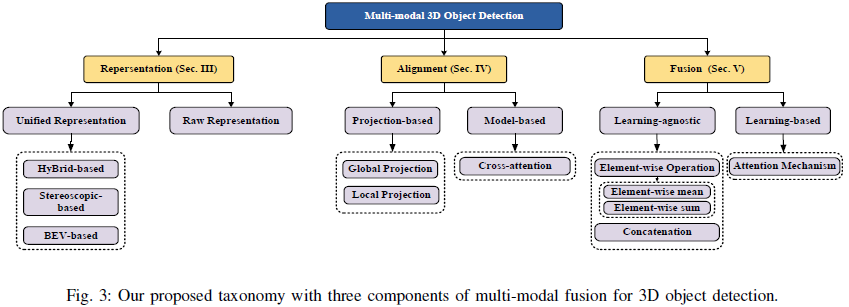
This paper proposes a taxonomy for multi-modal 3D detection that surpasses the traditional pre-, feature-, and post-fusion paradigms, consisting of representation, alignment, and fusion aspects;
-
The latest advancements in multi-modal 3D detection are presented;
-
The paper comprehensively compares existing methods on several public datasets and provides in-depth analysis.
Background
3D Object Detection
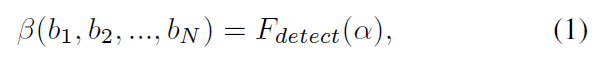

Feature Representation
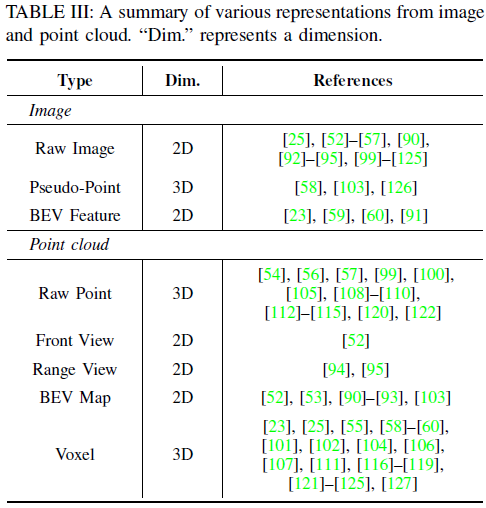
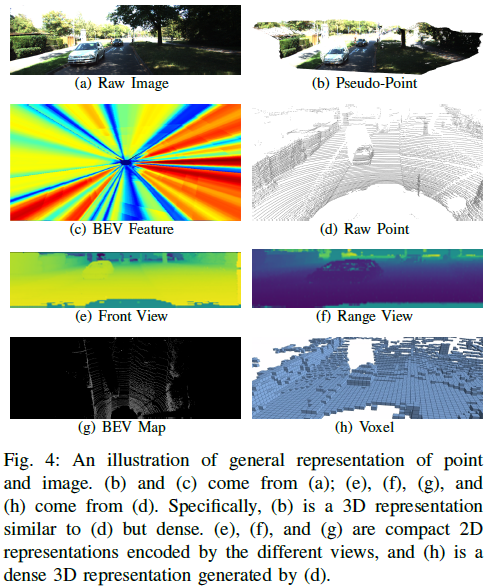
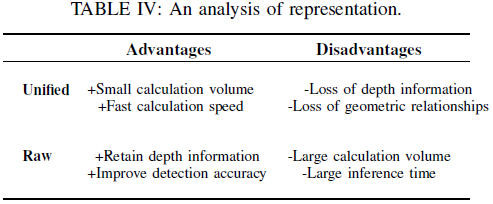
Unified Representation
Raw Representation
Conclusion and Discussion
Feature Alignment
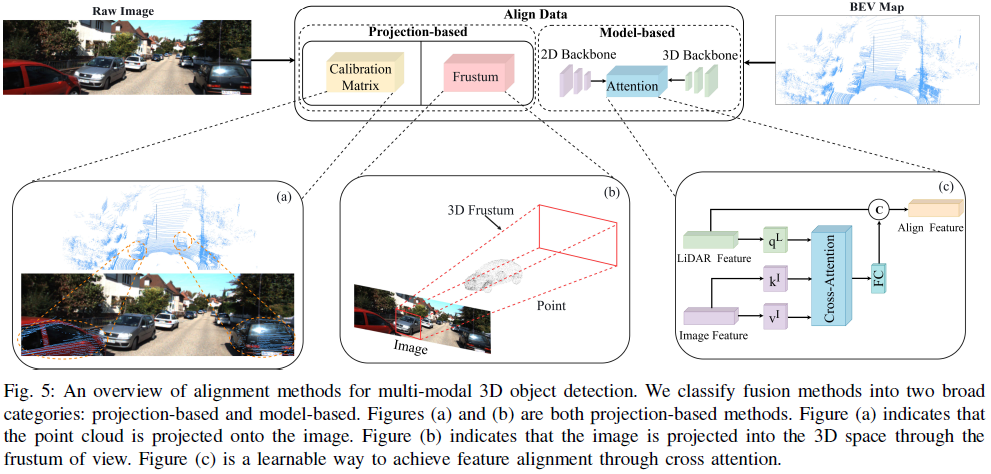
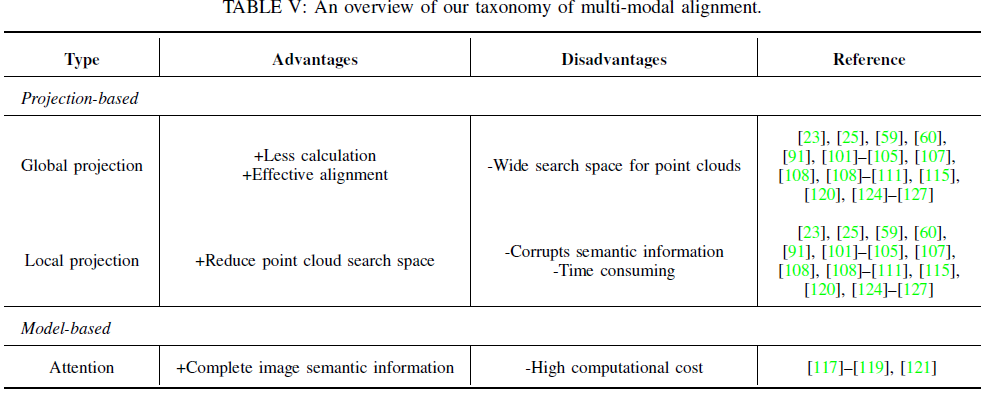
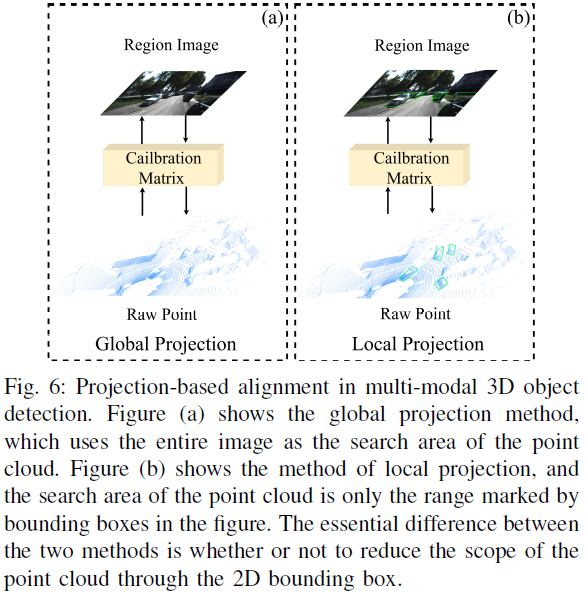
Projection-Based Feature Alignment
Model-Based Feature Alignment
Conclusion and Discussion
Feature Fusion
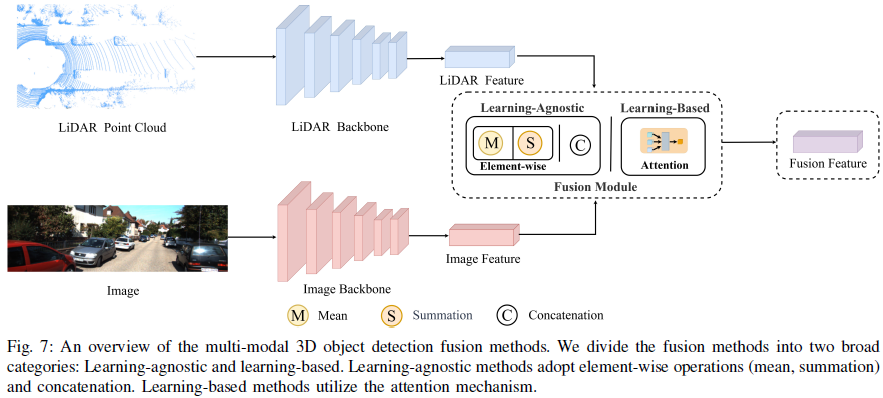
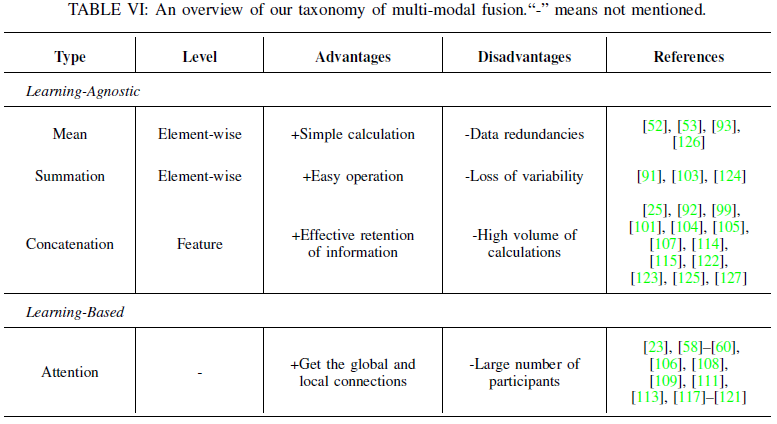
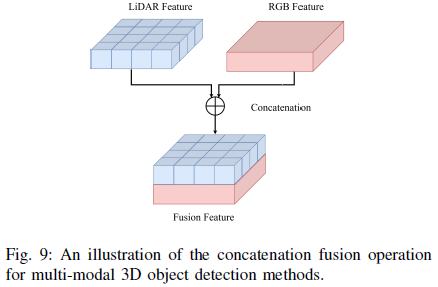
Learning-Agnostic Fusion
Learning-Based Fusion
Discussion and Conclusion
-
Data information experiences varying degrees of information loss during feature transformation;
-
Current fusion methods use image features to complement point cloud features, and image features may encounter issues when using point cloud baselines, such as domain gaps;
-
Learning-agnostic methods need to consider fusion issues based on the importance of information;
-
Learning-based methods have many parameters, requiring consideration of parameter count optimization issues.
Challenges and Trends
-
Data Noise: Effectively fusing multi-modal information has always been a major challenge in multi-modal learning. For various sensors, there are information gaps between data from different modalities, leading to information desynchronization. This issue introduces significant noise in feature fusion, which harms information representation learning. For example, the presence of different dimensional ROIs during the fusion process leads to the combination of background features in images by two-stage detectors. Recent works[59], [60] utilize BEV representations to unify different heterogeneous modalities, providing a new perspective for addressing this issue, which deserves further exploration.
-
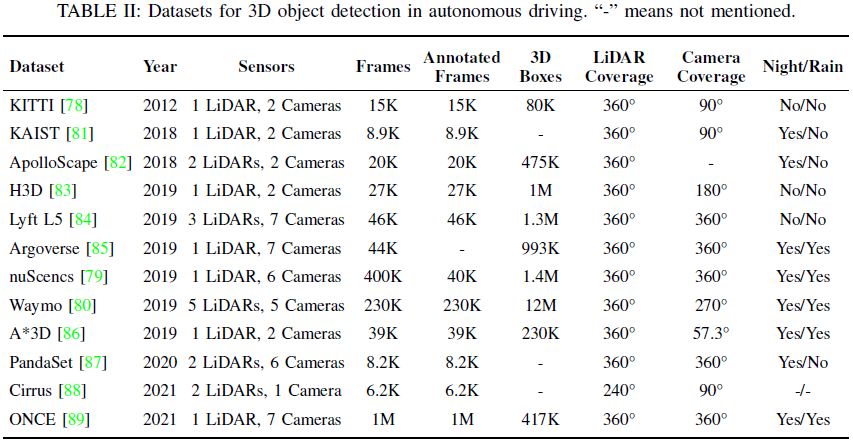
Limited Receptive Field in Open-Source Datasets: Insufficient sensor coverage adversely affects the performance of multi-modal detection. Recently, more and more multi-modal works have focused on nuScenes[79], as it has excellent perception range (both point clouds and cameras are 360 degrees). Excellent perception range aids multi-modal learning, especially in autonomous driving perception tasks. Utilizing sensors with good perception ranges, such as nuScenes[79] and Waymo[80], may improve the coverage of multi-modal detection systems and enhance their performance in complex environments, potentially providing a possible solution to the limited reception field issue in open-source datasets.
-
Compact Representation: Compact representation contains more information but less data ratio. Although existing works attempt to encode sparse 3D representations into 2D representations, significant information loss occurs during the encoding process. The projection of distance images may cause multiple points to fall into the same pixel, leading to information loss. Recently, the Waymo open dataset has provided high-resolution range images, but only a few works have examined them. High-quality representation remains an outstanding challenge. Advanced encoding techniques may be used to achieve more compact 3D representations, such as using deep learning-based autoencoders and generative adversarial networks to represent 3D features.
-
Information Loss: Maximizing the retention of multi-modal information has always been one of the key challenges in multi-modal 3D detection. The fusion of information from multiple modalities may lead to information loss. For example, during the fusion stage, when images are complemented with point cloud features, semantic information from images may be lost. This leads to the fusion process not better utilizing image feature information, resulting in suboptimal model performance. State-of-the-art models in multi-modal learning[109], [117] may prove beneficial for sensor fusion in 3D detection, and new fusion methods and neural network architectures can be explored to maximize the retention of multi-modal information.
-
Unlabeled Data: Unlabeled data is prevalent in autonomous driving scenarios, and unsupervised learning can provide more robust representation learning, which has been studied to some extent in similar tasks, such as 2D detection[145]-[153]. However, in current multi-modal 3D detection, there is no compelling unsupervised representation study. Particularly in the multi-modal research field, better unsupervised learning representation for multi-modal representations is a challenging research topic. In future research, the difficulties of unsupervised learning representation will revolve around simultaneously representing multi-modal data across multi-modal differences.
-
High Computational Complexity: One important challenge of multi-modal 3D object detection is to quickly and real-time detect objects in autonomous driving scenarios. Since multi-modal methods need to process multiple pieces of information, this leads to an increase in parameters and computational load, longer training times, and inference times, making applications unable to meet real-time performance. Recent multi-modal methods have also considered real-time performance, for example, MVP[110] and BEVFusion[59] experiments on the nuScenes dataset have already used FPS as model evaluation metrics. As shown in Table VII, to alleviate the issue of high computational complexity, future work is encouraged to explore model pruning and quantization techniques. These techniques aim to simplify model structures and reduce model parameters for efficient model deployment, which requires further research in autonomous driving scenarios.
-
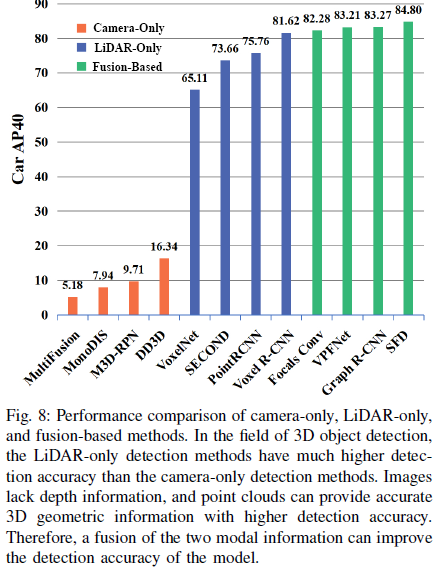
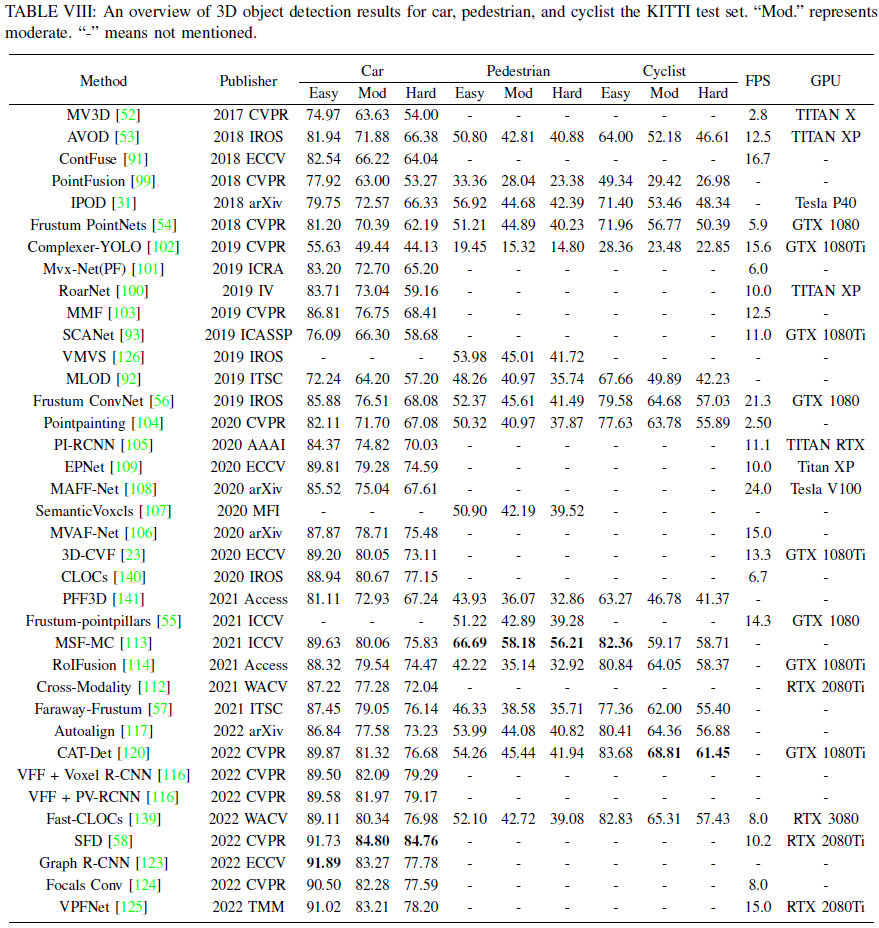
Long-Tail Effect: How to address the long-tail effect caused by performance variation is an important challenge in multi-modal 3D object detection. In the field of autonomous driving, most models need to detect cars, but other objects, such as pedestrians, are also essential detection requirements. As shown in Table VIII, there are many categories in autonomous driving scenarios. Models effective in detecting cars may perform poorly in detecting pedestrians, such as SFD[58]. This leads to uneven category detection. In future work, exploring the use of loss functions and sampling strategies may be potential solutions to the aforementioned issues.
-
Cross-Modal Data Augmentation: Data augmentation is a key part of achieving competitive results in 3D detection, but data augmentation is primarily applied to single-modal methods, with little consideration in multi-modal scenarios. Since point clouds and images are two heterogeneous data types, achieving cross-modal synchronized augmentation is challenging, leading to serious cross-modal misalignment. Applying gt-aug to point clouds and camera data without distortion is difficult. In some methods, only the point cloud part is augmented, while ignoring the image part. Some methods also keep the original image unchanged and perform inverse transformations on the point cloud to achieve correspondence between images and point clouds. Point cloud augmentation[115] proposed a more complex cross-modal data augmentation method, but it uses additional mask annotations on the image branch and is prone to noise. These methods do not well address the synchronization issue of cross-modal data augmentation. A potential solution to this challenge could be to convert heterogeneous data into a unified representation through representation reconstruction and achieve simultaneous data augmentation.
-
Temporal Synchronization: Temporal synchronization is a key issue in multi-modal 3D detection. Due to the differences in sampling rates, working modes, and acquisition speeds of different sensors, there are temporal offsets between the data collected by the sensors, leading to misalignment of multi-modal data, which affects the accuracy and efficiency of multi-modal 3D detection. First, there may be errors in the timestamps of different sensors. Even with hardware for timing synchronization, it is challenging to ensure the consistency of sensor timestamps completely. This method may require expensive equipment. Software synchronization methods can be utilized, such as timestamp interpolation methods, Kalman filter-based time synchronization algorithms, and deep learning-based time synchronization methods. Secondly, sensor data may experience frame loss or delay, which also affects the accuracy of multi-modal 3D object detection. The idea to address this issue is to use caching mechanisms to handle delayed or lost data and use data interpolation or extrapolation methods to fill in the gaps in the data. Temporal synchronization in multi-modal 3D detection is a complex issue that requires various technical means to solve.
Conclusion
References