This article is an outstanding article from the Kexue Forum, Author ID: 大大薇薇
1
Overview
2
Evaluation Conclusion
3
Project Information
4
KNN Model Result Analysis
Basic Information
KNN Model Information
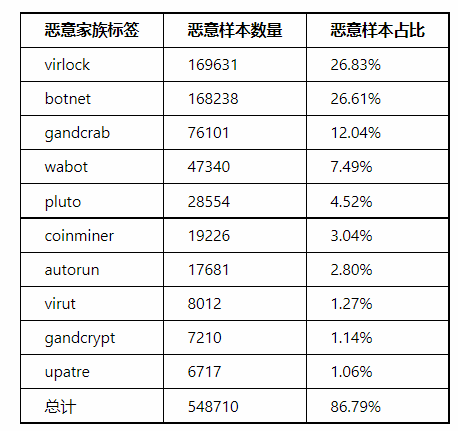
Test File Set Information
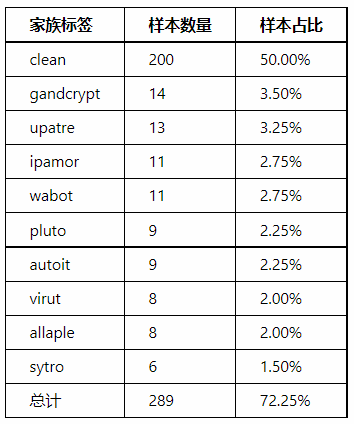
Test Method
-
TP indicates the number of actual labels that are true (malicious) and predicted labels that are true (malicious)
-
TN indicates the number of actual labels that are false (clean) and predicted labels that are false (clean)
-
FP indicates the number of actual labels that are false (clean) and predicted labels that are true (malicious)
-
FN indicates the number of actual labels that are true (malicious) and predicted labels that are false (clean)
-
Accuracy (ACC) indicates the proportion of all correctly predicted labels (can be understood as the detection rate of the KNN model), calculated as: ACC = (TP + TN)/(TP + TN + FP + FN)
-
Precision (PRE) indicates the proportion of all actual true (malicious) numbers in the predicted true (malicious) numbers (can be understood as the credibility of the KNN model’s detection of malicious samples), calculated as: PRE = TP/(TP + FP)
-
Recall (REC) indicates the proportion of all predicted true (malicious) numbers in the actual true (malicious) numbers (can be understood as the KNN model’s detection coverage capability for malicious samples), calculated as: REC = TP/(TP + FN)
Test Code
# -*- coding: utf-8 -*-import sysimport requestsfrom python_mmdt.mmdt.common import mmdt_load # Similarity determination threshold, two thresholds, 0.95 and 0.90dlt = 0.95 def mmdt_scan_online_check(): file_name = sys.argv[1] # Load test data features = mmdt_load(file_name) # 4 indicators TP = 0 TN = 0 FP = 0 FN = 0 count = 0 print('Detection result, file md5, actual label, similar files, predicted label, similarity') for feature in features: count += 1 tmp = feature.strip().split(":") file_mmdt = ':'.join(tmp[:2]) tag = tmp[2] file_sha1 = tmp[3] data = { "md5": file_sha1, "sha1": file_sha1, "file_name": file_sha1, "mmdt": file_mmdt, "data": {} } r = requests.post(url='http://146.56.242.184/mmdt/scan', json=data) r_data = r.json() if r_data.get('status', 0) == 20001: status = r_data.get('status', 0) message = r_data.get('message', '') print('File md5: %s, Status Code: %d, Submission Info: %s' % (file_sha1, status, message)) else: label = r_data.get('data', {}).get('label', 'unknown') sim_hash = r_data.get('data', {}).get('similars', [])[0].get('hash', 'None') sim = r_data.get('data', {}).get('similars', [])[0].get('sim', 0.0) check_result = '' # Statistical hidden condition, the actual label must match the predicted label to be counted as TP, recorded as correct classification if tag == label and sim > dlt: TP += 1 check_result = 'Correct' elif tag == 'clean' and sim > dlt: FP += 1 check_result = 'Incorrect' elif tag == 'clean' and sim <= dlt: TN += 1 check_result = 'Correct' else: FN += 1 check_result = 'Incorrect' print('%s,%s,%s,%s,%s,%.5f' % (check_result, file_sha1, tag, sim_hash, label, sim)) if count >= 500: break print('Total mmdthash tested: %d' % count) print('Total correct detections: %d' % (TP + TN)) print('Total incorrect detections: %d' % (FP + FN)) print('Total TP detected: %d' % TP) print('Total TN detected: %d' % TN) print('Total FP detected: %d' % FP) print('Total FN detected: %d' % FN) print('Detection accuracy (ACC): %.3f' % ((TP + TN)/(TP + TN + FP + FN))) print('Detection precision (PRE): %.3f' % (TP/(TP + FP))) print('Detection recall (REC): %.3f' % (TP/(TP + FN))) def main(): mmdt_scan_online_check() if __name__ == '__main__': main()Test Results are as follows:
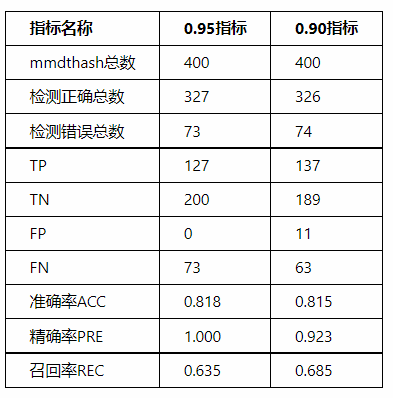
-
The accuracy (ACC) of the KNN model detection is above 80%, and the recall (REC) is above 60%
-
The accuracy (ACC) at the 0.95 threshold improved by 3.68‰ compared to the accuracy (ACC) at the 0.90 threshold, reaching 81.8%
-
The precision (PRE) at the 0.95 threshold improved by 83.42‰ compared to the precision (PRE) at the 0.90 threshold, reaching 100%
-
The recall (REC) at the 0.95 threshold decreased by 72.99‰ compared to the recall (REC) at the 0.90 threshold, reaching 63.5%
-
At the 0.95 threshold, no false positives were found (FP=0)
-
In summary, 0.95 can be set as the initial determination threshold: results no less than 0.95 can be preliminarily judged as credible; results below 0.95 can be preliminarily judged as not credible
Sample Analysis of Classification Errors

-
Errors with a similarity of 1: gandcrypt and gandcrab belong to different names of the same malicious family, detection results with a similarity of 1 are correct;
-
Errors with a similarity greater than 0.99 and less than 1: due to incorrect labeling of the agent sample, through VT query, the agent sample is actually klez, detection results are correct;
-
Errors with a similarity greater than 0.95 and less than 0.99: two files differ significantly, mmdthash issue, confirming detection results are incorrect.

-
Errors with a similarity greater than 0.95: same classification errors as at the 0.95 threshold;
-
Errors with a similarity greater than 0.94 and less than 0.95: detection results confirmed to be all incorrect, such as associating UPX shell files with Delphi compiled files, associating NSIS files with Word files, associating PE files with Excel files;
-
Errors with a similarity below 0.94: the vast majority of detections are incorrect, with many reasons for the errors, including a small number of correct results.
Notes

Kexue ID: 大大薇薇
https://bbs.pediy.com/user-home-467421.htm

# Previous Recommendations
1. A General Method for Integrating LLVM Pass into NDK
2. Artificial Intelligence Competition – House Price Prediction
3. Windows PrintNightmare Vulnerability Reproduction Analysis
4. GKCTF2021 KillerAid
5. Initial Exploration of Kernel, Container, and eBPF Attack and Defense
6. Reproduction Learning of CVE-2019-10999

Share

Like

Watching