
© Author | Wang Kunze
Affiliation | The University of Sydney
Research Direction | NLP

[[w11, w12, w13, w14], [w21, w22, w23, w24], [w31, w32, w33, w34]
[w41, w42, w43, w44], [w51, w52, w53, w54], [w61, w62, w63, w64]]
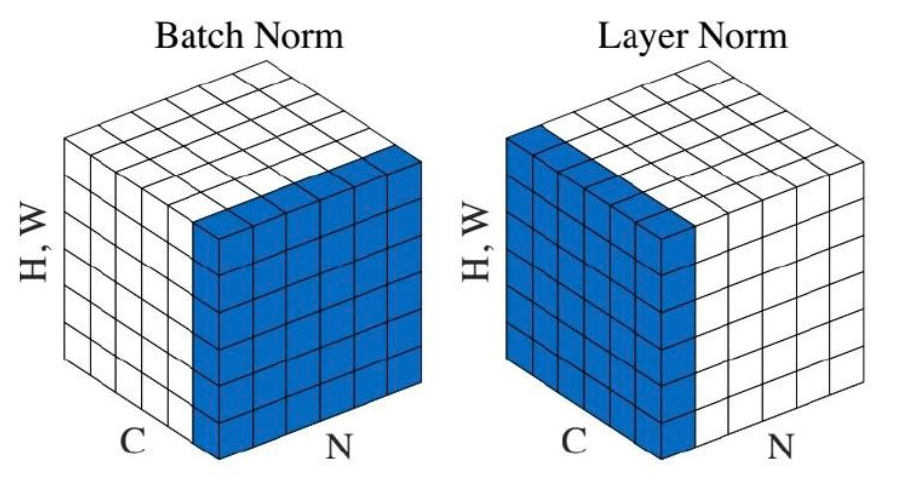
# torch.nn.TransformerEncoderLayer
# https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/transformer.py
# Line 412
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
# huggingface bert_model
# https://github.com/huggingface/transformers/blob/3223d49354e41dfa44649a9829c7b09013ad096e/src/transformers/models/bert/modeling_bert.py#L378
# Line 382
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
import torch
batch_size, seq_size, dim = 2, 3, 4
embedding = torch.randn(batch_size, seq_size, dim)
layer_norm = torch.nn.LayerNorm(dim, elementwise_affine = False)
print("y: ", layer_norm(embedding))
eps: float = 0.00001
mean = torch.mean(embedding[:, :, :], dim=(-1), keepdim=True)
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-1), keepdim=True)
print("mean: ", mean.shape)
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))
y: tensor([[[-0.2500, 1.0848, 0.6808, -1.5156],
[-1.1630, -0.7052, 1.3840, 0.4843],
[-1.3510, 0.4520, -0.4354, 1.3345]],
[[ 0.4372, -0.4610, 1.3527, -1.3290],
[ 0.2282, 1.3853, -0.2037, -1.4097],
[-0.9960, -0.6184, -0.0059, 1.6203]]])
mean: torch.Size([2, 3, 1])
y_custom: tensor([[[-0.2500, 1.0848, 0.6808, -1.5156],
[-1.1630, -0.7052, 1.3840, 0.4843],
[-1.3510, 0.4520, -0.4354, 1.3345]],
[[ 0.4372, -0.4610, 1.3527, -1.3290],
[ 0.2282, 1.3853, -0.2037, -1.4097],
[-0.9960, -0.6184, -0.0059, 1.6203]]])
import torch
batch_size, seq_size, dim = 2, 3, 4
embedding = torch.randn(batch_size, seq_size, dim)
layer_norm = torch.nn.LayerNorm([seq_size,dim], elementwise_affine = False)
print("y: ", layer_norm(embedding))
eps: float = 0.00001
mean = torch.mean(embedding[:, :, :], dim=(-2,-1), keepdim=True)
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-2,-1), keepdim=True)
print("mean: ", mean.shape)
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))
from torch.nn import InstanceNorm2d
instance_norm = InstanceNorm2d(3, affine=False)
x = torch.randn(2, 3, 4)
output = instance_norm(x.reshape(2,3,4,1)) # InstanceNorm2D requires (N,C,H,W) shape as input
print(output.reshape(2,3,4))
layer_norm = torch.nn.LayerNorm(4, elementwise_affine = False)
print(layer_norm(x))

References

Further Reading




#Submission Guidelines
Let Your Writing Be Seen by More People
How can we ensure that more quality content reaches the readership with a shorter path, reducing the cost for readers to find quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly might serve as a bridge to facilitate the collision of diverse backgrounds and academic inspirations, sparking more possibilities.
PaperWeekly encourages university labs or individuals to share various quality content on our platform, which can include interpretations of the latest papers, analyses of academic hotspots, research insights, or competition experience explanations. Our only goal is to let knowledge flow.
📝 Basic Submission Requirements:
• Articles must be original works by individuals and not previously published in public channels. If they have been published or are pending publication on other platforms, please clearly indicate.
• Submissions are recommended to be written in markdown format, and images should be sent as attachments, with clear images and no copyright issues.
• PaperWeekly respects the authors’ right to attribution and will provide competitive remuneration for each original article accepted for publication, based on a tiered system according to article views and quality.
📬 Submission Channels:
• Submission Email:[email protected]
• Please include your immediate contact information (WeChat) with your submission, so we can contact the author as soon as the article is selected.
• You can also directly add the editor’s WeChat (pwbot02) for quick submissions, with a note: Name-Submission

△ Long press to add PaperWeekly editor
🔍
Now, you can also find us on “Zhihu”
Search for “PaperWeekly” on Zhihu’s homepage
Click “Follow” to subscribe to our column
