
This is the sixth article in the large model programming series, and also my notes from the free course on some cloud large model engineer ACA certification[1]. This course is really good, highly recommended! 👍🏻 If you’re interested in the course, please click the link at the bottom to view the original article.
Here are a few images extracted from the course with brief explanations.
Official Terminology
RAG (Retrieval-Augmented Generation) is a natural language processing framework that combines information retrieval and generative models. It enhances generative models by introducing external knowledge bases (such as document libraries, databases, etc.), thereby improving the accuracy and relevance of responses.
The core idea of RAG is that when relying solely on generative models for language generation, the model can only respond based on the knowledge it acquired during training, which may lead to inaccurate or “hallucinated” outputs. By introducing a retrieval mechanism, RAG models can access external information during the generation process, resulting in more accurate, rich, and contextually relevant responses.
Layman’s Terms
A large model can be likened to answering questions through pre-prepared material searches, using RAG based on specific information relevant to the user’s question, prioritizing its data. The built-in information in the large model may be outdated or inaccurate.
The first type of knowledge base can be understood as a company-wide configured knowledge base; in the second scheme, each team or user can also add their customized private knowledge base according to their needs. Clearly, the second system is more flexible and can supplement business knowledge without complex operations. Overall, both systems enhance the assistant’s capabilities through knowledge bases, reducing the occurrence of “hallucinated” responses (i.e., the assistant does not fabricate a seemingly plausible address but answers based on existing knowledge). This is what we are about to introduce: Retrieval-Augmented Generation (RAG). RAG includes three steps: indexing, retrieval, and generation. If the large model assistant is a volunteer, then the process of preparing a “volunteer manual” is the indexing of the knowledge base, retrieving information is like the volunteers checking the materials, and the volunteers thinking deeply and answering user questions based on the retrieved materials is the generation of answers.
Principles of RAG Implementation
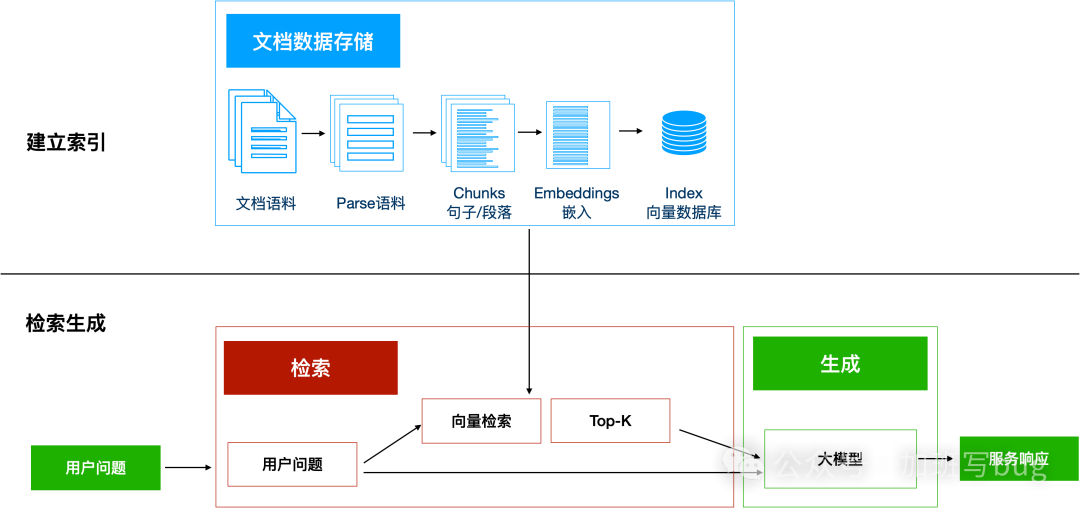
As shown in the figure, RAG mainly consists of two parts:
Indexing
First, we need to clean and extract raw data, parsing different formats such as PDF and Docx into plain text data; then, the text data is segmented into smaller chunks; finally, these chunks are converted into vector data through an embedding model (this process is called embedding), and the original text chunks and embedded vectors are stored in the vector database as key-value pairs for subsequent fast and frequent searches. This is the process of indexing. Refer to BERT Text Segmentation – Chinese – General Domain[2]
Retrieval Generation
The system will receive user input, then calculate the similarity between the user’s question and the document chunks in the vector database, selecting the top K document chunks (K value can be set by the user) as knowledge to answer the current question. The knowledge and the question will be merged into a prompt template and submitted to the large model, which will provide a response. This is the retrieval generation process.
The most essential upgrade: the difference from the previous method we used to search with <span>es</span> is that the search results are not directly given, but rather summarized by the large model before being provided to the user.
Personal Summary
In an ideal scenario, many times it is not just a simple search, for example, if the database only contains basic information about black tea and green tea. If the user searches for which is cheaper, black tea or green tea, then query rewriting, sub-task splitting, and merging by the large model is needed. There are many points to learn.
Some cloud large model engineer ACA certification free course: https://edu.aliyun.com/course/3126500/lesson/342570389
[2]BERT Text Segmentation – Chinese – General Domain: https://www.modelscope.cn/models/iic/nlp_bert_document-segmentation_chinese-base/summary