Author: PicturesqueOriginal: https://zhuanlan.zhihu.com/p/13700531874
>>Join the Qingke AI Technology Exchange Group to discuss the latest AI technologies with young researchers/developers
Technical Report: https//arxiv.org/abs/2412.15115
Github Code: https//github.com/QwenLM/Qwen2.50 Abstract
Qwen2.5 is a comprehensive series of LLMs designed to meet various needs.
Compared to previous versions, Qwen2.5 has significant improvements in both the pre-training (Pretrain) and post-training (SFT, RLHF) stages.
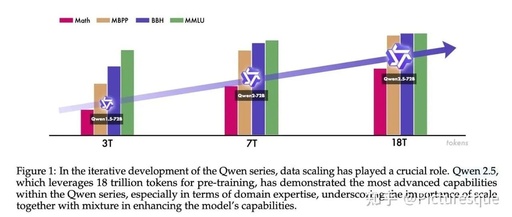
The pre-training data has been expanded from 7T tokens to 18T tokens, providing a solid foundation for common sense, professional knowledge, and reasoning capabilities.
The post-training stage includes SFT and multi-stage RL conducted on over 1M data points—offline DPO and online GRPO. Post-training significantly enhances human preference, improves long text generation, structured data analysis, and instruction-following capabilities.
Open-source models of various scales have been released, including 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B, along with quantized versions. The closed-source models currently include two MoE variants: Qwen2.5-Turbo and Qwen2.5-Plus.
Qwen2.5 demonstrates top-tier performance across a wide range of benchmarks in language understanding, reasoning, mathematics, code, and human preference alignment. Qwen2.5-72B-Instruct outperforms many other open-source and closed-source models. The costs of Qwen2.5-Turbo and Qwen2.5-Plus are also competitive compared to GPT-4o-mini and GPT-4o.
Qwen2.5 plays a crucial role in supporting the training of domain-specific expert models, including Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
1 Introduction
Several key features of Qwen:
-
• Better in Size: Compared to the previous generation Qwen2, new models of 3B, 14B, and 32B have been added. Qwen2.5-Turbo and Qwen2.5-Plus offer a good balance between accuracy, latency, and cost. -
• Better in Data: The pre-training data has increased to 18T tokens, focusing on knowledge, code, and mathematics. Pre-training is conducted in phases to allow transitions between different data mixes. The post-training data exceeds 1M samples, covering SFT, DPO, and GRPO. -
• Better in Use: Compared to the previous generation, the generation length has increased from 2K to 8K. It better supports structured input and output (such as tables and JSON). Easier to use tools. Additionally, Qwen2.5-Turbo supports a context length of 1M.
2 Architecture & Tokenizer
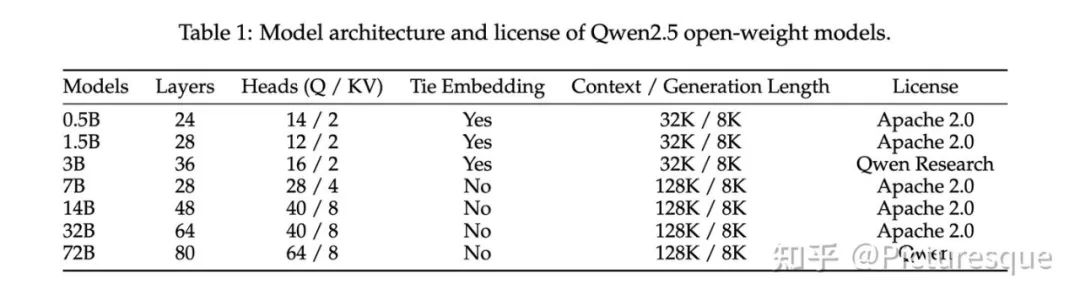
Key components: GQA for efficient KV cache, SwiGLU activation function, RoPE positional encoding, QKV bias in attention mechanisms, and RMSNorm normalization.
GQA: https://arxiv.org/abs/2305.13245
SwiGLU: https://arxiv.org/abs/1612.08083
RoPE: https://arxiv.org/abs/2104.09864
QKV bias: https://spaces.ac.cn/archives/9577
RMSNorm: https://arxiv.org/abs/2305.14858Based on the Dense model architecture, it is expanded to MoE architecture by replacing standard FFN layers with MoE layers. Similar to Qwen1.5-MoE, fine-grained expert segmentation and shared expert routing are implemented. This provides a substantial improvement in model performance on downstream tasks.
Fine-Grained Expert Segmentation: https://arxiv.org/abs/2401.06066
Shared Experts Routing: https://proceedings.mlr.press/v162/rajbhandari22a/rajbhandari22a.pdf
https://arxiv.org/abs/2401.06066The tokenizer is Qwen’s tokenizer encoded at the byte-level BPE, with a vocabulary size of 151,643. The number of control tokens has increased from 3 to 22 compared to previous versions, with 2 new tokens added for tool calls.
3 Pre-training
The pre-training phase consists of several key parts:
-
• Through complex filtering and scoring mechanisms, combined with data mixing strategies, high-quality pretrain data is carefully collected. -
• Extensive research on hyperparameters has been conducted to effectively train models of various scales. -
• A dedicated long-context pretrain has been added to enhance the model’s ability to handle long texts.
3.1 Pre-training Data
Compared to the previous generation, the improvement in Qwen2.5 pre-training data quality is as follows:
-
• Better data filtering: Data quality assessment and filtering are key parts of the pipeline. Qwen2-Instruct is used as a filter to comprehensively and multi-dimensionally assess and score data. Since Qwen2 was trained on a larger multilingual corpus, filtering has significantly improved compared to Qwen2, enhancing the retention of high-quality data and effectively filtering low-quality data across multiple languages. -
• Better math and code data: The training data from Qwen2.5-Math and Qwen2.5-Coder has been integrated. This data integration strategy has proven to be very effective. -
• Better synthetic data: High-quality and synthetic data generation is conducted using both Qwen2-72B-Instruct and Qwen2-Math-72B-Instruct. Strict filtering is performed through proprietary general RM and Qwen2-Math-RM-72B. -
• Better data mixture: Qwen2-Instruct is used to classify and balance content from different domains. Analysis shows that there is an overabundance of data in domains like e-commerce, social media, and entertainment, which often contains repetitive, template-based, and machine-generated content. In contrast, fields like technology and academic research, while containing higher quality information, are underrepresented. Through downsampling and upsampling, a better data mix is achieved.
Through these methods, a larger and higher quality dataset of 18T has been obtained.
3.2 Scaling Law for Hyper-parameters
Hyperparameter scaling law research is based on pre-training data. Based on the previously optimal model size scaling law under given computational resources, optimal hyperparameters across model architectures are identified. Key hyperparameters like batch size and learning rate are determined for different sizes of Dense models and MoE models.
Extensive experiments systematically studied the relationship between model architecture and optimal hyperparameters. The optimal learning rate and how it changes with model size and pre-training data scale were analyzed. Experiments included Dense models ranging from 44M to 14B and MoE models from 44M to 1B, trained on datasets ranging from 0.8B to 600B tokens. The final loss is modeled as a function of model architecture and training data scale using optimal hyperparameters.
Additionally, scaling laws are used to predict and compare the performance of different sizes of MoE models and their Dense counterparts, guiding the hyperparameter configuration of MoE models to achieve performance equivalence with specific Dense model variants (e.g., Qwen2.5-72B and Qwen2.5-14B) by adjusting activated parameters and total parameters.
3.3 Long-context Pre-training
Two-stage training method:
In the initial stage, a context length of 4096 is used. Subsequently, the context length is expanded to 32768 in the final phase of pre-training (except for Qwen2.5-Turbo). At the same time, the fundamental frequency of RoPE is increased from 10,000 to 1,000,000 using ABF technology.
ABF: https://arxiv.org/abs/2309.16039For Qwen2.5-Turbo, a progressive context length expansion strategy is implemented in 4 stages: 32,768, 65,536, 131,072, and 262,144. The RoPE fundamental frequency is set to 1,000,000. In each stage, training data is carefully adjusted to cover 40% of the sequences that meet the current maximum length, with 60% being shorter sequences.
YARN and Dual Chunk Attention (DCA) are employed to enhance the model’s ability to handle long sequences during inference. Through these innovations, a fourfold increase in sequence length capacity is achieved, allowing Qwen2.5-Turbo to handle 1M tokens, while other models can manage 131,072 tokens.
YARN: https://arxiv.org/abs/2309.00071
DCA: https://arxiv.org/abs/2402.174634 Post-training
Compared to Qwen2, Qwen2.5 has two improvements in post-training design:
(1) Expanded Supervised Fine-tuning Data Coverage
Utilized millions of high-quality SFT data, with data expansion specifically targeting areas where previous models were lacking, such as long sequence generation, mathematical problems, code, instruction following, structured data understanding, logical reasoning, cross-language transfer, and robust system instructions.
(2) Two-stage Reinforcement Learning
The RL process of Qwen2.5 is divided into two stages: Offline RL and Online RL.
-
• Offline RL: This stage focuses on developing capabilities that are difficult to evaluate by RM, such as reasoning, facts, and instruction following. Carefully constructed and verified training data ensure that the Offline RL signal is both learnable and reliable. -
• Online RL: This stage utilizes RM’s ability to detect subtle differences in output quality, including truthfulness, helpfulness, conciseness, relevance, harmlessness, and debiasing.
4.1 Supervised Fine-tuning
(1) Long-sequence Generation
Qwen2.5 outputs context lengths of up to 8,192 tokens. A long-response dataset has been developed. Back-translation techniques are used to generate long text query data from pre-training corpora, applying output length constraints and using Qwen2 to filter low-quality data.
(2) Mathematics
The CoT data of Qwen2.5-Math has been introduced, sourced from public datasets, K-12 problem sets, and synthetic problem data.
To ensure high-quality reasoning, a combination of RM and annotated answers guided rejection sampling is employed to produce step-by-step reasoning processes.
(3) Coding
Instruction fine-tuning data from Qwen2.5-Coder has been added. Multiple language-specific agents are integrated into a collaborative framework to generate diverse and high-quality instruction pairs across nearly 40 programming languages.
The instruction dataset is expanded by synthesizing new data from code-related Q&A websites and collecting code snippets from GitHub.
A comprehensive multilingual sandbox is used for automated unit testing, static code analysis, and code snippet validation to ensure code quality and correctness.
(4) Instruction-following
A strict code-based validation framework has been implemented. LLMs are used to generate instructions and validate code, along with comprehensive unit tests for cross-validation. Data selection is performed through rejection sampling based on execution feedback.
(5) Structured Data Understanding
A comprehensive structured understanding dataset has been developed. This includes traditional tasks such as table QA, fact verification, error correction, and structured understanding, as well as designing complex tasks for structured and semi-structured understanding.
By integrating reasoning chains into responses, the model’s ability to infer information from structured data is enhanced.
(6) Logical Reasoning
A new set of 70,000 queries spanning different domains has been introduced. This includes multiple-choice questions, true/false questions, and open-ended questions, training the model on a variety of reasoning methods. Systematic fine-tuning iteratively filters out data with incorrect answers or flawed reasoning processes.
(7) Cross-Lingual Transfer
Using translation models, instructions are transformed from high-resource languages to various low-resource languages, generating corresponding response candidates.
To ensure the accuracy and consistency of these responses, semantic alignment between each multilingual response and the original response is evaluated.
(8) Robust System Instruction
Hundreds of general system prompts have been constructed to enhance diversity. Evaluations using different system prompts show that the model maintains good performance, reducing variance and enhancing robustness.
(9) Response Filtering
Multiple automated labeling methods, including dedicated critic models and multi-agent collaborative scoring systems, are used to assess the quality of responses. Responses deemed flawless by all evaluation systems are retained.
Ultimately, a SFT dataset containing over 1M data points has been constructed. Fine-tuning was conducted for 2 epochs at a sequence length of 32,768. The learning rate gradually decreased to . To address overfitting issues, a weight decay of 0.1 was applied, and gradient clipping was set to a maximum of 1.0.
4.2 Offline Reinforcement Learning
Compared to Online RL, Offline RL can pre-prepare training data and is suitable for tasks with standard answers but are difficult to evaluate by RM.
This primarily focuses on objective query domains, such as mathematics, code, instruction following, and logical reasoning, where obtaining accurate evaluations can be complex.
In SFT, strategies like execution feedback and answer matching are extensively applied to ensure the quality of responses. This pipeline is reused in the Offline RL stage, using the SFT model to resample a new set of queries.
In DPO, responses that pass quality checks are considered positive examples, while those that do not are negatives. Both manual and automated inspection processes further improve the reliability and accuracy of training data, ensuring that data is not only learnable but also aligns with human expectations.
Ultimately, a training dataset of approximately 150,000 pairs has been constructed. An epoch was trained using the Online Merging Optimizer with a learning rate of .
Online Merging Optimizer: https://arxiv.org/abs/2405.179314.3 Online Reinforcement Learning
To develop a robust RM for Online RL, a carefully crafted labeling standard has been adopted. This standard ensures that the responses generated by the model are not only high-quality but also ethical and user-centered.
The specific standards for data labeling are as follows:
-
• Truthfulness: Responses must be based on factual accuracy, providing a truthful reflection of the context and instructions given. The model should avoid generating incorrect information or unsupported data. -
• Helpfulness: The model’s output should be genuinely useful, effectively addressing the user’s queries while providing positive, engaging, educational, and relevant content. It should precisely follow the given instructions, providing value to the user. -
• Conciseness: Responses should be concise, avoiding unnecessary verbosity. The goal is to convey information clearly and effectively without overwhelming the user with excessive details. -
• Relevance: All parts of the response should be directly related to the user’s query, dialogue history, and the assistant’s context. The model should adjust its output to ensure it fully aligns with the user’s needs and expectations. -
• Harmlessness: The model must prioritize user safety, avoiding any content that could lead to illegal, unethical, or harmful behavior. It should always promote ethical behavior and responsible communication. -
• Debiasing: The model should produce unbiased responses, including but not limited to gender, race, nationality, and politics. It should treat all topics equally and fairly, adhering to widely accepted moral and ethical standards.
The queries used to train RM come from two different datasets: open-source data and proprietary data with higher complexity.
Responses are generated from checkpoints of the Qwen model, which come from various training stages including SFT, DPO, RL, etc.
To introduce diversity, sampling is done with different temperatures.
Preference pairs are constructed through manual and automated labeling processes, and DPO training data is also included in the RM data.
The Online RL framework employs GRPO.
The query set used to train RM and the query set used for RL training are the same.
The training order of queries is determined by the variance of their response RM scores. Queries with higher response variance are prioritized for training. Eight responses are sampled for each query.
All models are trained with a global batch size of 2048 and 2048 samples (one query-response pair constitutes one sample) per episode.
4.4 Long Context Fine-tuning
To further extend the context length of Qwen2.5-Turbo, longer SFT data has been introduced during post-training to ensure the model aligns with human preferences on long queries.
Two-stage SFT:
-
• The first stage involves short instruction fine-tuning, with each instruction up to 32,768 tokens. -
• The second stage combines short instructions (up to 32,768 tokens) and long instructions (up to 262,144 tokens).
In the RL stage, training strategies similar to other Qwen2.5 models are used, focusing only on short instructions. This design has two main reasons. First, RL training for long contexts is costly; second, there is currently a lack of suitable reward signals for long context tasks. Additionally, performing RL only on short instructions can still significantly enhance the model’s alignment with human preferences on long context tasks.
5 Evaluation
A comprehensive evaluation component, including common public benchmarks and skill-oriented internal datasets. Evaluations are primarily automated, with minimal human interaction.
To prevent data leakage, n-gram matching is used to exclude potential contamination data when constructing pre-training and post-training datasets. For a training dataset, if there exists a test dataset such that the longest common subsequence (LCS) meets both and , then that data is deleted.
Model performance is shown in partial tables, with details available in the original text.
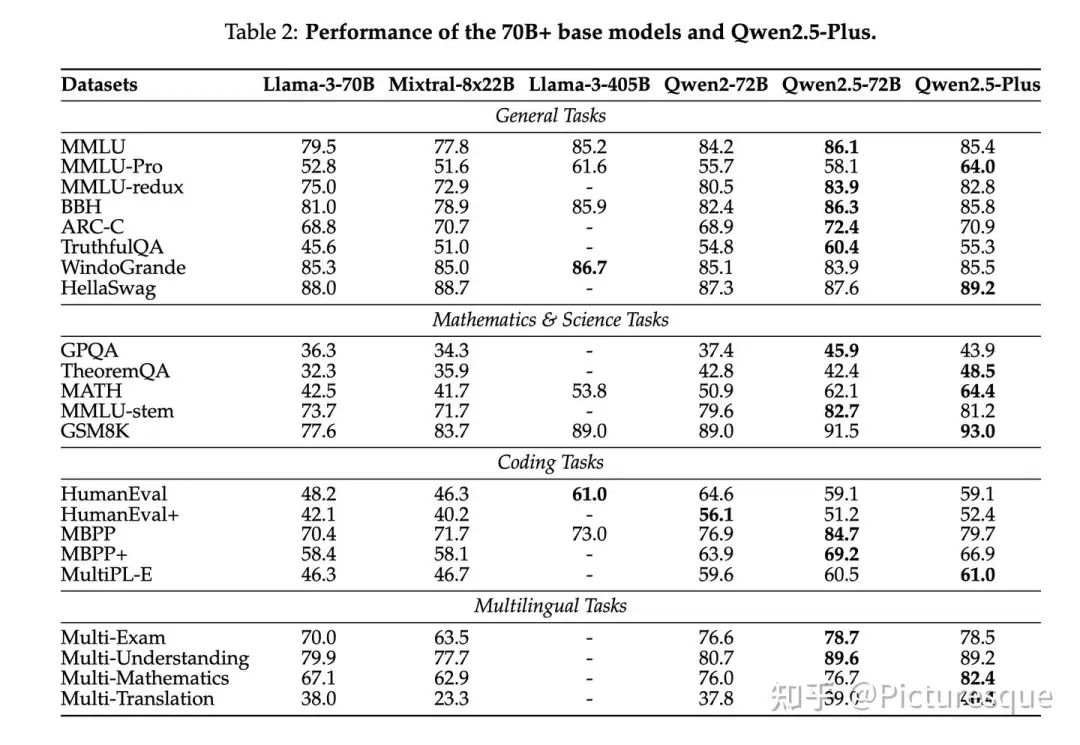
5.1 Base Models
5.2 Instruction-tuned Model
5.2.1 Open Benchmark Evaluation
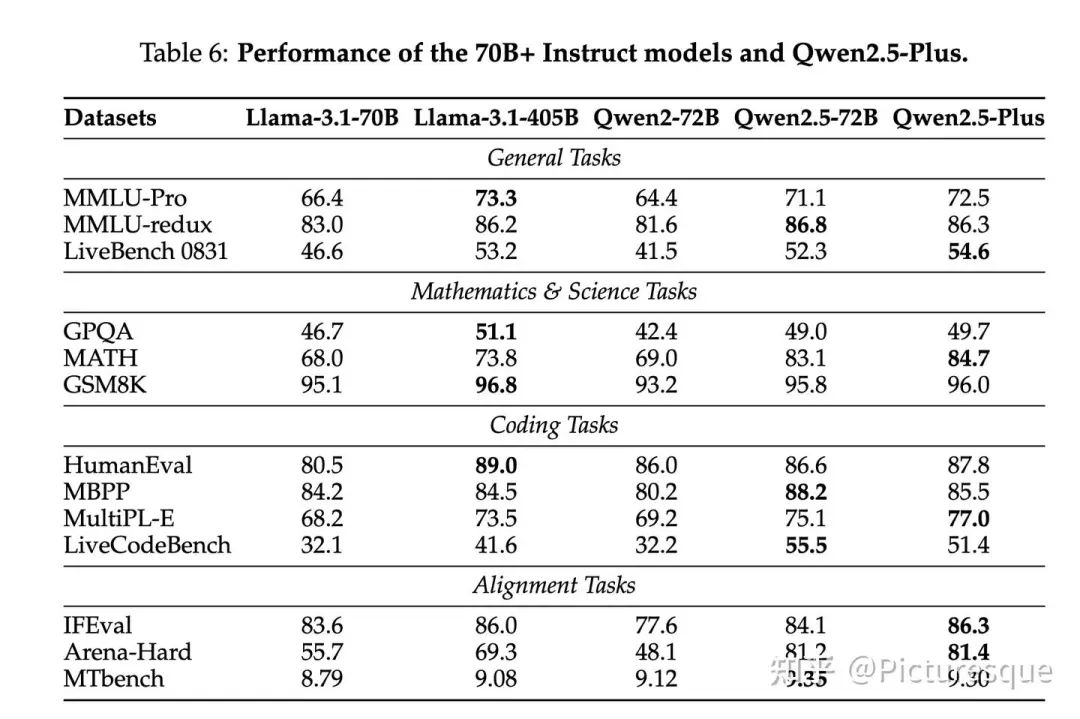
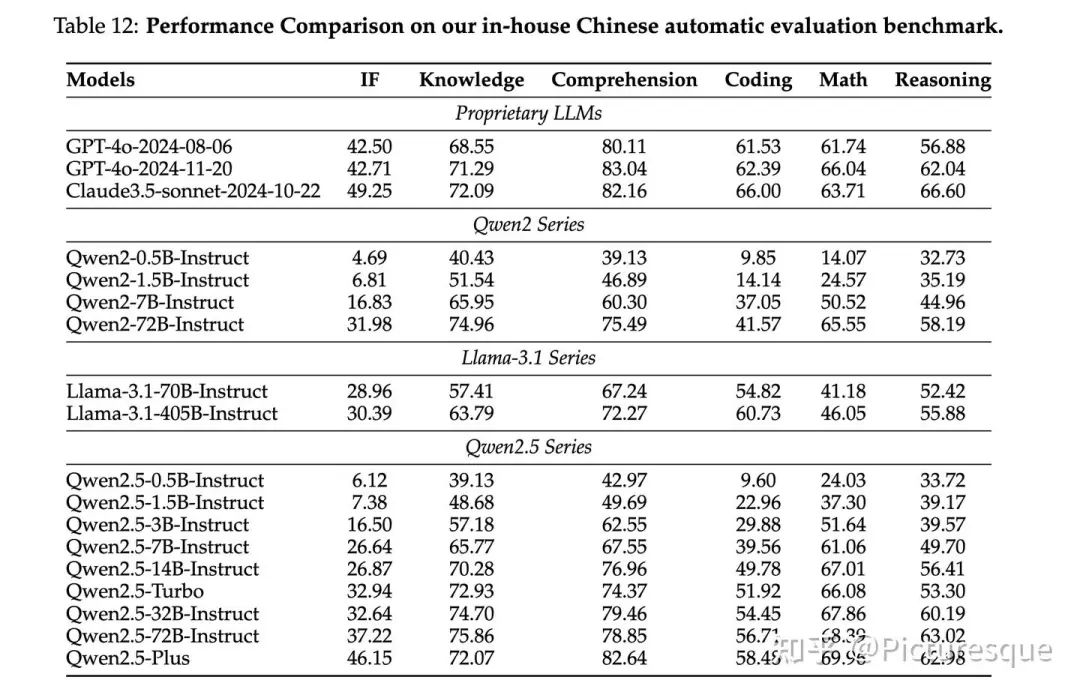
5.2.2 In-house Automatic Evaluation
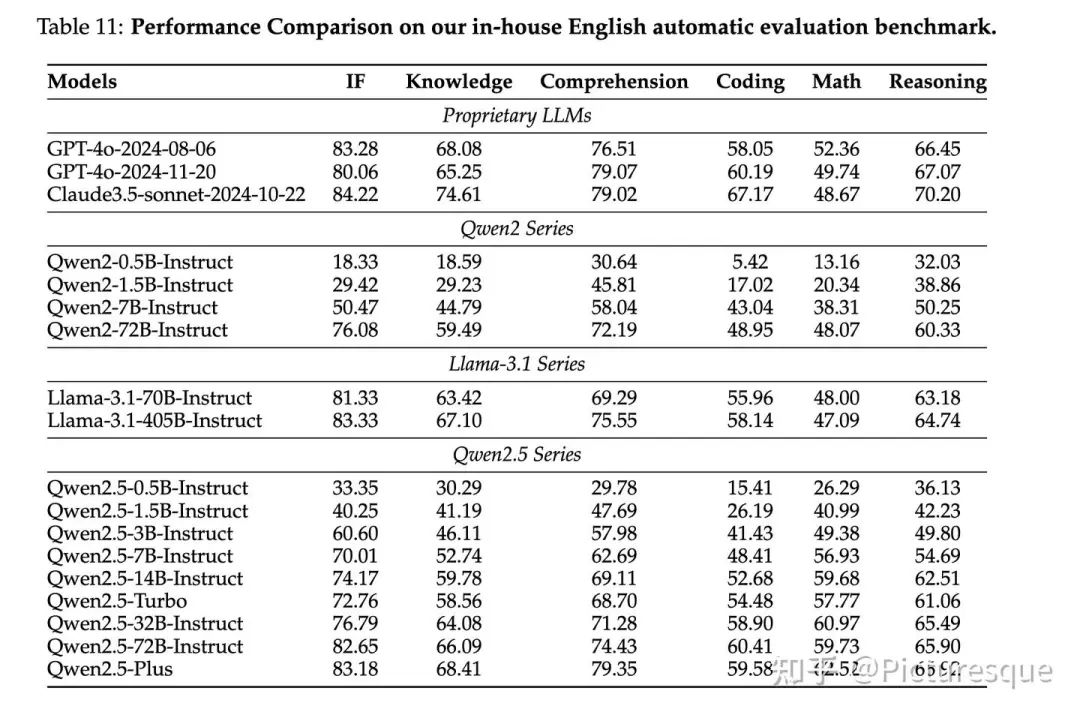
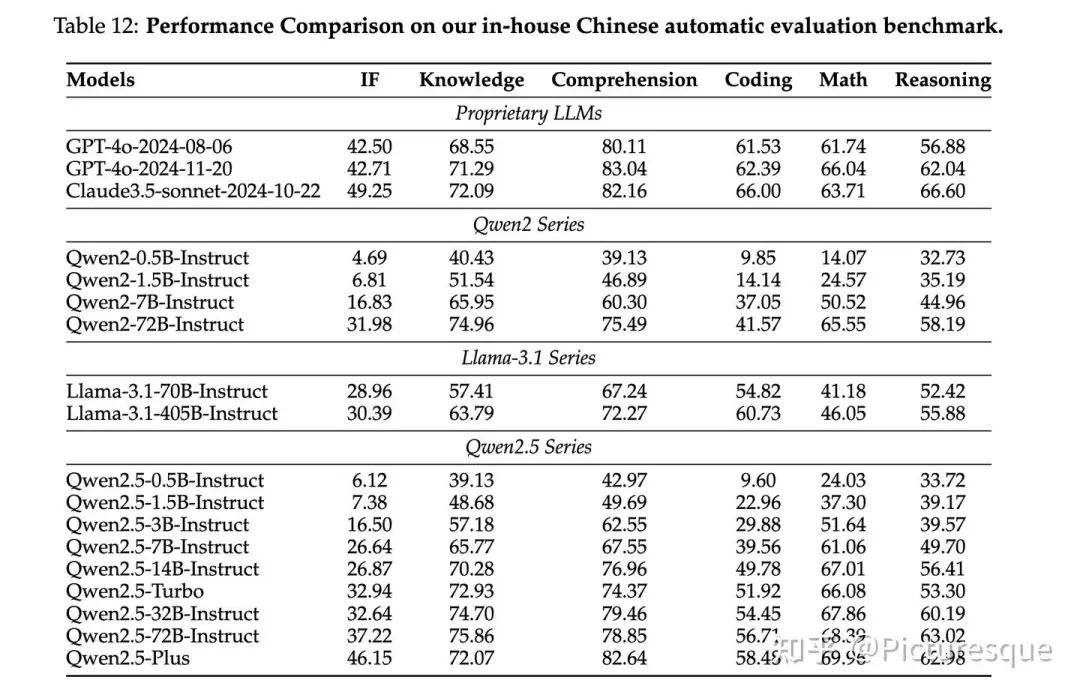
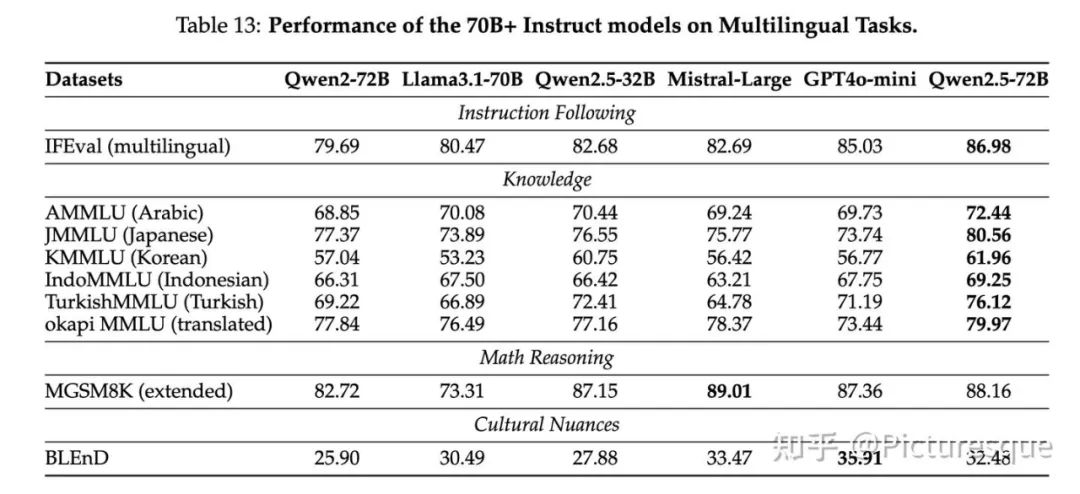
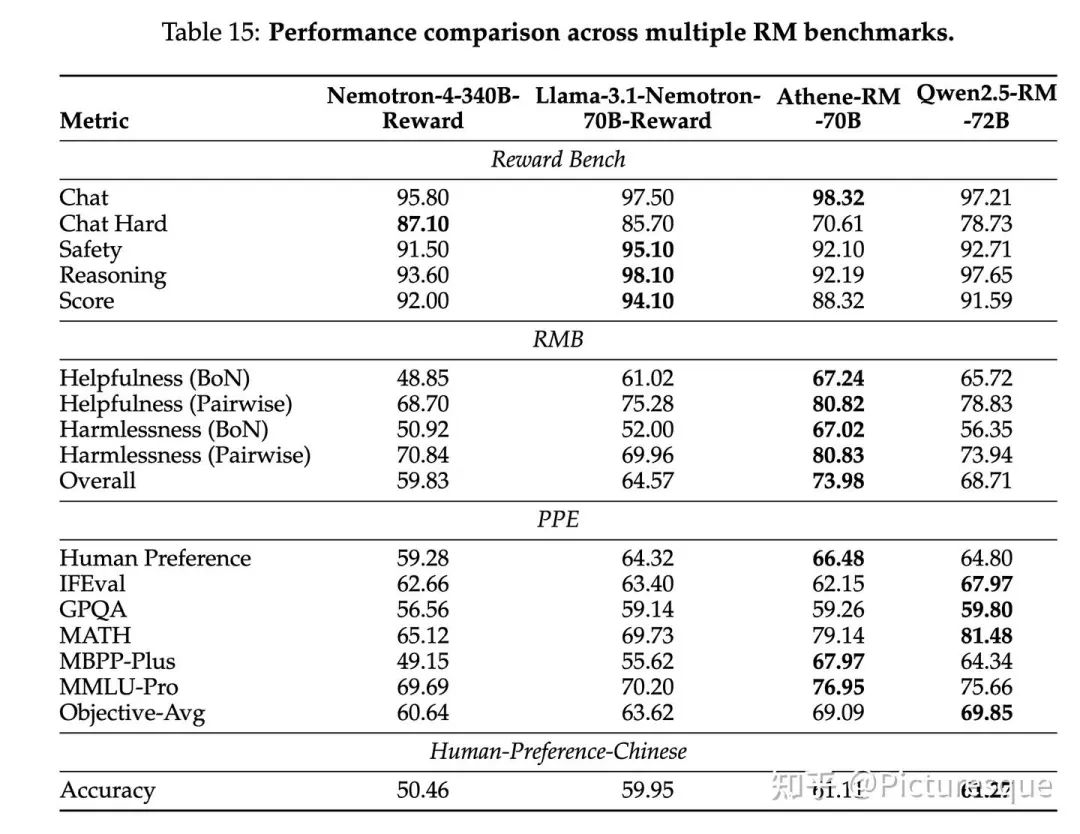
5.2.3 Reward Model
5.2.4 Long Context Capabilities
If you’ve read this far, please give a follow before you go🧐~