Click the above“Beginner Learning Vision” and select toStar or “Pin”
Important information delivered first time
1. In most classical models, the use of multiple sizes, such as the UNet structure and FCN structure, leads to the redundancy of information due to continuous feature extraction from the same low-level information from the beginning.
2. Past models may show insufficient discriminative ability when applied to pixel-level segmentation challenges (e.g., in the medical field).
2. Views on Current Methods for Enhancing Learning Feature Representation, Such as Multi-scale Context Fusion, Using Dilation Convolutions, Pooling, etc.
1. Although previous methods can obtain information about the target at different sizes, the contextual relationships of all images are homogeneous and non-adaptive, ignoring the differences between local features and contextual dependencies across different categories.
2. These multi-scale contextual dependencies are mostly artificially set, lacking flexibility in the model itself. This prevents the full utilization of some long-range relationships in images, which are critical for medical image segmentation.
3. Views on the Attention Mechanism
1. The application of the attention mechanism can effectively highlight the features of the segmented area while suppressing other noisy parts.
2. The author also employs a comprehensive attention mechanism in this paper: a. Using attention mechanisms for semantic information of different sizes; b. Each attention model consists of a position attention model and a channel attention model, allowing the model to learn broader and richer contextual dependency information, as well as enhancing the contextual dependencies between different channels.
1. Overall Description of the Model
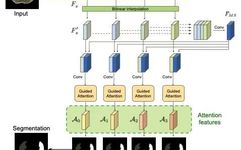
In conventional CNNs, global features are usually obtained based on local receptive fields. Therefore, long-range contextual dependencies have not been adequately expressed. The author introduces the attention mechanism to address this issue. First, a multi-size strategy is used to obtain global features, which are then introduced into the attention module. The attention module consists of a spatial attention module and a channel attention module. On one hand, the attention module helps fuse local features with global features; on the other hand, it filters out unrelated noise information. The overall structure of the model is shown in the figure below:
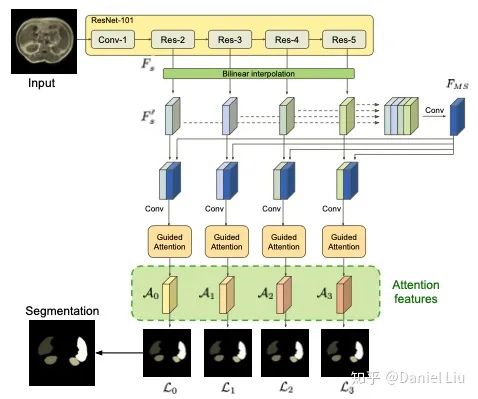
2. Multi-scale Attention Mechanism
The entire model is based on improvements to ResNet-101, with feature maps F0, F1, F2, F3 generated from Res-2, Res-3, Res-4, and Res-5; these are upsampled to the same size using linear interpolation, resulting in F’. The generated F’0, F’1, F’2, F’3 are concatenated, followed by convolution operations to generate the multi-scale fused feature map FMS:
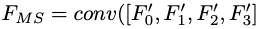
Next, the generated FMS is concatenated with F’0, F’1, F’2, F’3 respectively, followed by convolution, and finally fed into the attention model to obtain the attention feature maps A0, A1, A2, A3 at different sizes:
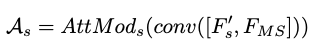
3. Spatial and Channel Attention Feature Maps
The spatial and channel attention self-attention modules in this article are mainly derived from another paper: Dual Attention Network for Scene Segmentation.
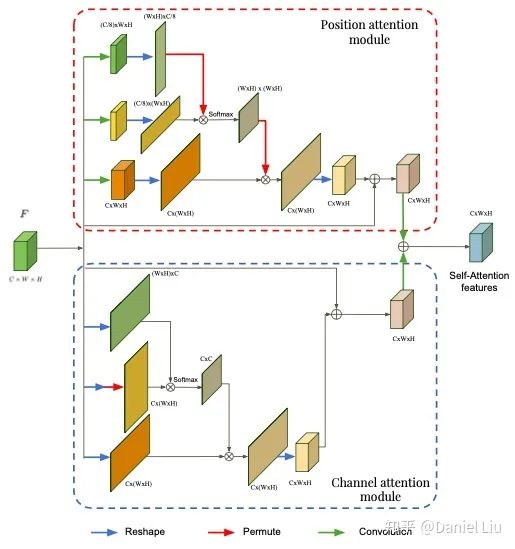
Position Attention Module Part: Used to capture long-range dependencies and solve the local receptive field problem.
In the first three branches, the first two branches F0 and F1 calculate the correlation matrix between positions.
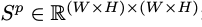
The correlation matrix between positions is then used to guide the third branch.
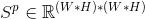
Calculating the spatial attention map, and performing a weighted sum with the input:
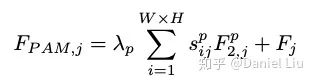
Channel Attention Module (CAM): Captures the dependencies present between channels, enhancing specific semantic feature representations.
Similar to the spatial attention module, in the three branches, the first two branches first calculate the correlation matrix of different positions in the channel, then multiply with the third branch to obtain the channel attention map, which is finally weighted with the input:
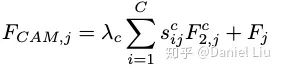
Finally, the spatial attention map and channel attention map are combined through element-wise addition to obtain the spatial-channel attention feature map.
4. Attention Loss
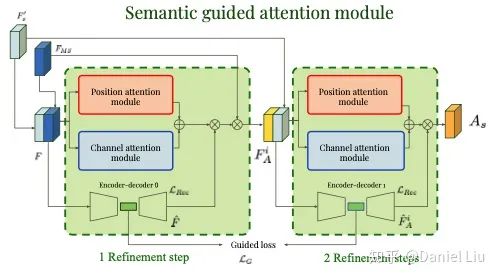
F is fed into the attention model to generate attention feature maps, while also entering a UNet structure, producing the first attention loss:
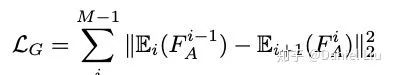
The second attention loss is generated from the outputs of the two UNet structures:
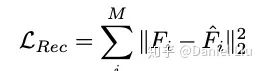
The segmentation loss is:
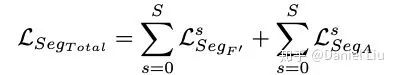
The final total loss is:
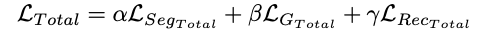
Good news!
Beginner Learning Vision Knowledge Community
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Beginner Learning Vision" WeChat account backend to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Projects" in the "Beginner Learning Vision" WeChat account backend to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the "Beginner Learning Vision" WeChat account backend to download 20 practical projects based on OpenCV, achieving an advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the WeChat public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (will gradually be subdivided). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~