Follow our official account to discover the beauty of CV technology

-
Paper link: https://arxiv.org/abs/1902.11074
-
Project link: https://github.com/upup123/AAAI-2019-AFS
01
-
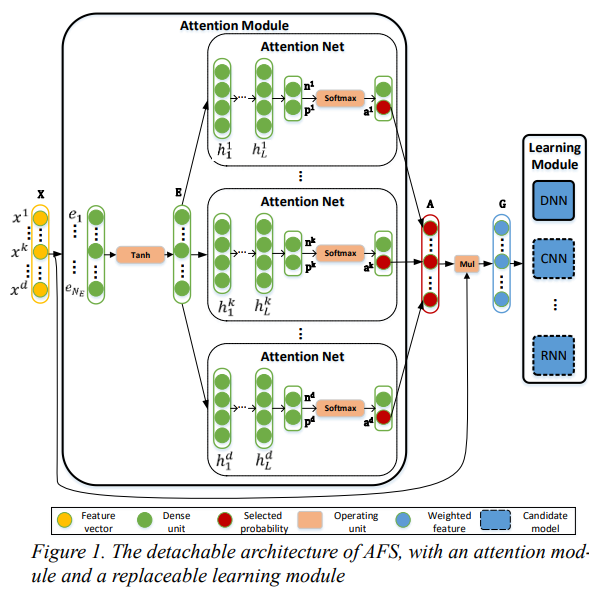
A new attention-based supervised feature selection architecture is proposed: this architecture consists of an attention-based feature weight generation module and a learning module, while the highly coupled design allows for separate training or initialization of different modules.
-
An attention-based feature weight generation mechanism is proposed, transforming the feature weight generation problem into a feature selection pattern problem solvable by the available attention mechanism.
-
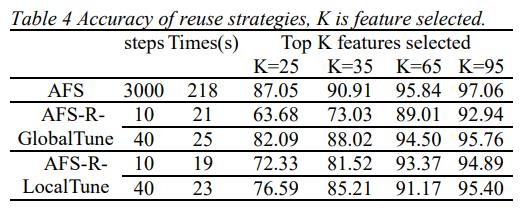
A model reuse mechanism for computational optimization is proposed, allowing for the direct reuse of existing models, effectively reducing the computational complexity of generating feature weights.
-
A hybrid initialization method for small datasets is proposed, combining existing feature selection methods for weight initialization to address the issue of insufficient data in small datasets for generating feature weights.
02
03
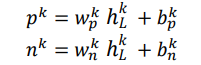
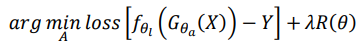
04
-
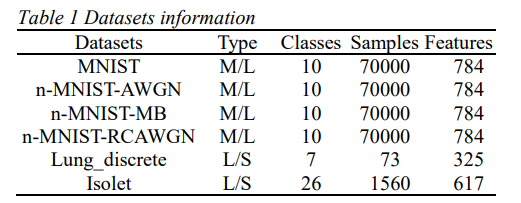
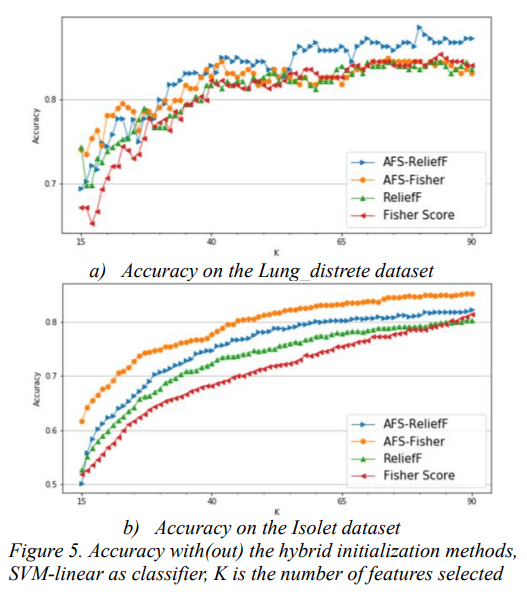
AFS achieved the best accuracy across all four datasets and nearly all feature selection ranges, significantly outperforming other comparative methods.
-
For different types of noise, AFS achieved optimal feature selection stability, demonstrating consistently good performance regardless of the type of noise introduced.
-
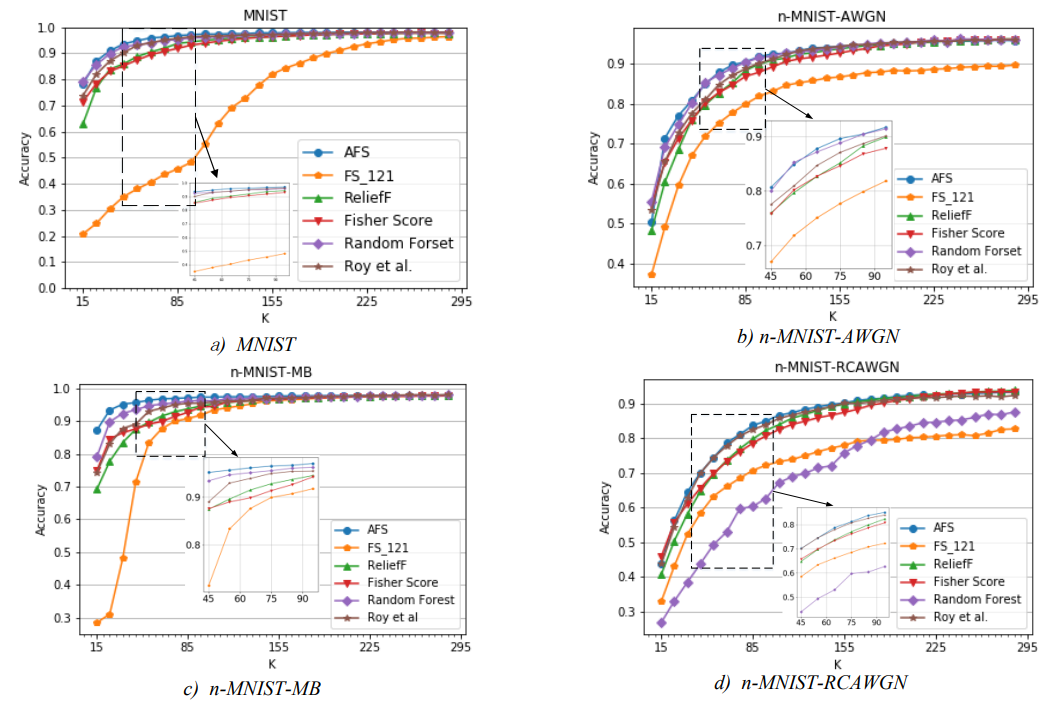
Moreover, as shown in Table 2, when the number of selected features is between 15 and 85, AFS significantly outperformed the other five methods, further indicating that AFS has the most accurate feature weight ranking, which is a crucial advantage in many modeling processes.
-
Table 3 presents the computational overhead of different feature selection methods, measured by the execution time of the feature weight generation process, revealing that the AFS algorithm has moderate computational complexity while providing a substantial performance boost.

05

END
Join the “Computer Vision” group chat👇 Note:CV
