
Machine Heart Column
Author: Zhang Junlin
BERT has brought great surprises to people, but in the blink of an eye, about half a year has passed, and during this time, many new works related to BERT have emerged.
In recent months, aside from my main work on recommendation algorithms, I have been quite curious about the following two questions:
Question 1: The original paper on BERT proved that under comprehensive NLP datasets like GLUE, BERT pre-training has a significant promoting effect on almost all types of NLP tasks (except for generative models). However, since the various tasks in GLUE have a certain proportion of small dataset sizes and the fields are relatively limited, in more fields and larger datasets, does pre-training technology really have a significant promoting effect on many application fields as demonstrated in the experiments of the original BERT paper? If so, how significant is this effect? Is the magnitude of this effect related to the field? This is the first question I care about.
Question 2: As a new technology, BERT certainly has many immature or improvable aspects, so what problems does BERT currently face? What directions are worth improving in the future? This is the second question I care about.
Continuously, I have collected about 70-80 works related to BERT published up to the end of May 2019. Initially, I planned to write the answers to these two questions in one article, but as I wrote, I realized it was too long, and the two themes could indeed be separated, so I changed it to two articles.
This article answers the first question, focusing on the applications of BERT in various NLP fields. Generally, such applications do not involve improvements to BERT’s own capabilities; they simply apply and leverage the capabilities of the BERT pre-training model, which is relatively straightforward. As for enhancements or improvements to BERT’s capabilities, the technicality is stronger. I have summarized about 10 future improvement directions for BERT, which will be placed in the second article, and I will revise and publish the second article later, summarizing the possible future development directions of BERT.
These two articles require a certain level of knowledge structure from the readers. It is recommended to familiarize yourself with how BERT works before reading. You can refer to my previous article introducing BERT:
https://zhuanlan.zhihu.com/p/49271699
This article mainly answers the first question. In addition, from the perspective of application, what characteristics of tasks is BERT particularly good at handling? What types of applications is it not good at handling? Which NLP application fields is BERT good at but are still untouched? What impact will the emergence of BERT have on traditional technologies in various NLP fields? Will a unified technical solution be formed in the future? Including how we should innovate in the era of BERT? These questions will also be addressed, along with my personal views.
Before answering these questions, I will first talk about my abstract views on BERT. The original content was supposed to be in this position of the article, but it was too long, so I have already extracted it and published it separately. If you are interested, you can refer to the following article:
https://zhuanlan.zhihu.com/p/65470719
Flourishing: Progress of BERT Applications in Various NLP Fields
Since the birth of BERT, half a year has passed. If we summarize it, a large number of works using BERT for direct applications in various NLP fields have emerged, with methods that are simple and direct, and the overall effects are quite good. Of course, it also needs to be differentiated by specific fields, as different fields benefit from BERT to varying degrees.
This section introduces these works by field and provides some subjective judgments and analyses from my perspective.
Application Field: Question Answering (QA) and Reading Comprehension
QA, generally referred to as question answering systems in Chinese, is an important application field of NLP and has a long history. I remember that when I was studying, I almost chose this direction as my doctoral proposal… That was close… At that time, the level of technological development was such that various tricks were flying around, and the reliability of technologies was mixed… Of course, I ultimately chose a worse doctoral proposal direction… This should be a specific example of Murphy’s Law? “Choice is greater than effort,” this saying has always been proven and has never been overturned. PhD students should pay attention to this heartfelt advice and choose a good proposal direction. Of course, sometimes the direction you can choose is not entirely up to you; this is something to consider when you have the freedom to choose.
The core issue of QA is: given a user’s natural language query question Q, such as asking “Who is the president most like a 2B pencil in American history?”, the system should find a language segment from a large number of candidate documents that can correctly answer the user’s question, ideally returning the answer A directly to the user, such as the correct answer to the above question: “Donald Trump”.
Clearly, this is a very practical direction. In fact, the future of search engines may be QA + reading comprehension, where machines learn to read and understand each article, and then directly return answers to user questions.
The QA field is currently one of the best-performing areas for BERT applications, possibly even to the extent that we can remove the “one of”. I personally believe the possible reason is that QA questions are relatively pure. The so-called “pure” means that this is a relatively straightforward natural language or semantic problem, where the required answer is found in the text content, and at most some knowledge graphs may be needed. Therefore, as long as NLP technology improves, this field will directly benefit. Of course, it may also be related to the fact that the format of QA questions aligns well with BERT’s strengths. So what kinds of problems is BERT particularly suitable for solving? This will be specifically analyzed later in this article.
Currently, the different technical solutions utilizing BERT in the QA field are quite similar and generally follow the following process:
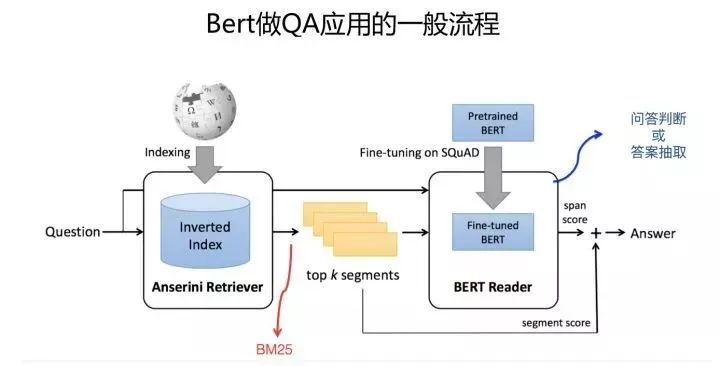
When applying BERT for QA, the process is generally divided into two stages: retrieval + QA judgment. First, longer documents are often segmented into passages or sentences, forming language segments, commonly referred to as Passages, and a fast query mechanism is established using inverted indexing in search.
The first stage is the retrieval stage, which is similar to the conventional search process. Generally, the BM25 model (or BM25+RM3 and other technologies) is used to query possible answer candidate passages or sentences based on the question; the second stage is the QA judgment.
During model training, larger QA datasets like SQuAD are typically used to fine-tune the BERT model, or task data at hand. In the application stage, for the top K candidate passages returned by the first stage, the user’s question and the candidate passage are taken as input for BERT, which classifies whether the current passage contains the correct answer to the question or outputs the starting and ending positions of the answer. This is a relatively common approach to optimizing QA problems using BERT. Different schemes are quite similar, with the only differences likely lying in the datasets used for fine-tuning.
QA and reading comprehension, when applying BERT, are fundamentally similar tasks to a certain extent. If you simplify your understanding, you can actually discard the first stage of the QA process and only retain the second stage, which is the process of applying BERT for reading comprehension tasks.
Of course, the above is a simplified understanding. In terms of the tasks themselves, there are significant commonalities, but there are also subtle differences. Generally, ordinary QA questions rely on shorter contexts, with more localized reference information, and the answers tend to be more surface-level; whereas reading comprehension tasks may require longer contextual references to correctly locate answers, and some high-difficulty reading comprehension questions may require machines to perform a certain degree of reasoning. Overall, it feels like reading comprehension is a more difficult version of the usual QA task. However, from the perspective of BERT applications, the processes of the two are similar, so I have combined these two tasks together. I know that the above statements may be controversial, but this is purely my personal view and should be referenced cautiously.
It was mentioned earlier that the QA field may be the most successful application area for BERT. Many studies have demonstrated that after applying the BERT pre-training model, tasks often see substantial improvements. Below are some specific examples.


In reading comprehension tasks, applying BERT has had a huge impact on the previously complex technologies. A few years ago, I personally felt that although many new technologies were proposed in the reading comprehension field, the methods were overly complex and tended to become increasingly complicated. This is definitely not a normal or good technical development route. I felt the direction might have gone astray, and I have always had a psychological aversion to overly complex technologies. Perhaps it is because my intelligence is limited and I cannot understand the profound mysteries behind complex technologies?
For whatever reason, I have not followed this direction anymore. Of course, it is a good direction. I believe that the emergence of BERT will bring the technology in this field back to its essence. The simplification of models can be achieved more thoroughly. Perhaps it has not been done yet, but I believe it will certainly be done in the future. The technical solutions for reading comprehension should be a concise and unified model. As for the effects of applying BERT in reading comprehension, you can look at the SQuAD competition leaderboard, where the top entries are all BERT models. This also shows the tremendous influence BERT has in the reading comprehension field.
Application Field: Search and Information Retrieval (IR)
For applying BERT, the problem patterns and solution processes in search or IR are very similar to QA tasks. However, due to the different tasks, there are still some distinctions.
The differences between search tasks and QA tasks, based on various information, can be summarized as follows:
First, although both tasks are about matching queries and documents, the factors emphasized during matching differ between the two tasks. The connotations represented by the “relevance” and “semantic similarity” of the two texts are different; “relevance” emphasizes precise matching of literal content, whereas “semantic similarity” encompasses another meaning: even if the literal text does not match, the underlying semantics are similar. QA tasks pay attention to both, possibly leaning more towards semantic similarity, while search tasks focus more on the relevance of text matching.
Secondly, there are differences in document length. QA tasks often seek answers to question Q, and the answers are likely to be just a small segment of language within a passage, which is generally short enough to contain the correct answer. Therefore, the objects of QA processing tend to be short texts. In contrast, search tasks typically involve longer documents. Although determining whether a document is relevant to a query might rely on only a few key passages or sentences within the long document, these key segments may be scattered throughout different parts of the document. When applying BERT, because BERT has input length limitations, with a maximum input of 512 units, how to handle long documents is particularly important for search.
Lastly, for QA tasks, the information contained within the text is often sufficient for making judgments, so no additional feature information is needed. However, for search tasks, especially practical searches in real life, rather than the relatively simple ad hoc retrieval tasks in evaluations, in many cases, relying solely on text may not effectively determine the relevance between queries and documents. Other factors severely impact search quality, such as link analysis, webpage quality, user behavior data, and various other features also play significant roles in the final judgment. BERT seems unable to effectively integrate and reflect this non-textual information. The recommendation field actually faces similar issues as search.
Despite discussing these inter-field differences, it may not be very useful. If you look at the current works utilizing BERT to improve the retrieval field, especially at the passage level, you may find it hard to distinguish whether the work is addressing a search problem or a QA problem. Of course, for long document searches, there are still unique issues that need to be addressed. Why does this indistinguishability between QA and search tasks arise? This is because current works utilizing BERT to improve retrieval are, on one hand, relatively concentrated at the passage level; on the other hand, the tasks are generally ad hoc retrieval, primarily focused on content matching, which is quite different from the main features used in real search engines. These two reasons are likely the main contributors.
Let us summarize how BERT is generally applied in ad hoc retrieval tasks: it is typically divided into two stages. First, classic text matching models like BM25 are used for preliminary ranking of documents to obtain the top K documents, and then complex machine learning models are used to re-rank the top K results. The application of BERT is clearly in the search re-ranking stage, and the application pattern is similar to QA, where the query and document are input into BERT to determine their relevance. If it is passage-level short document retrieval, the process is essentially the same as QA; but if it is long document retrieval, a technical solution for handling long documents needs to be added before passing it to BERT for relevance judgment.
Thus, from two different perspectives on how to apply BERT in the information retrieval field, we can look at short document retrieval and long document retrieval.
For short document retrieval, you can treat it as a QA task, so there is no need for further elaboration. Let’s directly present the results. A few works on passage-level document retrieval can refer to the contents listed in this PPT:

From the various experimental data above, it can be seen that for short document retrieval, using BERT generally leads to significant performance improvements.
For long document retrieval tasks, since BERT cannot accept excessively long inputs on the input side, the challenge of how to shorten long documents arises. The remaining processes are similar to short document retrieval. So how can the long document problem in search be solved? You can refer to the ideas in the following paper.
Paper: Simple Applications of BERT for Ad Hoc Document Retrieval
This paper was the first to apply BERT in the information retrieval field and demonstrated that BERT can effectively enhance search applications. It also conducted experiments on both short and long documents. For short documents, it utilized the TREC 2014 Weibo data. By introducing BERT, improvements of 5% to 18% were observed in various Weibo search tasks compared to the current best retrieval models, and a 20% to 30% improvement over the baseline method (BM25+RM3, which is a strong baseline that surpasses most other improvement methods).
The second dataset was the TREC long document retrieval task. Here, the differences between search and QA tasks become apparent. Since the documents to be searched are relatively long, during the re-ranking stage, it is challenging to input the entire document into BERT. Therefore, this work took a simple approach: it divided the documents into sentences, utilized BERT to assess the relevance of each sentence to the query Q, and then aggregated the scores of the top N sentences (the conclusion is that obtaining the top 3 sentences is sufficient; more than that may decrease performance) to obtain the relevance score between the document and query Q. This way, the long document problem was transformed into a model that aggregates the scores of parts of the document’s sentences.
A Solution Idea for Long Document Search in the Search Field
From the processing process of the above paper on long document searches, we can further delve into this issue. Considering the specificity of search tasks: the relevance between documents and user queries does not manifest in all sentences of the article, but is concentrated in certain sentences of the document.
If this fact holds, then an intuitive general idea for solving the long document problem in search tasks could be as follows: first, through a certain method, assess the relevance between the query and the sentences in the document, generating a judgment function Score=F(Q,S), and based on the score, filter out a smaller subset of sentences Sub_Set(Sentences) that represent the document’s content.
In this way, the long document can be shortened in a targeted manner. From the perspective of relevance to the query, this approach would not lose too much information. The key is how to define the function F(Q,S); different definitions may yield different performance. This function can be referred to as the sentence selection function for documents in the search domain, and various DNN models can be used to implement it. There are many articles that can be written on this topic, and interested students can pay attention.
In summary, in the search field, applying BERT for passage-level short document searches often yields significant improvements, while for long document searches, using BERT can also yield some improvements, but the effects are not as pronounced as for short documents. The likely reason is that the handling of long documents in search has its own characteristics, and more reasonable methods that better reflect the long document characteristics in search need to be explored further to maximize BERT’s effectiveness.
Application Field: Dialogue Systems / Chatbots
Chatbots or dialogue systems have also been very active in recent years, which is related to the emergence of a large number of chatbot products on the market. Personally, I believe this direction aligns with future development trends, but the current technology is not mature enough to support a product that meets people’s expectations for usability, so I am not too optimistic about the recent product forms in this direction, mainly due to the current technological development stage limitations, which cannot support a good user experience. This is a side note.
Chatbots can be categorized into two common types based on task type: casual chatting and task-solving. Casual chatting is straightforward; it is aimless small talk that helps you pass the time, provided you have free time that needs to be filled. I found that young children are likely the target audience for this task type. Two years ago, my daughter could chat with Siri for half an hour, until Siri found her annoying. Of course, the last thing Siri often hears is: “Siri, you are too stupid!”
Task-solving involves helping users with daily affairs and solving practical problems encountered in daily life. For example, 99% of straight men will suffer from holiday phobia due to forgetting holidays and being scolded by their girlfriends or wives; with a chatbot, you no longer have to worry.
You can tell the chatbot: “From now on, remind me of every holiday and help me order flowers for XX.” Thus, throughout the year, on 364 days, you will receive over 500 reminders from the chatbot, and you will no longer have to worry about being scolded, making life better.
Moreover, if you happen to become unemployed in middle age because you are particularly familiar with sending flowers, you might open a chain flower shop, which may go public faster than Luckin Coffee… This is the practical benefit brought by task-solving chatbots, and if it doesn’t work out, it might unexpectedly push you towards the pinnacle of life.
Just kidding; from a technical perspective, chatbots face two main technical challenges.
First, for single-turn dialogues, which is a one-question-one-answer scenario, task-solving chatbots need to parse the user’s intent from the user’s words. For instance, whether the user wants to order food or request a song is generally a classification problem known as user intent classification, which categorizes the user’s intent into various service types.
Additionally, if the user’s intent is confirmed, key elements need to be extracted based on that intent. For example, when booking a flight, information such as departure location, destination, departure time, and return time need to be extracted. Currently, slot filling technology is generally used for this, where each key element corresponds to a slot, and the value extracted from user interaction for this slot corresponds to the filling process.
For instance, in the song request scenario, one slot might be “singer”; if the user says, “Play a song by TFBoys,” after slot filling, the value for the “singer” slot would be “singer = TFBoys,” which is a typical slot filling process.
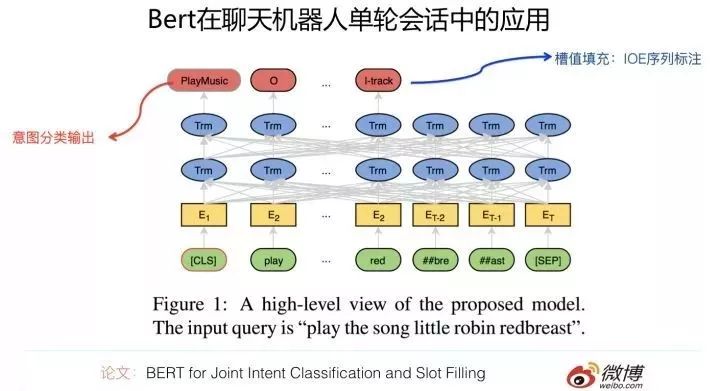
The paper “BERT for Joint Intent Classification and Slot Filling” utilizes BERT to solve the intent classification and slot filling tasks of single-turn conversations. The solution is quite intuitive: input a conversational sentence, and the output of the high-level Transformer position corresponding to the [CLS] input position classifies the intent of the sentence. This is a typical application of BERT for text classification; meanwhile, for each word in the conversational sentence, it is treated as a sequence labeling problem, where each word at the corresponding position in the highest layer of the Transformer is classified to mark which type of slot the word belongs to using IOE labeling. This method accomplishes both tasks simultaneously, which is quite good.
By adopting BERT’s pre-training process, the performance in the intent classification task did not show significant improvement compared to baseline methods, possibly because the baseline methods had already achieved high metrics; in the slot filling aspect, performance varied across two datasets, with one dataset showing a 2% improvement and the other around a 12% improvement. Overall, performance is decent, but not outstanding.
Secondly, for multi-turn dialogues, where the user and chatbot interact through several rounds of Q&A, how to improve the model to enable the chatbot to remember historical user interaction information and correctly use that historical information in subsequent responses is a crucial issue that significantly affects users’ experiences of how intelligent the chatbot appears.
Thus, effectively incorporating more historical information and using it appropriately in context is key to improving the model.
So what would be the effect of applying BERT in multi-turn conversation problems? The paper “Comparison of Transfer-Learning Approaches for Response Selection in Multi-Turn Conversations” provides experimental results.
It utilizes GPT and BERT and other pre-training models to improve how historical information is integrated into multi-turn dialogues for the next sentence selection problem. The improvement is significant, with BERT outperforming GPT, and GPT significantly outperforming baseline methods. BERT’s performance relative to baseline methods varies between 11% to 41% across different datasets.
In summary, the potential for BERT applications in the chatbot field should still be considerable. Single-turn conversation problems are relatively simple; in multi-turn conversations, the issue of how to integrate context is more complex, and I believe BERT can play a significant role here.
Application Field: Text Summarization
Text summarization has two types: one is generative (Abstractive Summarization), where the input is a longer original document, and the output content is not limited to sentences present in the original text but is autonomously generated to reflect the main ideas of the article in a shorter summary; the other type is extractive (Extractive Summarization), which involves selecting parts of the original document that can reflect the main idea, with the summary composed of several original sentences from the text.
Below, I will describe the key points when applying BERT for these two different types of summarization tasks.
Generative Text Summarization
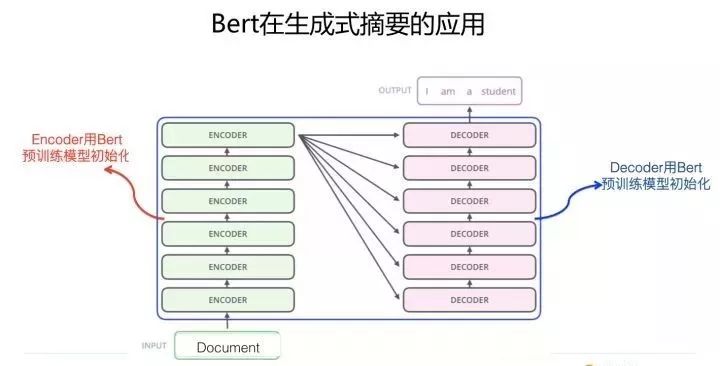
Clearly, generative summarization tasks conform to a typical Encoder-Decoder framework: the original article is input into the Encoder, and the Decoder generates sentences as the summary result. Since this is the case, to leverage BERT’s pre-training results, it mainly manifests in two places. One is on the Encoder side, which is straightforward; it only needs to initialize the Encoder’s Transformer parameters with the pre-trained BERT model.
The other place is on the Decoder side, which is more complicated. The main issue is: although the pre-trained parameters of BERT can also be used to initialize the corresponding Transformer parameters of the Decoder, various experimental results have shown that this approach does not yield good results, primarily because BERT’s pre-training uses a bidirectional language model.
In contrast, the generation process at the Decoder stage for general NLP tasks is to generate one word at a time from left to right. Thus, this differs from BERT’s bidirectional language model training mode, preventing BERT from effectively utilizing the information hinting learned during pre-training. This leads to the pre-trained BERT model not being able to fully exert its effectiveness at the Decoder stage.
Therefore, if one wants to utilize BERT in the Encoder-Decoder framework for generative text summarization, it is not easy to unleash BERT’s power, as it faces the same challenges as generative NLP tasks, and currently, several solutions have emerged, yet this issue seems to remain unsolved to a large extent, making it heavily reliant on advancements in BERT’s generative model technology.
As for how to leverage BERT’s potential in generative tasks, this is an important direction for BERT model improvement. The current solutions and evaluations of their effectiveness will be analyzed in my next article, so I will temporarily skip this topic.
Extractive Text Summarization
Extractive text summarization is essentially a typical sentence classification problem. This means that the model inputs the overall text content of the article and, given a specific sentence in the text, the model needs to perform a binary classification task to determine whether this sentence should be included in the summary.
Thus, extractive text summarization is fundamentally a sentence classification task, but compared to regular text classification tasks, it has its unique characteristics. The key difference is that the input needs to include the entire article content, while the classification object is merely the current sentence being judged. The entire article merely serves as context for the current sentence, which must also be input.
Therefore, for extractive summarization tasks, although it can be viewed as a sentence classification task, the input content and output object do not align well, which is a critical distinction. Consequently, how to express the hierarchical relationship between the sentence and the article in the input part requires some thought.
If one wants to use BERT for extractive summarization, it involves using the Transformer as a feature extractor and initializing the Transformer parameters with BERT’s pre-trained model to construct a binary classification task for the sentence. From the model perspective, BERT can certainly support this task; it just requires initializing the Transformer parameters with BERT’s pre-trained model.
The key issue is how to design and construct the input part of the Transformer. The requirement is that the input must include both the overall content of the article and specify which sentence is currently being judged. Therefore, the critical issue lies in how to construct the input and output of the Transformer model, while the application of BERT’s results is relatively standard.
I previously published an article on methodological thinking:
https://zhuanlan.zhihu.com/p/51934140
Now, I can apply this method. That is, before seeing how others do it, think about how you would do it. Therefore, before seeing any papers on using BERT for extractive summarization, I thought of a couple of methods:
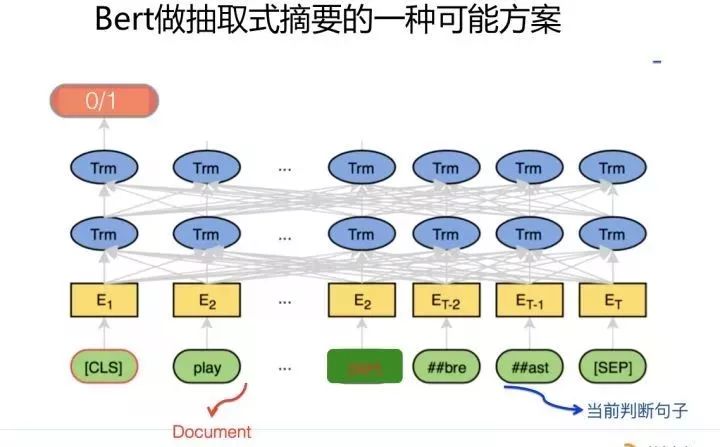
Method 1: Divide the input of the Transformer into two parts. The first part is the original text of the article. Of course, the maximum length supported by BERT is 512, so the original text cannot be too long. The second part is the current sentence to be judged.
These two parts can be separated by a delimiter <SEP>; the output requires that the output corresponding to the first [CLS] input position in the highest layer of the Transformer be a binary classification result of 0/1. If the result is 1, it means that this sentence can be included as a summary sentence; if 0, it means it will not be included.
By sequentially judging each sentence in the article in this manner, the sentences classified as 1 can be concatenated in order to obtain the text summary. This is one possible method; I have not yet seen a model doing this, and I personally feel that this approach is a bit cumbersome.
Method 2: The input of the Transformer consists of only one part, which is the complete content of the article composed of multiple sentences. If this is the input, it raises a new question: how do we know which sentence we are currently judging for inclusion in the summary?
One approach is to add a sentence start marker <BOS> at the beginning of each sentence in the input part, or to interpret this delimiter as a separator between sentences; alternatively, you could add sentence numbers to the corresponding embeddings of the sentences to indicate the boundaries of different sentences (BERT’s input part includes not only standard word embeddings but also sentence embeddings, where words belonging to the same sentence share the same sentence embedding). Although various specific methods can be applied, the core idea is similar: to clearly include markers in the input to differentiate between sentences.
Once the input part is resolved, the remaining question is how to design the output part of the Transformer. Similarly, there may be several approaches. For instance, you can mimic the output of reading comprehension, requiring the Transformer to output several sentence positions <start Position, end Position>. This is one possible approach.
For instance, you could also bind K output heads to the initial input [CLS] position of the Transformer, with each output head indicating the sentence number selected for the summary, specifying a maximum of K summary sentences. This is another possible approach.
Additionally, there are other potential approaches. For example, you could treat the summary as a similar problem to word segmentation or POS tagging, where each input word corresponds to a Transformer high-level node, requiring classification for each word, and the output categories could be defined as [BOS (summary sentence start word marker), MOS (summary sentence internal word marker), EOS (summary sentence end word marker), OOS (non-summary sentence word marker)]. This is also a possible method, treating the summary as a sequence labeling problem. Of course, you can brainstorm; I estimate that many other methods exist.
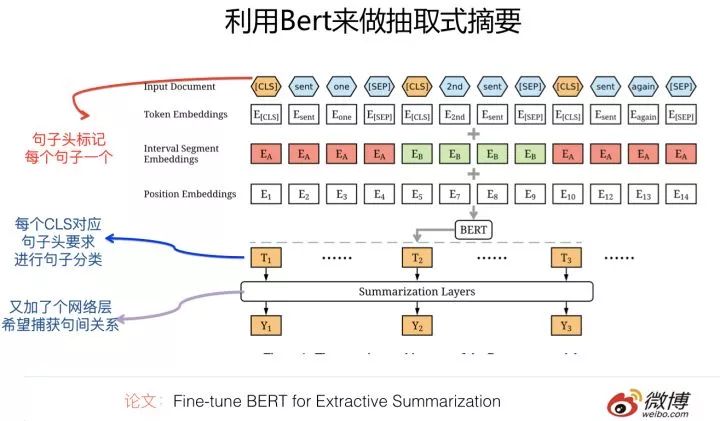
Currently, there is a paper (Fine-tune BERT for Extractive Summarization) that addresses extractive text summarization. Its specific approach essentially follows the framework of the second method mentioned above, where the input part uses special delimiters to separate different sentences, and each sentence is prefixed with a sentence head marker <CLS>. In the output part, it requires constructing an output layer on top of the highest layer embeddings corresponding to the input at the <CLS> position to determine whether the sentence will be selected as a summary sentence.
The difference from the previously described method is that it adds an intermediate network layer between the output layer at the <CLS> position and the actual classification layer to integrate the relationships between different sentences in the article, such as using linear classification / transformer / RNN models to capture inter-sentence information, and then outputting the actual sentence classification results based on this.
However, based on experimental results, the performance of this newly added intermediate network layer, using different models, does not vary significantly, indicating that this additional layer has not captured new information. I personally believe this component could be removed to simplify the model. As for the summary system that introduces BERT’s pre-training model based on the above ideas, while it outperforms the current SOTA models, the improvement is not substantial. This raises an interesting question.
Application Field: Data Augmentation in NLP
We know that in the CV field, image data augmentation plays a very important role, such as image rotation or cropping part of an image to create new training instances. In fact, NLP tasks also face similar needs; the reason for this demand is that the more comprehensive the training data is, covering more scenarios, the better the model’s performance will be. This is easy to understand. The question is how to cost-effectively expand the new training data for tasks.
Of course, you could choose to label more training data manually, but unfortunately, the cost of manual labeling is too high. Is it possible to leverage some models to assist in generating new training data instances to enhance model performance? NLP data augmentation is aimed at this.
Returning to our topic: can we use the BERT model to expand the manually labeled training data? This is the core goal of applying BERT in the data augmentation field. The goal is clear; the remaining issue is the specific methods. This field is relatively novel in terms of BERT applications.
Paper: Conditional BERT Contextual Augmentation
This is a relatively interesting application from the Institute of Computing Technology, Chinese Academy of Sciences. Its purpose is to generate new training data by modifying the BERT pre-training model to enhance task classification performance. This means that for a certain task, input training data a, and generate training data b through BERT to enhance the classifier’s performance.
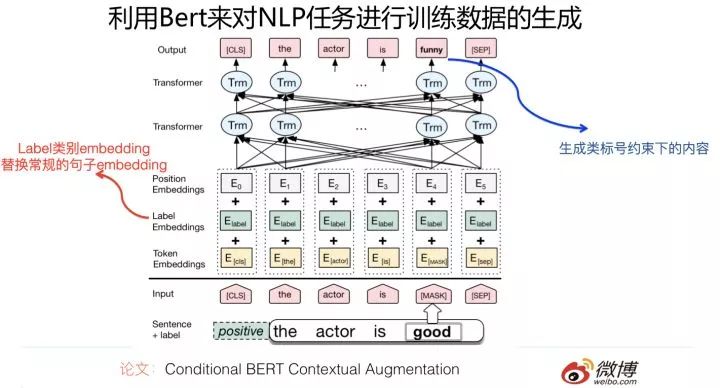
Its modification method is as follows: transforming BERT’s bidirectional language model into a conditional language model. The term “conditional” means that for training data a, certain words are masked, and BERT is required to predict these masked words. However, unlike the usual BERT pre-training, when predicting the masked words, a condition is added at the input: the class label of the training data a is known, and BERT is required to predict certain words based on the class label of training data a and the context. This is intended to generate more meaningful training data.
For example, for a sentiment analysis task, if a training instance S with positive sentiment masks the sentiment word “good,” BERT is required to generate a new training instance N. If no conditional constraints are applied, BERT might predict the word “bad,” which is reasonable but reverses the sentiment meaning for sentiment analysis, which is not what we want.
What we want is that the newly generated training example N also expresses positive sentiment, such as “funny.” By adding the label constraints, this can be achieved. The specific way to increase constraints is to replace the sentence embedding part of the original BERT input with the embedding of the corresponding class label of the input sentence. This approach is quite interesting.
If the new training data generated through BERT is added to the original training data, the paper proves that it can bring stable performance improvements to CNN and RNN classifiers.
Another paper, Data Augmentation for BERT Fine-Tuning in Open-Domain Question Answering, also touches on data augmentation in NLP, but this augmentation does not involve generating training data through BERT as in the previous article. Instead, it seems to use rules to augment positive and negative samples in QA problems, which is not particularly innovative and has little to do with BERT.
It mainly explores how to use these augmented training data in QA tasks under the BERT model. A valuable conclusion is that if both positive and negative examples generated through augmentation are added, it helps to enhance BERT’s performance; furthermore, a stage-wise approach to augmenting data (that is, training with the original training data and augmented training data in multiple stages, with the augmented data being introduced progressively further from the original training data) performs better than mixing augmented and original data for single-stage training.
Therefore, by looking at both papers together, it can be seen as a complete process of generating new training instances using BERT and how to apply these augmented instances.
Application Field: Text Classification
Text classification is a long-established and mature application field in NLP. It means that given a document, the model tells which category it belongs to, whether it is about “sports” or “entertainment,” and so on.
So, what is the effect of applying BERT in this field? Currently, there are also works.
Paper: DocBERT: BERT for Document Classification
In tests on four commonly used standard text classification datasets, the performance achieved by utilizing BERT’s pre-trained model can be said to reach or exceed various previous methods. However, overall, the performance improvement compared to previous common methods such as LSTM or CNN models is not very large, generally in the range of 3% to 6%.
For text classification, BERT has not achieved a significant performance improvement, which can be understood. This is because classifying a relatively long document into a category relies heavily on shallow linguistic features, and there are many indicative words, so it is considered a relatively easy task to solve, and the difficulty level is low, making it challenging for BERT to demonstrate its potential.
Application Field: Sequence Labeling
Strictly speaking, sequence labeling is not a specific application field but a problem-solving mode in NLP. Many NLP tasks can be mapped to sequence labeling problems, such as word segmentation, part-of-speech tagging, semantic role labeling, etc., and there are many.
One of its characteristics is that for any word in a sentence, there will be a corresponding classification output. In the original BERT paper, it also provided guidance on how to use BERT’s pre-training process for sequence labeling tasks, and the application mode in practice follows that model.
If we do not consider specific application scenarios and map different application scenarios to the sequence labeling problem-solving mode, there are currently some works using BERT to enhance application effects.
Paper: Toward Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning
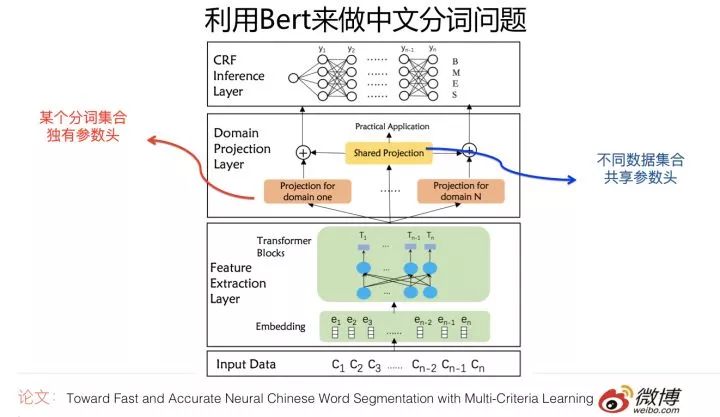
This work uses BERT as a feature extractor for multi-criteria word segmentation. The term “multi-criteria” refers to the fact that the same language fragment may have different word segmentation results under different scenarios.
It uses the pre-trained BERT Transformer as the main feature extractor, and due to the different standards for word segmentation across different datasets, it constructs a unique parameter head for each word segmentation dataset to learn their respective standards. At the same time, a shared parameter head is added to capture common information.
On top of this, CRF is used for global optimal planning. This model achieved the highest word segmentation performance across multiple datasets. However, overall, the performance improvement is not very significant. This may also be related to the fact that previous technical methods had already solved word segmentation quite well, leading to a high baseline.
Paper: BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis
This work addressed two tasks: reading comprehension and sentiment analysis. The aspect extraction task in sentiment analysis was approached using sequence labeling, and the performance after utilizing BERT’s pre-training process did not show significant improvements compared to previous best methods.
Paper: Multi-Head Multi-Layer Attention to Deep Language Representations for Grammatical Error Detection
This work primarily addresses the application problem of syntactic error detection. It maps the problem to a sequence labeling issue and achieves significant performance improvements after using BERT’s pre-training compared to baseline methods.
In the earlier discussion of the dialogue system application field, I also mentioned a single-turn dialogue system that utilized BERT for slot filling, which was also mapped as a sequence labeling problem. The conclusion was a 2% improvement in one dataset and a 12% improvement in another.
Overall, most sequence labeling tasks utilizing BERT can achieve the current best performance, but the extent of performance improvement, compared to many other fields, is not significant. This may be related to specific application fields.
Application Field: Others
In addition to the BERT applications I have categorized above, there are also sporadic works in other fields of BERT applications, which I will briefly mention.
Paper: Assessing BERT’s Syntactic Abilities
This work tested BERT’s syntactic analysis capabilities using a subject-predicate agreement task. Comparisons with traditionally well-performing LSTM models showed that BERT’s performance significantly exceeded that of LSTM on the test data, though the authors emphasized that due to some reasons, this data cannot be directly compared. However, it at least suggests that BERT is not weaker than or is stronger than LSTM in terms of syntax.
Additionally, there are two papers addressing NLP to SQL tasks (Achieving 90% accuracy in WikiSQL/ Table2answer: Read the database and answer without SQL), which means that you do not need to write SQL statements, but instead issue commands in natural language, and the system automatically converts them into executable SQL statements. After using BERT, they also achieved a certain degree of performance improvement. I understand that such tasks are relatively easier due to their domain constraints, so I am not particularly interested in this direction, and I will not elaborate further; interested parties can refer to the papers.
Moreover, there are two papers addressing information extraction tasks, where the performance after using BERT is also relatively average, and this field is indeed worth further attention.
Most of the published BERT applications have already been categorized into the various fields mentioned above. The papers explicitly mentioned here are just a part that I consider to have certain reference value, not the entirety. I have filtered out a batch that I deem not to be of high quality, of little reference value, or whose methods are overly complex, so please note this. Of course, there are certainly valuable works that have not entered my narrow vision, so it is also possible.
All Things Return to One: The Facts May Not Be What You Think
Above, I introduced many ways in which BERT has been applied to enhance effects in various NLP fields. The methods are numerous, and the effects vary, making it easy for people to feel dazzled and unable to grasp the essence. Perhaps before you read this content, you had the impression that BERT is great and can significantly enhance performance across various NLP applications. Is this really the case? Actually, it is not. After you have read the content above, seeing the colorful and diverse methods, it may be easier to feel dazed, as if there are no conclusions to be drawn, and at this moment, your eyes are shining with a confused light…
In fact, this is just a superficial phenomenon. Here, I will summarize. This is purely personal analysis; correctness is not guaranteed, and hitting the mark is just luck; being wrong is also normal.
Although it seems there are various NLP tasks, how to apply BERT is essentially covered in the original BERT paper, where most of the processes are discussed. The process of utilizing BERT is fundamentally the same: using the Transformer as a feature extractor, initializing the parameters of the Transformer with the BERT pre-trained model, and then fine-tuning it for the current task, that’s all.
If we analyze it more meticulously by task type, the conclusions may be as follows:
If the application problem can be transformed into a standard sequence labeling problem (word segmentation / part-of-speech tagging / semantic role labeling / dialogue slot filling / information extraction, etc., many NLP tasks can be transformed into sequence labeling problem-solving forms), or single-sentence or document classification problems (text classification / extractive text summarization can be seen as a context-aware single-sentence classification problem), then BERT can be directly utilized without special modifications.
Current experimental results seem to indicate that in these two types of tasks, using BERT should be able to achieve the best performance, but compared to the best models prior to adopting BERT, the performance improvements seem relatively limited. Is there a deeper reason behind this? I have a judgment that I will discuss later.
If it is a short document’s dual-sentence relationship judgment task, such as typical QA / reading comprehension / short document search / dialogue tasks, the way to utilize BERT is also intuitive: it involves inputting two sentences with a separator as proposed in the original BERT paper, without needing special modifications. Currently, it appears that tasks in this category often see substantial performance improvements.
However, why do you feel that there are many different models when reading the above text? This is primarily because in certain NLP fields, despite the process of utilizing BERT being similar, specific task characteristics need to be separately addressed. For instance, how to resolve the long document input issue in the search field, and the need for other methods for coarse ranking in the search field; for extractive summarization, how to design input and output is a problem, as it differs from regular text classification; for multi-turn dialogue systems, the integration of historical information requires a method for historical information fusion or selection… and so on. In fact, the key parts of applying BERT do not have any special features. This has long been discussed in the original BERT paper. “Do not be surprised by the spring sleep, betting on the book reduces the tea aroma; at that time, it was just considered ordinary.” Many things are just like that.
After my whimsical explanation, has the light of confusion in your eyes extinguished? Or has it become even more blazing?
72 Transformations: Reconstructing Application Problems
If the above judgments are correct, you should ask yourself a question: “Since it appears that BERT is more suitable for handling sentence pair relationship judgment problems, and for single-sentence classification or sequence labeling problems, while effective, the performance improvements seem less pronounced. Can we utilize this point of BERT and think of how to leverage it? For instance, can we transform single-sentence classification problems or sequence labeling problems into a form of dual-sentence relationship judgment?”
If you can genuinely pose this question, it indicates that you are quite suitable for cutting-edge research.
In fact, some works have already done this, and it has been proven that if application problems can be reconstructed, there is no need to do anything else; just this transformation can directly enhance the performance of these tasks, with some tasks showing significant performance improvements. How to reconstruct? For certain NLP tasks with specific characteristics, if it seems to be a single-sentence classification problem, you can introduce a virtual sentence to transform the single-sentence input problem into a sentence pair matching task. This way, you can fully leverage BERT’s advantages.
This is how to reconstruct.
Paper: Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence
This work comes from Fudan University. It utilizes BERT to optimize fine-grained sentiment classification tasks. The so-called fine-grained sentiment classification task refers to not only making an overall judgment on the sentiment tendency of a certain sentence or entity but also making different judgments for different aspects of the entity. For example, in the sentence “LOCATION1 is often considered the coolest area of London,” it indicates how the sentiment tendency of aspect A (such as price) of a certain entity (in this case, a location) is, and how aspect B (such as safety) is.
This work is very clever; it transforms the conventional single-sentence classification problem of sentiment analysis into a sentence pair matching task by adding auxiliary sentences (for instance, in the above example, an auxiliary sentence could be: “What do you think of the safety of LOCATION 1?”). As mentioned earlier, many experimental results have shown that BERT is particularly suited for sentence pair matching tasks, so this transformation undoubtedly allows for fuller utilization of BERT’s application advantages. Experimental results have shown that after this problem transformation, performance improves significantly.
Salesforce also has a similar idea in its work (Unifying Question Answering and Text Classification via Span Extraction), and some of its experimental results also indicate that single-sentence classification tasks can be enhanced by adding auxiliary sentences to transform them into dual-sentence relationship judgment tasks.
Why does it happen that for BERT applications, the same data and task can achieve significantly better performance simply by transforming a single-sentence task into a sentence pair matching task? This is indeed a good question, and I will provide two possible explanations later.
This direction is worth further exploration; currently, there are still few works in this area, and I sense there is still great potential to be tapped, whether from an exploratory or application perspective.
Changing the Child: In-domain and Out-domain Issues During Fine-tuning
We know that during the application of BERT, the actual data used for a specific application is during the second stage of fine-tuning, where the parameters of the Transformer are adjusted by training with the task’s training data, which generally leads to significant performance improvements.
The so-called in-domain and out-domain issues refer to the situation where the hand task has a dataset A, but in the fine-tuning stage of BERT, dataset B is used. Knowing what out-domain means also clarifies what in-domain means: it indicates that dataset A for the hand task is used to fine-tune the parameters without introducing other datasets.
Now the question is: why would you want to introduce dataset B when the hand task is A? This is actually a common occurrence in practical applications. If the training data for your hand task A is sufficiently large, you can follow the in-domain route.
However, if the training data for your task A is too small, generally speaking, even if it can be used for fine-tuning BERT, the performance is likely to be limited, as the BERT model, with its large parameter scale, may not be able to fully capture task characteristics with too few fine-tuning data.
Therefore, we look forward to introducing a dataset B that is somewhat similar to the hand task A during the fine-tuning stage, to transfer some common knowledge from dataset B to the current task A in order to improve the performance of task A. In a sense, this is somewhat similar to the goal of multi-task learning.
Now the new question is: since we expect dataset B to transfer knowledge to the current task A, what factors determine the impact of different nature datasets B on the current task A? This is actually a very practical and interesting question.
Currently, there are some works and preliminary conclusions addressing these issues.
Paper: ThisIsCompetition at SemEval-2019 Task 9: BERT is unstable for out-of-domain samples studied the impact of out-domain data on target tasks, using approximately 9,000 training samples from the electronic domain for the fine-tuning stage, while the target task was in the hotel domain.
It can be seen that there is a significant difference between these two fields. Through comparative experiments, the conclusion is that when it is an out-domain situation, the performance of the target task is very unstable, with the lowest performance of the hotel task being 0 and the highest being 71, with a variance of 31. This indicates that the performance fluctuates dramatically between the extremes. Why is this the case? Currently, there is no explanation. This is worth exploring in depth.
From this work, we can infer that even if dataset B is relatively out-domain compared to the hand task A, if its domain similarity is closer to the hand task A, the performance should be better, which seems to be quite straightforward to understand. However, this is my inferred conclusion, and I have not seen specific research comparing this; this is a topic worth investigating.
Another work is Simple Applications of BERT for Ad Hoc Document Retrieval. Although it studies information retrieval, it also designed some experiments related to out-domain.
It verified some characteristics of the data used during the fine-tuning stage of BERT: the task relevance of the training data B used in the fine-tuning stage compared to the downstream task data A is more important than the similarity of the external presentation forms of the two datasets. The experimental conclusion is that for a downstream short-text retrieval task (task A), although it differs significantly from the news text format of TREC retrieval (out-domain data B), since both are retrieval tasks, it is relatively better to fine-tune BERT with this data compared to QA tasks (another out-domain dataset B).
This indicates that for out-domain situations, the task similarity between the fine-tuning dataset B and the downstream task A has a significant impact on performance; we should try to find the same or similar tasks for fine-tuning, even if they appear different in form.
Another work is Data Augmentation for BERT Fine-Tuning in Open-Domain Question Answering. Although it is primarily about data augmentation, I believe the conclusions from its experimental results can also be applied to out-domain situations. Its conclusion is that if there are several new training datasets, such as B, C, and D, each differing in similarity to the target task A, with B being the furthest, C next, and D being the closest to A.
Then, if this is the case, one approach is to combine A+B+C+D for fine-tuning the model, while another approach is to fine-tune the model in stages from far to near, starting with the most distant B, then C, and finally D, followed by A. The conclusion is that the stage-wise approach is significantly better than the first method.
In addition, I believe that for out-domain situations, if the fine-tuning task and the downstream task have relevance, the larger the dataset, the greater the positive influence on the downstream task.
In summary, based on the current research conclusions and my own casual inferences, the likely conclusion is that for out-domain situations, the first choice is to fine-tune with datasets B that are the same or similar to the hand task A, and the higher the domain similarity between the two datasets, the better. Additionally, the larger the dataset, the better.
If multiple different datasets are available, it is better to fine-tune the model in stages based on their similarity to the hand task, starting from the farthest.
This direction is a very valuable area, and it seems that related work is still too sparse. Some issues have not been clarified, and further exploration to find good experiences is worthwhile, as we often encounter situations where task data is insufficient, making it challenging to leverage BERT effectively.
Competitive Advantage: What is BERT Good At?
After reviewing almost all published BERT application works, it is evident that while BERT has made progress in many application fields, the promoting effect of introducing BERT varies across different directions. Some areas exhibit performance improvements of even 100%, while others show relatively modest enhancements.
This leads me to ask a new question: Why does this phenomenon occur? It indicates that BERT has application scenarios that are particularly suited for it; if an application scenario can maximize BERT’s strengths, the performance tends to increase significantly. However, if the application scenario cannot fully leverage BERT’s advantages, the improvements, while present, may not be particularly noticeable.
Thus, a new question arises: What types of NLP tasks are BERT particularly good at solving? What scenarios are more suitable for BERT to address?
To answer this question, I compared various works and attempted to summarize and infer some conclusions, aiming to identify the characteristics of tasks that can tap into BERT’s advantages. The analysis results are as follows, purely personal judgments, and mistakes are inevitable; please refer cautiously to avoid misleading you.
First, if NLP tasks lean towards having answers contained within the language itself and do not particularly rely on external textual features, applying BERT often leads to significant performance enhancements. Typical tasks include QA and reading comprehension, where the correct answers are more dependent on language comprehension, and the stronger the understanding capability, the better the problem is solved, with less reliance on external judgment factors, resulting in particularly noticeable improvements.
Conversely, for certain tasks where non-textual features are also critical, such as user behavior, link analysis, and content quality in search, BERT’s strengths may not be easily exploited. Similarly, the recommendation system faces analogous reasoning, where BERT may only assist in text content encoding, while other user behavior features are challenging to integrate into BERT.
Second, BERT is particularly well-suited for solving sentence or paragraph matching tasks. This means that BERT excels at addressing sentence relationship judgment problems, which is comparatively more advantageous than other typical NLP tasks like single-text classification or sequence labeling. Many experimental results have demonstrated this.
The reasons for this may primarily be twofold. One reason is that the inclusion of the Next Sentence Prediction task during the pre-training phase allows BERT to learn some knowledge about inter-sentence relationships, making it particularly well-suited for downstream tasks involving sentence relationship judgments, thus yielding significant effects.
The second possible reason is that the self-attention mechanism inherently provides attention effects between any words in sentence A and any words in sentence B. This fine-grained matching is particularly important for sentence matching tasks, so the intrinsic characteristics of the Transformer determine its suitability for these tasks.
From BERT’s strengths in handling sentence relationship tasks, we can further infer the following viewpoints:
Since the pre-training phase includes the Next Sentence Prediction task, which promotes similar downstream tasks, could we continue to add other new auxiliary tasks during the pre-training phase? If this auxiliary task possesses a degree of universality, it could directly enhance the performance of a class of downstream tasks. This is also an interesting exploration direction; however, such directions typically fall into the realm of the affluent in the NLP field, while the less affluent can only observe, applaud, and cheer.
Third, BERT’s applicable scenarios are related to the degree of deep semantic feature demand in NLP tasks. It seems that the more a task requires deep semantic features, the more suitable it is to utilize BERT for resolution; conversely, for some NLP tasks, shallow features suffice to solve the problem. Typical shallow feature tasks include word segmentation, POS tagging, NER, and text classification, where these types of tasks require only short contexts and shallow non-semantic features to be adequately addressed, resulting in limited room for BERT to exert its influence, almost akin to using a sledgehammer to crack a nut.
This is likely because the Transformer layers are relatively deep, allowing for the capture of various features at different levels and depths. Thus, for tasks requiring semantic features, BERT’s ability to capture these deep features is more easily realized, while for shallow tasks like word segmentation or text classification, traditional methods may suffice.
Fourth, BERT is more suitable for solving NLP tasks with relatively short inputs, while tasks involving longer inputs, such as document-level tasks, may not be as effectively addressed by BERT. The main reason is that the self-attention mechanism of the Transformer requires attention calculations for any two words, leading to a time complexity of n squared, where n is the input length.
If the input length is relatively long, the training and inference speed of the Transformer decreases significantly, thereby limiting BERT’s input length. Consequently, BERT is better suited for addressing sentence-level or paragraph-level NLP tasks.
There may be other factors, but they do not seem to be as evident as the four points above, so I will summarize these four basic principles.
Gold Mining: How to Identify Untapped BERT Application Fields
Given that we have summarized the characteristics of tasks that BERT excels at, the next step is to search for application fields that have not yet been explored but are particularly suitable for BERT. Then, you can unleash your talents.
How to find these fields? You can look for application fields that meet one or more of the following conditions. The more conditions that are met, the more theoretically suitable it is to use BERT:
-
The input is not too long, ideally a sentence or paragraph, to avoid the long document issues with BERT;
-
The language itself can effectively resolve the problem, without relying on other types of features;
-
Avoid generative tasks, steering clear of the pitfalls of BERT’s insufficient performance in generative tasks;
-
It is preferable to involve multi-sentence relationship judgment tasks, fully leveraging BERT’s strengths in sentence matching;
-
It should ideally involve semantic-level tasks, taking full advantage of BERT’s ability to encode deep linguistic knowledge;
-
If it is a single-input problem, consider whether you can add auxiliary sentences to transform it into a dual-input sentence matching task;
At this point, you might be feigning curiosity and asking me: What application fields meet these characteristics?… Well, brother, this is not a question of curiosity; it is a matter of laziness. I invite you to dinner, and the vinegar is ready, and now it just depends on your dumplings. It’s up to you to figure it out; if you have time to ask such questions, you might as well make the dumplings yourself… It’s better to retreat and make dumplings than to envy the fish in the deep.
New Trends: Can BERT Unify the World of NLP?
Before the emergence of BERT, different application fields in NLP often used different models that were characteristic of those fields, leading to a seemingly diverse and significantly different landscape. For example, reading comprehension relied on various forms of Attention; the search field, while entering the DNN era, still largely depended on Learning to Rank frameworks; and text classification was a typical battleground for LSTM…
However, with the emergence of BERT, I believe that the current chaotic situation, where different application fields are dominated by various technical means, will not last long. BERT, carrying the mandate of the pre-trained model, will gradually unify the fragmented landscape of various NLP application fields, restoring the old mountains and rivers and heading towards the heavenly gate. This likely marks the beginning of a new era in NLP, as historically, there has not been such a dominant NLP model.
Why do I say this? In fact, you should have seen signs of this in the content of the first section. The above has involved many application fields in NLP; although BERT’s promoting effects vary across different fields, with some being significant and others less so, the almost universal observation is that it has outperformed the previous SOTA methods in nearly all fields, with the only distinction being the degree of improvement, rather than whether there is an improvement.
This implies that at least in the mentioned fields, the architecture and model of BERT can completely replace all other SOTA methods in that field. What does this imply? It means that at least in these fields, a relatively unified solution can be implemented, leading to a convergence of methods. This indicates that the era of convergence has arrived, with BERT as the leader.
This also means that you will have to learn significantly less than before, as the cost-effectiveness of learning NLP has dramatically improved. You can confidently say that this is a good thing, right? Oh, I didn’t ask you to pat someone else’s chest, brother…
As the capabilities of BERT continue to be enhanced, it is likely that this unified approach will accelerate. I estimate that within the next 1 to 2 years, the majority of NLP subfields will likely converge around the BERT two-stage + Transformer feature extractor framework.
I believe this is a very positive development because it allows everyone to focus on enhancing the capabilities of the foundational model. As long as the foundational model’s capabilities improve, it means that the application effects across various fields will directly benefit from this without needing to devise personalized solutions for each field, which is somewhat inefficient.
Will this scenario truly unfold? Can such a powerful model exist across the vast array of subfields in NLP? Let’s wait and see.
Of course, I personally hold an optimistic view on this.
That’s all for now; even I feel it’s too long. To those who made it to the last sentence, I commend your diligence and patience… However, please consider how much time you estimate it took me to write this article, compared to the time you spent reading it?… Additionally, I haven’t been feeling particularly well lately, but I still have to find ways to concoct some jokes to make you laugh… After writing these AI articles, my technical skills may not have improved, but the possibility of transforming into a joke-teller has indeed increased significantly… Li Dan, just wait for me…
All things considered, it’s just that.
Author Introduction: Zhang Junlin, Council Member of the Chinese Chinese Information Society, PhD from the Institute of Software, Chinese Academy of Sciences. Currently a senior algorithm expert at Sina Weibo AI Lab. Previously, Zhang Junlin served as a senior technical expert at Alibaba, leading a new technology team, and held positions as a technical manager and director at Baidu and Yonyou. He has published books including: “This is Search Engine: Core Technology Explained” (which won the 12th National Excellent Book Award) and “Big Data Daily Knowledge Record: Architecture and Algorithms”.
Original Link: https://zhuanlan.zhihu.com/p/68446772
This article is part of the Machine Heart column. Please contact the original author for authorization to reprint.
✄————————————————
Join Machine Heart (Full-time Reporter / Intern): [email protected]
Submissions or Seeking Coverage: content@jiqizhixin.com
Advertising & Business Cooperation: [email protected]