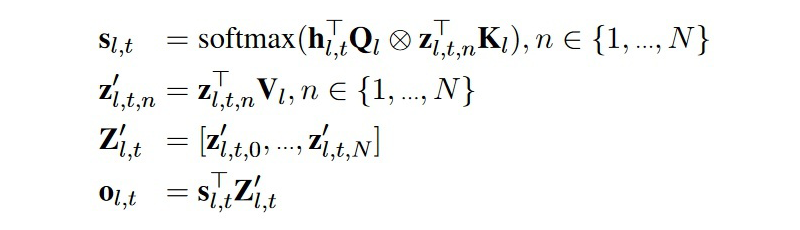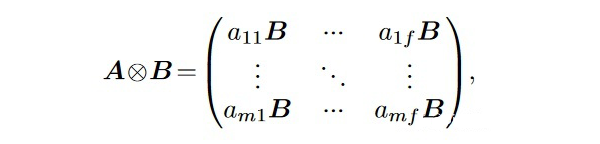MLNLP ( Machine Learning Algorithms and Natural Language Processing ) community is a well-known natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.The vision of the community is to promote communication between academia, industry, and enthusiasts in natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | PaperWeekly
Author | Wu DiAffiliation | UCLAResearch Direction | NLP
1
“Introduction”
In the application of modern natural language processing (NLP), using pre-trained representations for transfer learning is an important method. After deep learning began to be applied, transfer learning first appeared using pre-trained feature vectors and fine-tuning pre-trained language models (PLMs).[1] Based on pre-trained models, adapters provide a new idea: can we insert a small number of parameters into the model and only train these parameters during fine-tuning for a downstream task, while keeping the original parameters of the pre-trained model unchanged? If using adapters allows us to achieve the same effect (or better) as fine-tuning the entire model, it can bring many benefits:
Higher parameter efficiency: only a small number of parameters are needed for a task, training is faster, consumes less memory, is less prone to overfitting on smaller datasets, and is more conducive to model storage and distribution.
The forgetting problem of continual learning: adapters freeze the original model parameters, ensuring that the original knowledge is not forgotten.
Multi-task learning: using adapters can also learn multiple tasks with relatively few parameters, compared to traditional multi-task learning, the advantage is that different tasks have less impact on each other, but the disadvantage is that mutual supervision from different tasks may decrease.
Adapters were first proposed by [2] and applied to models in computer vision, later introduced into NLP by [1]and more related work has emerged in recent years. Recently, there has been great interest in the application of adapters in NLP; in this article, I will organize some notes on papers related to learning adapters, many of which have implementations in the open-source library AdapterHub:https://adapterhub.ml/
2
“Bottleneck Adapter”
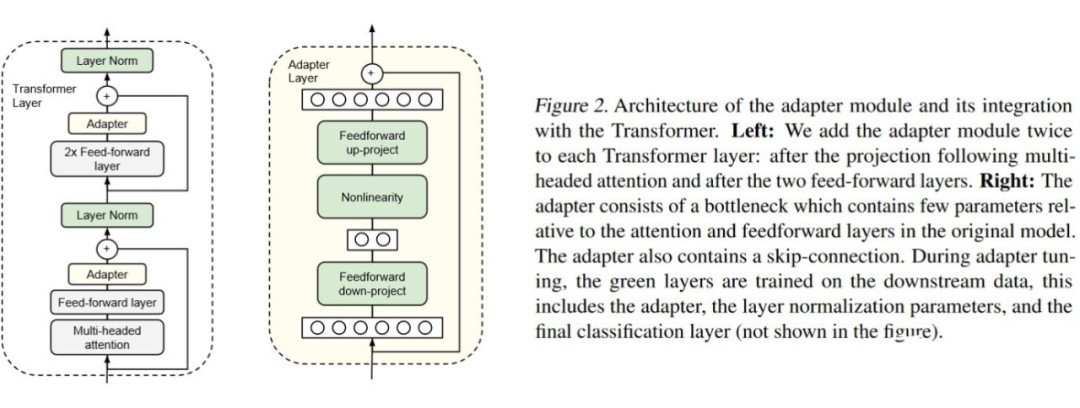
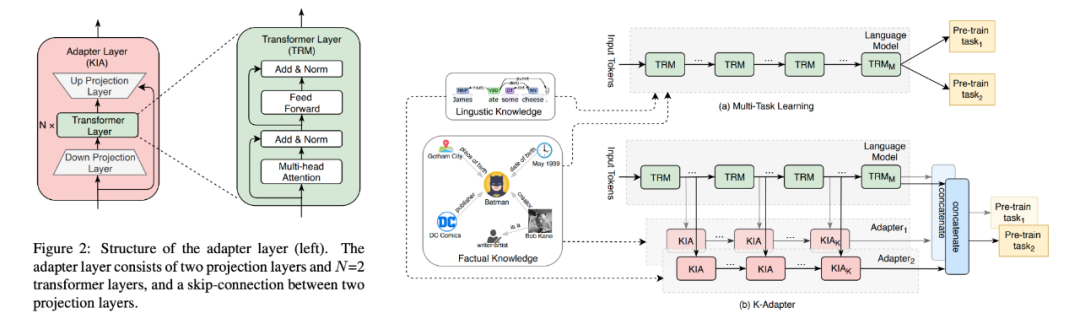
First, let’s summarize the paper that introduced adapters into NLP [1]. The main contribution of this paper is to propose the adapter structure applied to transformers and demonstrate the feasibility of using adapters for parameter-efficient transfer learning on classic NLP tasks.Network Structure: As shown in the figure below,[1] proposed inserting adapter layers into the transformer layers. The structure of the adapter layer is simple: it projects down to a smaller dimension, passes through a layer of non-linear activation function, and then projects back up to the original dimension. Additionally, there is a residual connection between the input and output of the entire adapter layer. This type of adapter is also vividly referred to as a bottleneck adapter. Taking BERT as an example, depending on the size of the bottleneck layer, the newly added parameters account for approximately 0.5% to 8% of the original model.▲Structure of the Bottleneck AdapterInitialization: All adapter parameters are sampled from a normal distribution with a mean of 0 and a standard deviation of 0.01. This ensures that at the beginning of training, the output of the fully connected network of the adapter backbone is very small, mainly passing information through the residual connection.Training: Freeze all parameters of the original model, only train the parameters of the adapter layer and the parameters of layer normalization.Experiments: Mainly conducted on classification tasks (GLUE) and extractive question answering tasks (SQuAD v1.1), comparing the performance of fine-tuning the entire BERT-Large model and fine-tuning only the adapter of BERT-Large.Experimental Findings:
Fine-tuning only the adapter can achieve performance close to that of fine-tuning the entire model, and if the size of the adapter is adjusted according to each task, it can achieve a relatively small drop in performance.
The parameter efficiency of using adapters is higher than fine-tuning several layers close to the output of BERT, and performance is better than only training the parameters of layer normalization.
During the inference phase, pruning the adapter of a certain layer is feasible and does not significantly affect performance. However, pruning multiple layers will greatly decrease performance. Compared to layers close to the output (top layers), layers close to the input (bottom layers) are less sensitive to pruning.
When the standard deviation of the weight initialization distribution is less than 0.01, the effect is better; too large a standard deviation can worsen the effect.
3
“Improvements to Adapter Structures or Training/Inferences Processes”
The papers [3-5] improved and expanded upon [1], addressing the following main issues:
AdapterFusion [3]: How to better combine multi-task learning with adapters, leveraging the advantages of multi-task learning while avoiding its disadvantages?
AdapterDrop [4]: How much slower is the speed of adapters during inference? How to prune adapters?
Compacter [5]: Can we make adapter layers more lightweight without sacrificing performance?
3.1 AdapterFusion
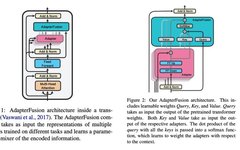
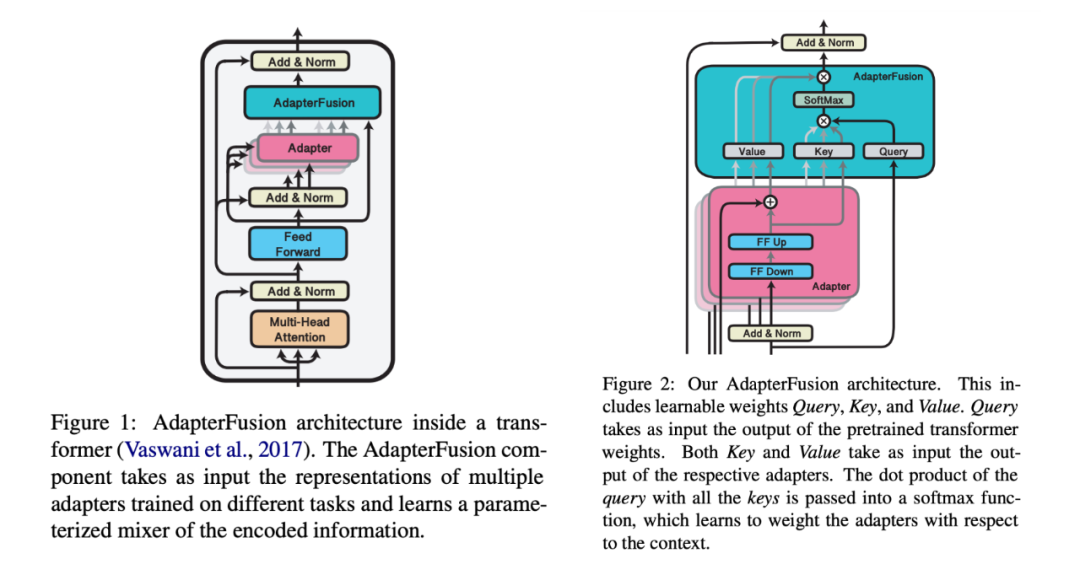
To combine knowledge from multiple tasks, traditional methods are either sequential fine-tuning or multi-task learning. A major issue with the former is the need for prior knowledge to determine the order, and the model easily forgets the knowledge learned from previous tasks. The latter has issues with different tasks influencing each other and balancing tasks with significantly different dataset sizes. One advantage of adapters is that they do not require updating the parameters of the pre-trained model; instead, they insert relatively few new parameters to effectively learn a task. At this point, the parameters of the adapter somewhat express the knowledge needed to solve this task. Inspired by this,[3] proposes that if we want to combine knowledge from multiple tasks, we can consider combining the parameters of the adapters from multiple tasks.[3] proposed a multi-task learning framework for AdapterFusion divided into two stages. First, for each task, learn a set of new adapter parameters. Then, for a specific target task, learn a fusion module to combine all the adapters from the first step.[3] assumes that each task in the second stage is included in the first stage, without considering the introduction of new tasks in the second stage.Network Structure:▲Structure of AdapterFusionThe figure shows the structure of AdapterFusion (right) and its placement in the transformer layer (left). The single adapter layer (pink) is no different from that in [1] but only retains the topmost adapter layer in each transformer layer, removing the adapter layers after the multi-head attention layer.AdapterFusion layers (blue-green) are structured as an attention module. Q is the output of the fully connected layer in the original transformer layer, and K and V are the outputs of the adapters corresponding to each task. Similar to cross-attention in transformers, QKV undergoes a linear projection, then QK is multiplied and softmax is calculated, and the output combines V (outputs from different task adapters) with weights, detailed in the formula below. l represents the layer number, t represents the sequence position, and n represents the task (with a total of N tasks). Abstractly, the AdapterFusion for task X corresponds to selecting and applying the knowledge most suitable for task X from the knowledge of multiple tasks based on the output of the previous layer.Initialization: QK is randomly initialized, and V is initialized to the identity matrix plus some small random noise.Training:
First step: Train the adapter for each task. The authors experimented with two methods: (1) independently initializing a set of adapter parameters for each task, only learning the current task without updating the parameters of the pre-trained model (ST-A); (2) assembling all adapters together and simultaneously training all adapters using a multi-task learning loss function, also fine-tuning all pre-trained parameters (MT-A).
Second step: Assemble all adapters from the first step (only for ST-A, MT-A has already been assembled), then add the AdapterFusion layer and train on the target task. The dataset used is the same version as that used in the first step. The authors also experimented with using MT-A in the second step as a control.
Experiments: The authors selected 16 different types and sizes of tasks for multi-task learning. Categories include commonsense, sentiment analysis, natural language inference, and sentence relevance; dataset sizes include over 40k, over 10k, over 5k, and below 5k. The pre-trained models used are BERT-base and RoBERTa-base.Experimental Findings:
In the first stage of training, using ST-A can achieve performance close to that of fine-tuning the entire model, while using MT-A will somewhat affect performance. The authors explain that training only the adapter serves as a form of regularization that helps generalization.
In the second stage, adding AdapterFusion significantly improves performance for tasks with smaller training sets.
The best results are achieved when using ST-A in the first stage and AdapterFusion in the second stage, also leveraging the reuse of adapters. Using MT-A in the first stage also requires using MT-A in the second stage to see some improvement.
For tasks where AdapterFusion shows significant improvement, each AdapterFusion layer tends to attend to the adapters of other tasks.
3.2 AdapterDrop
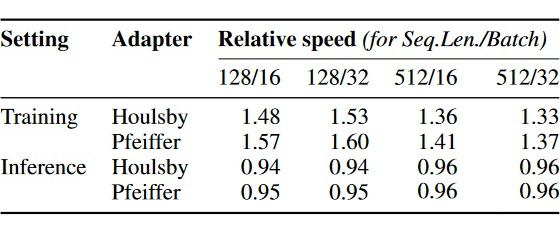
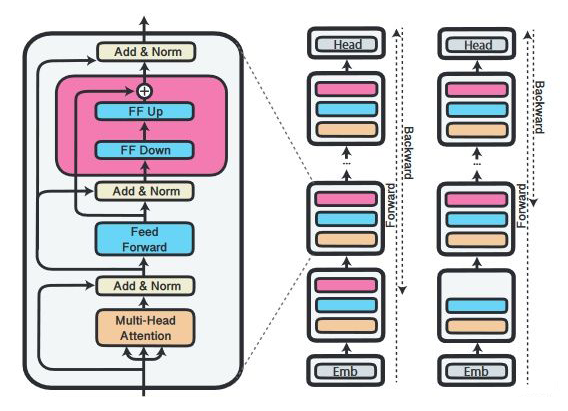
The main contributions of the paper [4] are: 1) establishing a series of measurement results related to the training/inference speed of adapters; 2) proposing a method to prune the entire adapter layer, AdapterDrop, to accelerate the speed of multi-task inference; 3) establishing results for pruning AdapterFusion.Training and Inference Speed of Adapters: The authors measured the training and inference speed of both [1] and [3] adapter structures on two different GPUs compared to fine-tuning the entire model, and the results are shown in the figure below. Training with adapters is approximately 60% faster than fine-tuning the entire model, while inference is about 4%-6% slower than using the original model.3.2.1 AdapterDropTo accelerate inference speed, certain layers of adapters can be pruned during inference. Based on [1]‘s conclusions, pruning adapters close to the input has less impact on performance. Therefore, the authors of AdapterDrop propose that during inference, the lowest n layers of adapters, which are closest to the input, can be pruned. To minimize performance drop, the authors designed two training schemes: (1) specialized AdapterDrop: fix n during training, and the model prunes the first n layers during inference; (2) robust AdapterDrop: randomly select the size of n for each batch during training, allowing the trained model to adapt to multiple n. Since the other parameters of the original model are not trained, the gradient during training can only be backpropagated to the earliest layer that retains adapters (see the figure below).▲Standard Adapter Training (middle) and AdapterDrop Training (right)Experimental Results: On multiple tasks of GLUE, both types of AdapterDrop can achieve minimal performance drops when n=5 or less during inference, while traditional adapters show rapid performance decline when n>1. When five layers of adapters are removed, training speed can be accelerated by 26%, and multi-task simultaneous inference speed can be accelerated by 21%-42%, exceeding the inference speed of the original model. It is important to note that to highlight the advantages of AdapterDrop, the authors measured speed in scenarios of multi-task simultaneous inference, meaning inputting text and the model generating outputs for multiple tasks.3.2.2 Pruning AdapterFusionThe authors first measured the training and inference time of AdapterFusion (AF, [3]) and found that compared to the overall fine-tuning and inference of the original model, the training speed of AF with eight adapters per layer is about 47% slower, and the inference speed is about 62% slower, mainly because adapters need to be inferred one by one. The authors trained an AF model on eight tasks of GLUE (excluding WNLI) and experimented with two ideas to accelerate AdapterFusion:
Removing the first few AF layers has different impacts on performance for different tasks. For example, the impact on RTE is minimal, but CoLA is very sensitive. This indicates that simply removing AF layers is not a universally good method.
Pruning adapters that contribute less to the output in each layer. The authors measured the average activation level of each adapter using the training set (which should be the weighted output) and kept only the two adapters with the highest contributions in each layer, maintaining model performance similar to the original while improving inference speed by 68%.
3.3 Compacter
The structure of Compacter comes from the paper [5]. The authors adopted the placement and training methods of adapters from [1] but redesigned a more lightweight adapter structure that only requires adding approximately 0.05%-0.2% of the original model’s parameters to achieve good performance on benchmarks like GLUE and SuperGLUE.Network Structure:
Compacter applies the Kronecker product. The Kronecker product of an mxf matrix A and a pxq matrix B is
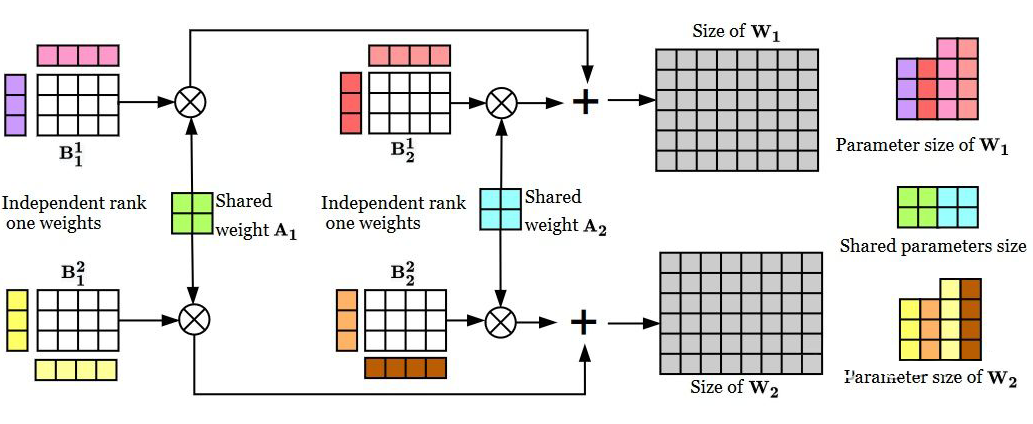
Assuming the model’s hidden state size is k and the bottleneck size is b, the adapter layers in [1] contain two kxb matrices. Compacter first borrows the concept of parameterized hypercomplex multiplication layers, expressing the parameters of each adapter as the Kronecker product of an nxn matrix A and a (k/n)x(d/n) matrix B, significantly reducing the number of parameters.
On top of this, all adapters are required to share matrix A.
Additionally, matrix B is further decomposed into n groups of products of two low-rank matrices, with the two matrices sized (k/n)xr and rx(d/n). To reduce the number of parameters, the authors fixed r to 1.
The structure of the Compacter layer is shown in the figure below. The figure displays two compacter layers, with the colored parts being the parameters that need to be trained. By expressing the parameters from the adapter layers in [1] in this form, the structure of Compacter is obtained.
▲Structure of CompacterExperiments: The authors mainly used T5-base to experiment on the tasks of GLUE and SuperGLUE. They compared Compacter with the entire model fine-tuning and a series of parameter-efficient methods. For Compacter, the authors also experimented with a version without low-rank decomposition for comparison and a structure similar to [3] that retains only one adapter close to the output in each transformer layer (referred to as compacter++).Experimental Results:
On T5-base, the adapter layers from [3] perform better than those from [1]. Both AdapterDrop or merely performing low-rank decomposition on adapter layers perform worse than fine-tuning the entire model.
Compacter’s three innovations allow training only about 0.1% of new parameters to achieve performance comparable to full model fine-tuning.
Compared to full model fine-tuning, Compacter performs better on smaller training sets (0.1k-4k).
4
“What is Contrastive Learning?”
The following papers [6-12] utilize adapter designs to solve specific problems, some focusing on parameter efficiency and others on further enhancing the performance of the original model. Due to space constraints, this section will only provide brief introductions to each paper.
4.1 Bapna & Firat (2019)
This paper [6] mainly applies adapters to solve two problems in neural machine translation (NMT): (1) domain adaptation and (2) large-scale multilingual NMT. The authors primarily adopt a framework of pre-training a base model, then inserting a new adapter for each target task for fine-tuning. The main contribution of the paper is to demonstrate that adapter-based methods can achieve performance similar to full model fine-tuning on NMT tasks while being more parameter efficient. Additionally, in multilingual NMT tasks, a single model can perform well on both low-resource and high-resource languages simultaneously.
Adapter Structure: This paper uses a similar structure to that in [3] (but this work predates [3]), inserting an adapter layer only at the end of each transformer layer. Additionally, the authors reinitialize the parameters of layer normalization (unlike [1], which continues training with the pre-trained layer normalization parameters).
Domain Adaptation: The authors trained on WMT En-Fr, then froze the parameters, inserted adapters, and transferred to IWSLT’15 and JRC. The model outperformed LHUC [7] and was close to full model fine-tuning.
Multilingual NMT: The authors first trained a model for English <=> 102 other languages, then froze the parameters and inserted an adapter for fine-tuning for each combination of (source language, target language). The main baseline methods compared are models trained only on (source language, target language) data. The results show that when English is the source language, most target languages perform comparably to or better than the baseline; however, when English is the target language, there are significant improvements primarily for languages with less training data, while performance may decline for languages with more training data.
4.2 K-Adapter
This paper [8] mainly contributes by using adapters in a modular way to inject knowledge into pre-trained language models to solve some knowledge-intensive NLP tasks (relationship classification, entity type recognition, question answering, etc.). The authors introduce two adapters to inject two types of knowledge into RoBERTa: (1) factual knowledge and (2) linguistic knowledge. The two adapters are trained separately and do not interfere with each other.
Model Structure: K-Adapter does not alter the original transformer layers but instead inserts adapter layers between two transformer layers. Within each adapter layer, two transformer layers are added between the fully connected layers that project down and up (left in the figure below), increasing the module’s expressive capacity. Each adapter layer’s input can see the output of the previous adapter and the output of the neighboring previous transformer layer (right in the figure below).
▲Structure of K-Adapter (left) and Training Method (right)
Pre-training: Insert adapter layers, freeze the parameters of the original model, concatenate the output of the last layer of the original model with the output of the last adapter layer as features, and then learn on specific pre-training tasks.
Factual Knowledge: Trained on the relationship classification task, with a total of 430 classes and 5.5M sentences. By learning to predict the relationships between entities, the model can learn some basic facts and common sense.
Linguistic Knowledge: Trained on dependency relation classification tasks, the authors prepared approximately 1M training samples using Stanford’s parser. By learning to predict the head position corresponding to each token, the model can learn some syntactic/semantic-related knowledge.
Downstream Fine-tuning: The parameters added for each task are trained on the output of the last adapter layer. If using multiple adapters simultaneously, their outputs are concatenated as features. Additionally, the parameters of the original pre-trained model are also fine-tuned.
Downstream tasks mainly cover relationship classification, entity type recognition, and question answering.
The baseline models compared include the previously effective language model + knowledge model, the original RoBERTa model, the original RoBERTa model + randomly initialized adapter parameters, and the original RoBERTa model further trained on two tasks using multi-task learning. Experimental results show that using both adapters simultaneously achieves the best performance. For the last two downstream tasks, factual knowledge is more beneficial, while linguistic knowledge helps more for the first task.
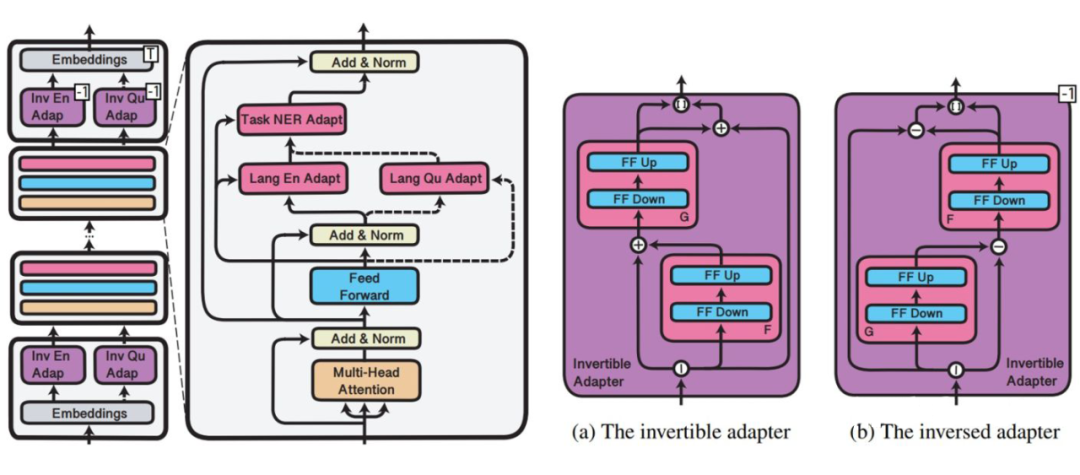
4.3 MAD-X
Similar to the previously summarized AdapterFusion and K-Adapter, MAD-X [9] also aims to use adapters to learn and store modular knowledge, achieving a “plug-and-play” capability. The goal of AdapterFusion is to enable tasks with small training sets to utilize knowledge from tasks with large training sets, while MAD-X aims to allow low-resource languages to utilize knowledge from high-resource languages within the same task.To decouple language and task, the authors propose training corresponding adapters separately, allowing for a low-resource language L to utilize the adapter for language L along with the adapter for task T trained on another language L’. Within this framework, the authors also design invertible adapters as part of the adapters for learning language knowledge.Network Structure: Adapters are still inserted in each transformer layer (shown in the figure below), where language adapters and task adapters follow the network structure of AdapterFusion, while invertible adapters serve as a token-level mapping function, trained together with language adapters, which can be understood as learning a dedicated embedding function for each language on multilingual embedding, but is more parameter-efficient than retraining embeddings for each target language.▲Placement of Three Types of Adapters in MAD-X (left) and Structure of Invertible Adapter (right)Training and Inference: First, for each language, train the language adapter and invertible adapter using the MLM task. Then insert a task-specific adapter, training on the source language training set with the corresponding language adapter and invertible adapter. During inference, use the target language’s language adapter and invertible adapter along with the source language’s task adapter.Experiments and Findings:1. The authors mainly conducted cross-language transfer experiments on named entity recognition, question answering, and causal commonsense reasoning, selecting pairs of 16 languages from various language families with varying training set sizes for experimentation. They added adapters to XLM-R and compared baseline models including mBERT and XLM-R, as well as XLM-R pre-trained on the target language.2. For languages not present during the pre-training phase, both XLM-R and MAD-X using only task adapters perform poorly; however, after pre-training on the target language, XLM-R shows significant improvement.3. For the NER task, both language adapters and invertible adapters have a significant impact on performance. MAD-X is most helpful for transferring knowledge from high-resource to low-resource languages.4. In the causal commonsense reasoning task, MAD-X performs similarly to XLM-R pre-trained on the target language; however, in the question answering task, the latter seems to perform better than MAD-X. Nevertheless, MAD-X requires fewer training parameters.
Philip et al. (2020) [11]: Similar to [6], focusing on multilingual machine translation tasks but introducing adapter parameters for each language rather than for each pair of languages as in [6].
Lauscher et al. (2020) [12]: Similar to [8], using adapters to modularly introduce knowledge.
5
“What is Contrastive Learning?”
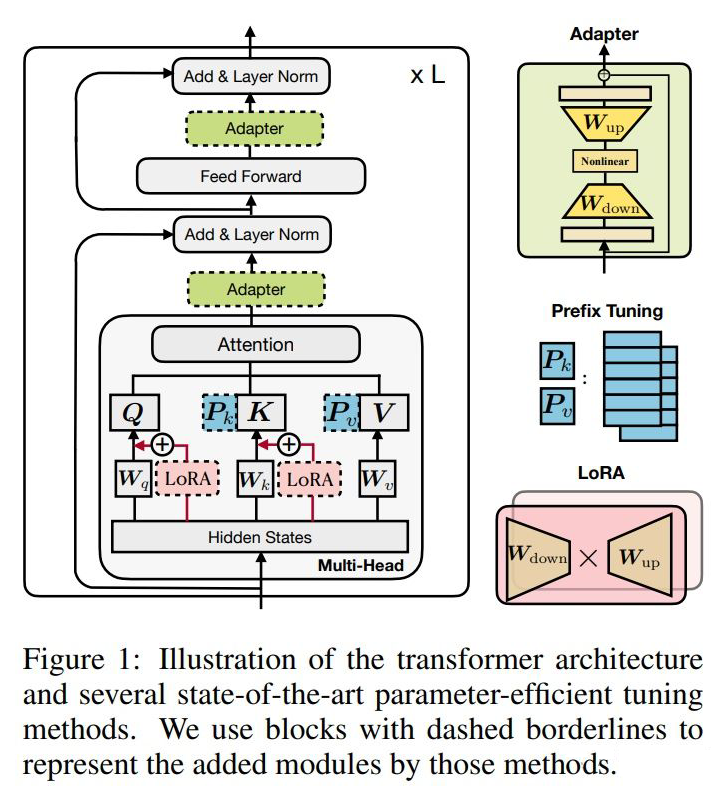
The following ideas are similar to adapters but differ in network structure design; they are not detailed here but are recommended in the ICLR 2022 paper [16] (or the video explanation by He Junxian).
BERT and PAL [13]
Prefix Tuning [14]
LoRA [15]
▲Structures of Three Types of Adapters (adapter, prefix tuning, LoRA), image from [16].References[1] Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q. D., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. Proceedings of the 36th International Conference on Machine Learning, 2790–2799. https://proceedings.mlr.press/v97/houlsby19a.html[2] Rebuffi, S. A., Bilen, H., & Vedaldi, A. (2017). Learning multiple visual domains with residual adapters. Advances in neural information processing systems,30. https://proceedings.neurips.cc/paper/2017/file/e7b24b112a44fdd9ee93bdf998c6ca0e-Paper.pdf[3] Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., & Gurevych, I. (2021). AdapterFusion: Non-Destructive Task Composition for Transfer Learning. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 487–503. https://doi.org/10.18653/v1/2021.eacl-main.39[4] Rücklé, A., Geigle, G., Glockner, M., Beck, T., Pfeiffer, J., Reimers, N., & Gurevych, I. (2021). AdapterDrop: On the Efficiency of Adapters in Transformers. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 7930–7946. https://doi.org/10.18653/v1/2021.emnlp-main.626[5] Karimi Mahabadi, R., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. Advances in Neural Information Processing Systems, 34, 1022–1035. https://proceedings.neurips.cc/paper/2021/hash/081be9fdff07f3bc808f935906ef70c0-Abstract.html[6] Bapna, A., & Firat, O. (2019). Simple, Scalable Adaptation for Neural Machine Translation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 1538–1548. https://doi.org/10.18653/v1/D19-1165[7] Vilar, D. (2018). Learning Hidden Unit Contribution for Adapting Neural Machine Translation Models. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), 500–505. https://doi.org/10.18653/v1/N18-2080[8] Wang, R., Tang, D., Duan, N., Wei, Z., Huang, X., Ji, J., Cao, G., Jiang, D., & Zhou, M. (2021). K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 1405–1418. https://doi.org/10.18653/v1/2021.findings-acl.121[9] Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2020). MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer (arXiv:2005.00052). arXiv. http://arxiv.org/abs/2005.00052[10] Üstün, A., Bisazza, A., Bouma, G., & van Noord, G. (2020). UDapter: Language Adaptation for Truly Universal Dependency Parsing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2302–2315. https://doi.org/10.18653/v1/2020.emnlp-main.180[11] Philip, J., Berard, A., Gallé, M., & Besacier, L. (2020). Monolingual Adapters for Zero-Shot Neural Machine Translation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 4465–4470. https://doi.org/10.18653/v1/2020.emnlp-main.361[12] Lauscher, A., Majewska, O., Ribeiro, L. F. R., Gurevych, I., Rozanov, N., & Glavaš, G. (2020). Common Sense or World Knowledge? Investigating Adapter-Based Knowledge Injection into Pretrained Transformers. Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 43–49. https://doi.org/10.18653/v1/2020.deelio-1.5[13] Stickland, A. C., & Murray, I. (2019). BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning. Proceedings of the 36th International Conference on Machine Learning, 5986–5995. https://proceedings.mlr.press/v97/stickland19a.html[14] Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 4582–4597. https://doi.org/10.18653/v1/2021.acl-long.353[15] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models (arXiv:2106.09685). arXiv. http://arxiv.org/abs/2106.09685[16] He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2022). Towards a Unified View of Parameter-Efficient Transfer Learning (arXiv:2110.04366). arXiv. http://arxiv.org/abs/2110.04366Technical Community Invitation
△Long press to add the assistant
Scan the QR code to add the assistant’s WeChat
Please note: Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue Systems)to apply to join the Natural Language Processing/Pytorch and other technical exchange groups
About Us
MLNLP Community ( Machine Learning Algorithms and Natural Language Processing ) is a grassroots academic community jointly built by scholars in natural language processing both domestically and internationally, and has developed into a well-known natural language processing community, including well-known brands such as 10,000-person top conference exchange group, AI Selection Exchange, AI Talent Exchange and AI Academic Exchange, aiming to promote progress among academia, industry, and enthusiasts in machine learning and natural language processing.The community can provide an open communication platform for practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.