
This article is reprinted with permission from the WeChat public account Paper Weekly (ID: paperweekly). Paper Weekly shares interesting papers in the field of natural language processing every week.
“NLP is not magic, but sometimes its results are almost magically amazing.” Quoted from: http://www.confidencenow.com/nlp-seduction.htm
【Editor’s Note】To clarify, when writing this popular science article on the NLP contact map, deep learning had not yet become popular. AI had not yet transformed and been taken over by DL. At that time, the machine learning community still looked down upon and ridiculed AI, keeping a distance from it. Unexpectedly, today AI is regarded as synonymous with DL and has suddenly become highly sought after. Neural networks are often mentioned, and even NLP has been equated with DL. The symbolic logic AI and rule-based NLP have spent a lifetime together, only to find that they have lost their ‘home’ in the end. Everything is about learning, and everything must be neural. However, I believe that while the world has changed, the principles remain unchanged. Therefore, the following contact map may transcend the narrow thinking of a neural-dominated world. It is not easy to rectify the chaos. This is just one perspective; those who are willing may take the bait.

(NLP Word Cloud, courtesy of ourselves who built the NLP engine to parse social media to generate this graph)
【Editor’s Original Note】In the classic opera “Taking Tiger Mountain by Strategy”, Yang Zirong becomes a guest of the bandit leader, because in the realm where mountains are everywhere, whoever holds the contact map can unify the world. Marx seems to have said that people are the sum of social relationships, and professional fields are no exception. Defining and understanding NLP within relationships can be said to be a shortcut to understanding a discipline and its technology. A wise man knows the way, and it is his duty to elaborate, so I meticulously crafted four contact maps to share with colleagues and online friends. This series of contact maps can be compared to the Little Red Book in the hands of Marshal Lin Biao, urgently needed for quick learning, with immediate effects. Importantly, although knowledge is ever-changing and endless, the trends of the world inherently have their unchanging principles. With these four maps in hand, one can remain unfazed by changes, whether in research or development, and will not lose sight of the revolutionary direction.
An active field constantly generates new concepts and new terms. Without a proper reference map, newcomers are particularly likely to be lost in it. New terms often start off as informal; different people may use different terms for the same concept, and the same term may have different interpretations by different people. Often, there is a chaotic period before the research community gradually reaches a consensus on standardization. Regardless of whether a consensus has been reached, the key is to understand the underlying meanings of the terms (including broad, narrow, traditional definitions, and possible ambiguities). Strengthening sensitivity to terms and continuously exploring to accurately locate new concepts/new terms within the existing system is fundamental for professionals.
This article will systematically sort and explain the terms related to NLP based on these four self-made contact maps. All terms mentioned in this article will be underlined in Chinese upon their first appearance, and italicized in English, mostly with Chinese-English counterparts, and some terms will also provide hyperlinks for further reading and exploration.
Before we delve into the mysteries of the NLP series contact maps, it is necessary to clarify the general concept of natural language processing (NLP) and its higher-level concepts, as well as some terms that can be used interchangeably with NLP.
The term NLP is a broad concept named after the problem domain of “natural language.” As the name suggests, natural language processing is the computer processing of natural language. Regardless of the goal, depth of analysis, as long as it involves computer processing of natural language, it falls under NLP. The so-called natural language refers to the languages we use daily, such as English, Russian, Japanese, and Chinese. It is synonymous with human language, primarily to distinguish it from formal languages, including computer languages. Natural language is the most natural and common form of human communication, not only oral but also written, especially with the proliferation of mobile internet and social networks today. Compared to formal languages, natural languages are much more complex, often containing omissions and ambiguities, which presents considerable processing challenges (hence the establishment of the NLP profession and our livelihood). Incidentally, there are also artificial languages in the gray area of natural language, particularly the widely known Esperanto. Their forms are indistinguishable from natural languages and are designed for human communication, but they are not “natural” in their origins, and their analysis and processing also belong to NLP. (Many years ago, my master’s thesis on machine translation was a system that automatically translated Esperanto into English and Chinese, which filled a gap.)
A term that is often used interchangeably with NLP is computational linguistics (CL). As the name suggests, computational linguistics is an interdisciplinary field between computer science and linguistics. In fact, NLP and CL are two sides of the same coin; NLP focuses on practice, while CL is a discipline (theory). It can be said that CL is the scientific foundation of NLP, and NLP is the application process of CL. Since CL is different from foundational disciplines like mathematics, and is more application-oriented, CL and NLP are almost the same thing. Practitioners can describe themselves from these two perspectives. For example, I can be called an NLP engineer in the industry and a computational linguist in academia. Of course, computational linguists in universities and research institutes also need to develop NLP systems and experiments, but the focus of their discipline is to support theoretical and algorithmic research through experiments. In the industrial sector, NLP engineers focus on the implementation of real-life systems and related product development, often adhering to the principle of “it doesn’t matter if it’s a black cat or a white cat, as long as it catches mice,” with less theoretical constraints.
Another term frequently used in parallel with NLP is machine learning (ML). Strictly speaking, machine learning and NLP are completely different levels of concepts; the former is a method, while the latter is a problem domain. However, due to the universal applicability of machine learning (who says machine learning is not omnipotent, statisticians might argue with you), and since ML has become the mainstream method in the field of NLP (especially in academia), many people have forgotten or ignored that NLP also has methods based on language rules, so in their eyes, NLP is just machine learning. In fact, machine learning is not limited to the NLP domain; the machine learning algorithms used for language processing can also be applied to many other artificial intelligence (AI) tasks, such as stock market prediction, credit card fraud detection, computer vision, DNA sequence classification, and even medical diagnosis.
In the field of NLP, the traditional methods parallel to machine learning include language rules manually crafted by linguists or knowledge engineers (Linguistic rules, or hand-crafted rules). The collection of these rules is called computational grammar, and the systems supported (or compiled) by computational grammar are called rule systems.
Both machine learning and rule systems have their pros and cons, allowing for complementary advantages. In general, machine learning excels in document classification, grasping language phenomena on a macro level, while computational grammar excels in detailed linguistic analysis, capturing language phenomena on a micro level. If we view language as a forest and sentences as various trees within it, machine learning generally sees the forest without noticing the trees, while computational grammar sees the trees without seeing the forest (this is a natural complementary relationship, but there are a significant number of “fundamentalist extremists” on both sides who refuse to acknowledge the strengths of the other). In terms of effectiveness, machine learning often wins by coverage, a term known in the industry as high recall, while computational grammar excels in analytical precision, meaning high precision. Since natural language tasks are relatively complex, a practical system often needs to strike a balance between coarse and fine granularity as well as recall and precision, thus hybrid systems that combine both methods are often more practical and useful. A simple and effective way to combine them is to establish a back-off model for each major task, allowing computational grammar to handle high-precision, low-coverage processing first, followed by the statistical model produced by machine learning to cover residual issues.
It is worth mentioning that traditional AI also relies on manually crafted rule systems, known as symbolic logic, but it fundamentally differs from the computational grammar of linguists: AI rule systems are far less practical than computational grammar. AI rule systems not only include relatively easy-to-grasp (tractable) and formalized language rules, but they also attempt to encompass a vast array of common sense (at least the core parts) and other knowledge, integrating this knowledge through a cleverly designed logical reasoning system. It can be said that AI aims to fundamentally simulate human intelligent processes, but due to its ambitious nature, it has made little progress over the years. Past glories were only evident in extremely narrow toy systems (which later developed into more practical expert systems), while statistical models were still in their infancy. The rise of statistical methods centered around ML, supported by big data, has made traditional AI appear inadequate. Interestingly, although artificial intelligence (which Taiwanese compatriots refer to as artificial wisdom) sounds impressive and can evoke a certain scientific fantasy miracle in the minds of the general public (thus often favored by marketers of electronic products), it is relatively lonely in the scientific community: many statisticians even consider AI a has-been joke. While there is inevitably some bias in this perspective, the traditional AI methodology and its unrealistic ambitions are also a factor. Perhaps in the future, there will be a revival of symbolic logic AI, but in the foreseeable future, methods that treat human intelligence as a black box linking input and output through machine learning have evidently taken the lead.
From this perspective, the relationship between ML and AI resembles that between NLP and CL, with almost overlapping extensions; ML focuses on the application of AI (including NLP), while traditional AI should serve as the theoretical guidance for ML. However, due to methodological differences, traditional AI, based on knowledge representation and logical reasoning, increasingly struggles to serve as practical intelligent systems’ theoretical guidance, while the territory of intelligent systems has gradually been occupied by machine learning, which is based on statistics and information theory. Rare individuals like the panda, who insist on traditional AI (like Douglas Lenat, the inventor of Cyc), and those who excel in ML (more numerous than dinosaurs), although their problem domains almost completely overlap, have solutions that seem to diverge further and further.
Another term that is almost equivalent to natural language processing is natural language understanding (NLU). Literally, the term NLU, meaning “machine understanding language,” carries a strong romantic flavor of artificial intelligence, unlike “machine processing language,” which is straightforward and realistic. However, whether using NLP or NLU, just as using NLP or CL, it often reflects different habits of people from different circles, with essentially the same reference. The reason for saying they are essentially the same is that NLP can also specifically refer to shallow language processing (for example, shallow parsing mentioned later), while deep parsing is an inherent part of NLU; superficial processing cannot be regarded as NLU/AI. One might say that when viewed through the lens of AI, it is NLU; whereas through the lens of ML, it can only be considered NLP.
Moreover, natural language technology or language technology is also a colloquial expression for NLP.
Since NLP’s equivalent term CL has two parents, computer science and linguistics, the higher-level concept of NLP can naturally have two figures: NLP can be seen as an application branch of computer science or as an application branch of linguistics. In fact, broadly defined applied linguistics encompasses both computational linguistics and NLP. However, since computational linguistics has established itself as an independent discipline for over half a century (its main journal is “Computational Linguistics,” and its association is ACL, with top international conferences including the ACL annual meeting and COLING), (narrowly defined) applied linguistics is now more used to denote practical fields such as language teaching and translation, no longer encompassing computational linguistics as a branch.
Functionally, NLP, like ML, belongs to the realm of artificial intelligence, especially natural language understanding and various applications of NLP, such as machine translation. Therefore, broadly speaking, artificial intelligence is both a higher-level concept for machine learning and for natural language processing. However, as mentioned above, narrow or traditional artificial intelligence emphasizes knowledge processing, including common-sense reasoning, which is quite distant from the current data-driven state of ML and NLP. Thus, some NLP scholars deliberately maintain a distance from traditional AI to show disdain for it.
With many threads to unravel, the following text will explain NLP per se at four levels, using four contact maps. The four levels are:
-
Linguistic Level
-
Extraction Level
-
Mining Level
-
Application Level
The relationships among these four levels are fundamentally supportive from bottom to top: 1 ==> 2 ==> 3 ==> 4. Clearly, the core syntactic parser of NLP is at the first level, while systems like “automated polling,” “question answering systems,” and “machine translation” are examples at the fourth level of applications.
It should be noted that the object of NLP, natural language, has two forms: speech and text. Therefore, NLP naturally encompasses two important directions in speech: 1. Teaching computers to understand human speech through speech recognition; 2. Teaching computers to speak human language through speech synthesis. Since I am relatively inexperienced in speech processing, this series will focus on text-based NLP, regarding speech recognition and synthesis as prelude and sequel to text processing. In fact, in actual language systems, the division of labor between speech processing and text processing is indeed such that, for example, the latest application of NLP on mobile phones, like Apple’s Siri, first performs speech recognition, outputs text results, then conducts text analysis, and finally takes action based on the analysis results (such as checking the weather forecast, stock prices, playing a certain song, etc.).
Clean Hands and Incense for Good Reading
I have divided the NLP system from core engines to applications into four stages, corresponding to four framework diagrams.
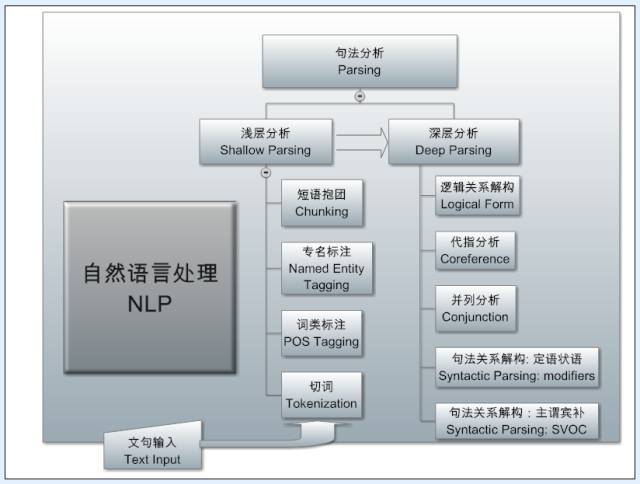
The lowest and most central level is deep parsing, which is the bottom-up automatic analyzer of natural language. This task is the most complex, yet it is the foundational technology of most NLP systems, as natural language is structured from unstructured data. Faced with the ever-changing expressions of language, only by structuring can patterns be easily captured, information extracted, and semantics resolved. This principle has been a consensus in (computational) linguistics since Chomsky’s linguistic revolution in 1957, which proposed the transformation from surface structure to deep structure. The structure tree not only expresses syntactic relationships through branches (arcs) but also includes the leaves (nodes) that carry various pieces of information, such as words or phrases. Although the structure tree is important, it generally cannot directly support products; it merely serves as an internal representation of the system, acting as a carrier for language analysis and understanding, and providing core support for semantic application.
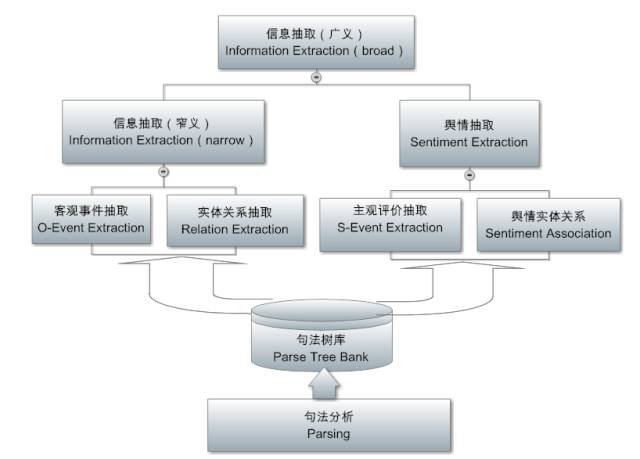
The next level is the extraction level, as shown in the above image. Its input is the structure tree, and its output is filled templates, similar to filling out a form: it pre-defines a table for the information needed for the application, allowing the extraction system to fill in the blanks, extracting relevant words or phrases from sentences and sending them into the predefined fields of the table. This level has transitioned from the original domain-independent parser to task-oriented applications and product needs.
It is important to emphasize that the extraction level is semantically focused on the domain, while the previous analysis level is domain-independent. Therefore, a good architecture is to conduct deep and logical analysis to alleviate the burden of extraction. Performing extraction on the logical semantic structure of deep analysis means that one extraction rule is equivalent to thousands of surface language rules. This creates conditions for domain transfer.
There are two main types of extraction: one is traditional information extraction (IE), which extracts factual or objective information: entities, relationships between entities, events involving different entities, etc., capable of answering questions like who did what when and where. This objective information extraction is the core technology and foundation of today’s incredibly popular knowledge graphs. After completing IE, adding the integration from the next mining layer (IF: information fusion) can construct a knowledge graph. The second type of extraction is subjective information, where sentiment mining is based on this type of extraction. This is also the area I have focused on in the last five years, particularly fine-grained sentiment extraction (not just sentiment classification, but also extracting the reasons behind sentiments to inform decision-making). This is one of the most challenging tasks in NLP, significantly more difficult than objective information extraction (IE).
The extracted information is usually stored in some database, providing fragmented information for the subsequent mining layer.
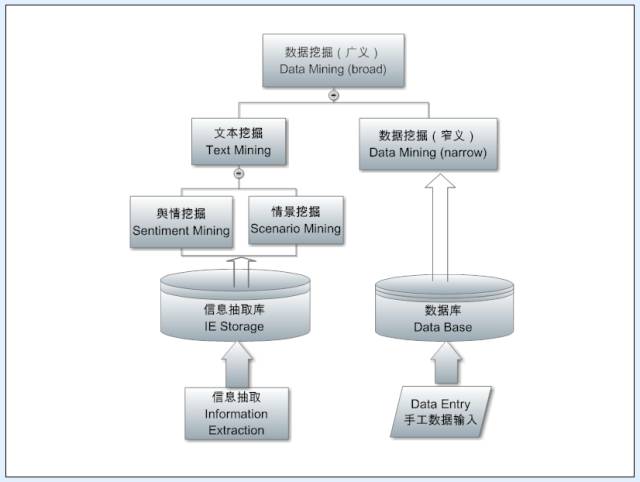
Many people confuse extraction (information extraction) with the next step of mining (text mining), but in reality, these are two different levels of tasks. Extraction deals with individual language trees, finding the desired information from individual sentences. In contrast, mining deals with an entire corpus or data source, extracting statistically valuable information from the language forest. In the information age, our greatest challenge is information overload; we cannot exhaustively analyze the ocean of information. Therefore, we must rely on computers to extract critical information from the information ocean to meet various applications. Thus, mining inherently relies on statistics; without statistics, the extracted information remains chaotic fragments with significant redundancy, while mining can integrate them.
Many systems do not delve into mining, simply using the query expressing information needs as an entry point to real-time retrieve and merge the top n results from the database of extracted relevant fragmented information, directly supporting applications. This is also a form of mining, but it achieves simple mining through a retrieval method.
In fact, to perform well in mining, there is a lot of work to be done, not only to integrate and improve the quality of existing information but also to conduct in-depth work to uncover hidden information, i.e., information not explicitly expressed in metadata, such as discovering causal relationships between pieces of information or other statistical trends. This type of mining was first done in traditional data mining, as traditional mining targets structured data like transaction records, making it easier to uncover implicit associations (for example, people who buy diapers often also buy beer, which is a common behavior of new parents; this type of information can help optimize product placement and sales). Now that natural language has also been structured into extracted fragmented information in databases, it is certainly possible to perform implicit association mining to enhance the value of the information.
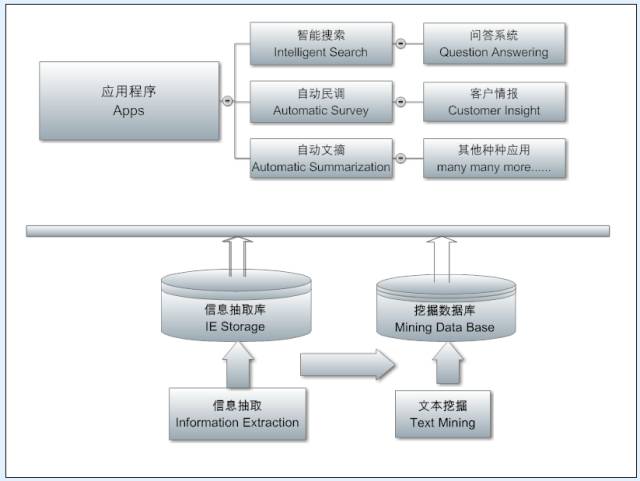
The fourth framework diagram is the NLP application (apps) layer. At this level, the various pieces of information analyzed, extracted, and mined can support different NLP products and services, from question-answering systems to dynamic browsing of knowledge graphs (for instance, searching for celebrities in Google search already showcases this application), from automated polling to customer intelligence, from intelligent assistants to automatic summarization, and so on.
This is my overall explanation of the basic architecture of NLP. It is based on over 20 years of experience in developing NLP products in the industry. Eighteen years ago, I secured my first venture capital with an NLP architecture diagram, with the investor saying it was a million-dollar slide. The current explanation has evolved from that initial diagram.
The world changes, but the principles remain constant.
About the Author
Li Wei, PhD, a senior architect in natural language processing (NLP), Chief Scientist at Netbase, a big data sentiment analysis company in Silicon Valley, former Vice President of R&D at Cymfony, winner of the first prize in the question-answering system (TREC-8 QA Track), and has won 17 information extraction projects from the U.S. Department of Defense (PI for 17 SBIRs). His expertise in natural language deep parsing is notable, leading a team to develop understanding and application systems for 18 languages with high precision and efficiency, especially in Chinese and English, achieving world-class analytical accuracy, robustness, and scalability to big data. The system quality has been recognized by third-party evaluations as significantly ahead of competitors. Application directions include big data sentiment analysis, customer intelligence, information extraction, knowledge graphs, question-answering systems, intelligent assistants, semantic search, intelligent browsing, machine translation, and more.
This article is reprinted from Li Wei’s NLP channel:

Read More
▽ Story
· Einstein Rejected After Submission
· The 2016 “Chang Jiang Scholars” Selection List Announced: 159 Distinguished Professors, 52 Chair Professors, 229 Young Scholars
· The Power of Hunger: Improving Health, Assisting Chemotherapy, Reversing Diabetes
· Cell Heavyweight | The Elixir of Life Has Never Been So Close
▽ Paper Recommendations
· What Differences Exist Between the Brains of Memory Experts and Ordinary People? | Neuron Paper Recommendation
· Where Do Cosmic Rays Come From? Seven Years of Data Still Cannot Provide Answers | PRL Paper Recommendation
· Spider Venom May Prevent Brain Stroke Damage | PNAS Paper Recommendation
▽ Paper Reading Guide
· Science Weekly Paper Reading Guide | March 24, 2017
· Nature Weekly Paper Reading Guide | March 23, 2017
For content collaboration, please contact
