


Google releases the native multimodal AI large model Gemini
A new visual prompt AI model T-Rex achieves image recognition through images
The “white-box” Transformer architecture CRATE enhances AI model interpretability
【Key Insight】
In practical applications, artificial intelligence (AI) is often difficult to achieve a comprehensive improvement in production efficiency as a single technology, and often requires the ability to integrate technologies and innovate upgrades.
Currently, AI large models are evolving in the following directions: first, enhancing model capabilities, continuously challenging multimodal and multi-domain integration issues; second, lightweight model development, sinking to mobile terminals to deeply serve end-users; third, continuously striving to improve model interpretability and trustworthiness, making AI architectures more in line with human logical thinking, which helps with model optimization and expansion.
Through continuous exploration and improvement in these directions, the development and application of artificial intelligence in various industries and fields will be strongly promoted.
01
Google releases the native multimodal AI large model Gemini
Recently, Google announced the launch of an AI large model called Gemini. It is reported that this model has one trillion parameters and the training compute is five times that of GPT-4, surpassing human experts for the first time in the MMLU (Massive Multitask Language Understanding) evaluation, achieving 30 SOTA (state-of-the-art) results in 32 multimodal benchmarks, almost fully surpassing GPT-4.
Gemini has created three versions for different applications: the basic version Nano, the mid-range version Pro, and the highest version Ultra.

▲Three versions of Gemini
Nano can run on mobile devices using special chips, without the need for cloud servers, bringing generative AI to Android phones.Nano is divided into two categories: one has 1.8 billion parameters, suitable for ordinary performance phones; the other is for high-performance phones, with 3.25 billion parameters.Gemini Pro is a scalable model for cross-range tasks.Ultra is for highly complex tasks, its security testing is still ongoing, and it is planned to be launched in 2024.
Currently, most models complete multimodal tasks by training separate modules and then stitching them together, which is insufficient for deep complex reasoning in multimodal spaces. One of Gemini’s biggest highlights is its native multimodal large model, capable of processing different forms of data, generalizing, understanding, operating, and combining different types of information, including text, code, audio, images, and video. Based on its native multimodal advantages, Google is researching how to combine Gemini with robotics technology to interact physically with the world.

▲Gemini generates code based on video input
Google has trained Gemini 1.0 on a large scale using its self-designed Tensor Processing Unit (TPU) v4 and v5e on AI-optimized infrastructure. Gemini runs significantly faster on TPU than earlier smaller and less capable models.
To improve security, Google has built a dedicated safety classifier to identify, label, and filter out content involving violence or negative themes, used in conjunction with filters. Additionally, Google is continuously addressing existing challenges of AI large models, such as factuality, basis, and attribution issues.
Currently, Gemini Pro and Gemini Nano have been integrated into the chatbot Bard and the smartphone Pixel 8 Pro, and will gradually provide services in Google Search, Ads, Chrome, and Duet AI in the future. Starting from December 13, 2023, developers and enterprise clients can access Gemini Pro through the Gemini API in Google AI Studio or Google Cloud Vertex AI.
02
The New Visual Prompt AI Model T-Rex Achieves Image Recognition Through Images
At the 2023 IDEA Conference, the IDEA Research Institute showcased a new experience in target detection based on visual prompts and released an experiment based on the new visual prompt model T-Rex: an Interactive Visual Prompt (iVP) system that specifies detection targets using visual examples, overcoming the challenge of expressing rare and complex objects adequately with text to improve prompt efficiency.

Unlike AI models that only support text prompts, the T-Rex model focuses on building a strong interactive visual prompt feature. Using iVP, users can mark objects of interest on images, providing visual examples to the model, which then detects all instances in the target image that are similar. During this process, the model provides intuitive visual feedback, such as bounding boxes, to help users efficiently evaluate detection results.
T-Rex is ready to use out of the box, requiring no retraining or fine-tuning, and is not limited by predefined categories, enabling it to detect objects the model has never seen during training. This model can be applied to all detection tasks, including counting, and provide new solutions for intelligent interactive labeling scenarios.

▲Three advanced modes
Based on insights into practical usage needs, the team designed T-Rex to accept multiple visual prompts and have cross-image prompt capabilities. In addition to the basic single-turn prompt mode, the model now supports three advanced modes: multi-turn positive example mode, suitable for scenarios where visual prompts are not precise enough, leading to missed detections; “positive + negative example” mode, suitable for scenarios where visual prompts have ambiguity, leading to false detections; and cross-image mode, suitable for prompting detection in other images using a single reference image.
03
The “White-box” Transformer Architecture CRATE Enhances AI Model Interpretability
Researchers from institutions such as the University of California, Berkeley, and the University of Hong Kong have recently proposed a “white-box” Transformer architecture CRATE, aimed at improving model interpretability while maintaining excellent performance.
Traditional AI models like Transformer are often viewed as “black boxes” due to their complex and hard-to-interpret internal mechanisms. CRATE (Coding RAte reduction TransformEr) is a white-box (mathematically interpretable) Transformer architecture that provides clearer internal logic and working principles.
CRATE optimizes information representation through mathematical methods, similar to how we compress files in daily life to save space. The core of CRATE lies in how it processes and transforms data; it encodes input data (such as images or text) into a series of “tokens” that represent information, and then through a series of optimization steps, transforms these tokens into a more efficient and meaningful form.
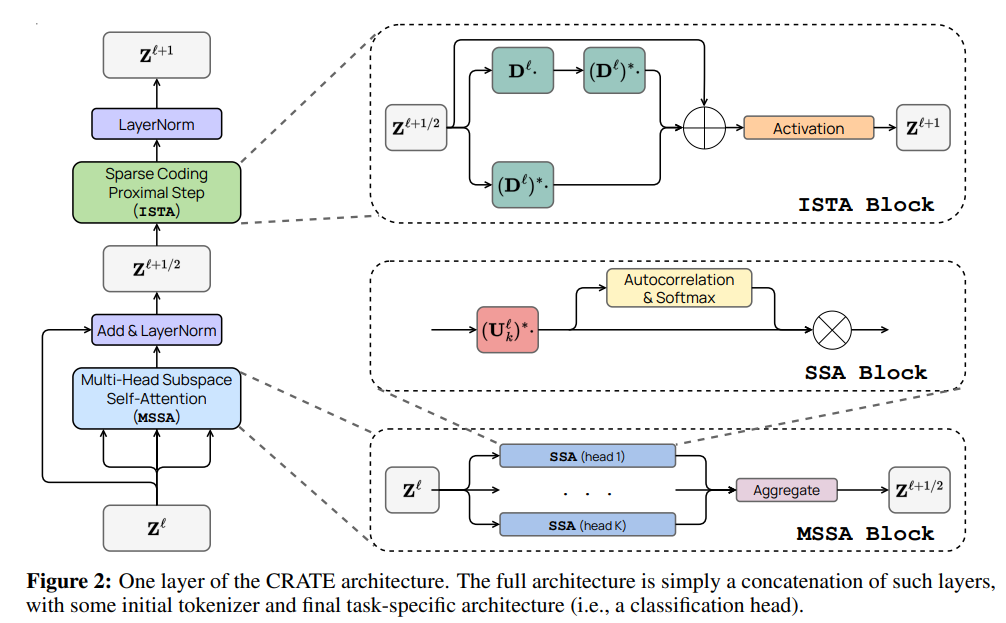
▲One layer of the CRATE architecture
The research team proposed a theory that the core mechanism of all AI models is data compression and optimization, achieving effective representation by compressing data from high-dimensional distributions to low-dimensional structures. In practice, CRATE builds a deep network where each layer executes a specific algorithmic step, focusing on reducing “sparsity”—that is, simplifying and refining the way information is represented. This approach makes data representation more compact and efficient while also making each decision of the model clearer and more interpretable.
CRATE not only performs excellently on standard machine learning tasks but also shows significant advantages in interpretability. More importantly, this architecture allows researchers and developers to better understand and control the behavior of AI models, enabling targeted measures when optimizing and enhancing AI models.
(All images in this issue are sourced from the internet)

Written by the editor丨Zhang Xue
Proofread by丨Wang Weina
Reviewed by丨Wang Cui
Final review by丨Liu Da
Call for Contributions!
Don’t forget to like + follow!
